
Kurs
Biomedical Image Analysis in Python
4 Std.
23.4K
SAM2 ist ein von Meta entwickeltes Basismodell für die prompte visuelle Segmentierung in Bildern und Videos. Anders als sein Vorgänger, SAMdas sich hauptsächlich auf statische Bilder konzentrierte, ist SAM2 so konzipiert, dass es auch die Komplexität der Videosegmentierung bewältigen kann.
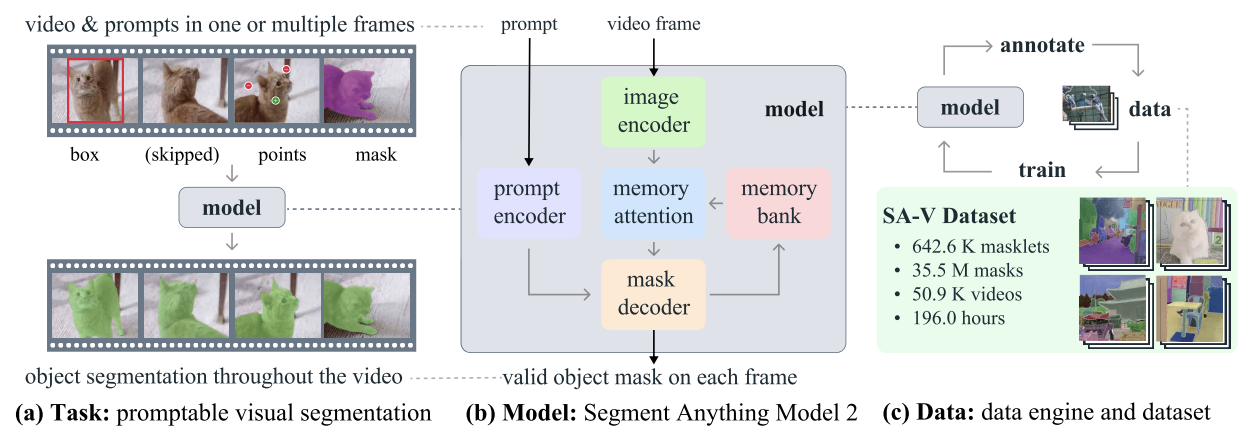
SAM2 - Aufgabe, Modell und Daten (Quelle: Ravi et al., 2024)
Es verwendet eine Transformator-Architektur mit einem Streaming-Speicher, der die Videoverarbeitung in Echtzeit ermöglicht. Für das Training von SAM 2 wurde ein umfangreicher und vielfältiger Datensatz verwendet, der den neuen SA-V-Datensatz mit mehr als 600.000 Masklet-Annotationen in 51.000 Videos enthält.
Seine Daten-Engine, die eine interaktive Datenerfassung und Modellverbesserung ermöglicht, gibt dem Modell die Fähigkeit, alles Mögliche zu segmentieren. Diese Engine ermöglicht es SAM 2, kontinuierlich zu lernen und sich anzupassen, sodass es effizienter mit neuen und schwierigen Daten umgehen kann. Bei domänenspezifischen Aufgaben oder seltenen Objekten ist eine Feinabstimmung jedoch unerlässlich, um eine optimale Leistung zu erzielen.
Im Zusammenhang mit SAM 2 ist Feintuning der Prozess des weiteren Trainings des vortrainierten SAM 2-Modells auf einem bestimmten Datensatz, um seine Leistung für eine bestimmte Aufgabe oder Domäne zu verbessern. SAM 2 ist zwar ein leistungsfähiges Werkzeug, das auf einem breiten und vielfältigen Datensatz trainiert wurde, aber seine Allgemeingültigkeit führt nicht immer zu optimalen Ergebnissen bei speziellen oder seltenen Aufgaben.
Wenn du zum Beispiel an einem medizinischen Bildgebungsprojekt arbeitest, das die Identifizierung bestimmter Tumorarten erfordert, könnte die Leistung des Modells aufgrund seines allgemeinen Trainings zu gering sein.
Der Feinabstimmungsprozess
Das Feintuning von SAM 2 behebt diese Einschränkung, indem es dir ermöglicht, das Modell an deinen spezifischen Datensatz anzupassen. Dieser Prozess verbessert die Genauigkeit des Modells und macht es effektiver für deinen speziellen Anwendungsfall.
Hier sind die wichtigsten Vorteile der Feinabstimmung von SAM 2:
Um mit der Feinabstimmung von SAM 2 zu beginnen, musst du die folgenden Voraussetzungen erfüllen:
Software und andere Anforderungen:
Die Qualität deines Datensatzes ist entscheidend für die Feinabstimmung des SAM 2-Modells. Qualitativ hochwertige kommentierte Bilder oder Videos mit genauen Segmentierungsmasken sind entscheidend für eine optimale Leistung. Genaue Annotationen ermöglichen es dem Modell, die richtigen Merkmale zu lernen, was zu einer besseren Segmentierungsgenauigkeit und Robustheit in realen Anwendungen führt.
Der erste Schritt ist die Beschaffung des Datensatzes, der das Rückgrat des Trainingsprozesses bildet. Wir haben unsere Daten von Kaggleeiner zuverlässigen Plattform, die eine Vielzahl von Datensätzen bereitstellt. Über die Kaggle-API luden wir die Daten im gewünschten Format herunter und stellten so sicher, dass die Bilder und die entsprechenden Segmentierungsmasken für die weitere Bearbeitung zur Verfügung standen.
Nachdem wir die Datensätze heruntergeladen hatten, führten wir die folgenden Schritte durch:
Da das SAM2-Modell Eingaben in bestimmten Formaten benötigt, haben wir die Daten wie folgt konvertiert:
Die bearbeiteten Bilder und Masken werden dann in entsprechenden Ordnern organisiert, damit du bei der Feinabstimmung leicht darauf zugreifen kannst. Zusätzlich werden die Pfade zu diesen Bildern und Masken in eine CSV-Datei (train.csv ) geschrieben, um das Laden der Daten während des Trainings zu erleichtern.
Der letzte Schritt war die Validierung des Datensatzes, um seine Genauigkeit zu gewährleisten:
Hier ist ein schnelles Notizbuch, das dich durch den Code für die Erstellung von Datensätzen führt. Du kannst entweder diesen Weg der Datenerstellung gehen oder direkt einen online verfügbaren Datensatz im gleichen Format wie in den Voraussetzungen angegeben verwenden.
Segment Anything Model 2 enthält mehrere Komponenten, aber der Haken an der Sache ist, dass man für eine schnellere Feinabstimmung nur die leichtgewichtigen Komponenten wie den Maskendecoder und den Prompt-Encoder trainiert und nicht das gesamte Modell. Die Schritte zur Feinabstimmung dieses Modells sind wie folgt:
Um mit der Feinabstimmung zu beginnen, müssen wir die SAM-2 Bibliothek installieren, die für das Segment Anything Model (SAM2) entscheidend ist. Dieses Modell wurde entwickelt, um verschiedene Segmentierungsaufgaben effektiv zu bewältigen. Die Installation umfasst das Klonen des SAM-2-Repositorys von GitHub und die Installation der notwendigen Abhängigkeiten.
!git clone https://github.com/facebookresearch/segment-anything-2
%cd /content/segment-anything-2
!pip install -q -e .Dieses Codeschnipsel stellt sicher, dass die SAM2-Bibliothek korrekt installiert und für unseren Feinabstimmungs-Workflow einsatzbereit ist.
Sobald die SAM-2-Bibliothek installiert ist, müssen wir im nächsten Schritt den Datensatz erwerben, den wir für die Feinabstimmung verwenden werden. Wir verwenden einen Datensatz, der auf Kaggle verfügbar ist, und zwar einen Datensatz zur Segmentierung von Brustkorb-CTs, der Bilder und Masken von Lunge, Herz und Luftröhre enthält.
Der Datensatz enthält:
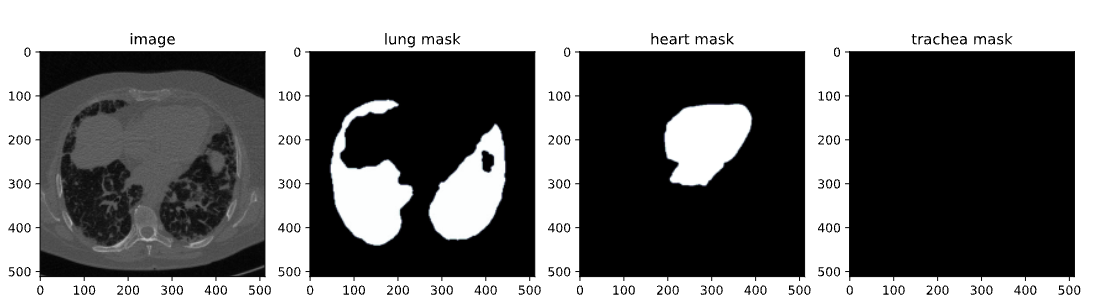
Bild aus dem CT-Scan-Datensatz
In diesem Blog werden wir nur Bilder und Masken von Lungen für die Segmentierung verwenden. Mit der Kaggle-API können wir Datensätze direkt in unsere Umgebung herunterladen. Wir beginnen mit dem Hochladen der kaggle.json Datei von Kaggle, um einfach auf jeden Datensatz zugreifen zu können.
Um kaggle.json zu erhalten, gehe auf die Registerkarte Einstellungen in deinem Benutzerprofil und wähle Neues Token erstellen. Dadurch wird der Kaggle-Download ausgelöst. json, eine Datei mit deinen API-Anmeldedaten.
# get dataset from Kaggle
from google.colab import files
files.upload() # This will prompt you to upload the kaggle.json file
!mkdir -p ~/.kaggle
!mv kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d polomarco/chest-ct-segmentationEntpacke die Daten:
!unzip chest-ct-segmentation.zip -d chest-ct-segmentationWenn der Datensatz fertig ist, können wir mit der Feinabstimmung beginnen. Wie ich bereits erwähnt habe, liegt der Schlüssel dazu darin, nur die leichtgewichtigen Komponenten von SAM2, wie den Maskendecoder und den Prompt-Encoder, und nicht das gesamte Modell fein abzustimmen. Dieser Ansatz ist effizienter und erfordert weniger Ressourcen.
Für die Feinabstimmung müssen wir mit vortrainierten SAM2-Modellgewichten beginnen. Diese Gewichte, "Checkpoints" genannt, sind der Ausgangspunkt für das weitere Training. Die Kontrollpunkte wurden auf einer Vielzahl von Bildern trainiert. Durch eine Feinabstimmung auf unseren speziellen Datensatz können wir eine bessere Leistung bei unseren Zielaufgaben erzielen.
!wget -O sam2_hiera_tiny.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt"
!wget -O sam2_hiera_small.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt"
!wget -O sam2_hiera_base_plus.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt"
!wget -O sam2_hiera_large.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt"In diesem Schritt laden wir verschiedene SAM-2 Checkpoints herunter, die verschiedenen Modellgrößen entsprechen (z.B. tiny, small, base_plus, large). Die Wahl des Kontrollpunkts kann je nach den verfügbaren Rechenressourcen und der jeweiligen Aufgabe angepasst werden.
Wenn du den Datensatz heruntergeladen hast, musst du ihn im nächsten Schritt für das Training vorbereiten. Dabei wird der Datensatz in einen Trainings- und einen Testdatensatz aufgeteilt und es werden Datenstrukturen erstellt, die bei der Feinabstimmung in das SAM 2-Modell eingespeist werden können.
%cd /content/segment-anything-2
import os
import pandas as pd
import cv2
import torch
import torch.nn.utils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from sklearn.model_selection import train_test_split
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
# Path to the chest-ct-segmentation dataset folder
data_dir = "/content/segment-anything-2/chest-ct-segmentation"
images_dir = os.path.join(data_dir, "images/images")
masks_dir = os.path.join(data_dir, "masks/masks")
# Load the train.csv file
train_df = pd.read_csv(os.path.join(data_dir, "train.csv"))
# Split the data into two halves: one for training and one for testing
train_df, test_df = train_test_split(train_df, test_size=0.2, random_state=42)
# Prepare the training data list
train_data = []
for index, row in train_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
train_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
# Prepare the testing data list (if needed for inference or evaluation later)
test_data = []
for index, row in test_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
test_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
Wir teilen den Datensatz in einen Trainingssatz (80%) und einen Testsatz (20%) auf, um sicherzustellen, dass wir die Leistung des Modells nach dem Training bewerten können. Die Trainingsdaten werden für die Feinabstimmung des SAM 2-Modells verwendet, während die Testdaten für die Inferenz und die Auswertung genutzt werden.
Nachdem du deinen Datensatz in einen Trainings- und einen Testdatensatz aufgeteilt hast, geht es im nächsten Schritt darum, binäre Masken zu erstellen, Schlüsselpunkte innerhalb dieser Masken auszuwählen und diese Elemente zu visualisieren, um sicherzustellen, dass die Daten korrekt verarbeitet werden.
1. Bilder lesen und ihre Größe ändern: Der Prozess beginnt mit der zufälligen Auswahl eines Bildes und der dazugehörigen Maske aus dem Datensatz. Das Bild wird vom BGR- in das RGB-Format umgewandelt, das das Standard-Farbformat für die meisten Deep Learning-Modelle ist. Die entsprechende Beschriftung (Maske) wird im Graustufenmodus gelesen. Dann werden sowohl das Bild als auch die Anmerkungsmaske auf eine maximale Größe von 1024 Pixeln verkleinert, wobei das Seitenverhältnis beibehalten wird, um sicherzustellen, dass die Daten in die Eingabeanforderungen des Modells passen und die Rechenlast reduziert wird.
def read_batch(data, visualize_data=False):
# Select a random entry
ent = data[np.random.randint(len(data))]
# Get full paths
Img = cv2.imread(ent["image"])[..., ::-1] # Convert BGR to RGB
ann_map = cv2.imread(ent["annotation"], cv2.IMREAD_GRAYSCALE) # Read annotation as grayscale
if Img is None or ann_map is None:
print(f"Error: Could not read image or mask from path {ent['image']} or {ent['annotation']}")
return None, None, None, 0
# Resize image and mask
r = np.min([1024 / Img.shape[1], 1024 / Img.shape[0]]) # Scaling factor
Img = cv2.resize(Img, (int(Img.shape[1] * r), int(Img.shape[0] * r)))
ann_map = cv2.resize(ann_map, (int(ann_map.shape[1] * r), int(ann_map.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
2. Binarisierung von Segmentierungsmasken: Die Multi-Klassen-Maske (die mehrere Objektklassen mit unterschiedlichen Pixelwerten enthalten kann) wird in eine binäre Maske umgewandelt. Diese Maske hebt alle interessanten Bereiche des Bildes hervor und vereinfacht die Segmentierungsaufgabe auf ein binäres Klassifizierungsproblem: Objekt vs. Hintergrund. Die binäre Maske wird dann mit einem 5x5-Kernel erodiert.
Durch die Erosion wird die Maske leicht verkleinert, was dazu beiträgt, Randeffekte bei der Auswahl von Punkten zu vermeiden. Dadurch wird sichergestellt, dass die ausgewählten Punkte im Inneren des Objekts liegen und nicht in der Nähe der Ränder, die verrauscht oder mehrdeutig sein könnten.
Die Schlüsselpunkte werden innerhalb der erodierten Maske ausgewählt. Diese Punkte dienen während des Feinabstimmungsprozesses als Anhaltspunkte, die dem Modell zeigen, worauf es sich konzentrieren soll. Die Punkte werden zufällig aus dem Inneren der Objekte ausgewählt, um sicherzustellen, dass sie repräsentativ sind und nicht durch verrauschte Grenzen beeinflusst werden.
### Continuation of read_batch() ###
# Initialize a single binary mask
binary_mask = np.zeros_like(ann_map, dtype=np.uint8)
points = []
# Get binary masks and combine them into a single mask
inds = np.unique(ann_map)[1:] # Skip the background (index 0)
for ind in inds:
mask = (ann_map == ind).astype(np.uint8) # Create binary mask for each unique index
binary_mask = np.maximum(binary_mask, mask) # Combine with the existing binary mask
# Erode the combined binary mask to avoid boundary points
eroded_mask = cv2.erode(binary_mask, np.ones((5, 5), np.uint8), iterations=1)
# Get all coordinates inside the eroded mask and choose a random point
coords = np.argwhere(eroded_mask > 0)
if len(coords) > 0:
for _ in inds: # Select as many points as there are unique labels
yx = np.array(coords[np.random.randint(len(coords))])
points.append([yx[1], yx[0]])
points = np.array(points)
3. Visualisierung: Dieser Schritt ist wichtig, um zu überprüfen, ob die Schritte zur Datenvorverarbeitung korrekt ausgeführt wurden. Indem du die Punkte auf der binarisierten Maske visuell überprüfst, kannst du sicherstellen, dass das Modell während des Trainings den richtigen Input erhält. Schließlich wird die binäre Maske umgestaltet und korrekt formatiert (mit Abmessungen, die für die Modelleingabe geeignet sind), und die Punkte werden für die weitere Verwendung im Trainingsprozess ebenfalls umgestaltet. Die Funktion gibt das verarbeitete Bild, die binäre Maske, die ausgewählten Punkte und die Anzahl der gefundenen Masken zurück.
### Continuation of read_batch() ###
if visualize_data:
# Plotting the images and points
plt.figure(figsize=(15, 5))
# Original Image
plt.subplot(1, 3, 1)
plt.title('Original Image')
plt.imshow(img)
plt.axis('off')
# Segmentation Mask (binary_mask)
plt.subplot(1, 3, 2)
plt.title('Binarized Mask')
plt.imshow(binary_mask, cmap='gray')
plt.axis('off')
# Mask with Points in Different Colors
plt.subplot(1, 3, 3)
plt.title('Binarized Mask with Points')
plt.imshow(binary_mask, cmap='gray')
# Plot points in different colors
colors = list(mcolors.TABLEAU_COLORS.values())
for i, point in enumerate(points):
plt.scatter(point[0], point[1], c=colors[i % len(colors)], s=100, label=f'Point {i+1}') # Corrected to plot y, x order
# plt.legend()
plt.axis('off')
plt.tight_layout()
plt.show()
binary_mask = np.expand_dims(binary_mask, axis=-1) # Now shape is (1024, 1024, 1)
binary_mask = binary_mask.transpose((2, 0, 1))
points = np.expand_dims(points, axis=1)
# Return the image, binarized mask, points, and number of masks
return img, binary_mask, points, len(inds)
# Visualize the data
Img1, masks1, points1, num_masks = read_batch(train_data, visualize_data=True)
Der obige Code liefert die folgende Abbildung, die das Originalbild aus dem Datensatz zusammen mit seiner binarisierten Maske und der binarisierten Maske mit Punkten enthält.

Originalbild, binarisierte Maske und binarisierte Maske mit Punkten für den Datensatz.
Die Feinabstimmung des SAM2-Modells umfasst mehrere Schritte, darunter das Laden des Modells, das Einrichten des Optimierers und des Schedulers sowie die iterative Aktualisierung der Modellgewichte anhand der Trainingsdaten.
Lade die Modellprüfpunkte:
sam2_checkpoint = "sam2_hiera_small.pt" # @param ["sam2_hiera_tiny.pt", "sam2_hiera_small.pt", "sam2_hiera_base_plus.pt", "sam2_hiera_large.pt"]
model_cfg = "sam2_hiera_s.yaml" # @param ["sam2_hiera_t.yaml", "sam2_hiera_s.yaml", "sam2_hiera_b+.yaml", "sam2_hiera_l.yaml"]
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
predictor = SAM2ImagePredictor(sam2_model)
Wir beginnen mit der Erstellung des SAM2-Modells unter Verwendung der vorher trainierten Checkpoints. Das Modell wird dann in eine Prädikatorenklasse verpackt, was das Einstellen von Bildern, das Kodieren von Prompts und das Dekodieren von Masken vereinfacht.
Wir konfigurieren mehrere Hyperparameter, um sicherzustellen, dass das Modell effektiv lernt, z. B. die Lernrate, den Gewichtsabfall und die Gradientenakkumulationsschritte. Diese Hyperparameter steuern den Lernprozess, z. B. wie schnell das Modell seine Gewichte aktualisiert und wie es ein Overfitting vermeidet. Du kannst gerne damit herumspielen.
# Train mask decoder.
predictor.model.sam_mask_decoder.train(True)
# Train prompt encoder.
predictor.model.sam_prompt_encoder.train(True)
# Configure optimizer.
optimizer=torch.optim.AdamW(params=predictor.model.parameters(),lr=0.0001,weight_decay=1e-4) #1e-5, weight_decay = 4e-5
# Mix precision.
scaler = torch.cuda.amp.GradScaler()
# No. of steps to train the model.
NO_OF_STEPS = 3000 # @param
# Fine-tuned model name.
FINE_TUNED_MODEL_NAME = "fine_tuned_sam2"
Der Optimierer ist für die Aktualisierung der Modellgewichte zuständig, während der Scheduler die Lernrate während des Trainings anpasst, um die Konvergenz zu verbessern. Durch die Feinabstimmung dieser Parameter können wir eine bessere Segmentierungsgenauigkeit erreichen.
Der eigentliche Feinabstimmungsprozess ist iterativ. In jedem Schritt wird ein Stapel von Bildern und Masken für die Lunge durch das Modell geleitet, der Verlust berechnet und zur Aktualisierung der Modellgewichte verwendet.
# Initialize scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=500, gamma=0.2) # 500 , 250, gamma = 0.1
accumulation_steps = 4 # Number of steps to accumulate gradients before updating
for step in range(1, NO_OF_STEPS + 1):
with torch.cuda.amp.autocast():
image, mask, input_point, num_masks = read_batch(train_data, visualize_data=False)
if image is None or mask is None or num_masks == 0:
continue
input_label = np.ones((num_masks, 1))
if not isinstance(input_point, np.ndarray) or not isinstance(input_label, np.ndarray):
continue
if input_point.size == 0 or input_label.size == 0:
continue
predictor.set_image(image)
mask_input, unnorm_coords, labels, unnorm_box = predictor._prep_prompts(input_point, input_label, box=None, mask_logits=None, normalize_coords=True)
if unnorm_coords is None or labels is None or unnorm_coords.shape[0] == 0 or labels.shape[0] == 0:
continue
sparse_embeddings, dense_embeddings = predictor.model.sam_prompt_encoder(
points=(unnorm_coords, labels), boxes=None, masks=None,
)
batched_mode = unnorm_coords.shape[0] > 1
high_res_features = [feat_level[-1].unsqueeze(0) for feat_level in predictor._features["high_res_feats"]]
low_res_masks, prd_scores, _, _ = predictor.model.sam_mask_decoder(
image_embeddings=predictor._features["image_embed"][-1].unsqueeze(0),
image_pe=predictor.model.sam_prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=True,
repeat_image=batched_mode,
high_res_features=high_res_features,
)
prd_masks = predictor._transforms.postprocess_masks(low_res_masks, predictor._orig_hw[-1])
gt_mask = torch.tensor(mask.astype(np.float32)).cuda()
prd_mask = torch.sigmoid(prd_masks[:, 0])
seg_loss = (-gt_mask * torch.log(prd_mask + 0.000001) - (1 - gt_mask) * torch.log((1 - prd_mask) + 0.00001)).mean()
inter = (gt_mask * (prd_mask > 0.5)).sum(1).sum(1)
iou = inter / (gt_mask.sum(1).sum(1) + (prd_mask > 0.5).sum(1).sum(1) - inter)
score_loss = torch.abs(prd_scores[:, 0] - iou).mean()
loss = seg_loss + score_loss * 0.05
# Apply gradient accumulation
loss = loss / accumulation_steps
scaler.scale(loss).backward()
# Clip gradients
torch.nn.utils.clip_grad_norm_(predictor.model.parameters(), max_norm=1.0)
if step % accumulation_steps == 0:
scaler.step(optimizer)
scaler.update()
predictor.model.zero_grad()
# Update scheduler
scheduler.step()
if step % 500 == 0:
FINE_TUNED_MODEL = FINE_TUNED_MODEL_NAME + "_" + str(step) + ".torch"
torch.save(predictor.model.state_dict(), FINE_TUNED_MODEL)
if step == 1:
mean_iou = 0
mean_iou = mean_iou * 0.99 + 0.01 * np.mean(iou.cpu().detach().numpy())
if step % 100 == 0:
print("Step " + str(step) + ":\t", "Accuracy (IoU) = ", mean_iou)
Bei jeder Iteration verarbeitet das Modell eine Reihe von Bildern, berechnet die Segmentierungsmasken und vergleicht sie mit der Grundwahrheit, um den Verlust zu berechnen. Dieser Verlust wird dann verwendet, um die Modellgewichte anzupassen und so die Leistung des Modells schrittweise zu verbessern. Nach einem Training von etwa 3000 Epochen erhalten wir eine Genauigkeit (IoU - Intersection over Union) von etwa 72%.
Das Modell kann dann für Inferenzen verwendet werden, bei denen es Segmentierungsmasken für neue, ungesehene Bilder vorhersagt. Beginne mit denHilfsfunktionen read_images und get_points, um das Inferenzbild und seine Maske mit den Schlüsselpunkten zu erhalten.
def read_image(image_path, mask_path): # read and resize image and mask
img = cv2.imread(image_path)[..., ::-1] # Convert BGR to RGB
mask = cv2.imread(mask_path, 0)
r = np.min([1024 / img.shape[1], 1024 / img.shape[0]])
img = cv2.resize(img, (int(img.shape[1] * r), int(img.shape[0] * r)))
mask = cv2.resize(mask, (int(mask.shape[1] * r), int(mask.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
return img, mask
def get_points(mask, num_points): # Sample points inside the input mask
points = []
coords = np.argwhere(mask > 0)
for i in range(num_points):
yx = np.array(coords[np.random.randint(len(coords))])
points.append([[yx[1], yx[0]]])
return np.array(points)Lade dann die Beispielbilder, die du für die Inferenz verwenden willst, zusammen mit den neu eingestellten Gewichten und führe die Inferenz mit den Einstellungen torch.no_grad().
# Randomly select a test image from the test_data
selected_entry = random.choice(test_data)
image_path = selected_entry['image']
mask_path = selected_entry['annotation']
# Load the selected image and mask
image, mask = read_image(image_path, mask_path)
# Generate random points for the input
num_samples = 30 # Number of points per segment to sample
input_points = get_points(mask, num_samples)
# Load the fine-tuned model
FINE_TUNED_MODEL_WEIGHTS = "fine_tuned_sam2_1000.torch"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
# Build net and load weights
predictor = SAM2ImagePredictor(sam2_model)
predictor.model.load_state_dict(torch.load(FINE_TUNED_MODEL_WEIGHTS))
# Perform inference and predict masks
with torch.no_grad():
predictor.set_image(image)
masks, scores, logits = predictor.predict(
point_coords=input_points,
point_labels=np.ones([input_points.shape[0], 1])
)
# Process the predicted masks and sort by scores
np_masks = np.array(masks[:, 0])
np_scores = scores[:, 0]
sorted_masks = np_masks[np.argsort(np_scores)][::-1]
# Initialize segmentation map and occupancy mask
seg_map = np.zeros_like(sorted_masks[0], dtype=np.uint8)
occupancy_mask = np.zeros_like(sorted_masks[0], dtype=bool)
# Combine masks to create the final segmentation map
for i in range(sorted_masks.shape[0]):
mask = sorted_masks[i]
if (mask * occupancy_mask).sum() / mask.sum() > 0.15:
continue
mask_bool = mask.astype(bool)
mask_bool[occupancy_mask] = False # Set overlapping areas to False in the mask
seg_map[mask_bool] = i + 1 # Use boolean mask to index seg_map
occupancy_mask[mask_bool] = True # Update occupancy_mask
# Visualization: Show the original image, mask, and final segmentation side by side
plt.figure(figsize=(18, 6))
plt.subplot(1, 3, 1)
plt.title('Test Image')
plt.imshow(image)
plt.axis('off')
plt.subplot(1, 3, 2)
plt.title('Original Mask')
plt.imshow(mask, cmap='gray')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.title('Final Segmentation')
plt.imshow(seg_map, cmap='jet')
plt.axis('off')
plt.tight_layout()
plt.show()In diesem Schritt verwenden wir das feinabgestimmte Modell, um Segmentierungsmasken für Testbilder zu erstellen. Die vorhergesagten Masken werden dann zusammen mit den Originalbildern und den echten Masken visualisiert, um die Leistung des Modells zu bewerten.

Endgültiges Segmentierungsbild auf Testdaten
Die Feinabstimmung von SAM2 bietet eine praktische Möglichkeit, seine Fähigkeiten für bestimmte Aufgaben zu verbessern. Egal, ob du an medizinischer Bildgebung, autonomen Fahrzeugen oder Videobearbeitung arbeitest, mit der Feinabstimmung kannst du SAM2 für deine individuellen Bedürfnisse nutzen. Wenn du diesen Leitfaden befolgst, kannst du SAM2 für deine Projekte anpassen und moderne Segmentierungsergebnisse erzielen.
Für fortgeschrittene Anwendungsfälle kannst du zusätzliche Komponenten von SAM2, wie z. B. den Bildkodierer, feinabstimmen. Das erfordert zwar mehr Ressourcen, bietet aber mehr Flexibilität und Leistungsverbesserungen.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Matt Crabtree
Tutorial
Allan Ouko

