
Curso
Trabajar con Llama 3
2 h
13.8K
Kimi K2, desarrollado por Moonshot AI, es un modelo lingüístico de última generación basado en la mezcla de expertos (MoE, por sus siglas en inglés). Destaca en tareas relacionadas con conocimientos punteros, razonamiento y codificación, y está especialmente optimizado para capacidades agenticas, como el uso de herramientas y la resolución autónoma de problemas.
Como exploramos en nuestra guía de Kimi K2, el modelo está obteniendo resultados de referencia excepcionales, lo que lo convierte en el mejor modelo de lenguaje de código abierto para uso general. Estamos siendo testigos de la momento del Deepseek R1, y para celebrarlo, te enseñaré cómo ejecutar este enorme modelo de 1 terabyte en una sola GPU.
Aprenderemos a configurar el dispositivo Runpod, instalar llama.cpp y descargar el modelo a mayor velocidad. Además, ejecutaremos el modelo utilizando la CLI llama.cpp, descargando las capas del modelo a la RAM. Por último, abordaremos los problemas comunes que surgen al ejecutar estos modelos.
Ve a la nube GPU de Runpod y crea una nube con la máquina A100 SXM utilizando la imagen de contenedor Python versión 2.8.0.
A continuación, aumenta el almacenamiento del disco del contenedor a 300 GB mediante la opción Editar pod.
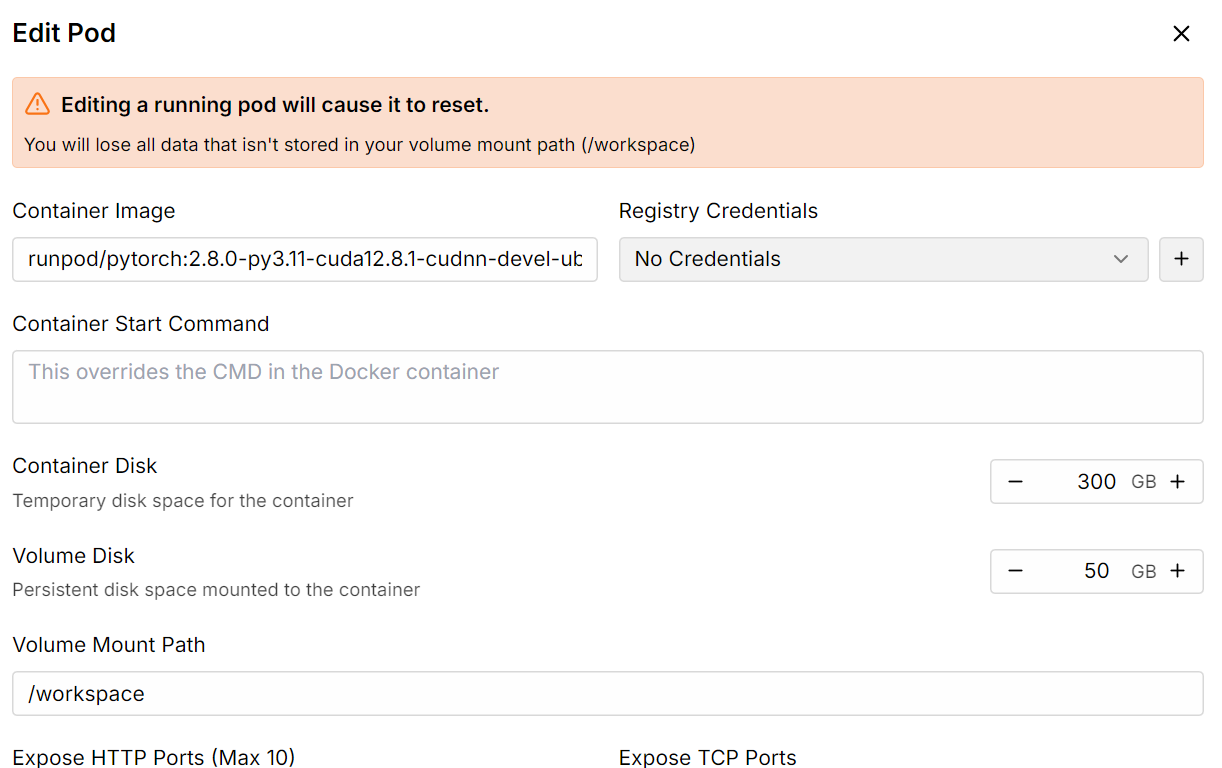
Una vez que todo esté configurado, verás que tienes 300 GB de almacenamiento, lo cual es suficiente, ya que nuestro modelo cuantificado de 1 bit requiere 250 GB de almacenamiento.
1. Haz clic en el botón «Conectar» y abre la instancia de Jupyter Lab. Crea un nuevo cuaderno e instala las herramientas Linux necesarias, como cmake y curl.
!apt-get update
!apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
2. Cambia el directorio a la raíz. No utilizaremos el directorio del espacio de trabajo. El motivo es aumentar tanto la velocidad de descarga como la de carga del modelo. Encontrarás más información al respecto en la sección de resolución de problemas al final del documento.
%cd ..3. Clona la última versión del repositorio llama.cpp.
!git clone https://github.com/ggml-org/llama.cpp
4. Configura las opciones de compilación. Estamos ejecutando la compilación para una máquina con GPU. Si deseas utilizar la inferencia de CPU, cambia DGGML_CUDA=ON por DGGML_CUDA=OFF.
!cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES="80;90" \
-DCMAKE_CUDA_FLAGS="-Wno-deprecated-gpu-targets"
5. Usaremos el comando « cmake » para compilar las herramientas: « llama-quantize », « llama-cli », « llama-gguf-split » y « llama-mtmd-cli ».
!cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split llama-mtmd-cli
6. Copia todas las herramientas de compilación al repositorio principal para que podamos acceder a ellas fácilmente.
!cp llama.cpp/build/bin/llama-* llama.cppLas versiones cuantificadas del modelo Kimi K2 de Unsloth son compatibles con xnet, lo que permite descargas y cargas cuatro veces más rápidas que Git LFS. Para activarlo localmente, instala la última versión de huggingface_hub y hf_transfer:
!pip install huggingface_hub hf_transfer
Utiliza la API snapshot_download para descargar solo los archivos del modelo GGUF cuantificados en 1 bit para el repositorio:
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/Kimi-K2-Instruct-GGUF",
local_dir = "/unsloth/Kimi-K2-Instruct-GGUF",
allow_patterns = ["*UD-TQ1_0*"],
)La descarga tardará unos minutos, dependiendo de tu conexión a Internet y de la velocidad de tu dispositivo.
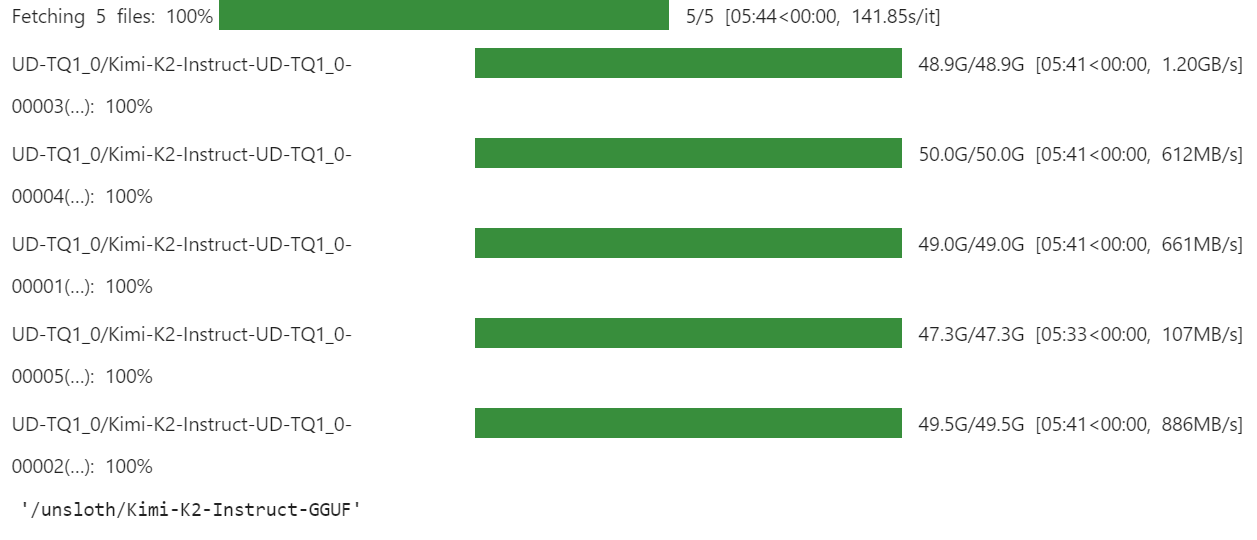
Para nosotros fue muy rápido, ya que contamos con soluciones de almacenamiento más rápidas con xnet habilitado.
Es hora de probar nuestra versión cuantificada del modelo. Esta es la parte en la que he pasado más tiempo depurando, ya que estoy intentando ejecutarlo en una sola GPU. Aunque esto no es imposible, plantea varios problemas relacionados con la carga y la ejecución del modelo.
Estamos utilizando todos los subprocesos de la CPU y maximizando la carga de capas en la GPU, lo que implica la descarga de la CPU de las capas de proyección ascendente y descendente de Mixture of Experts.
Este es el comando que estamos ejecutando en la terminal, que funciona correctamente:
./llama.cpp/llama-cli \
--model /unsloth/Kimi-K2-Instruct-GGUF/UD-TQ1_0/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--cache-type-k q4_0 \
--threads -1 \
--n-gpu-layers 99 \
--temp 0.6 \
--min_p 0.01 \
--ctx-size 16384 \
--seed 3407 \
-ot ".ffn_(up|down)_exps.=CPU" \
--prompt "Hey"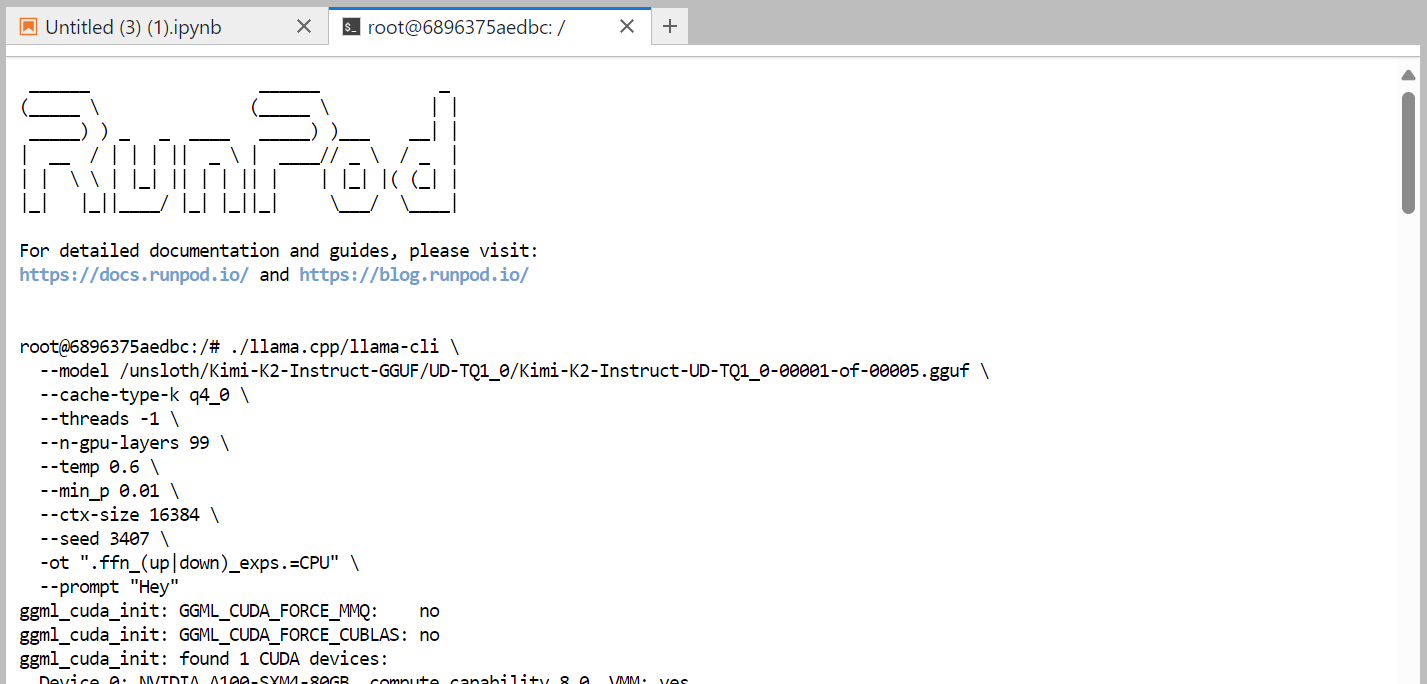
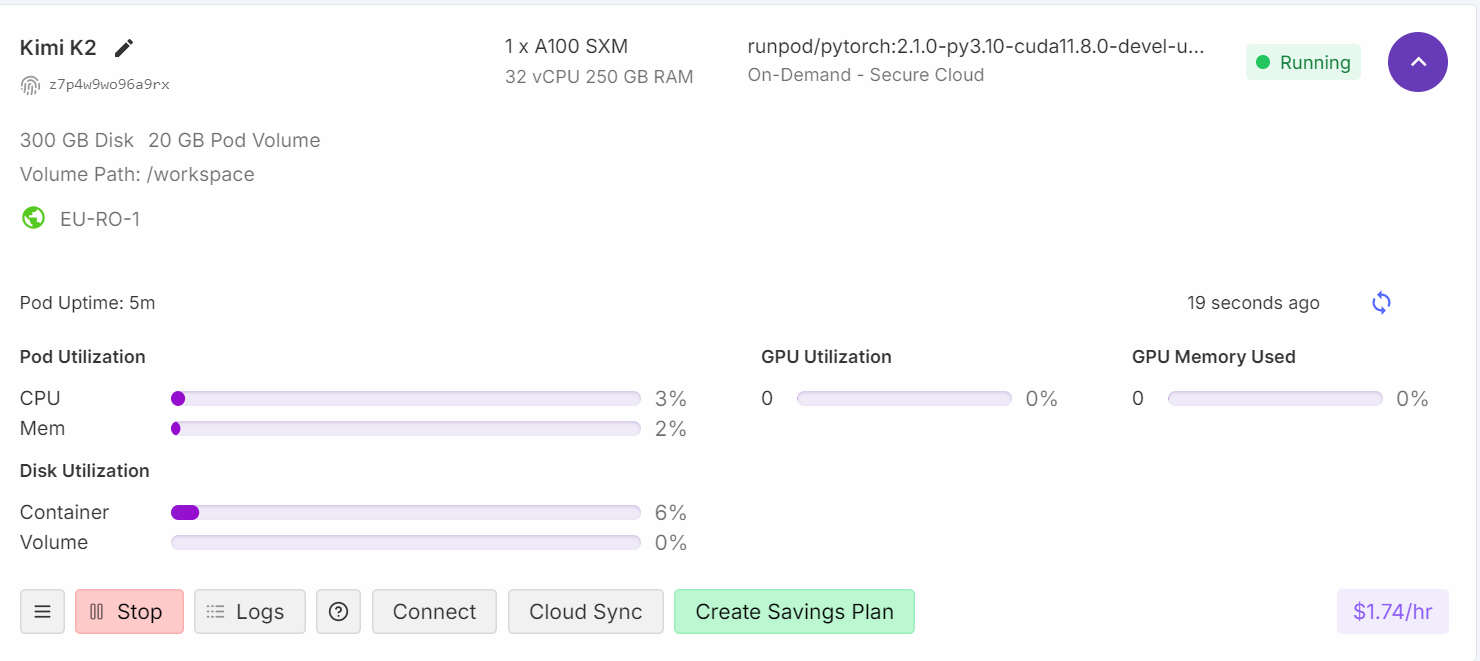
Se tardó casi un minuto en cargar el modelo completo. Como podemos ver, el modelo encaja perfectamente en la máquina.

Si compruebas el panel de control de Runpod, verás que el uso de la CPU es elevado y que se está utilizando tanto la memoria RAM como la VRAM.
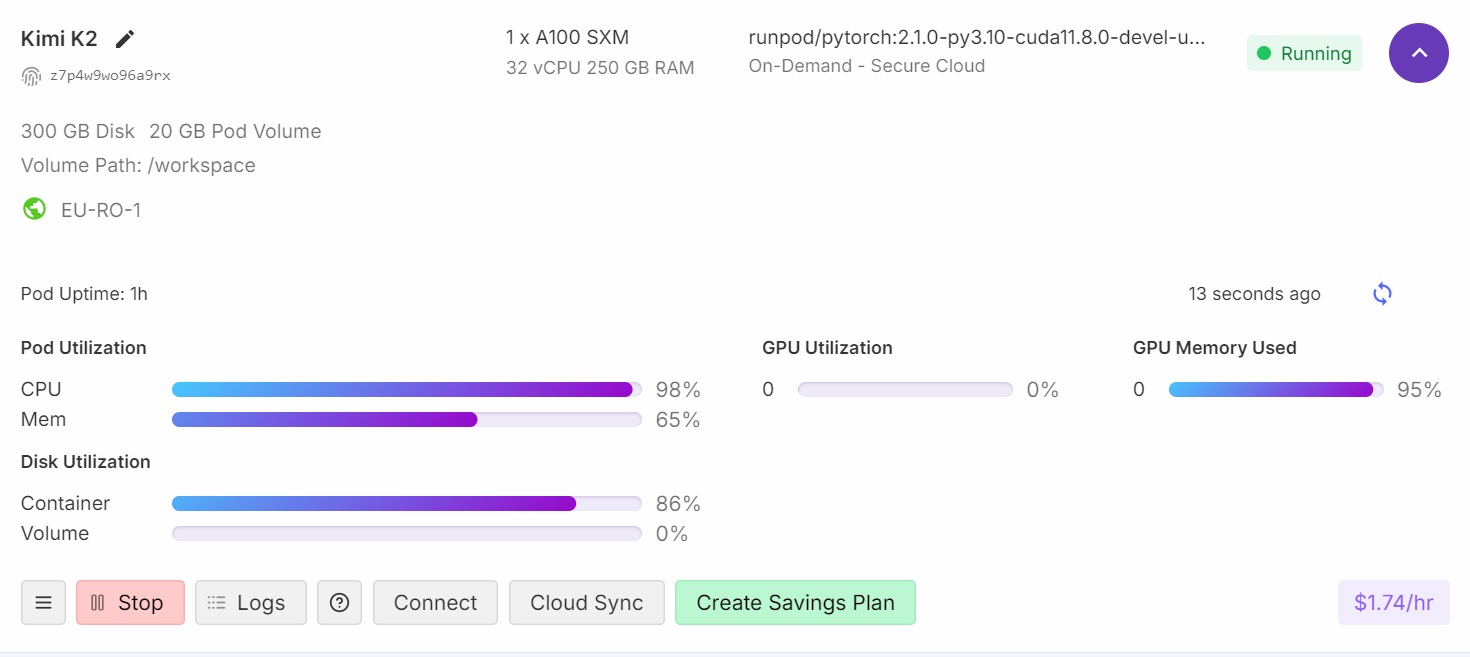
Después de unos cuatro minutos de carga y calentamiento, estarás listo para hacer preguntas al modelo.

Te hice una pregunta sencilla: ¿Qué es el monzón? Escribe la respuesta en una línea."

Se tardó casi cinco minutos en completar la generación.
Investigué un poco sobre por qué la generación de tokens es lenta y resulta que la GPU solo se utiliza como memoria, mientras que todo el procesamiento lo realiza la CPU. Para solucionar este problema, debes descargar más capas a la GPU, lo que significa que necesitarás dos máquinas A100.
En esta sección, analizaremos los problemas más comunes que se encuentran al ejecutar un modelo grande en una sola GPU y cómo puedes solucionarlos.
Cuando ves un uso del 95 % de la RAM de la GPU, un 0 % de computación de la GPU y una carga del 99 % de la CPU, normalmente significa que la VRAM está actuando como almacenamiento de memoria para el modelo, mientras que el procesamiento real se está llevando a cabo en la CPU.
Incluso los modelos altamente cuantificados y más pequeños de 1 bit deben cargarse en la memoria, lo que contribuye al uso de VRAM. La utilización de la GPU para el cálculo solo comenzará a producirse si descargas más capas a la VRAM.
Para mejorar la velocidad de generación de tokens, debes descargar más capas del modelo a la GPU. Quizás podrías considerar una configuración con varias GPU, como tres GPU A100. Establece la temperatura en 0,6 para ayudar a reducir la repetición y la incoherencia en el texto generado.
Si tienes una VRAM o RAM limitada, puedes seguir ejecutando modelos de 1 bit en una CPU de consumo. Sin embargo, la generación de tokens será muy lenta (por ejemplo, 1 token cada 20 segundos).
El único requisito estricto para ejecutar modelos de 1 bit es que el espacio total en disco + RAM + VRAM sea superior o igual a 250 GB.
Para obtener un rendimiento óptimo (más de 5 tokens por segundo), necesitarás al menos 250 GB de memoria unificada o una combinación de 250 GB de RAM y VRAM.
Instala la última versión de huggingface_hub y hf_transfer para acceder a «xnet speed», que es cuatro veces más rápido que el sencillo Git LFS.
Para optimizar el almacenamiento y la carga de archivos fragmentados GGUF, se recomienda utilizar un disco contenedor para el almacenamiento en lugar de un volumen contenedor. Esto se debe a que el volumen de los contenedores puede ralentizar la descarga y la carga del modelo.
La carga lenta de un modelo suele indicar que estás cargando un modelo muy grande. La carga de modelos desde el almacenamiento en red puede ralentizar considerablemente el proceso de carga. Utiliza siempre una unidad SSD M.2 local para almacenar tus modelos. Los SSD M.2 ofrecen velocidades de lectura/escritura mucho más rápidas en comparación con los discos duros tradicionales o el almacenamiento en red, lo que reduce drásticamente los tiempos de carga.
Si no hay suficiente RAM para cargar el modelo, el sistema operativo podría empezar a intercambiar datos al disco (utilizando un archivo de intercambio), lo cual es mucho más lento que la RAM y crea un cuello de botella. Intenta tener una configuración con varias GPU y más RAM.
La ejecución de versiones cuantificadas de Kimi K2 aún puede presentar dificultades, ya que herramientas como llama.cpp están evolucionando activamente para mantenerse al día con las últimas actualizaciones del modelo. En las próximas semanas, esperen soluciones mejoradas que trasladen los cálculos de generación de tokens a las GPU para obtener un mejor rendimiento, en lugar de depender únicamente de las CPU.
Además, ha sido una experiencia muy valiosa para mí. He adquirido conocimientos sobre cómo la comunidad de código abierto colabora para optimizar e implementar estos modelos de la forma más eficiente posible.
Kimi K2 destaca como uno de los mejores modelos de código abierto, acercándose a las capacidades de modelos como DeepSeek R1, con un rendimiento de vanguardia en conocimientos de frontera, matemáticas y codificación entre los modelos no pensantes.
Es especialmente eficaz en la selección de herramientas y tareas de agencia, lo que lo convierte en una alternativa rentable a modelos premium como Claude 4 Sonnet para proyectos de codificación o codificación vibe.
Puedes ofrecer la versión cuantificada de Kimi K2 para tus soluciones internas siguiendo esta guía. Llama.cpp te permite ofrecer los modelos de lenguaje como una API compatible con OpenAI. Para seguir aprendiendo, no te pierdas nuestra guía de Kimi K2 con ejemplos. Si te interesa aprender sobre la IA agencial, no te pierdas nuestro nuevo curso sobre creación de sistemas multiagente con LangGraph.
Los mejores cursos de IA
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita



