
Lernpfad
Natürliche Sprachverarbeitung in Python
20 Std.
Wissenschaftliche Durchbrüche finden selten in einem Vakuum statt. Stattdessen sind sie oft die vorletzte Stufe einer Treppe, die auf angesammeltem menschlichen Wissen aufbaut. Um den Erfolg von großen Sprachmodellen (LLMs) wie chatGPT und Google Bart zu verstehen, müssen wir in der Zeit zurückgehen und über BERT sprechen.
Der BERT wurde 2018 von Google-Forschern entwickelt und ist einer der ersten LLMs. Mit ihren erstaunlichen Ergebnissen wurde sie schnell zu einer allgegenwärtigen Grundlage für NLP-Aufgaben, wie z.B. allgemeines Sprachverständnis, Frage & Antwort und Erkennung von benannten Entitäten.
Willst du mehr über LLMs erfahren? Beginne noch heute mit Kapitel 1 unseres Kurses Large Language Models (LLMs) Concepts.
Man kann mit Fug und Recht behaupten, dass das BERT den Weg für die generative KI-Revolution geebnet hat, die wir heute erleben. Obwohl der BERT einer der ersten LLMs war, wird er immer noch häufig eingesetzt. Tausende von kostenlosen und vortrainierten Open-Source-BERT-Modellen sind für bestimmte Anwendungsfälle verfügbar, z. B. für die Stimmungsanalyse, die Analyse klinischer Notizen und die Erkennung toxischer Kommentare.
Neugierig auf BERT? Lies den Artikel weiter, in dem wir die Architektur von Ber, das Innenleben der Technologie, einige ihrer realen Anwendungen und ihre Grenzen erkunden werden.
BERT (steht für Bidirectional Encoder Representations from Transformers) ist ein Open-Source-Modell, das 2018 von Google entwickelt wurde. Es war ein ehrgeiziges Experiment, um die Leistung des sogenannten Transformers - einer innovativen neuronalen Architektur, die von Google-Forschern 2017 in dem berühmten Paper Attention is All You Need vorgestellt wurde - bei natürlichsprachlichen (NLP) Aufgaben zu testen.
Der Schlüssel zum Erfolg von BERT ist seine Transformator-Architektur. Bevor Transformatoren zum Einsatz kamen, war die Modellierung natürlicher Sprache eine große Herausforderung. Trotz des Aufkommens hochentwickelter neuronaler Netze - namentlich rekurrenter oder faltungsorientierter neuronaler Netze - waren die Ergebnisse nur teilweise erfolgreich.
Die größte Herausforderung liegt in dem Mechanismus, den neuronale Netze verwenden, um das fehlende Wort in einem Satz vorherzusagen. Damals basierten moderne neuronale Netze auf der Encoder-Decoder-Architektur, einem leistungsstarken, aber zeit- und ressourcenintensiven Mechanismus, der sich nicht für parallele Berechnungen eignet.
Mit Blick auf diese Herausforderungen haben Google-Forscher den Transformator entwickelt, eine innovative neuronale Architektur, die auf dem Aufmerksamkeitsmechanismus basiert, wie im folgenden Abschnitt erläutert wird.
Schauen wir uns an, wie BERT funktioniert. Wir erklären die Technologie hinter dem Modell, wie es trainiert wird und wie es Daten verarbeitet.
Rekurrente und konvolutionäre neuronale Netze verwenden sequenzielle Berechnungen, um Vorhersagen zu erstellen. Das heißt, sie können vorhersagen, welches Wort auf eine bestimmte Wortfolge folgen wird, wenn sie auf großen Datensätzen trainiert wurden. In diesem Sinne wurden sie als unidirektionale oder kontextfreie Algorithmen betrachtet.
Im Gegensatz dazu sind transformatorgestützte Modelle wie BERT, die ebenfalls auf der Encoder-Decoder-Architektur basieren, bidirektional, da sie Wörter auf der Grundlage der vorherigen und der folgenden Wörter vorhersagen. Erreicht wird dies durch den Self-Attention-Mechanismus, eine Schicht, die sowohl im Encoder als auch im Decoder eingebaut ist. Das Ziel der Aufmerksamkeitsschicht ist es, die kontextuellen Beziehungen zwischen verschiedenen Wörtern im Eingabesatz zu erfassen.
Heutzutage gibt es viele Versionen des vortrainierten BERT, aber in der ursprünglichen Arbeit trainierte Google zwei Versionen des BERT: BERTbase und BERTlarge mit unterschiedlichen neuronalen Architekturen. Im Wesentlichen wurde BERTbase mit 12 Transformatorschichten, 12 Aufmerksamkeitsschichten und 110 Millionen Parametern entwickelt, während BERTlarge 24 Transformatorschichten, 16 Aufmerksamkeitsschichten und 340 Millionen Parameter verwendete. Wie erwartet übertraf BERTlarge seinen kleineren Bruder bei den Genauigkeitstests.
Um im Detail zu erfahren, wie die Encoder-Decoder-Architektur in Transformatoren funktioniert, empfehlen wir dir, unsere Einführung in die Verwendung von Transformatoren und Hugging Face zu lesen .
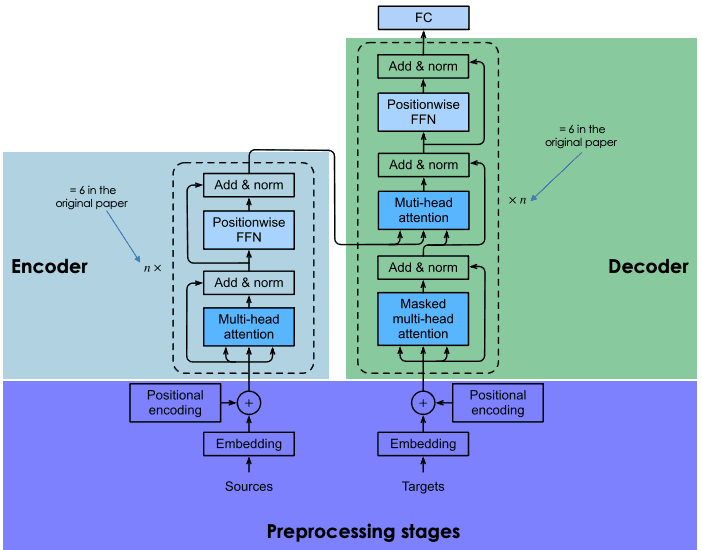
Eine Erklärung der Architektur von Transformatoren
Transformatoren werden in einem zeitaufwändigen und teuren Verfahren (das sich nur eine begrenzte Gruppe von Unternehmen, darunter Google, leisten kann) auf einem riesigen Datenbestand von Grund auf trainiert.
Im Fall von BERT wurde es vier Tage lang auf Wikipedia (~2,5 Mrd. Wörter) und Googles BooksCorpus (~800 Mio. Wörter) trainiert. So kann das Modell nicht nur auf Englisch, sondern auch in vielen anderen Sprachen aus der ganzen Welt Wissen erwerben.
Um den Trainingsprozess zu optimieren, hat Google neue Hardware entwickelt, die sogenannte TPU (Tensor Processing Unit), die speziell für maschinelle Lernaufgaben entwickelt wurde.
Um unnötige und kostspielige Interaktionen im Trainingsprozess zu vermeiden, nutzten die Google-Forscher Transfer-Learning-Techniken, um die (Vor-)Trainingsphase von der Feinabstimmungsphase zu trennen. Auf diese Weise können Entwickler/innen vortrainierte Modelle auswählen, die Input-Output-Paardaten der Zielaufgabe verfeinern und den Kopf des vortrainierten Modells mit domänenspezifischen Daten neu trainieren. Diese Eigenschaft macht LLMs wie den BERT zum Grundmodell für unzählige Anwendungen, die darauf aufbauen,
Das Schlüsselelement zum Erreichen des bidirektionalen Lernens im BERT (und jedem LLM, das auf Transformatoren basiert) ist der Aufmerksamkeitsmechanismus. Dieser Mechanismus basiert auf der maskierten Sprachmodellierung (MLM). Indem ein Wort in einem Satz maskiert wird, zwingt diese Technik das Modell dazu, die verbleibenden Wörter in beide Richtungen des Satzes zu analysieren, um die Wahrscheinlichkeit zu erhöhen, das maskierte Wort vorherzusagen. MLM basiert auf Techniken, die bereits im Bereich der Computer Vision erprobt wurden, und eignet sich hervorragend für Aufgaben, die ein gutes kontextuelles Verständnis einer ganzen Sequenz erfordern.
Das BERT war das erste LLM, das diese Technik angewendet hat. Insbesondere wurden 15% der tokenisierten Wörter während des Trainings maskiert. Das Ergebnis zeigt, dass BERT die versteckten Wörter mit hoher Genauigkeit vorhersagen konnte.
Bist du neugierig auf die maskierte Sprachmodellierung? In unserem Kurs "Large Language Models (LLMs) Concepts " erfährst du alle Details über diese innovative Technik.
Mit Hilfe von Transformatoren konnte das BERT bei mehreren NLP-Aufgaben die besten Ergebnisse erzielen. Hier sind einige der Tests, bei denen sich BERT auszeichnet:
Viele LLMs wurden in Versuchsreihen ausprobiert, aber nur wenige wurden in etablierte Anwendungen integriert. Das ist beim BERT nicht der Fall, das jeden Tag von Millionen von Menschen genutzt wird (auch wenn wir uns dessen vielleicht nicht bewusst sind).
Ein gutes Beispiel ist die Google-Suche. Im Jahr 2020 gab Google bekannt, dass es BERT über die Google-Suche in über 70 Sprachen eingeführt hat. Das bedeutet, dass Google BERT nutzt, um Inhalte zu bewerten und Featured Snippets anzuzeigen. Mit dem Aufmerksamkeitsmechanismus kann Google jetzt den Kontext deiner Frage nutzen, um nützliche Informationen zu liefern, wie im folgenden Beispiel gezeigt.
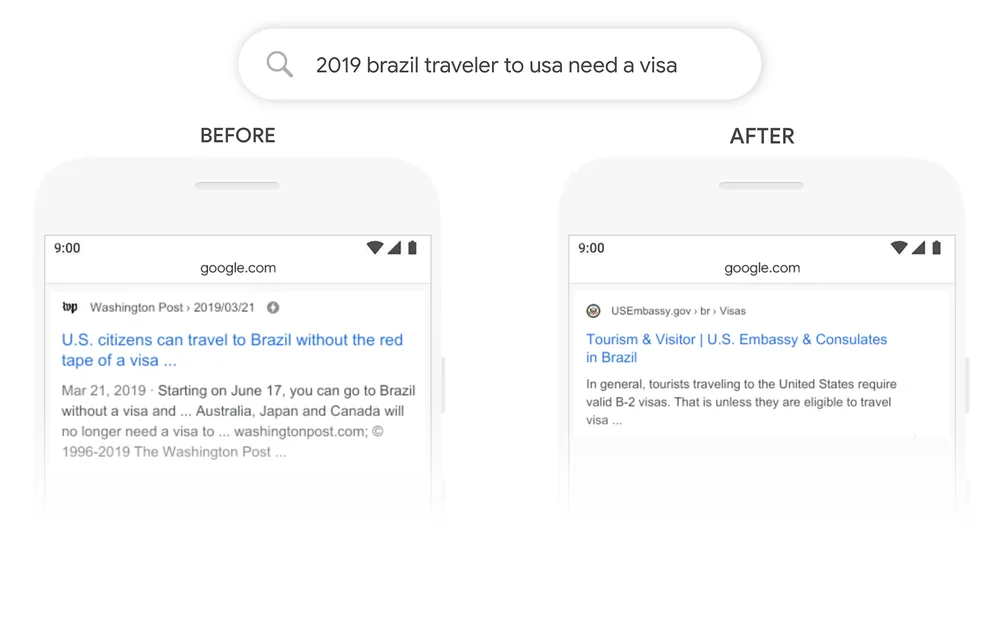
Quelle: Google
Aber das ist nur ein Teil der Geschichte. Der Erfolg von BERT ist zu einem großen Teil auf seine Open-Source-Natur zurückzuführen, die es Entwicklern ermöglicht hat, auf den Quellcode des ursprünglichen BERT zuzugreifen und neue Funktionen und Verbesserungen zu entwickeln.
Das hat zu einer großen Anzahl von BERTs-Varianten geführt. Im Folgenden findest du einige der bekanntesten Varianten:
Wenn du mehr über die Open-Source-LLM-Bewegung wissen willst, empfehlen wir dir unseren Beitrag mit den Top Open-Source LLM im Jahr 2023 zu lesen
Einer der größten Vorteile des BERT und der LLMs im Allgemeinen ist, dass der Prozess des Vortrainings vom Prozess der Feinabstimmung getrennt ist. Das bedeutet, dass Entwickler vortrainierte Versionen von BERT nehmen und sie für ihre spezifischen Anwendungsfälle anpassen können.
Im Fall von BERT gibt es Hunderte von fein abgestimmten Versionen von BERT, die für eine Vielzahl von NLP-Aufgaben entwickelt wurden. Unten findest du eine sehr, sehr begrenzte Liste mit fein abgestimmten Versionen von BERT:
Der BERT ist mit den traditionellen Einschränkungen und Problemen verbunden, die mit LLMs verbunden sind. Die Vorhersagen des BERT basieren immer auf der Menge und Qualität der Daten, die für das Training verwendet werden. Wenn die Trainingsdaten begrenzt, schlecht und verzerrt sind, kann der BERT ungenaue, schädliche Ergebnisse oder sogar sogenannte LLM-Halluzinationen liefern.
Im Fall des ursprünglichen BERT ist dies sogar noch wahrscheinlicher, da das Modell ohne Reinforcement Learning from Human Feedback (RLHF) trainiert wurde, eine Standardtechnik, die von fortschrittlicheren Modellen wie chatGPT, LLaMA 2 und Google Bard verwendet wird, um die KI-Sicherheit zu verbessern. RLHF beinhaltet die Verwendung von menschlichem Feedback, um den Lernprozess des LLM während der Ausbildung zu überwachen und zu steuern und so effektive, sichere und vertrauensvolle Systeme zu gewährleisten.
Obwohl es im Vergleich zu anderen modernen LLMs wie chatGPT als kleines Modell angesehen werden kann, erfordert es dennoch eine beträchtliche Menge an Rechenleistung, um es auszuführen, geschweige denn es von Grund auf zu trainieren. Deshalb können Entwickler/innen mit begrenzten Ressourcen es möglicherweise nicht nutzen.
Der BERT war einer der ersten modernen LLMs. Der BERT ist aber keineswegs altmodisch, sondern immer noch eines der erfolgreichsten und am weitesten verbreiteten LLMs. Dank seines Open-Source-Charakters gibt es heute mehrere Varianten und Hunderte von vortrainierten Versionen von BERT, die für bestimmte NLP-Aufgaben entwickelt wurden.
Wenn du dich über das BERT und die neuesten Entwicklungen im NLP auf dem Laufenden halten möchtest, ist das DataCamp für dich da. Schau dir unsere kuratierten Materialien an und bleibe auf dem Laufenden über die aktuelle generative KI-Revolution!
Beginne deine NLP-Reise noch heute!
Lernpfad
Kurs
Kurs