
Course
Working with Llama 3
2 hr
13.8K
Kimi K2, developed by Moonshot AI, is a state-of-the-art Mixture-of-Experts (MoE) language model. It excels in frontier knowledge, reasoning, and coding tasks, and is specially optimized for agentic capabilities, including tool use and autonomous problem-solving.
As we explore in our Kimi K2 guide, the model is achieving outstanding benchmark results, making it the best general-purpose open-source language model. We are witnessing the Deepseek R1 moment, and to celebrate that, I will teach you how to run this enormous 1-terabyte model on a single GPU.
We will learn how to set up the Runpod machine, install llama.cpp, and download the model at a faster speed. Additionally, we will run the model using the llama.cpp CLI, offloading the model layers to RAM. Ultimately, we will address common issues that arise when running these models. You can also find our guide to the new Kimi K2.5 with Agent Swarm.
Go to the Runpod GPU Cloud and create a cloud with the A100 SXM machine using the Python Container Image version 2.8.0.
After that, increase the container disk storage to 300 GB by using the Edit pod option.
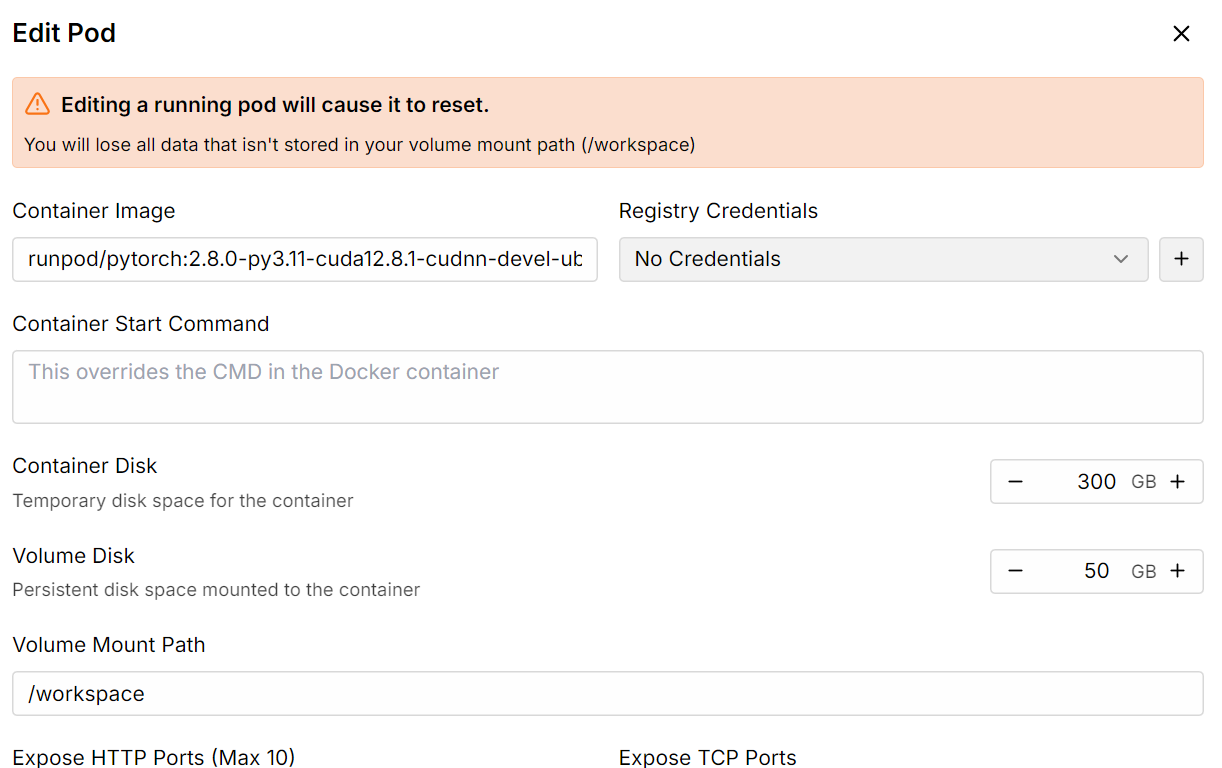
Once everything is set up, you will see that you have 300 GB of storage, which is sufficient since our 1-bit quantized model requires 250 GB of storage.
1. Click on the connect button and launch the Jupyter Lab instance. Create a new notebook and install the necessary Linux tools, such as cmake and curl.
!apt-get update
!apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
2. Change the directory to the root. We won't be using the workspace directory. The reason for this is to increase both the downloading and loading speeds of the model. You will learn more about it in the troubleshooting section at the end.
%cd ..3. Clone the latest version of the llama.cpp repository.
!git clone https://github.com/ggml-org/llama.cpp
4. Set up the build options. We are running the build for a GPU machine. If you want to use CPU inference, please change DGGML_CUDA=ON to DGGML_CUDA=OFF.
!cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES="80;90" \
-DCMAKE_CUDA_FLAGS="-Wno-deprecated-gpu-targets"
5. We will use the cmake command to build the tools: llama-quantize, llama-cli, llama-gguf-split, and llama-mtmd-cli.
!cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split llama-mtmd-cli
6. Copy all the build tools to the main repository so that we can access them easily.
!cp llama.cpp/build/bin/llama-* llama.cppThe quantized versions of the Kimi K2 model by Unsloth support xnet, which allows for downloads and uploads that are 4 times faster than Git LFS. To activate it locally, please install the latest version of huggingface_hub and hf_transfer:
!pip install huggingface_hub hf_transfer
Use the snapshot_download API to download only the 1-bit quantized GGUF model files for the repository:
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/Kimi-K2-Instruct-GGUF",
local_dir = "/unsloth/Kimi-K2-Instruct-GGUF",
allow_patterns = ["*UD-TQ1_0*"],
)The download will take some time, depending on your internet and storage speed.
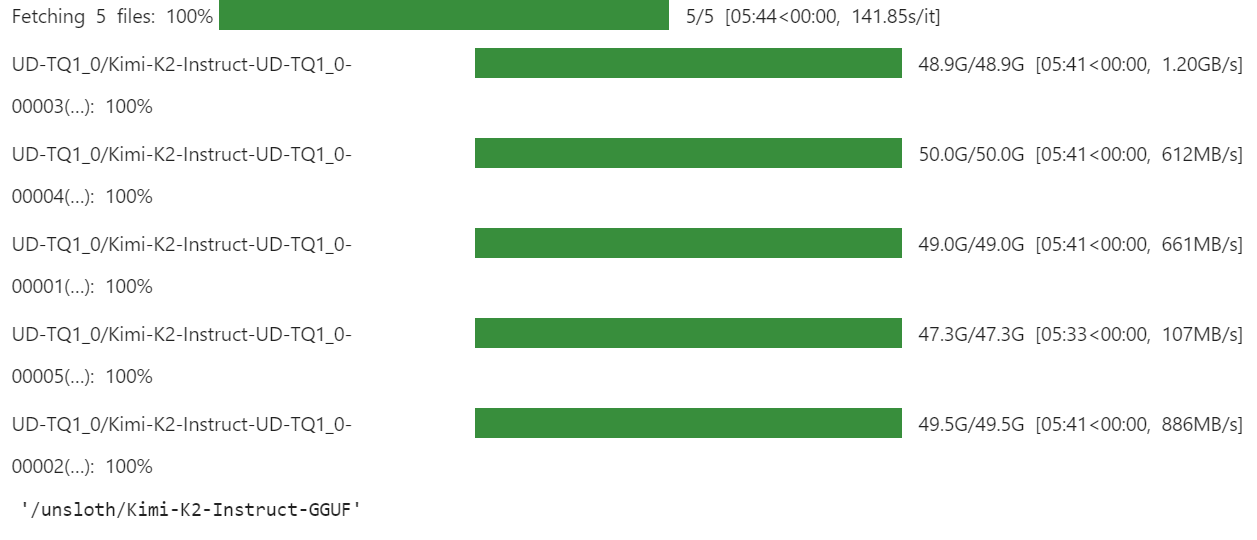
For us, it was super fast as we have faster storage solutions with xnet enabled.
It is time to test our quantized version of the model. This is the part where I spent most of my time debugging, as I am trying to run it on a single GPU. While this is not impossible, it comes with several issues related to model loading and execution.
We are using all CPU threads and maximizing layer loading to the GPU, which involves CPU offloading of both up and down projection Mixture of Experts layers.
Here’s the command that we are running in the terminal, which operates smoothly:
./llama.cpp/llama-cli \
--model /unsloth/Kimi-K2-Instruct-GGUF/UD-TQ1_0/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--cache-type-k q4_0 \
--threads -1 \
--n-gpu-layers 99 \
--temp 0.6 \
--min_p 0.01 \
--ctx-size 16384 \
--seed 3407 \
-ot ".ffn_(up|down)_exps.=CPU" \
--prompt "Hey"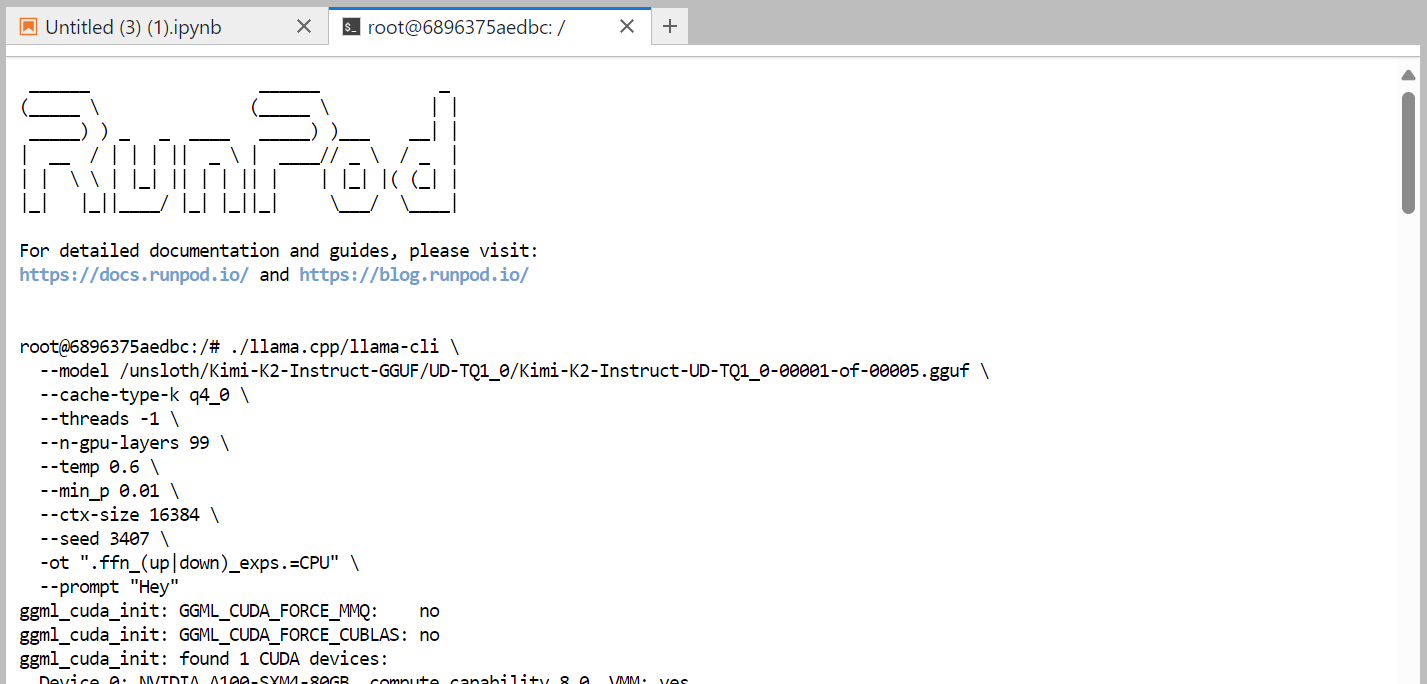
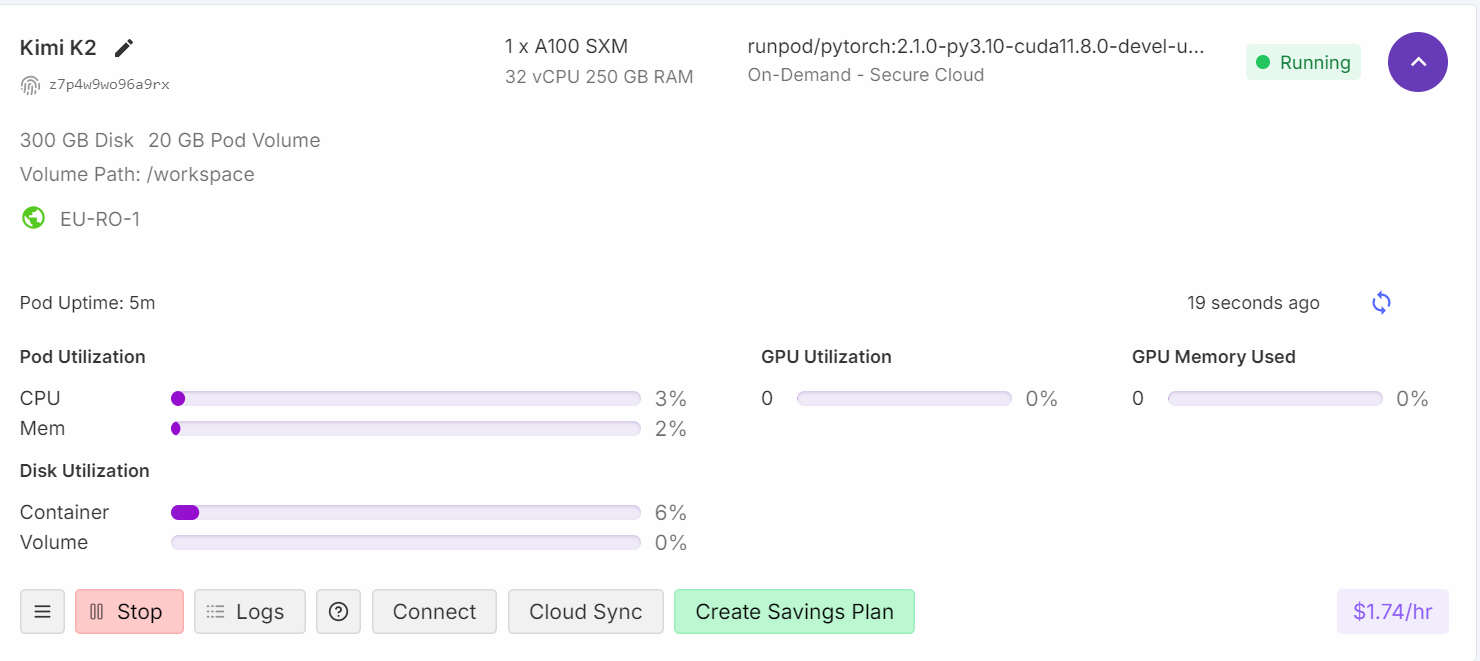
It took almost one minute to load the full model. As we can see, the model perfectly fits into the machine.

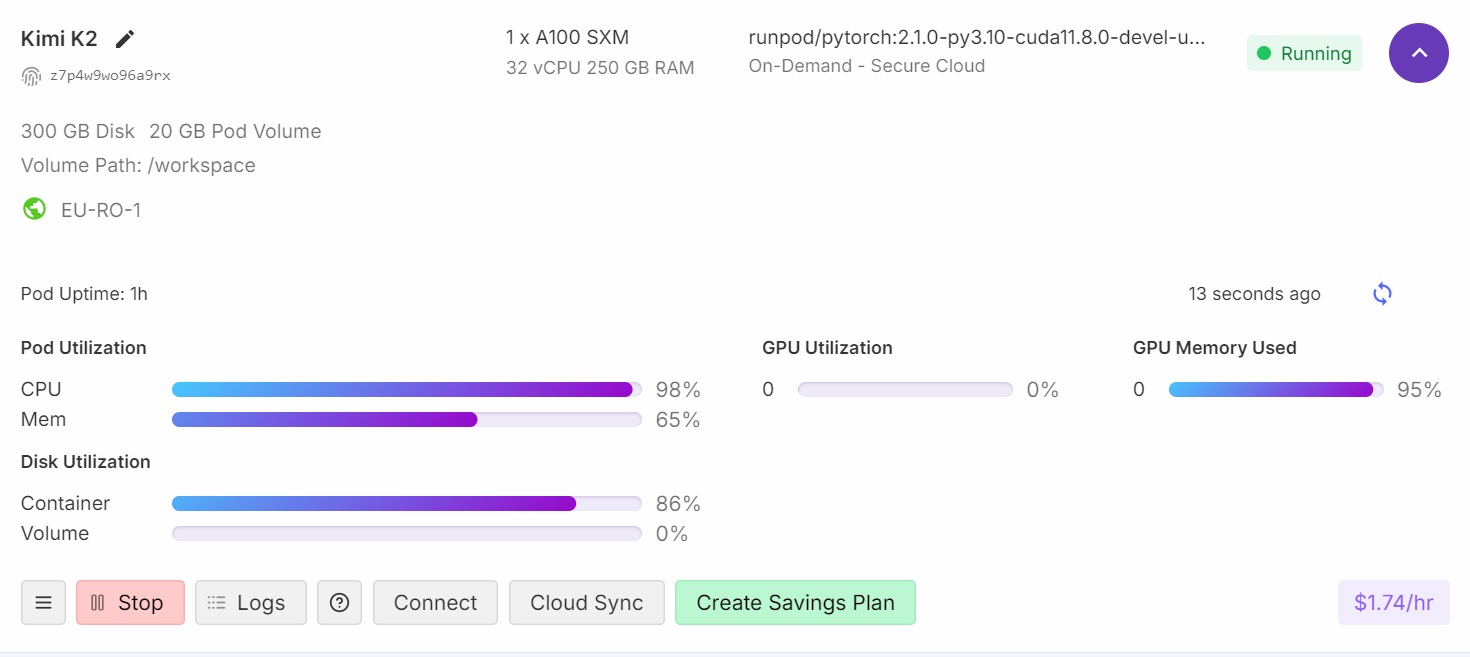
If you check your Runpod dashboard, you will see that your CPU usage is high, and both RAM and VRAM memory are being utilized.
After about four minutes of loading and warming up, you are ready to ask the model questions.

I asked a simple question: "What is monsoon? Write the answer in one line."

It took almost five minutes to complete the generation.
I did some research into why the token generation is slow, and it turns out that the GPU is only used as memory while all the processing is done by the CPU. To address this issue, you need to offload more layers to the GPU, which means you will require 2 A100 machines.
In this section, we will discuss the common issues encountered when running a large model on a single GPU and how you can overcome them.
When you see 95% GPU RAM usage, 0% GPU compute, and 99% CPU load, it typically means the VRAM is acting as memory storage for the model, while the actual processing is happening on the CPU.
Even highly quantized and smaller 1-bit models still need to be loaded into memory, which contributes to VRAM usage. GPU utilization for computation will only begin to occur if you offload more layers to the VRAM.
To improve token generation speed, you need to offload more layers of the model to the GPU. Maybe consider a multi-GPU setup, such as three A100 GPUs. Set the temperature to 0.6 to help reduce repetition and incoherence in the generated text.
If you have limited VRAM or RAM, you can still run 1-bit models on a consumer CPU. However, token generation will be very slow (e.g., 1 token per 20 seconds).
The only strict requirement for running 1-bit models is that your total disk space + RAM + VRAM is greater than or equal to 250GB.
For optimal performance (5+ tokens/second), you will need at least 250GB of unified memory or a combined 250GB of RAM and VRAM.
Install the latest version of huggingface_hub and hf_transfer to access "xnet speed," which is 4x faster than simple Git LFS.
To optimize the storage and loading of GGUF sharded files, it's recommended to use a container disk for storage rather than a container volume. This is because container volumes can lead to slow downloading and model loading.
Slow model loading often indicates you are loading a very large model. Loading models from network storage can significantly slow down the loading process. Always use a local M.2 SSD to store your models. M.2 SSDs offer much faster read/write speeds compared to traditional hard drives or network storage, drastically reducing loading times.
If there isn't enough RAM to load the model, the operating system might start swapping data to disk (using a swap file), which is much slower than RAM and creates a bottleneck. Try to have a multiple-GPU setup with higher RAM.
Running quantized versions of Kimi K2 can still encounter challenges, as tools like llama.cpp are actively evolving to keep pace with the model's latest updates. In the coming weeks, expect improved solutions that shift token generation computations to GPUs for better performance, rather than relying solely on CPUs.
Moreover, this has been a valuable learning experience for me. I have gained insights into how the open-source community collaborates to optimize and deploy these models as efficiently as possible.
Kimi K2 stands out as one of the top open-source models, approaching the capabilities of models like DeepSeek R1, with state-of-the-art performance in frontier knowledge, math, and coding among non-thinking models.
It is particularly strong in tool selection and agentic tasks, making it a cost-effective alternative to premium models like Claude 4 Sonnet for coding projects or vibe coding.
You can serve the quantized version of the Kimi K2 for your in-house solutions using this guide. Llama.cpp allows you to serve the language models as an API with OpenAI compatibility. To keep learning more, be sure to check out our Kimi K2 guide with examples. If you’re keen to learn about agentic AI, make sure to take our new course on building multi-agent systems with LangGraph.
Top AI Courses
Course
Course
Course
Tutorial
Bex Tuychiev
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
François Aubry
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan