
Cours
Travailler avec Llama 3
2 h
13.8K
Kimi K2, développé par Moonshot AI, est un modèle linguistique de pointe basé sur le principe de la combinaison d'experts (MoE). Il excelle dans les tâches liées aux connaissances de pointe, au raisonnement et au codage, et est spécialement optimisé pour les capacités agenturielles, notamment l'utilisation d'outils et la résolution autonome de problèmes.
Comme nous l'expliquons dans notre guide Kimi K2, ce modèle obtient des résultats de référence exceptionnels, ce qui en fait le meilleur modèle de langage open source à usage général. Nous assistons actuellement à l'avènement de la technologie Deepsee. moment Deepseek R1, et pour célébrer cela, je vais vous expliquer comment exécuter cet énorme modèle de 1 téraoctet sur un seul GPU.
Nous allons apprendre à configurer la machine Runpod, à installer llama.cpp et à télécharger le modèle plus rapidement. De plus, nous exécuterons le modèle à l'aide de l'interface CLI llama.cpp, en déchargeant les couches du modèle vers la mémoire RAM. Enfin, nous aborderons les problèmes courants qui surviennent lors de l'exécution de ces modèles.
Accédez à la page cloud GPU Runpod et créez un cloud avec la machine A100 SXM en utilisant l'image conteneur Python version 2.8.0.
Ensuite, augmentez la capacité de stockage du conteneur à 300 Go à l'aide de l'option Modifier le pod.
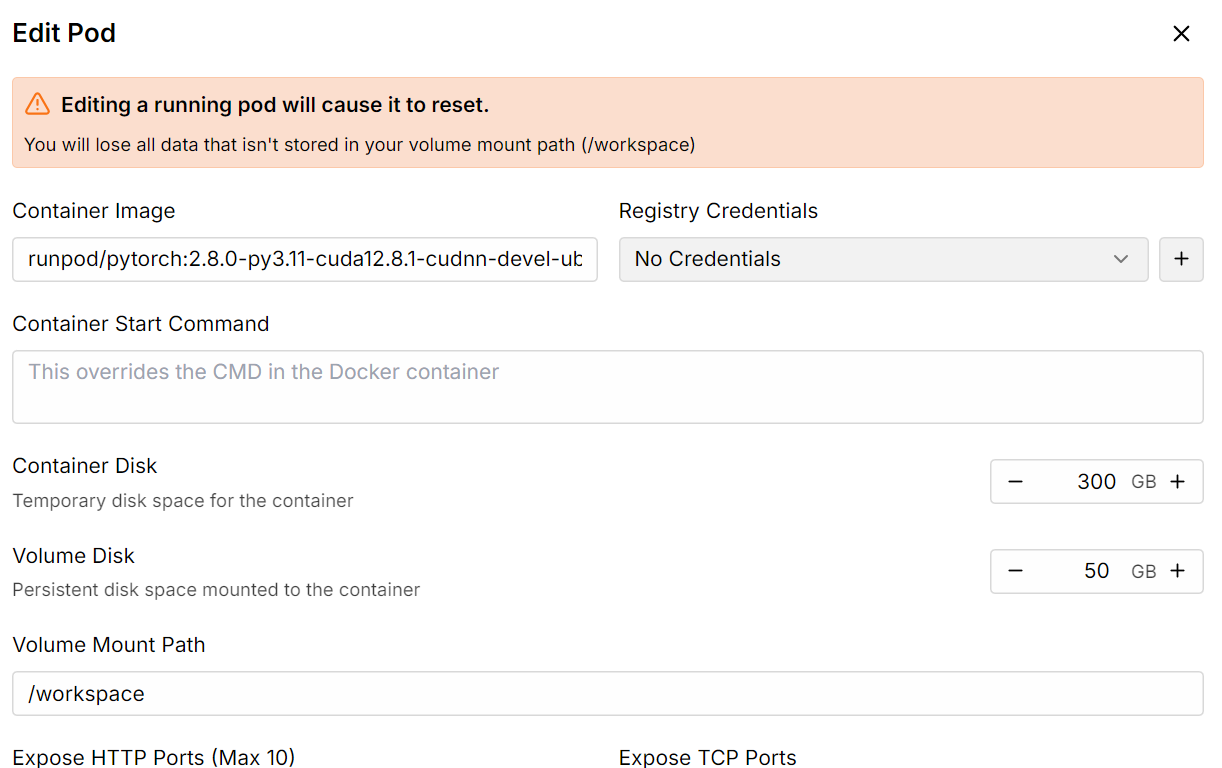
Une fois que tout est configuré, vous constaterez que vous disposez de 300 Go d'espace de stockage, ce qui est suffisant puisque notre modèle quantifié à 1 bit nécessite 250 Go d'espace de stockage.
1. Veuillez cliquer sur le bouton « Connect » et lancer l'instance Jupyter Lab. Veuillez créer un nouveau bloc-notes et installer les outils Linux nécessaires, tels que cmake et curl.
!apt-get update
!apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
2. Veuillez vous rendre dans le répertoire racine. Nous n'utiliserons pas le répertoire de travail. La raison est d'augmenter à la fois la vitesse de téléchargement et de chargement du modèle. Vous trouverez plus d'informations à ce sujet dans la section Dépannage à la fin du document.
%cd ..3. Veuillez cloner la dernière version du référentiel llama.cpp.
!git clone https://github.com/ggml-org/llama.cpp
4. Configurez les options de compilation. Nous exécutons la compilation pour une machine équipée d'un processeur graphique. Si vous souhaitez utiliser l'inférence CPU, veuillez remplacer DGGML_CUDA=ON par DGGML_CUDA=OFF.
!cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES="80;90" \
-DCMAKE_CUDA_FLAGS="-Wno-deprecated-gpu-targets"
5. Nous utiliserons la commande « cmake » pour compiler les outils : « llama-quantize », « llama-cli », « llama-gguf-split » et « llama-mtmd-cli ».
!cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split llama-mtmd-cli
6. Veuillez copier tous les outils de compilation dans le référentiel principal afin que nous puissions y accéder facilement.
!cp llama.cpp/build/bin/llama-* llama.cppLes versions quantifiées du modèle Kimi K2 par Unsloth prennent en charge xnet, qui permet des téléchargements et des chargements quatre fois plus rapides que Git LFS. Pour l'activer localement, veuillez installer la dernière version de huggingface_hub et hf_transfer:
!pip install huggingface_hub hf_transfer
Veuillez utiliser l'API snapshot_download pour télécharger uniquement les fichiers de modèle GGUF quantifiés en 1 bit pour le référentiel :
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/Kimi-K2-Instruct-GGUF",
local_dir = "/unsloth/Kimi-K2-Instruct-GGUF",
allow_patterns = ["*UD-TQ1_0*"],
)Le téléchargement peut prendre un certain temps, selon votre connexion Internet et votre espace de stockage.
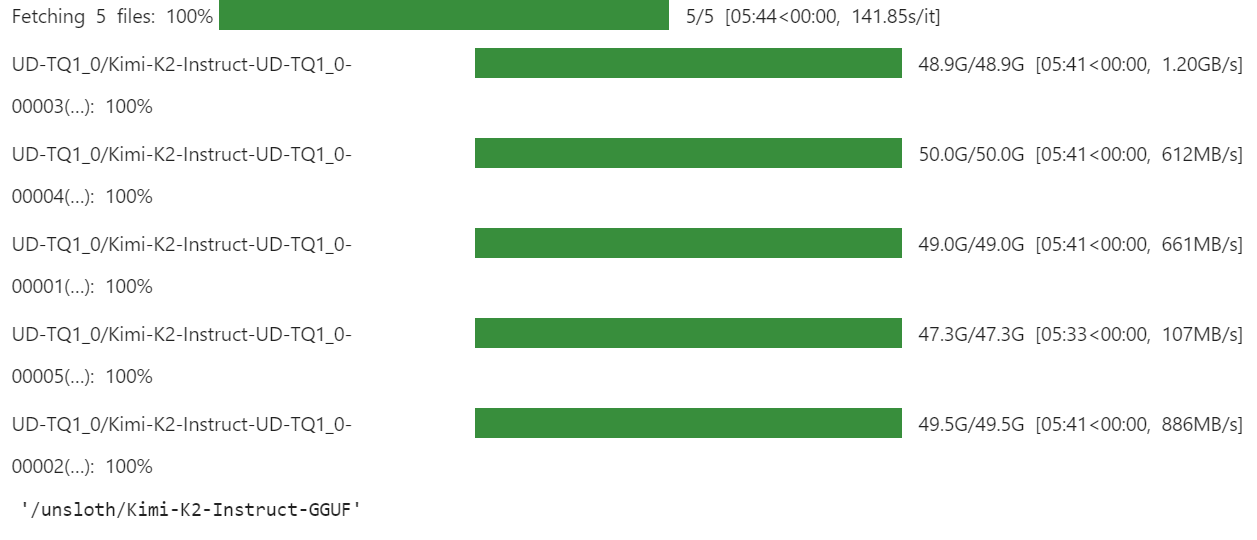
Pour nous, cela a été extrêmement rapide, car nous disposons de solutions de stockage plus rapides grâce à xnet.
Il est temps de tester notre version quantifiée du modèle. C'est la partie qui m'a demandé le plus de temps de débogage, car j'essaie de l'exécuter sur un seul GPU. Bien que cela ne soit pas impossible, cela pose plusieurs problèmes liés au chargement et à l'exécution du modèle.
Nous utilisons tous les threads du processeur et optimisons le chargement des couches vers le processeur graphique, ce qui implique le déchargement du processeur des couches de projection ascendante et descendante Mixture of Experts.
Voici la commande que nous exécutons dans le terminal, qui fonctionne correctement :
./llama.cpp/llama-cli \
--model /unsloth/Kimi-K2-Instruct-GGUF/UD-TQ1_0/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--cache-type-k q4_0 \
--threads -1 \
--n-gpu-layers 99 \
--temp 0.6 \
--min_p 0.01 \
--ctx-size 16384 \
--seed 3407 \
-ot ".ffn_(up|down)_exps.=CPU" \
--prompt "Hey"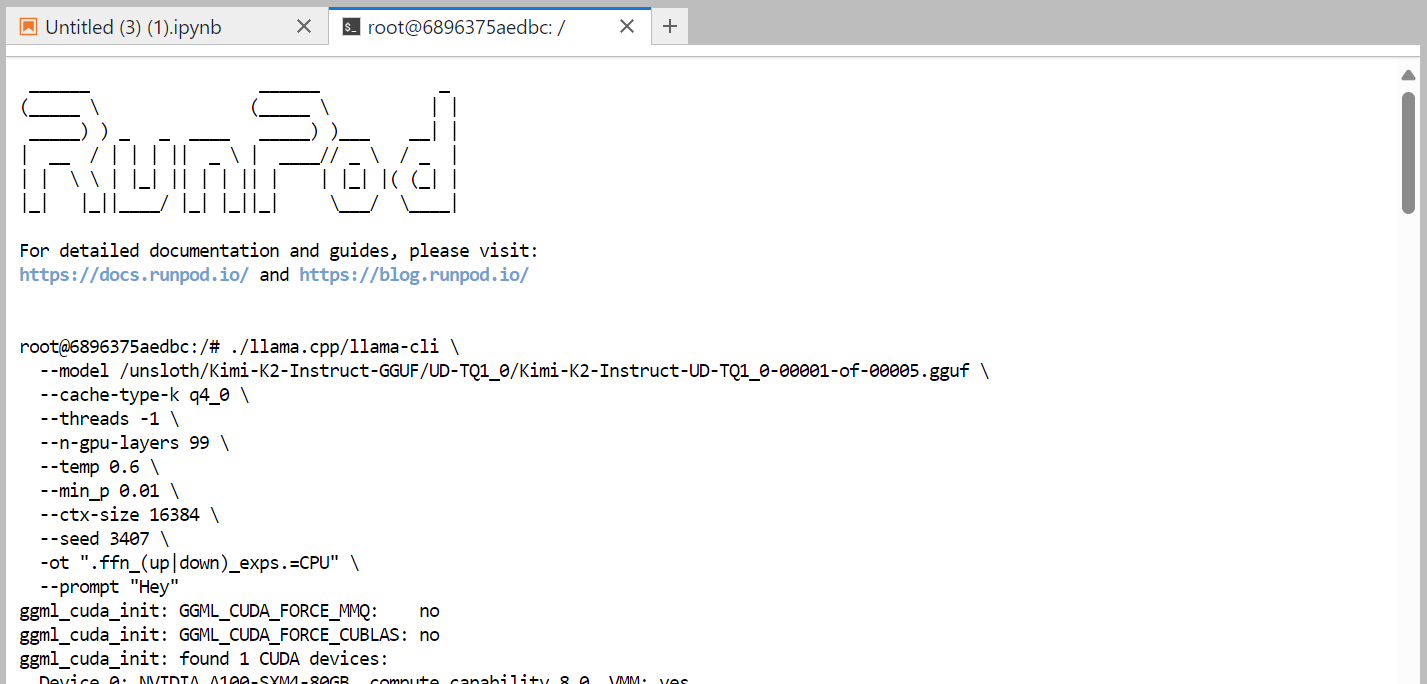
Il a fallu près d'une minute pour charger le modèle complet. Comme nous pouvons le constater, le modèle s'adapte parfaitement à la machine.

Si vous consultez votre tableau de bord Runpod, vous constaterez que l'utilisation de votre processeur est élevée et que la mémoire RAM et VRAM sont toutes deux utilisées.
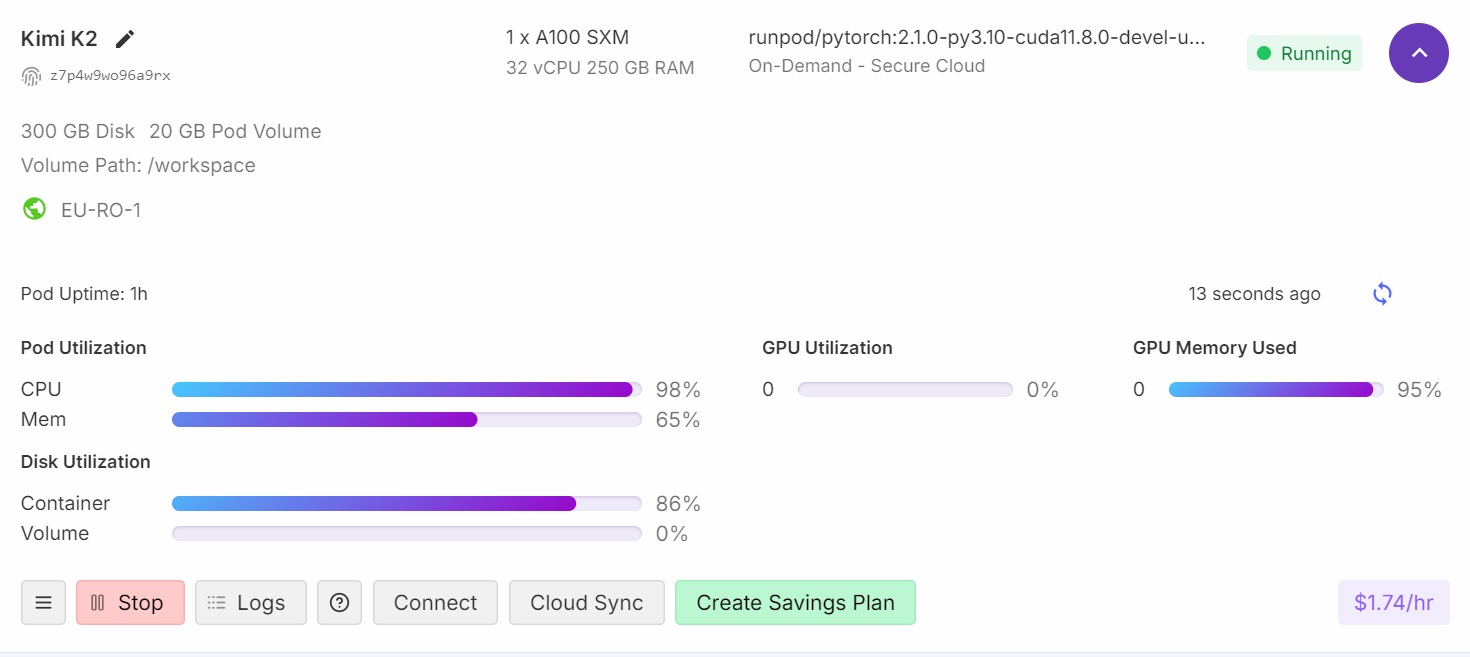
Après environ quatre minutes de chargement et de préchauffage, vous êtes prêt à poser des questions au modèle.

J'ai posé une question simple : Qu'est-ce que la mousson ? Veuillez écrire votre réponse sur une seule ligne.

Il a fallu près de cinq minutes pour terminer la génération.
J'ai effectué quelques recherches pour comprendre pourquoi la génération de jetons était lente, et il s'avère que le GPU n'est utilisé que comme mémoire, tandis que tout le traitement est effectué par le CPU. Pour résoudre ce problème, il est nécessaire de décharger davantage de couches vers le GPU, ce qui implique l'utilisation de deux machines A100.
Dans cette section, nous aborderons les problèmes courants rencontrés lors de l'exécution d'un modèle volumineux sur un seul GPU et les solutions pour les résoudre.
Lorsque vous constatez une utilisation de la mémoire GPU de 95 %, une utilisation du calcul GPU de 0 % et une charge CPU de 99 %, cela signifie généralement que la VRAM sert de mémoire de stockage pour le modèle, tandis que le traitement réel s'effectue sur le CPU.
Même les modèles hautement quantifiés et plus petits de 1 bit doivent être chargés en mémoire, ce qui contribue à l'utilisation de la VRAM. L'utilisation du GPU pour le calcul ne commencera que si vous transférez davantage de couches vers la VRAM.
Pour améliorer la vitesse de génération des jetons, il est nécessaire de décharger davantage de couches du modèle vers le GPU. Vous pourriez envisager une configuration multi-GPU, telle que trois GPU A100. Réglez la température sur 0,6 pour réduire les répétitions et les incohérences dans le texte généré.
Si votre mémoire VRAM ou RAM est limitée, vous pouvez toujours exécuter des modèles 1 bit sur un processeur grand public. Cependant, la génération de jetons sera très lente (par exemple, 1 jeton toutes les 20 secondes).
La seule exigence stricte pour exécuter des modèles 1 bit est que votre espace disque total + RAM + VRAM soit supérieur ou égal à 250 Go.
Pour des performances optimales (5 jetons/seconde ou plus), vous aurez besoin d'au moins 250 Go de mémoire unifiée ou d'une combinaison de 250 Go de RAM et de VRAM.
Veuillez installer la dernière version de huggingface_hub et hf_transfer pour accéder à « xnet speed », qui est quatre fois plus rapide que le simple Git LFS.
Afin d'optimiser le stockage et le chargement des fichiers fragmentés GGUF, il est recommandé d'utiliser un disque conteneur pour le stockage plutôt qu'un volume conteneur. En effet, le volume des conteneurs peut ralentir le téléchargement et le chargement des modèles.
Un chargement lent du modèle indique souvent que vous chargez un modèle très volumineux. Le chargement de modèles à partir d'un stockage réseau peut considérablement ralentir le processus de chargement. Veuillez toujours utiliser un SSD M.2 local pour stocker vos modèles. Les SSD M.2 offrent des vitesses de lecture/écriture nettement plus rapides que les disques durs traditionnels ou le stockage réseau, ce qui réduit considérablement les temps de chargement.
Si la mémoire vive (RAM) est insuffisante pour charger le modèle, le système d'exploitation peut commencer à transférer des données vers le disque (à l'aide d'un fichier d'échange), ce qui est beaucoup plus lent que la mémoire vive et crée un goulot d'étranglement. Nous vous recommandons d'utiliser une configuration à plusieurs cartes graphiques avec une mémoire vive plus importante.
L'exécution de versions quantifiées de Kimi K2 peut encore rencontrer des difficultés, car des outils tels que llama.cpp évoluent activement pour s'adapter aux dernières mises à jour du modèle. Dans les semaines à venir, nous vous proposons des solutions améliorées qui transfèrent les calculs de génération de jetons vers les processeurs graphiques (GPU) afin d'optimiser les performances, plutôt que de dépendre uniquement des processeurs centraux (CPU).
De plus, cela a été une expérience très enrichissante pour moi. J'ai acquis une meilleure compréhension de la manière dont la communauté open source collabore pour optimiser et déployer ces modèles de la manière la plus efficace possible.
Kimi K2 se distingue comme l'un des meilleurs modèles open source, se rapprochant des capacités de modèles tels que DeepSeek R1, avec des performances de pointe dans les domaines des connaissances de pointe, des mathématiques et du codage parmi les modèles non pensants.
Il est particulièrement performant dans la sélection d'outils et les tâches d'agent, ce qui en fait une alternative rentable aux modèles haut de gamme tels que Claude 4 Sonnet. Claude 4 Sonnet pour les projets de codage ou le codage vibe.
Vous pouvez utiliser la version quantifiée du Kimi K2 pour vos solutions internes en suivant ce guide. Llama.cpp vous permet de fournir les modèles linguistiques sous forme d'API compatible avec OpenAI. Pour en savoir plus, veuillez consulter notre guide Kimi K2 avec des exemples. Si vous souhaitez en savoir plus sur l'IA agentielle, ne manquez pas notre nouveau cours sur la création de systèmes multi-agents avec LangGraph.
Meilleures formations en IA
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Stephen Gruppetta
Tutoriel
DataCamp Team
Tutoriel
Adel Nehme
