programa
Ingeniero de datos en Python
40 h

Imagen del autor.
Apache Airflow es una popular herramienta de orquestación de datos de código abierto diseñada para construir, programar y supervisar canalizaciones de datos. Cuenta con un panel de control que ayuda a gestionar el estado de los flujos de trabajo, lo que la convierte en una herramienta perfecta para la mayoría de las necesidades de los flujos de trabajo.
Sin embargo, Airflow carece de algunas funciones importantes que pueden ser vitales para los requisitos de orquestación de datos complejos y modernos.
En este tutorial, exploraremos cinco alternativas a Airflow que ofrecen capacidades mejoradas y abordan algunas de sus limitaciones. Además, aprenderemos a construir una canalización ETL sencilla utilizando cada herramienta, ejecutarla y visualizarla en su panel de control.
Airflow es una potente herramienta para diversos flujos de trabajo de datos, pero tiene varias limitaciones que pueden hacer que las empresas se planteen alternativas.
He aquí algunas razones por las que podrías elegir una alternativa:
Antes de sumergirnos en la parte de codificación de otras herramientas de orquestación de datos, es importante que aprendas a escribir la canalización de datos utilizando Apache Airflow siguiendo el tutorial Introducción a Apache Airflow para que puedas comparar las alternativas.
Si eres completamente nuevo en Airflow, considera la posibilidad de realizar el breve Introducción a Airflow en Python para aprender los fundamentos de la construcción y programación de canalizaciones de datos.
Ahora vamos a describir las 5 mejores alternativas a Airflow y a mostrar cómo utilizarlas con ejemplos prácticos de código.
Prefect es una herramienta de orquestación de flujos de trabajo en Python de código abierto creada para los ingenieros modernos de datos y aprendizaje automático. Ofrece una API sencilla que te permite construir una canalización de datos rápidamente y gestionarla a través de un panel interactivo.
Perfect ofrece un modelo de ejecución híbrido, lo que significa que puedes desplegar el flujo de trabajo en la nube y ejecutarlo allí o utilizar el repositorio local.
Comparado con Airflow, Prefect viene con funciones avanzadas como dependencias automatizadas de tareas, activadores basados en eventos, notificaciones integradas, infraestructura específica de flujos de trabajo e intercambio de datos entre tareas. Estas capacidades la convierten en una potente solución para gestionar flujos de trabajo complejos de forma eficiente y eficaz.
Prefect es sencillo y tiene funciones potentes. Básicamente tardé 5 minutos en ejecutar el código de ejemplo. Me gusta especialmente cómo está diseñada la interfaz de usuario del panel de control, cómo puedes configurar notificaciones, volver a ejecutar canalizaciones, gestionar y supervisar todo a través del panel de control.
Abid Ali Awan, Author
Lee el Airflow vs Prefect: Decidir cuál es la adecuada para tu flujo de trabajo de datos blog para conocer la comparación detallada entre estas dos herramientas de orquestación de datos .
Comenzaremos nuestro proyecto Prefect instalando el paquete Python. Ejecuta el siguiente comando en un terminal.
$ pip install -U prefectDespués, crearemos un script de Python llamado prefect_etl.py y escribiremos el siguiente código.
from prefect import task, flow
import pandas as pd
# Extract data
@task
def extract_data():
# Simulating data extraction
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
return df
# Transform data
@task
def transform_data(df: pd.DataFrame):
# Example transformation: adding a new column
df["age_plus_ten"] = df["age"] + 10
return df
# Load data
@task
def load_data(df: pd.DataFrame):
# Simulating data load
print("Loading data to target destination:")
print(df)
# Defining the flow
@flow(log_prints=True)
def etl():
raw_data = extract_data()
transformed_data = transform_data(raw_data)
load_data(transformed_data)
# Running the flow
if __name__ == "__main__":
etl()El código anterior define las funciones de tarea extract_data(),transform_data(), y load_data()y las ejecuta en serie en una función de flujo llamada etl(). Estas funciones se crean utilizando decoradores Prefect Python.
En resumen, estamos creando un DataFrame de pandas, transformándolo y mostrando el resultado final mediante print. Esta es una forma sencilla de simular un canal ETL.
Para ejecutar el flujo de trabajo, basta con ejecutar el script de Python mediante el siguiente comando.
$ python prefect_etl.py Como podemos ver, la ejecución de nuestro flujo de trabajo se ha completado con éxito.

Registros de ejecución de flujo prefecto.
Ahora desplegaremos nuestro flujo de trabajo para que podamos ejecutarlo según una programación o activarlo en función de un evento. Desplegar el flujo también nos permite supervisar y gestionar varios flujos de trabajo de forma centralizada.
Para desplegar el flujo, utilizaremos la CLI de Prefect. La función deploy requiere el nombre del archivo Python, el nombre de la función de flujo en el archivo y el nombre de la implantación. En este caso, llamaremos a esta implantación "simple_etl".
$ prefect deploy prefect_etl.py:etl -n 'simple_etl'Tras ejecutar el script anterior en el terminal, puede que recibamos el mensaje de que no tenemos un grupo de trabajadores para ejecutar el despliegue. Para crear el pool de trabajadores, utiliza el siguiente comando.
$ prefect worker start --pool 'datacamp'Ahora que tenemos un grupo de trabajadores, lanzaremos otra ventana de terminal y ejecutaremos el despliegue. El comando prefect deployment run requiere "<nombre-función-flujo>/<nombre-despliegue>" como argumento, como se muestra en el comando siguiente.
$ prefect deployment run 'etl/simple_etlComo resultado de la ejecución del despliegue, recibirás el mensaje de que el flujo de trabajo se está ejecutando. Normalmente, al flujo que se crea se le asigna un nombre aleatorio, en mi caso witty-lorikeet.
Creating flow run for deployment 'etl/simple_etl'...
Created flow run 'witty-lorikeet'.
└── UUID: 4e0495b0-9c7e-4ed8-b9ab-5160994dc7f0
└── Parameters: {}
└── Job Variables: {}
└── Scheduled start time: 2024-06-22 14:05:01 PKT (now)
└── URL: <no dashboard available>Para ver el registro completo, vuelve a la ventana del terminal donde iniciaste el pool de trabajadores.
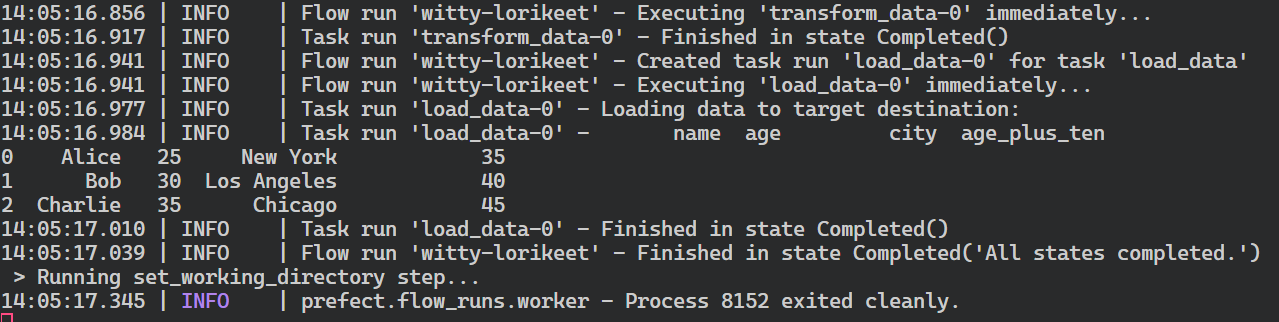
Resumen de la ejecución del flujo prefecto.
Debes iniciar el servidor web de Prefect para visualizar la ejecución del flujo de forma más sencilla y gestionar otros flujos de trabajo.
$ prefect server start Tras ejecutar el comando anterior, se te redirigirá al panel de Prefect. También puedes ir directamente a http://127.0.0.1:4200 en tu navegador.
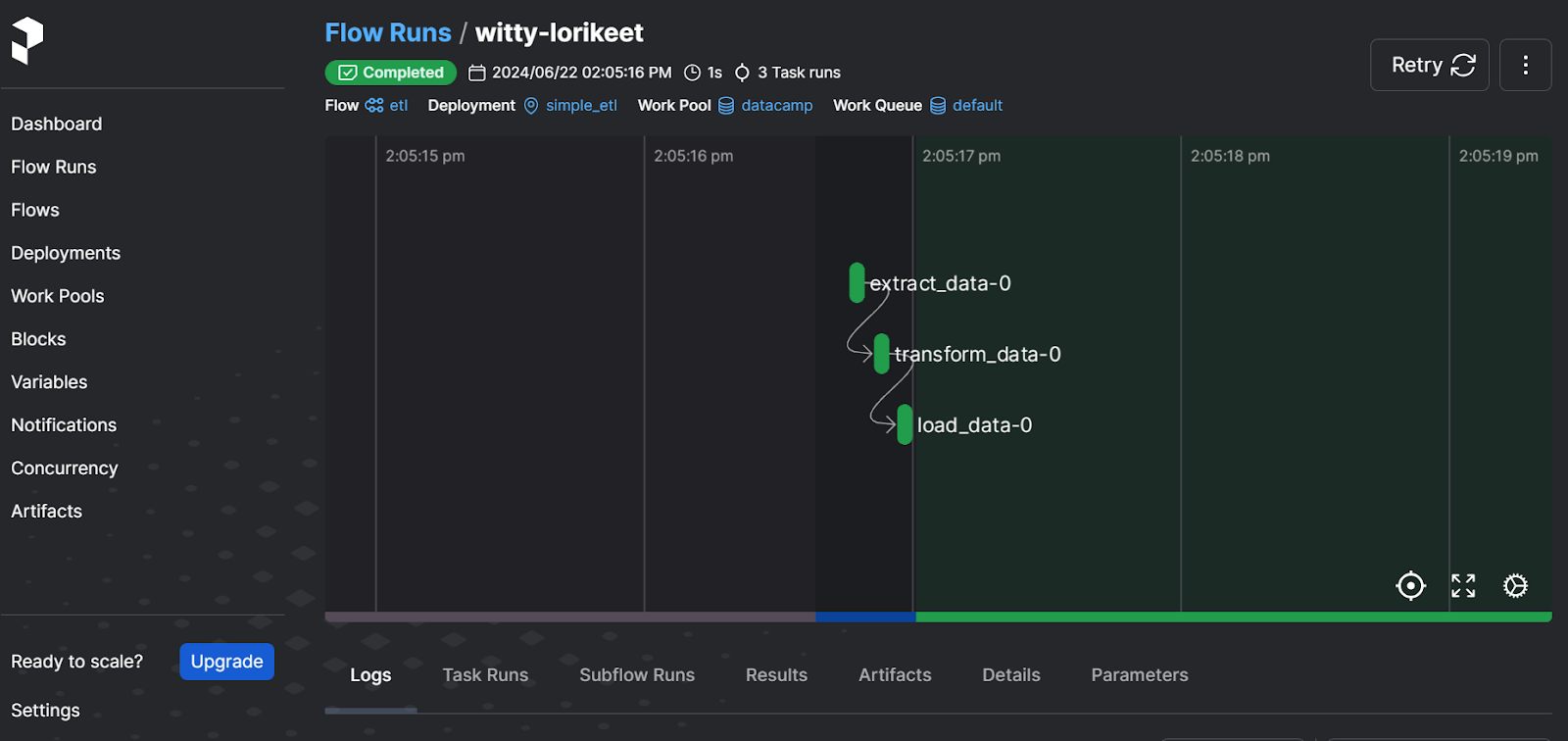
Prefecta interfaz de usuario del servidor web
El panel de control te permite volver a ejecutar el flujo de trabajo, ver los registros, comprobar los pools de trabajo, establecer notificaciones y seleccionar otras opciones avanzadas. Es una solución completa para tus necesidades modernas de orquestación de datos.
Para aprender a construir y ejecutar pipelines de aprendizaje automático utilizando Prefect, puedes seguir el tutorial Uso de Prefect para flujos de trabajo de aprendizaje automático de aprendizaje automático.
Dasgter es un marco de trabajo de código abierto diseñado para que los ingenieros de datos definan, programen y supervisen canalizaciones de datos. Es muy escalable y facilita la colaboración entre varios equipos de datos.
Dagster permite a los usuarios definir sus activos de datos como funciones Python utilizando decoradores. Una vez definidos estos activos, los usuarios pueden ejecutarlos sin problemas mediante la programación o activadores basados en eventos.
Comparado con Airflow, Dagster nos permite desarrollar, probar y revisar la canalización localmente, proporciona un enfoque de la orquestación basado en activos, y es nativo de la nube y los contenedores.
En lugar de pensar en el flujo de trabajo en términos de pasos y flujos, tuve que cambiar mi forma de pensar y construir una canalización utilizando activos de datos. Aparte de eso, construir y ejecutar una simple canalización ETL fue bastante sencillo. Además, el servidor web es relativamente mínimo, pero proporciona toda la información para supervisar activos, ejecuciones y despliegues.
Abid Ali Awan, Author
Crearemos una sencilla canalización ETL, la ejecutaremos y la visualizaremos utilizando el servidor web Dagster. De forma similar al panel de Prefect, el servidor web de Dagster proporciona formas centralizadas de supervisar múltiples flujos de trabajo y programar ejecuciones y activos.
Empezaremos instalando el paquete Python.
$ pip install dagster -qA continuación, crearemos tres funciones Python para extraer, transformar y cargar los datos. Estas funciones se denominan create_dirty_data(),clean_data(), y load_cleaned_data()en el código. Utilizando el decorador @asset, declararemos las funciones como activos de datos en Dagster.
A continuación, crearemos el trabajo de activos (job variable) utilizando todos los activos (all_assets variable) y, a continuación, crearemos la definición del activo (defs variable).
Puedes saltarte la parte de definición de activos, pero es importante si quieres programar tu ejecución, ejecutar varios trabajos y configurar sensores.
import pandas as pd
import numpy as np
from dagster import asset, Definitions, define_asset_job, materialize
@asset
def create_dirty_data():
# Create a sample DataFrame with dirty data
data = {
'Name': [' John Doe ', 'Jane Smith', 'Bob Johnson ', ' Alice Brown'],
'Age': [30, np.nan, 40, 35],
'City': ['New York', 'los angeles', 'CHICAGO', 'Houston'],
'Salary': ['50,000', '60000', '75,000', 'invalid']
}
df = pd.DataFrame(data)
# Save the DataFrame to a CSV file
dirty_file_path = 'dag_data/dirty_data.csv'
df.to_csv(dirty_file_path, index=False)
return dirty_file_path
@asset
def clean_data(create_dirty_data):
# Read the dirty CSV file
df = pd.read_csv(create_dirty_data)
# Clean the data
df['Name'] = df['Name'].str.strip()
df['Age'] = pd.to_numeric(df['Age'], errors='coerce').fillna(df['Age'].mean())
df['City'] = df['City'].str.upper()
df['Salary'] = df['Salary'].replace('[\$,]', '', regex=True)
df['Salary'] = pd.to_numeric(df['Salary'], errors='coerce').fillna(0)
# Calculate average salary
avg_salary = df['Salary'].mean()
# Save the cleaned DataFrame to a new CSV file
cleaned_file_path = 'dag_data/cleaned_data.csv'
df.to_csv(cleaned_file_path, index=False)
return {
'cleaned_file_path': cleaned_file_path,
'avg_salary': avg_salary
}
@asset
def load_cleaned_data(clean_data):
cleaned_file_path = clean_data['cleaned_file_path']
avg_salary = clean_data['avg_salary']
# Read the cleaned CSV file to verify
df = pd.read_csv(cleaned_file_path)
print({
'num_rows': len(df),
'num_columns': len(df.columns),
'avg_salary': avg_salary
})
# Define all assets
all_assets = [create_dirty_data, clean_data, load_cleaned_data]
# Create a job that will materialize all assets
job = define_asset_job("all_assets_job", selection=all_assets)
# Create Definitions object
defs = Definitions(
assets=all_assets,
jobs=[job]
)
if __name__ == "__main__":
result = materialize(all_assets)
print("Pipeline execution result:", result.success)Puedes ejecutar el código anterior en un cuaderno Jupyter o crear el archivo Python y ejecutarlo.
Como resultado de la ejecución del código, obtendremos un registro completo de la ejecución del flujo de trabajo.
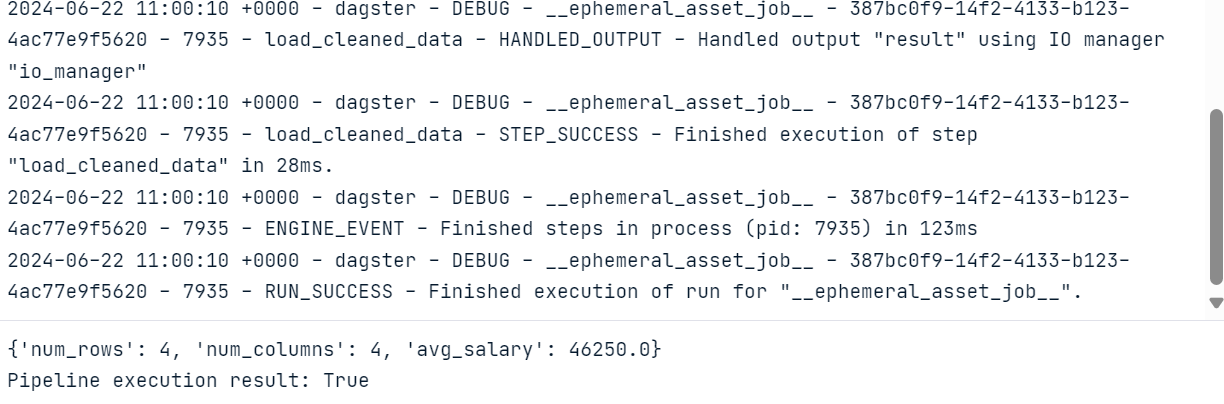
Para visualizar los activos y las ejecuciones de trabajo, tenemos que instalar y ejecutar el servidor web Dagster. El servidor web te permite ejecutar los trabajos, materializar activos individuales y supervisar varios trabajos a la vez.
$ pip install dagster-webserverPara iniciar el servidor Dagster, utilizaremos la CLI de Daster y le proporcionaremos la ubicación del archivo Python. En este caso, he llamado al archivo dagster_pipe.py.
$ dagster dev -f dagster_pipe.py El comando anterior iniciará automáticamente el servidor web en tu navegador. También puedes ir directamente a http://127.0.0.1:3000 en tu navegador.
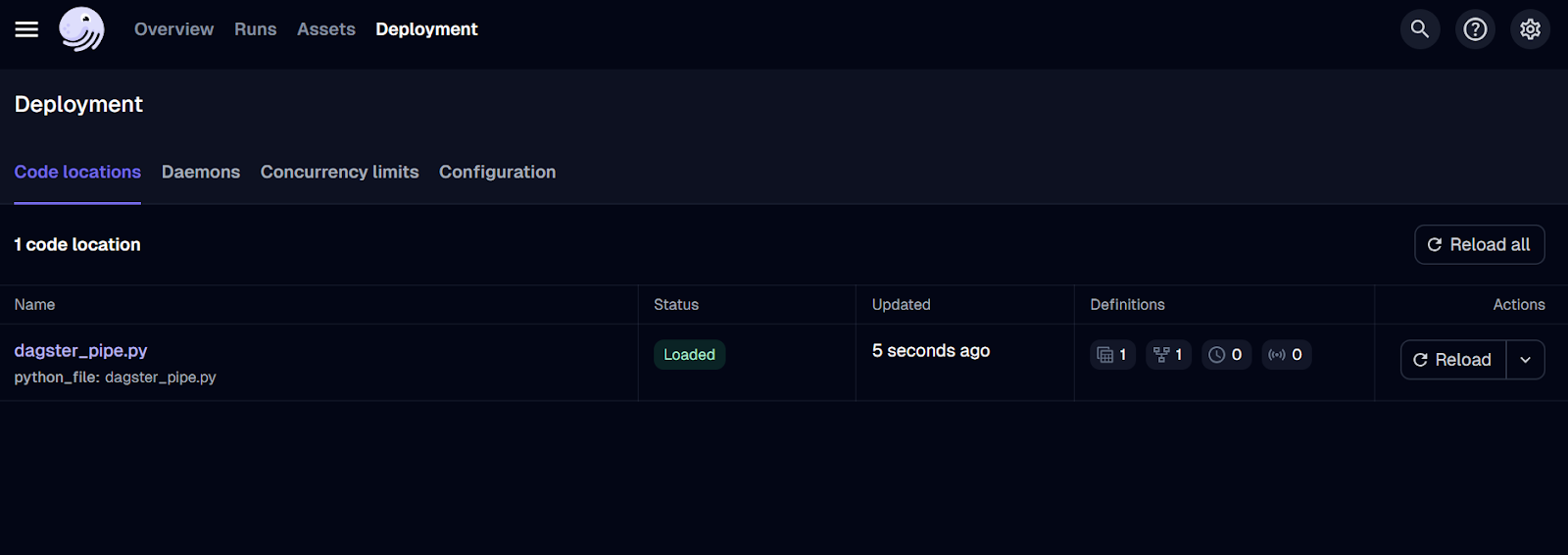
IU del servidor web Dagster.
Sólo hemos desplegado el trabajo hasta ahora. Para ejecutar el flujo de trabajo, ve a la pestaña "Ejecuciones" y haz clic en el botón "Lanzar una nueva ejecución".
¡La ejecución debería completarse con éxito! Para ver los registros, haz clic en el ID de la tirada que te interese.
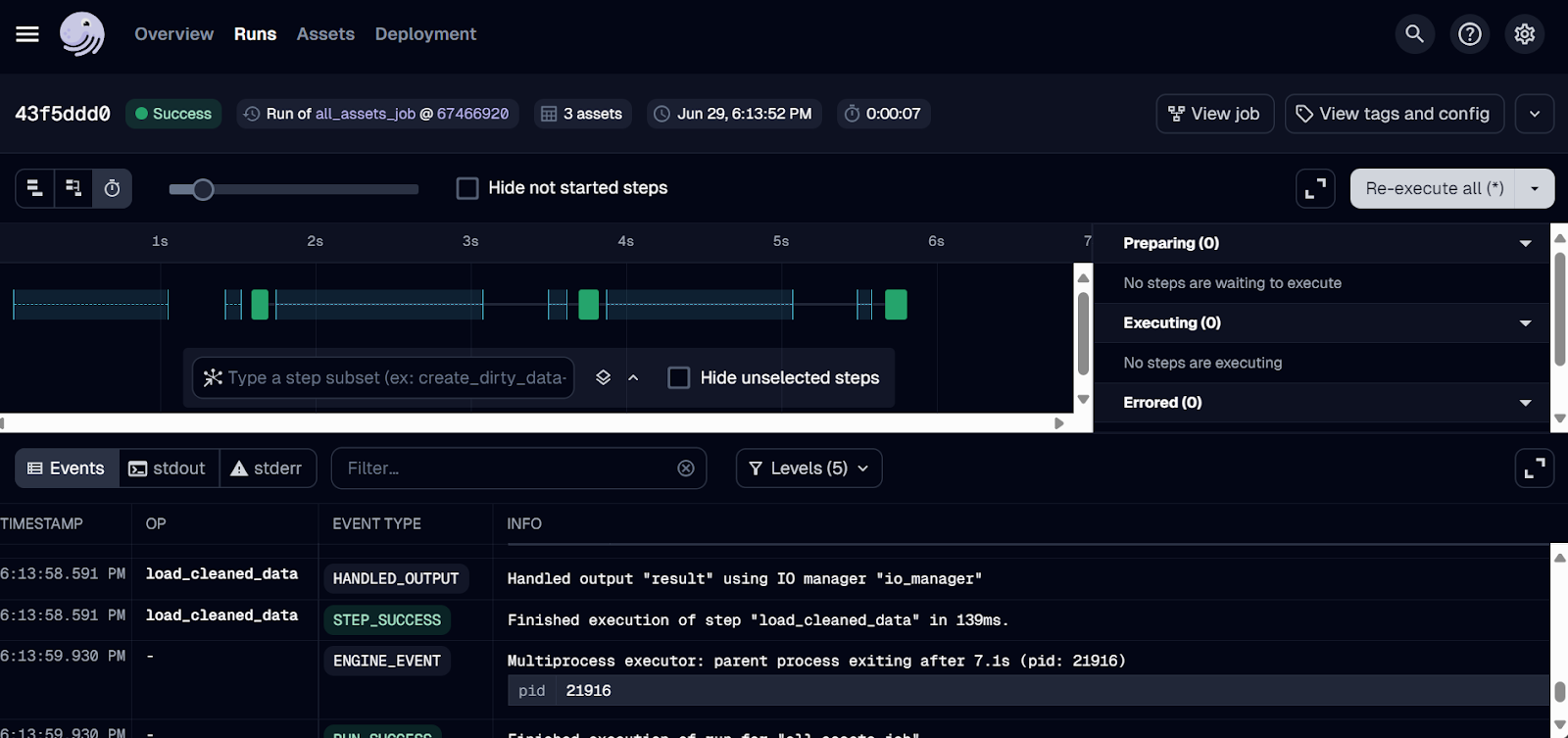
Registros de ejecución de Dagster.
Mage AI es un marco de orquestación de datos híbridos de código abierto. Híbrido significa que obtienes la flexibilidad de un Cuaderno Jupyter y el control del código modular.
Cualquiera, incluso con conocimientos limitados de Python, puede construir, ejecutar y supervisar canalizaciones de datos. En lugar de escribir y ejecutar directamente un archivo Python, crearás un proyecto Mage AI y lo lanzarás en el panel de control, donde podrás construir, ejecutar y gestionar tus canalizaciones de datos.
Comparado con Airflow, Mage AI ofrece una interfaz fácil de usar y de utilizar, lo que lo convierte en una opción excelente para los que se inician en la ingeniería de datos. Está diseñado teniendo en cuenta la escalabilidad y es capaz de manejar grandes volúmenes de datos y estructuras de canalización complejas de forma eficaz.
Me sentí extraña porque era completamente diferente a lo que estoy acostumbrada. Tuve que instalar e iniciar la interfaz web de Mage AI. Se suponía que iba a ser fácil, pero me resultó difícil construir y ejecutar la canalización ETL. Por otro lado, puedo entender por qué este diseño único puede resultar atractivo para las personas que se inician en este campo, ya que básicamente consiste en arrastrar y soltar y pulsar botones.
Abid Ali Awan, Author
Iniciar la IA Mago es bastante sencillo. Sólo tenemos que instalar el paquete Mage AI Python.
$ pip install mage-aiY pon en marcha el proyecto Mago AI.
$ mage start mage_ai_etl El comando anterior iniciará el servidor web. Como se ha mencionado antes, toda la edición de código, ejecución de trabajos y supervisión de trabajos se realiza a través de la interfaz de usuario de Mage AI.
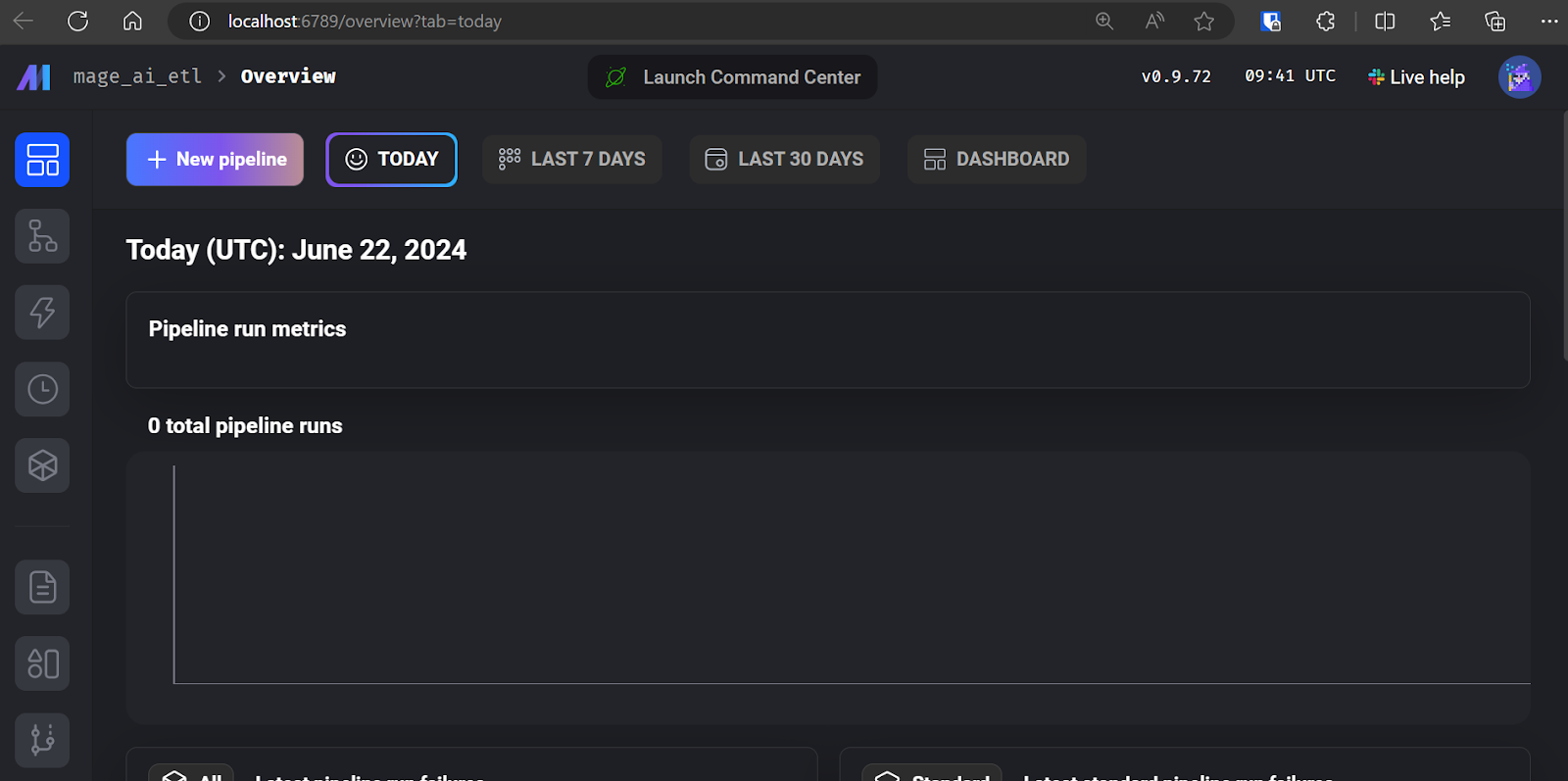
IU de la IA de mago.
Haz clic en "+ Nueva canalización" para crear tu primera canalización ETL. Yo llamé al mío "simple_etl".
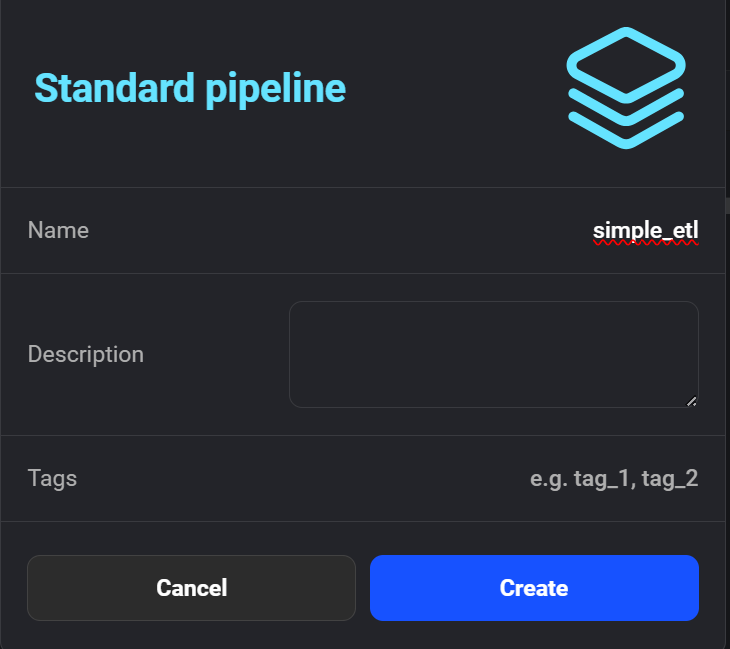
Creación de la nueva canalización en la IA de Mago.
A continuación, la interfaz te pedirá que añadas un módulo para empezar a codificar. Selecciona el módulo "Cargador de datos" y escribe el siguiente código Python.
Aquí declaramos una funcióncreate_sample_csv(), que es el primer paso de nuestro pipeline. Utilizamos el decorador Mage AI @data_loader. También definimos una función test_output() que afirma si existe la salida. Esto ayuda a gestionar la dependencia de las tareas.
import io
import pandas as pd
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def create_sample_csv() -> pd.DataFrame:
"""
Create a sample CSV file with duplicates and missing values
"""
csv_data = """
category,product,quantity,price
Electronics,Laptop,5,1000
Electronics,Smartphone,10,500
Clothing,T-shirt,50,20
Clothing,Jeans,30,50
Books,Novel,100,15
Books,Textbook,20,80
Electronics,Laptop,5,1000
Clothing,T-shirt,,20
Electronics,Tablet,,300
Books,Magazine,25,
"""
return pd.read_csv(io.StringIO(csv_data.strip()))
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'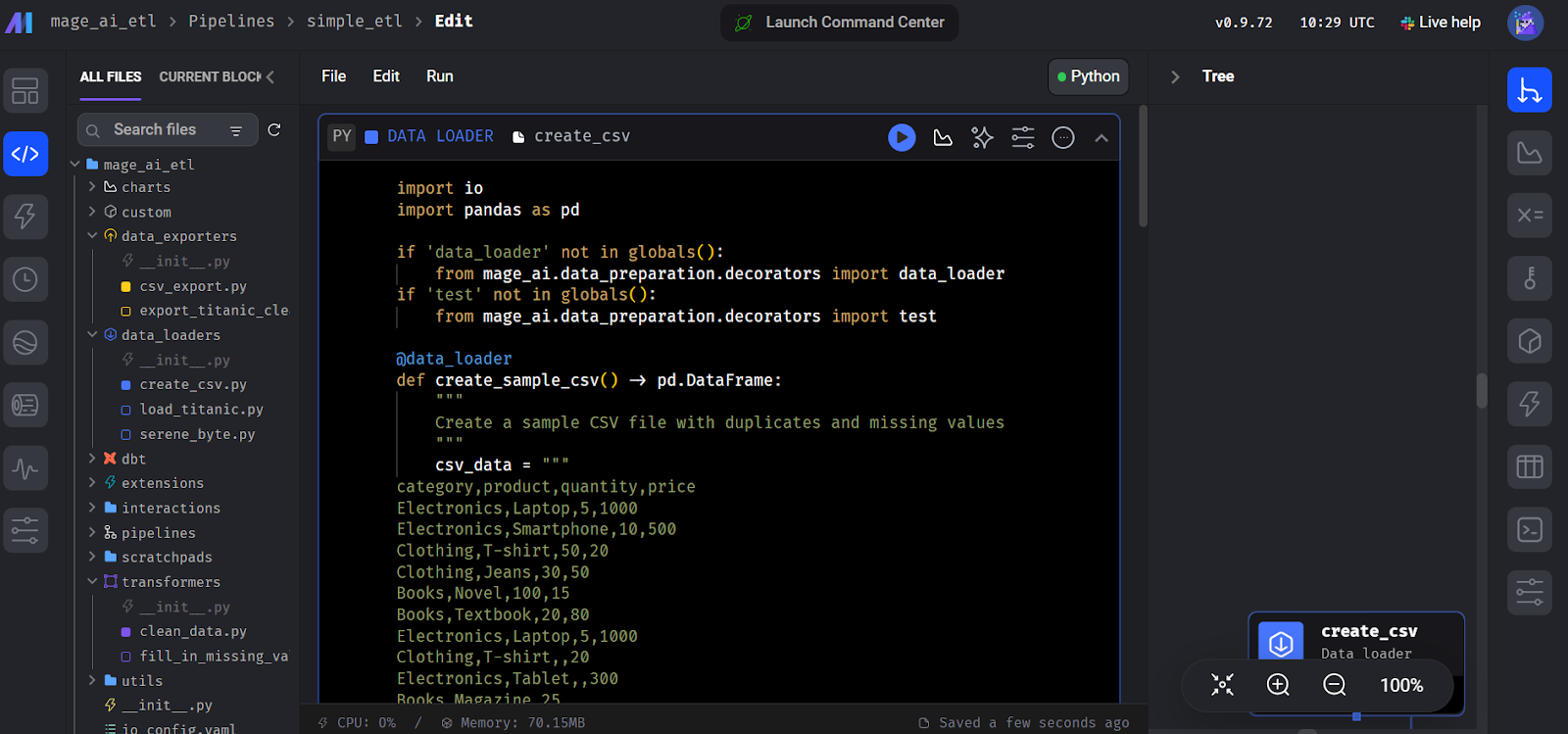
Crear el bloque cargador de datos en Mago AI.
A continuación, crea otro módulo llamado "Transformador" y añade la función limpiar_datos() como se muestra en el código siguiente.
Puedes ignorar la función test() función; sólo tienes que añadir la función principal del transformador, clean_data().
import pandas as pd
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
"""
Clean and transform the data
"""
# Remove duplicates
df = df.drop_duplicates()
# Fill missing values with 0
df = df.fillna(0)
return df
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'Del mismo modo, crea un módulo "Exportador de datos" y añade el siguiente código. El código declara una función de carga de datos, export_data_to_csv(), que guarda los datos transformados en un archivo CSV .
import pandas as pd
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_csv(df: pd.DataFrame) -> None:
"""
Export the processed data to a CSV file
"""
df.to_csv('output_data.csv', index=False)
print("Data exported successfully to output_data.csv")Para ejecutar la canalización, ve a la pestaña "Activador" y haz clic en "Ejecutar@una vez".
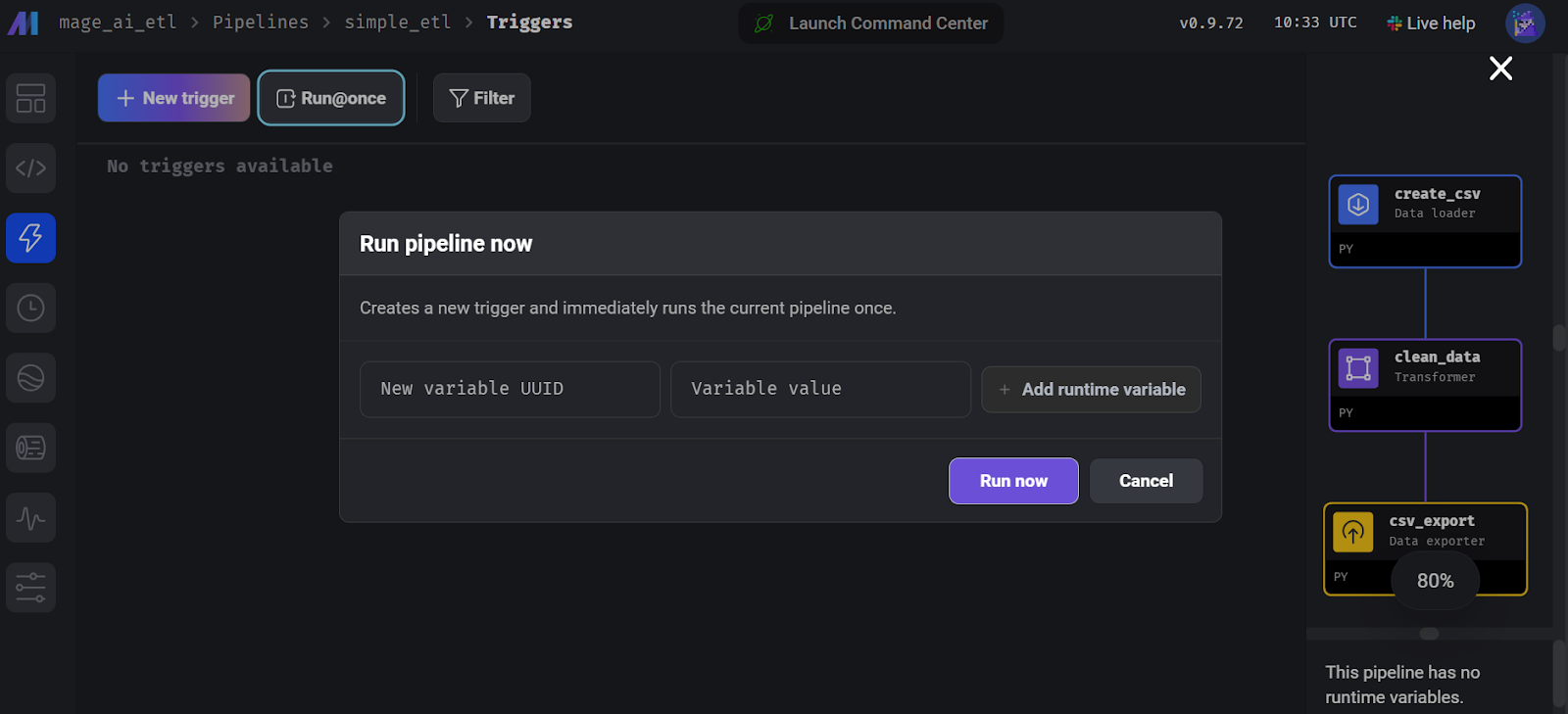
Ejecutar la canalización en la IA de Mago.
Para ver los registros de ejecución, ve a la pestaña "Ejecuciones" y haz clic en el botón "Registros" de la tubería ejecutada recientemente.
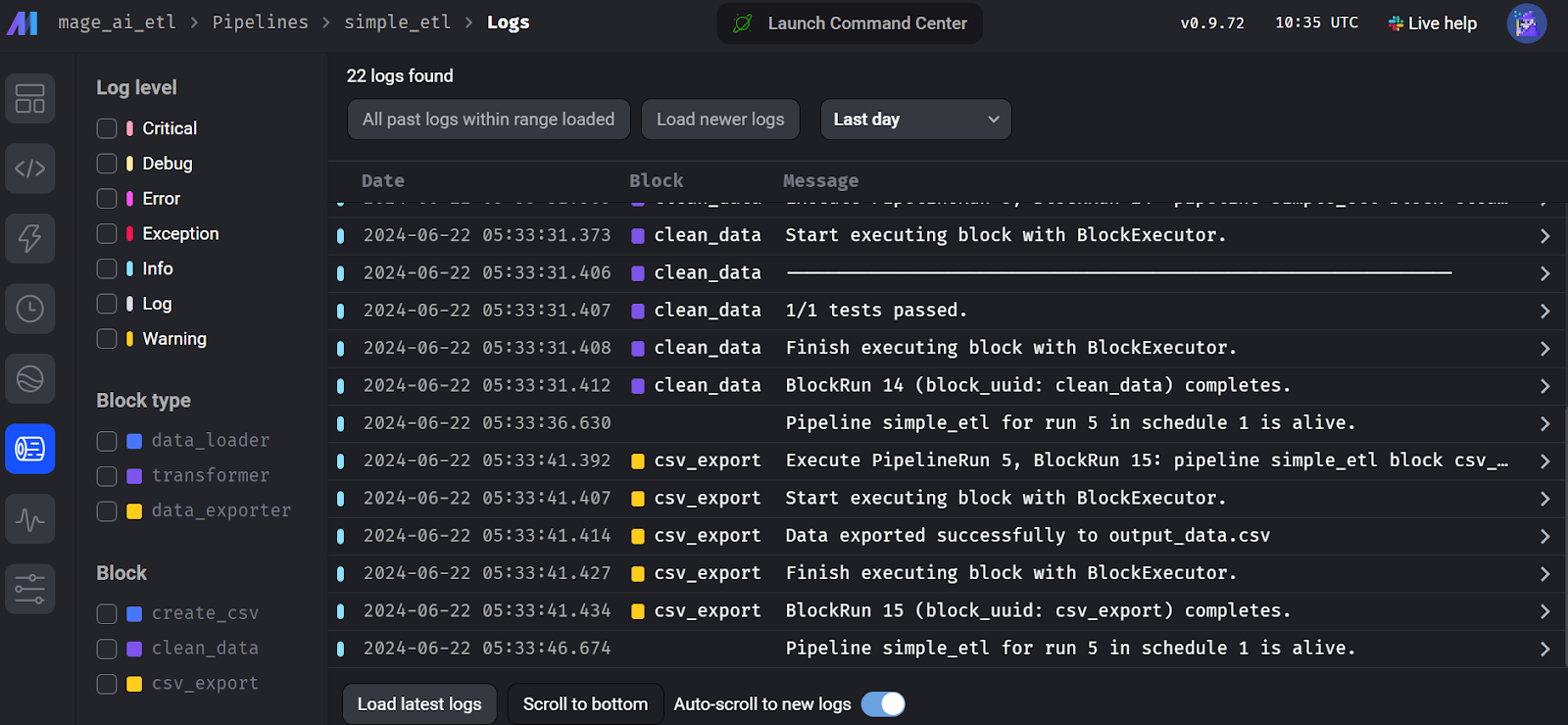
Registros de ejecución de flujo de IA de mago.
Kedro es otro popular marco de orquestación de datos de código abierto que es ligeramente diferente de las otras herramientas. Se creó para ingenieros de aprendizaje automático y toma prestados muchos conceptos de la ingeniería de software, aplicándolos a proyectos de aprendizaje automático.
Kedro está diseñado para ser altamente modular, lo que significa que incluso para exportar un conjunto de datos, tienes que crear un catálogo de datos que especifique la ubicación y el tipo de datos, garantizando una gestión de datos estandarizada y eficaz en todo el proceso.
Para comprender cómo encaja Kedro en el ecosistema del aprendizaje automático, puedes explorar varias herramientas de MLOps leyendo el artículo Las 25 principales herramientas MLOps que debes conocer en 2024.
Comparada con Airflow, la API de Kedro es más sencilla para construir una canalización de datos. Se centra más en la ingeniería de aprendizaje automático y ofrece categorización y versionado de datos.
La parte de codificación es bastante sencilla, pero surgen problemas cuando quieres ejecutar tu canalización. Tienes que crear un catálogo de datos, registrar la canalización y averiguar la estructura del proyecto Kedro. Yo diría que es más desafiante en comparación con Dagster y Prefect. Sin embargo, entiendo por qué está diseñado así: para que tu canal de datos sea fiable y no contenga errores.
Abid Ali Awan, Author
Construir una canalización de datos Kedro es un juego diferente. El marco es modular, y necesitas comprender la estructura del proyecto y los distintos pasos que implica para ejecutar el flujo de trabajo con éxito.
Empieza instalando el paquete Kedro Python.
$ pip install kedroInicializa el proyecto Kedro.
$ kedro new --name=kedro_etl --tools=none --example=n Desplázate al directorio del proyecto.
$ cd kedro-etl Crea una carpeta dentro de la carpeta pipelines carpeta llamada data_processing.
$ mkdir -p src/kedro_etl/pipelines/data_processing Crea un archivo Python llamado kedro_pipe.py y ábrelo en tu IDE favorito, por ejemplo, puedes utilizar Visual Studio Code.
$ code src/kedro_etl/pipelines/data_processing/kedro_pipe.pyEl script de Python debe contener las funciones de extracción, transformación y carga, que son nodos de la canalización. En este caso, se trata de las funciones create_sample_data(),clean_data(), y load_and_process_data().
A continuación, unimos estos nodos utilizando la clase Kedro Pipeline dentro de la funcióncreate_pipeline(). En la función pipeline, definimos nodos, y cada nodo tiene inputs,outputs, y un nodo name.
import pandas as pd
import numpy as np
from kedro.pipeline import Pipeline, node
def create_sample_data():
data = {
'id': range(1, 101),
'name': [f'Person_{i}' for i in range(1, 101)],
'age': np.random.randint(18, 80, 100),
'salary': np.random.randint(20000, 100000, 100),
'missing_values': [np.nan if i % 10 == 0 else i for i in range(100)]
}
return pd.DataFrame(data)
def clean_data(df: pd.DataFrame):
# Remove rows with missing values
df_cleaned = df.dropna()
# Convert salary to thousands
df_cleaned['salary'] = df_cleaned['salary'] / 1000
# Capitalize names
df_cleaned['name'] = df_cleaned['name'].str.upper()
return df_cleaned
def load_and_process_data(df: pd.DataFrame):
# Calculate average salary
avg_salary = df['salary'].mean()
# Add a new column for salary category
df['salary_category'] = df['salary'].apply(
lambda x: 'High' if x > avg_salary else 'Low')
# Calculate age groups
df['age_group'] = pd.cut(df['age'], bins=[0, 30, 50, 100], labels=[
'Young', 'Middle', 'Senior'])
print(df)
return df
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=create_sample_data,
inputs=None,
outputs="raw_data",
name="create_sample_data_node",
),
node(
func=clean_data,
inputs="raw_data",
outputs="cleaned_data",
name="clean_data_node",
),
node(
func=load_and_process_data,
inputs="cleaned_data",
outputs="processed_data",
name="load_and_process_data_node",
),
]
)Si ejecutamos la canalización sin crear el catálogo de datos, no exportará nuestros datos. Por tanto, tenemos que ir al archivo conf/base/catalog.yml y editarlo proporcionando la configuración del conjunto de datos.
raw_data:
type: pandas.CSVDataset
filepath: ./data/kedro/sample_data.csv
cleaned_data:
type: pandas.CSVDataset
filepath: ./data/kedro/cleaned_data.csv
processed_data:
type: pandas.CSVDataset
filepath: ./data/kedro/processed_data.csvTambién debemos incluir nuestro archivo Python recién creado dentro del registro de la tubería. Para ello, ve al archivo Python src/simple_etl/pipeline_registry.py e incluye el siguiente código .
"""Project pipelines."""
from __future__ import annotations
from kedro.pipeline import Pipeline
from kedro_etl.pipelines.data_processing import kedro_pipe
def register_pipelines() -> Dict[str, Pipeline]:
data_processing_pipeline = kedro_pipe.create_pipeline()
return {
"__default__": data_processing_pipeline,
"data_processing": data_processing_pipeline,
}Ejecuta la tubería y visualiza los registros en vivo dentro del terminal ejecutando el siguiente comando.
$ kedro run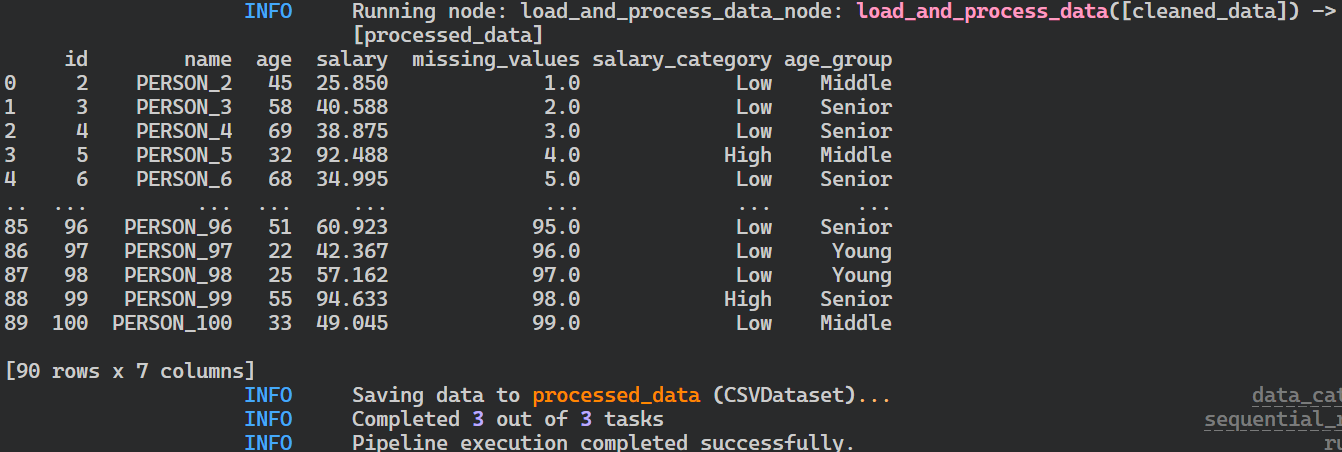
Registros de la ejecución del oleoducto Kedro.
Tras ejecutar el pipeline, tus archivos se almacenarán en formato CSV en la ubicación definida en el catálogo de datos.
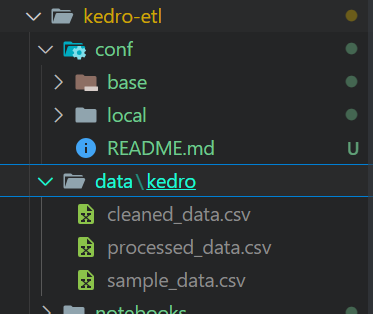
Ficheros de salida de la ejecución de la tubería Kedro.
Si tienes problemas para ejecutar la tubería, considera la posibilidad de instalar Kedro con todas las extensiones.
$ pip install "kedro[all]"Podemos visualizar y compartir nuestros pipelines instalando la herramienta kedro-viz .
$ pip install kedro-vizA continuación, ejecutar el siguiente comando nos permitirá visualizar todas las canalizaciones de datos y nodos de datos. También proporciona una opción para el rastreo de experimentos y la posibilidad de compartir la visualización de la tubería.
$ kedro viz run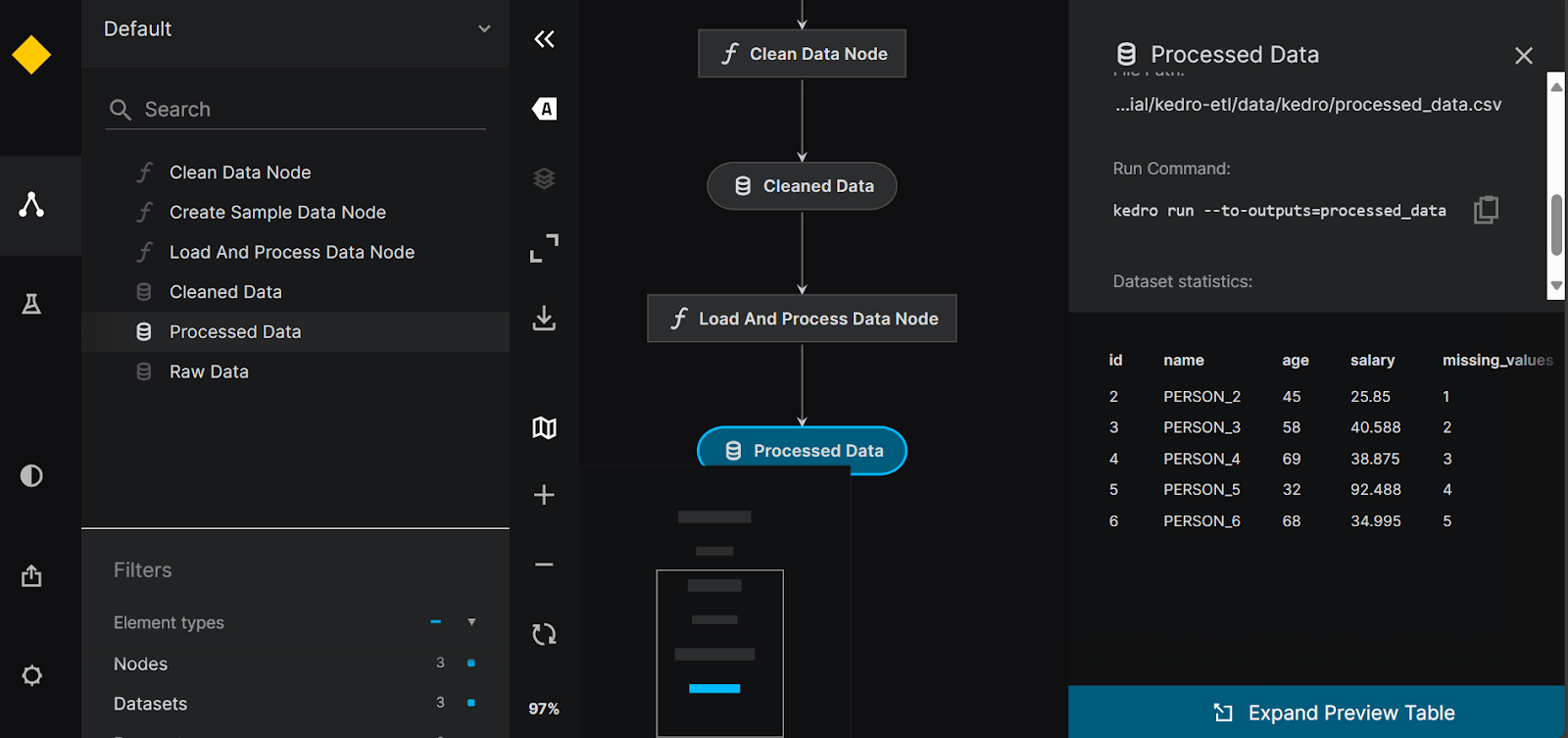
Visualización de la tubería Kedro.
Luigi es un framework de código abierto basado en Python desarrollado por Spotify que destaca en la gestión de procesos por lotes de larga duración y canalizaciones de datos complejas. Es bueno en la resolución de dependencias, la gestión de flujos de trabajo, la visualización y la recuperación de fallos, lo que lo convierte en una potente herramienta para orquestar flujos de trabajo de datos.
En comparación con Airflow, Luigi tiene una API mínima, programación por calendario y una base de usuarios leales que te ayudarán con cualquier problema relacionado con el canal de orquestación de datos.
Si eres principiante en Python, puede que te resulte difícil construir y ejecutar las canalizaciones. Sin embargo, la documentación y las guías pueden ayudarte a empezar rápidamente. Los registros proporcionan información limitada, y el panel de control es sólo una herramienta de visualización de DAGs y dependencias.
Abid Ali Awan, Author
La creación de una canalización de datos Luigi requiere conocimientos de programación orientada a objetos. Empecemos por instalar el paquete Luigi Python.
$ pip install luigiPara desarrollar un canal ETL sencillo en Luigi, crearemos tareas interconectadas. En lugar de crear funciones Python como tareas, crearemos una clase Python para cada paso dentro de la tubería, FetchData,ProcessData y GenerateReport. Cada clase tendrá tres funciones llamadas requires(), output(), y run().
Las funciones requires() y output() conectarán las tareas, y la funciónrun() ejecutará el código de procesamiento. Al final, construiremos la tubería utilizando la última tarea de la tubería.
import luigi
import pandas as pd
import numpy as np
class FetchData(luigi.Task):
def output(self):
return luigi.LocalTarget('data/fetch_data.csv')
def run(self):
# Simulate fetching data by creating a sample CSV file
data = {
'column1': [1, 2, np.nan, 4],
'column2': ['A', 'B', 'C', np.nan]
}
df = pd.DataFrame(data)
df.to_csv(self.output().path, index=False)
class ProcessData(luigi.Task):
def requires(self):
return FetchData()
def output(self):
return luigi.LocalTarget('data/process_data.csv')
def run(self):
df = pd.read_csv(self.input().path)
# Fill missing values
df['column1'].fillna(df['column1'].mean(), inplace=True)
df['column2'].fillna('B', inplace=True)
df.to_csv(self.output().path, index=False)
class GenerateReport(luigi.Task):
def requires(self):
return ProcessData()
def output(self):
return luigi.LocalTarget('data/generate_report.txt')
def run(self):
df = pd.read_csv(self.input().path)
# Simple data analysis: calculate mean of column1 and value counts of column2
mean_column1 = df['column1'].mean()
value_counts_column2 = df['column2'].value_counts()
with self.output().open('w') as out_file:
out_file.write(f'Mean of column1: {mean_column1}\n')
out_file.write('Value counts of column2:\n')
out_file.write(value_counts_column2.to_string())
if __name__ == '__main__':
luigi.build([GenerateReport()], local_scheduler=True)Ejecuta el código anterior en el Cuaderno Jupyter o crea el archivo Python y ejecútalo utilizando el terminal.
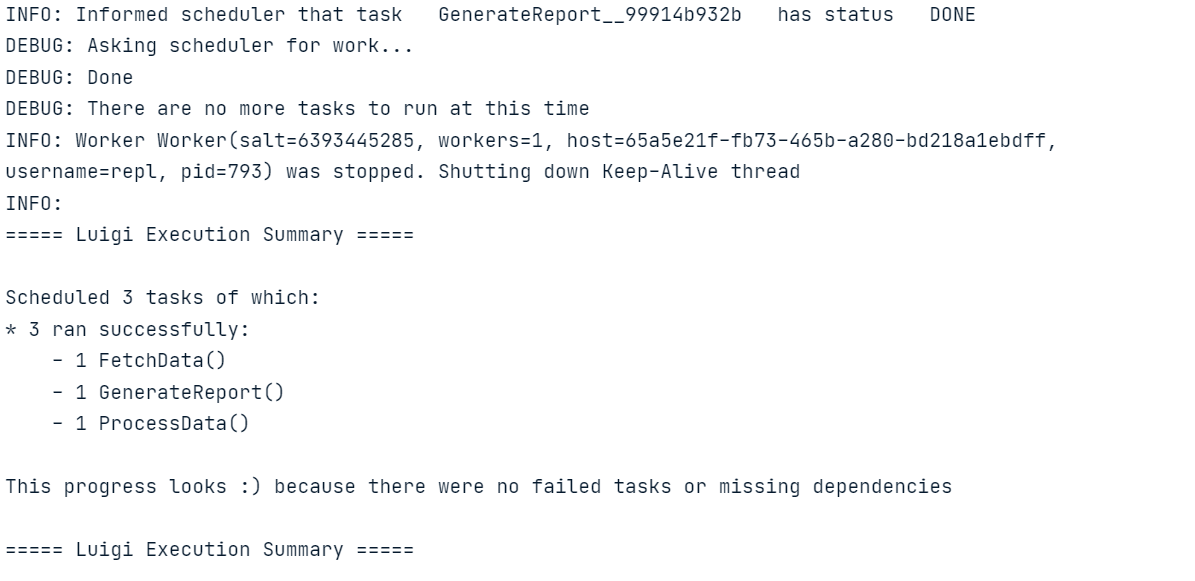
De forma similar a Luigi, también puedes aprender a construir un ETL pipeline con Apache Airflow. El tutorial cubre los aspectos básicos de la extracción, transformación y carga de datos con Apache Airflow.
Necesitamos inicializar el planificador central de Luigi para programar las ejecuciones de la tubería o activarlas con un evento.
Inicia el programador escribiendo el siguiente comando en el terminal.
$ luigid 2024-06-22 13:35:18,636 luigi[25056] INFO: logging configured by default settings
2024-06-22 13:35:18,636 luigi.scheduler[25056] INFO: No prior state file exists at /var/lib/luigi-server/state.pickle. Starting with empty state
2024-06-22 13:35:18,640 luigi.server[25056] INFO: Scheduler starting upPara ejecutar el pipeline, abre un nuevo terminal y escribe el siguiente comando. El comando Luigi requiere un nombre de archivo Python y la última tarea que queremos ejecutar. En este caso, el nombre del archivo es luigi_pipe.py, y nuestra última tarea Luigi es GenerateReport.
$ python -m luigi --module luigi_pipe GenerateReportSi quieres visualizar la ejecución del pipeline y el estado de las tareas, sólo tienes que ir a http://localhost:8082 en tu navegador.
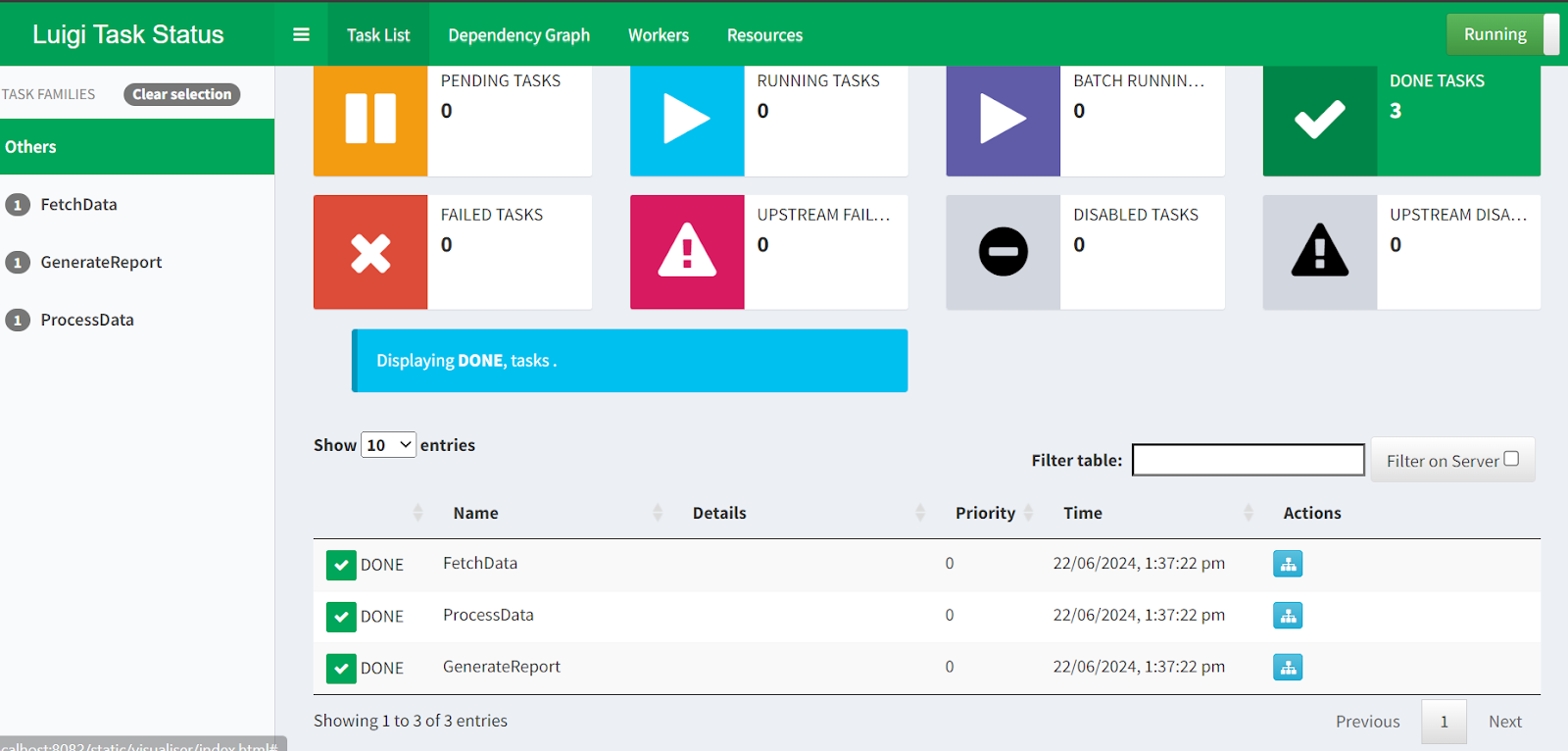
Planificador Central Luigi webUI.
¡Con esto terminamos nuestro recorrido por las 5 mejores alternativas a Airflow! Si quieres profundizar en alguno de los ejemplos presentados en este artículo, aquí tienes algunos recursos a tener en cuenta:
En este tutorial, hemos hablado de las mejores alternativas gratuitas y de código abierto a Airflow. También hemos aprendido sobre cada herramienta de orquestación de datos, y hemos construido y ejecutado una sencilla canalización ETL. Ver ejemplos de código te ayudará a decidir cuál funciona mejor para tu caso de uso.
Si eres principiante, te sugiero que empieces con Prefect o Mage AI, ya que son fáciles de usar y vienen con una configuración sencilla. Sin embargo, si buscas herramientas más avanzadas que se adhieran a las prácticas de la ingeniería del software, te recomiendo que explores Dagster, Kedro y Luigi.
Después de explorar este artículo, el siguiente paso natural en tu viaje por la ingeniería de datos es obtener una certificación como la de DataCamp Ingeniero de Datos en Python para aprender sobre otras herramientas y construir una canalización de datos de extremo a extremo que puedas desplegar en producción.
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
DataCamp Team
12 min
blog
Javier Canales Luna
12 min
blog
Tim Lu
11 min
blog
Javier Canales Luna
13 min
