
Cursus
Ingénieur de données en Python
40 h

Image de l'auteur.
Apache Airflow est un outil d'orchestration de données open-source très répandu, conçu pour construire, planifier et surveiller les pipelines de données. Il dispose d'un tableau de bord qui permet de gérer l'état des flux de travail, ce qui en fait un outil parfait pour la plupart des besoins en matière de flux de travail.
Cependant, Airflow ne dispose pas de certaines fonctionnalités importantes qui peuvent être vitales pour des besoins d'orchestration de données complexes et modernes.
Dans ce tutoriel, nous allons explorer cinq alternatives à Airflow qui offrent des capacités améliorées et répondent à certaines de ses limites. De plus, nous apprendrons à construire un pipeline ETL simple à l'aide de chaque outil, à l'exécuter et à le visualiser dans leur tableau de bord.
Airflow est un outil puissant pour divers flux de données, mais il présente plusieurs limites qui pourraient inciter les entreprises à envisager des alternatives.
Voici quelques raisons pour lesquelles vous pourriez opter pour une autre solution :
Avant de nous plonger dans la partie codage d'autres outils d'orchestration de données, il est important d'apprendre à écrire le pipeline de données en utilisant Apache Airflow en suivant les instructions suivantes Premiers pas avec Apache Airflow afin de pouvoir comparer équitablement les différentes solutions.
Si vous êtes complètement novice en matière d'Airflow, envisagez de suivre la courte formation suivante Introduction à Airflow en Python pour apprendre les bases de la construction et de la planification de pipelines de données.
Décrivons maintenant les 5 principales alternatives à Airflow et montrons comment les utiliser à l'aide d'exemples de code pratiques.
Python est un outil d'orchestration de flux de travail Python open-source construit pour les ingénieurs de données et d'apprentissage automatique modernes. Il offre une API simple qui vous permet de créer rapidement un pipeline de données et de le gérer à l'aide d'un tableau de bord interactif.
Perfect propose un modèle d'exécution hybride, ce qui signifie que vous pouvez déployer le flux de travail sur le cloud et l'y exécuter ou utiliser le référentiel local.
Par rapport à Airflow, Prefect dispose de fonctionnalités avancées telles que les dépendances automatisées des tâches, les déclencheurs basés sur des événements, les notifications intégrées, l'infrastructure spécifique au flux de travail et le partage des données entre les tâches. Ces capacités en font une solution puissante pour gérer efficacement des flux de travail complexes.
Prefect est simple et dispose de fonctionnalités puissantes. Il m'a fallu 5 minutes pour exécuter le code de l'exemple. J'aime particulièrement la conception de l'interface du tableau de bord, la façon dont vous pouvez configurer des notifications, réexécuter des pipelines, gérer et surveiller tout ce qui se passe à travers le tableau de bord.
Abid Ali Awan, Author
Lisez le site Airflow vs Prefect : Deciding Which is Right For Your Data Workflow blog pour découvrir la comparaison détaillée entre ces deux outils d'orchestration de données.
Nous allons commencer notre projet Prefect en installant le paquetage Python. Exécutez la commande suivante dans un terminal.
$ pip install -U prefectEnsuite, nous créerons un script Python nommé prefect_etl.py et écrire le code suivant.
from prefect import task, flow
import pandas as pd
# Extract data
@task
def extract_data():
# Simulating data extraction
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
return df
# Transform data
@task
def transform_data(df: pd.DataFrame):
# Example transformation: adding a new column
df["age_plus_ten"] = df["age"] + 10
return df
# Load data
@task
def load_data(df: pd.DataFrame):
# Simulating data load
print("Loading data to target destination:")
print(df)
# Defining the flow
@flow(log_prints=True)
def etl():
raw_data = extract_data()
transformed_data = transform_data(raw_data)
load_data(transformed_data)
# Running the flow
if __name__ == "__main__":
etl()Le code ci-dessus définit les fonctions de tâches extract_data(),transform_data() et load_data()et les exécute en série dans une fonction de flux appelée etl(). Ces fonctions sont créées à l'aide des décorateurs de Prefect Python.
En bref, nous créons un DataFrame pandas, nous le transformons, puis nous affichons le résultat final à l'aide de print. Il s'agit d'un moyen simple de simuler un pipeline ETL.
Pour exécuter le flux de travail, il suffit de lancer le script Python à l'aide de la commande suivante.
$ python prefect_etl.py Comme nous pouvons le constater, l'exécution de notre flux de travail s'est déroulée avec succès.

Les journaux d'exécution des flux sont parfaits.
Nous allons maintenant déployer notre flux de travail afin de pouvoir l'exécuter selon un calendrier ou le déclencher en fonction d'un événement. Le déploiement du flux nous permet également de surveiller et de gérer plusieurs flux de travail de manière centralisée.
Pour déployer le flux, nous utiliserons le CLI de Prefect. La fonction deploy requiert le nom du fichier Python, le nom de la fonction de flux dans le fichier et le nom du déploiement. Dans ce cas, nous appelons ce déploiement "simple_etl".
$ prefect deploy prefect_etl.py:etl -n 'simple_etl'Après avoir exécuté le script ci-dessus dans le terminal, il se peut que nous recevions un message indiquant que nous n'avons pas de pool de travailleurs pour exécuter le déploiement. Pour créer le pool de travailleurs, utilisez la commande suivante.
$ prefect worker start --pool 'datacamp'Maintenant que nous avons un pool de travailleurs, nous allons lancer une autre fenêtre de terminal et exécuter le déploiement. La commande prefect deployment run requiert l'argument "<nom de la fonction de flux>/<nom du déploiement>", comme le montre la commande ci-dessous.
$ prefect deployment run 'etl/simple_etlSuite à l'exécution du déploiement, vous recevrez un message indiquant que le flux de travail est en cours d'exécution. En général, le flux créé reçoit un nom aléatoire, dans mon cas witty-lorikeet.
Creating flow run for deployment 'etl/simple_etl'...
Created flow run 'witty-lorikeet'.
└── UUID: 4e0495b0-9c7e-4ed8-b9ab-5160994dc7f0
└── Parameters: {}
└── Job Variables: {}
└── Scheduled start time: 2024-06-22 14:05:01 PKT (now)
└── URL: <no dashboard available>Pour voir le journal complet, revenez à la fenêtre du terminal où vous avez démarré le pool de travailleurs.
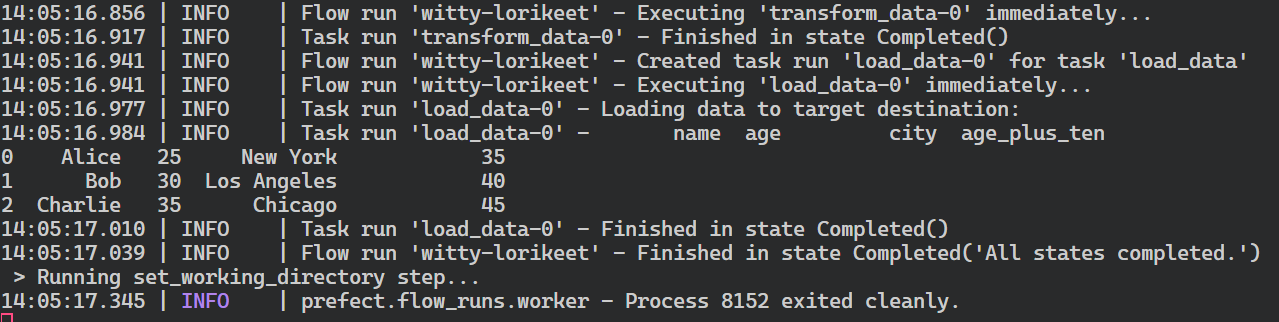
Résumé de l'exécution du flux parfait.
Vous devez lancer le serveur web de Prefect pour visualiser l'exécution du flux de manière plus conviviale et gérer d'autres flux de travail.
$ prefect server start Après avoir exécuté la commande ci-dessus, vous devriez être redirigé vers le tableau de bord de Prefect. Vous pouvez également vous rendre directement sur le site http://127.0.0.1:4200 dans votre navigateur.
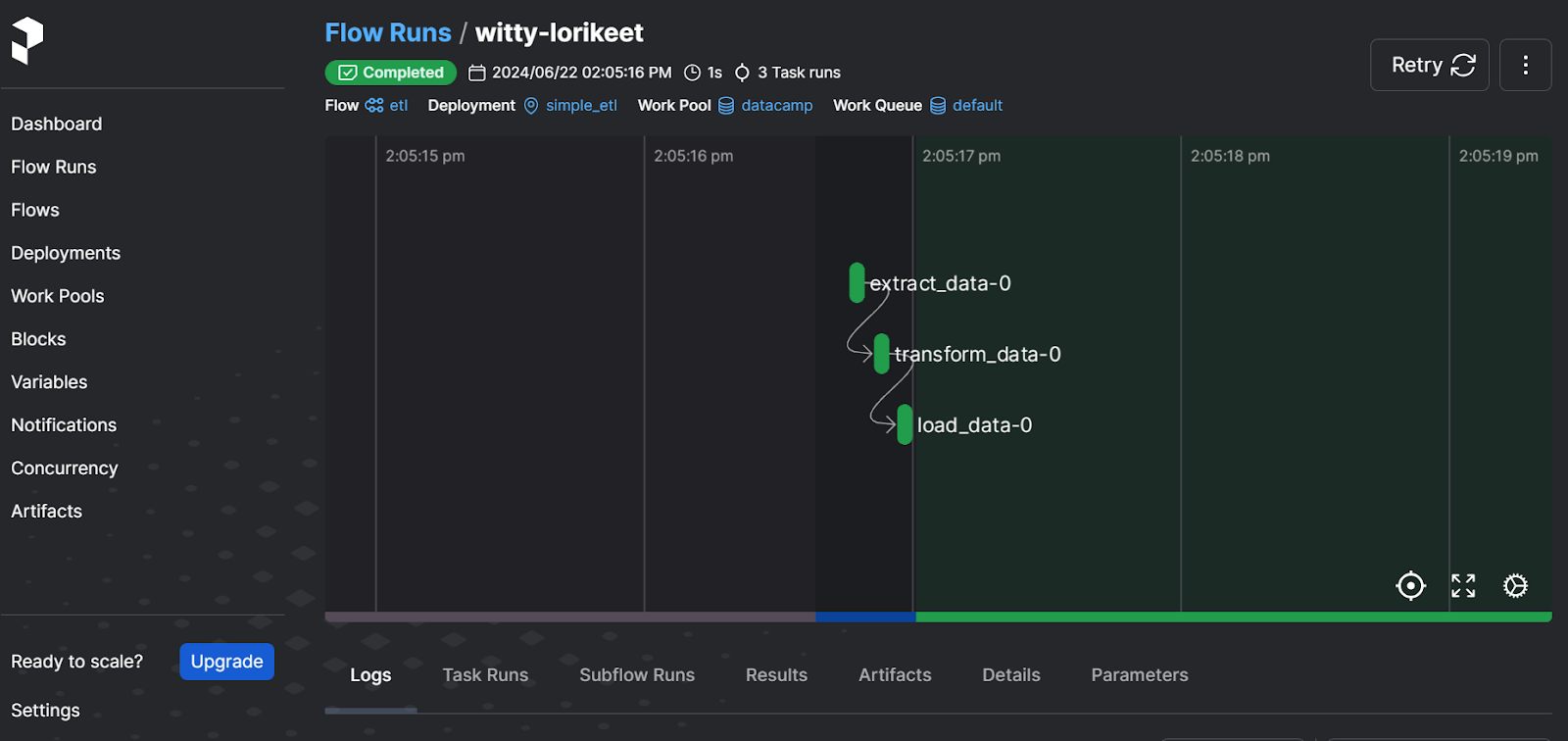
L'interface utilisateur du serveur web idéal
Le tableau de bord vous permet de réexécuter le flux de travail, de consulter les journaux, de vérifier les pools de travail, de définir des notifications et de sélectionner d'autres options avancées. Il s'agit d'une solution complète pour vos besoins en matière d'orchestration de données modernes.
Pour apprendre comment construire et exécuter des pipelines d'apprentissage automatique en utilisant Prefect, vous pouvez suivre les instructions suivantes Utiliser Prefect pour les workflows d'apprentissage automatique .
Dasgter est un framework open-source conçu pour les ingénieurs de données afin de définir, planifier et surveiller les pipelines de données. Il est très évolutif et facilite la collaboration entre les différentes équipes chargées des données.
Dagster permet aux utilisateurs de définir leurs ressources de données comme des fonctions Python à l'aide de décorateurs. Une fois ces actifs définis, les utilisateurs peuvent les exécuter de manière transparente par le biais d'une planification ou de déclencheurs basés sur des événements.
Par rapport à Airflow, Dagster nous permet de développer, tester et réviser le pipeline localement, fournit une approche de l'orchestration basée sur les actifs, et est native pour le cloud et les conteneurs.
Au lieu de penser au flux de travail en termes d'étapes et de flux, j'ai dû changer ma façon de penser et construire un pipeline en utilisant des données. En dehors de cela, la construction et l'exécution d'un pipeline ETL simple ont été assez simples. De même, le serveur web est relativement minimal mais fournit toutes les informations nécessaires au suivi des actifs, des exécutions et des déploiements.
Abid Ali Awan, Author
Nous allons créer un pipeline ETL simple, l'exécuter et le visualiser à l'aide du serveur web Dagster. Similaire au tableau de bord de Prefect, le serveur web de Dagster fournit des moyens centralisés de contrôler plusieurs flux de travail et de programmer des exécutions et des actifs.
Nous allons commencer par installer le paquetage Python.
$ pip install dagster -qEnsuite, nous créerons trois fonctions Python pour l'extraction, la transformation et le chargement des données. Ces fonctions sont appelées create_dirty_data(),clean_data(), et load_cleaned_data()dans le code. En utilisant le décorateur @asset, nous déclarons les fonctions comme des ressources de données dans Dagster.
Ensuite, nous allons créer le travail de l'actif (job variable) en utilisant tous les actifs (all_assets variable), puis nous créerons la définition de l'actif (defs variable).
Vous pouvez ignorer la partie relative à la définition des actifs, mais elle devient importante si vous souhaitez planifier votre exécution, exécuter plusieurs tâches et configurer des capteurs.
import pandas as pd
import numpy as np
from dagster import asset, Definitions, define_asset_job, materialize
@asset
def create_dirty_data():
# Create a sample DataFrame with dirty data
data = {
'Name': [' John Doe ', 'Jane Smith', 'Bob Johnson ', ' Alice Brown'],
'Age': [30, np.nan, 40, 35],
'City': ['New York', 'los angeles', 'CHICAGO', 'Houston'],
'Salary': ['50,000', '60000', '75,000', 'invalid']
}
df = pd.DataFrame(data)
# Save the DataFrame to a CSV file
dirty_file_path = 'dag_data/dirty_data.csv'
df.to_csv(dirty_file_path, index=False)
return dirty_file_path
@asset
def clean_data(create_dirty_data):
# Read the dirty CSV file
df = pd.read_csv(create_dirty_data)
# Clean the data
df['Name'] = df['Name'].str.strip()
df['Age'] = pd.to_numeric(df['Age'], errors='coerce').fillna(df['Age'].mean())
df['City'] = df['City'].str.upper()
df['Salary'] = df['Salary'].replace('[\$,]', '', regex=True)
df['Salary'] = pd.to_numeric(df['Salary'], errors='coerce').fillna(0)
# Calculate average salary
avg_salary = df['Salary'].mean()
# Save the cleaned DataFrame to a new CSV file
cleaned_file_path = 'dag_data/cleaned_data.csv'
df.to_csv(cleaned_file_path, index=False)
return {
'cleaned_file_path': cleaned_file_path,
'avg_salary': avg_salary
}
@asset
def load_cleaned_data(clean_data):
cleaned_file_path = clean_data['cleaned_file_path']
avg_salary = clean_data['avg_salary']
# Read the cleaned CSV file to verify
df = pd.read_csv(cleaned_file_path)
print({
'num_rows': len(df),
'num_columns': len(df.columns),
'avg_salary': avg_salary
})
# Define all assets
all_assets = [create_dirty_data, clean_data, load_cleaned_data]
# Create a job that will materialize all assets
job = define_asset_job("all_assets_job", selection=all_assets)
# Create Definitions object
defs = Definitions(
assets=all_assets,
jobs=[job]
)
if __name__ == "__main__":
result = materialize(all_assets)
print("Pipeline execution result:", result.success)Vous pouvez exécuter le code ci-dessus dans un carnet Jupyter ou créer le fichier Python et l'exécuter.
Après avoir exécuté le code, nous obtiendrons un journal complet de l'exécution du flux de travail.
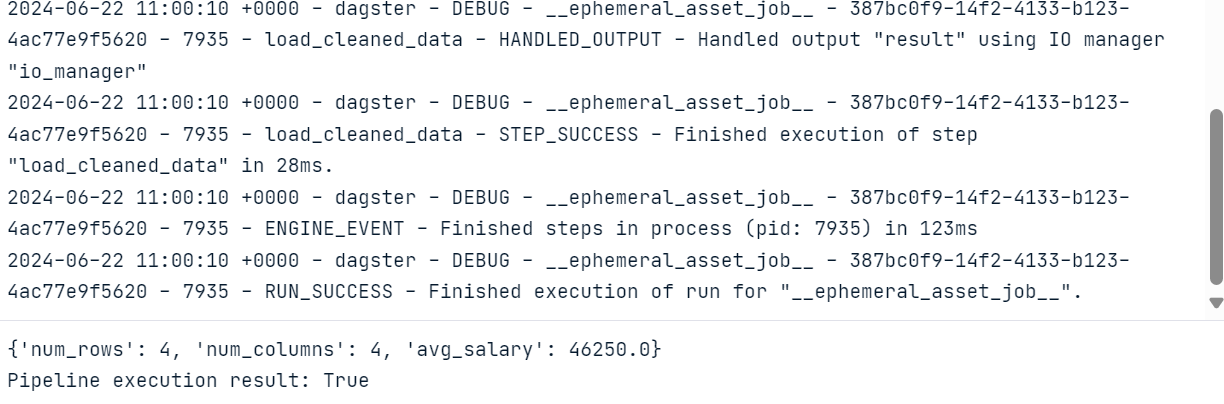
Pour visualiser les actifs et les travaux, nous devons installer et exécuter le serveur web Dagster. Le serveur web vous permet d'exécuter les tâches, de matérialiser des actifs individuels et de contrôler plusieurs tâches à la fois.
$ pip install dagster-webserverPour lancer le serveur Python, nous allons utiliser le CLI de Python et lui fournir l'emplacement du fichier Python. Dans ce cas, j'ai nommé le fichier dagster_pipe.py.
$ dagster dev -f dagster_pipe.py La commande ci-dessus lancera automatiquement le serveur web sur votre navigateur. Vous pouvez également vous rendre directement sur le site http://127.0.0.1:3000 dans votre navigateur.
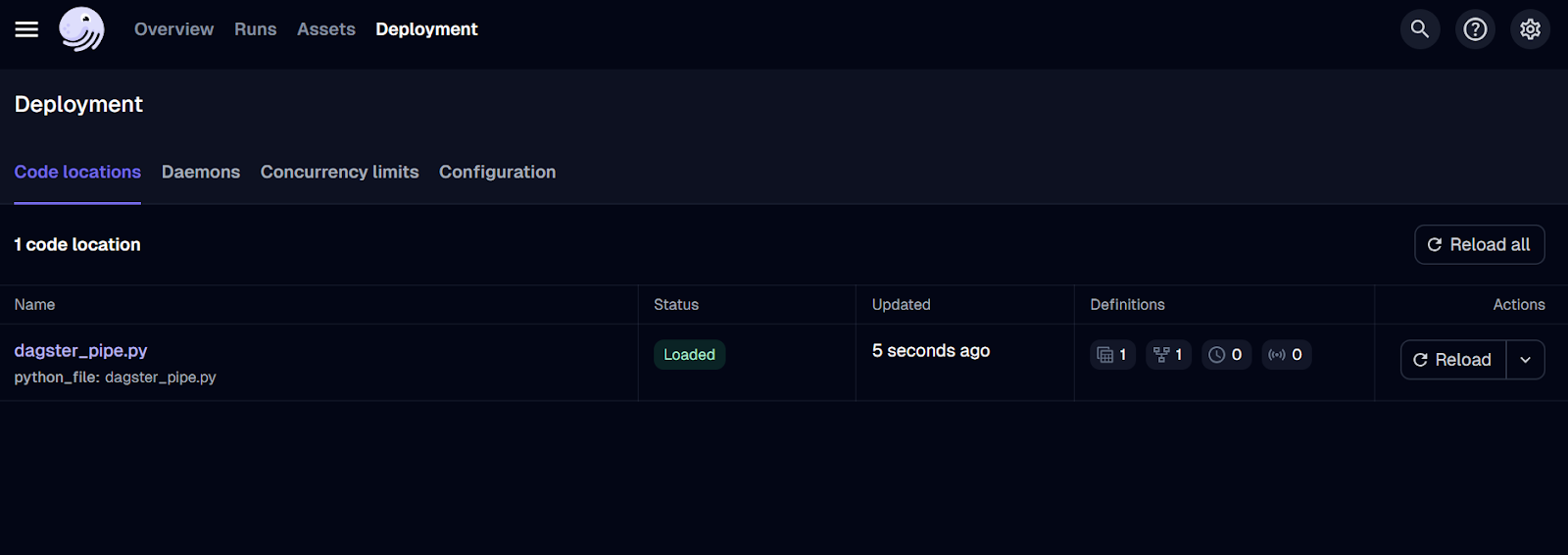
Interface utilisateur du serveur web Dagster.
Jusqu'à présent, nous n'avons fait que déployer le travail. Pour exécuter le flux de travail, allez dans l'onglet "Exécutions" et cliquez sur le bouton "Lancer une nouvelle exécution".
L'exécution devrait être terminée avec succès ! Pour consulter les journaux, cliquez sur l'identifiant de l'exécution qui vous intéresse.
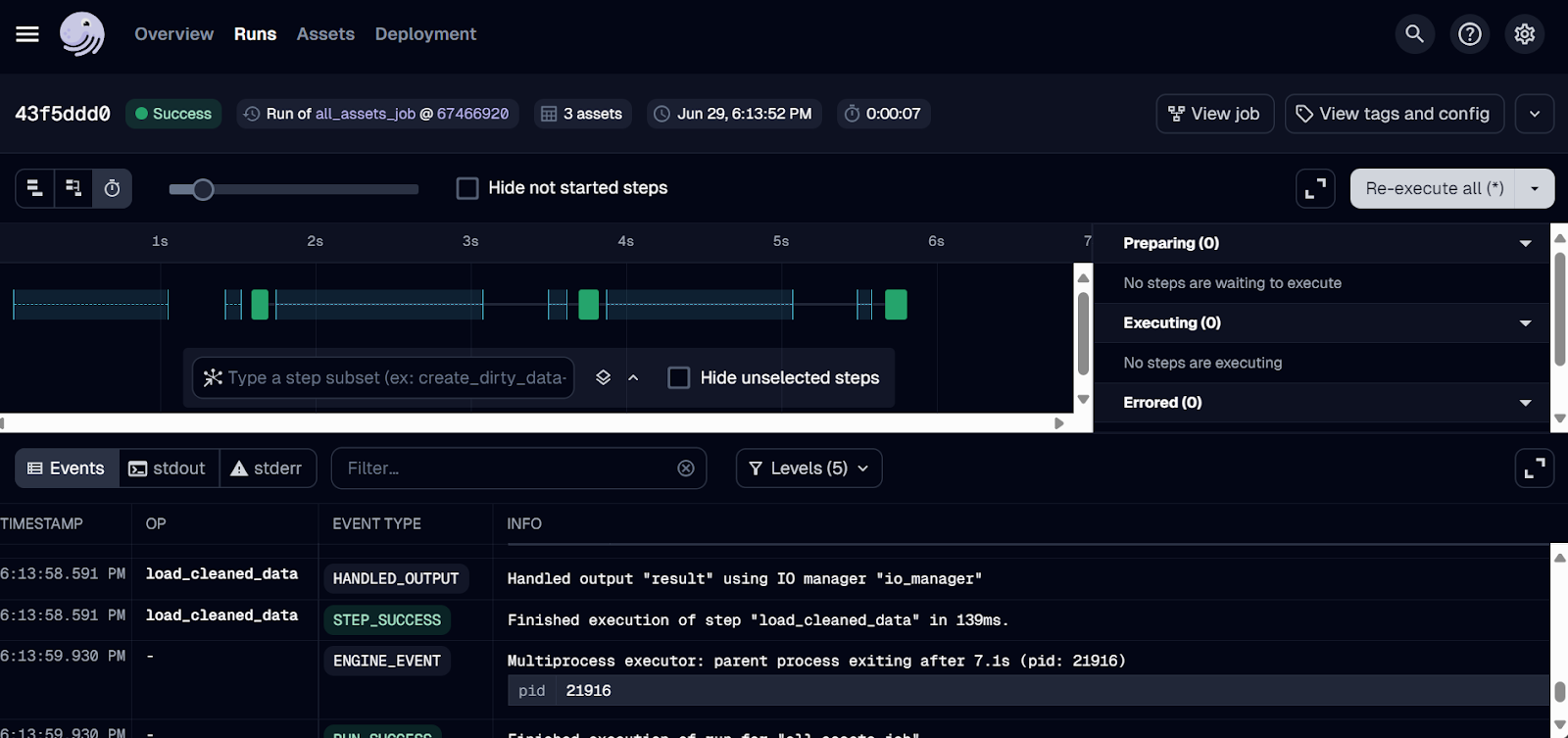
Journal de bord de Dagster.
Mage AI est un cadre d'orchestration de données hybrides open-source. Hybride signifie que vous bénéficiez de la flexibilité d'un carnet Jupyter et du contrôle d'un code modulaire.
N'importe qui, même avec une connaissance limitée de Python, peut construire, exécuter et surveiller des pipelines de données. Au lieu d'écrire et d'exécuter directement un fichier Python, vous créerez un projet Mage AI et le lancerez dans le tableau de bord, où vous pourrez construire, exécuter et gérer vos pipelines de données.
Comparé à Airflow, Mage AI offre une interface conviviale et une facilité d'utilisation, ce qui en fait un excellent choix pour ceux qui débutent dans l'ingénierie des données. Il a été conçu dans un souci d'évolutivité et est capable de traiter efficacement de grands volumes de données et des structures de pipeline complexes.
Je me suis sentie bizarre parce que c'était complètement différent de ce à quoi j'étais habituée. J'ai dû installer et lancer l'interface web de Mage AI. C'était censé être facile, mais j'ai eu du mal à construire et à faire fonctionner le pipeline ETL. D'un autre côté, je comprends pourquoi cette conception unique peut attirer les personnes qui débutent dans le domaine, puisqu'il s'agit essentiellement de glisser-déposer et d'appuyer sur des boutons.
Abid Ali Awan, Author
Le démarrage de l'IA Mage est assez simple. Il nous suffit d'installer le paquetage Python de Mage AI.
$ pip install mage-aiEt lancez le projet Mage AI.
$ mage start mage_ai_etl La commande ci-dessus lancera le serveur web. Comme nous l'avons déjà mentionné, toutes les opérations d'édition de code, d'exécution et de contrôle des tâches sont effectuées à partir de l'interface utilisateur de Mage AI.
Mage AI UI.
Cliquez sur "+ New pipeline" pour créer votre premier pipeline ETL. J'ai nommé le mien "simple_etl".
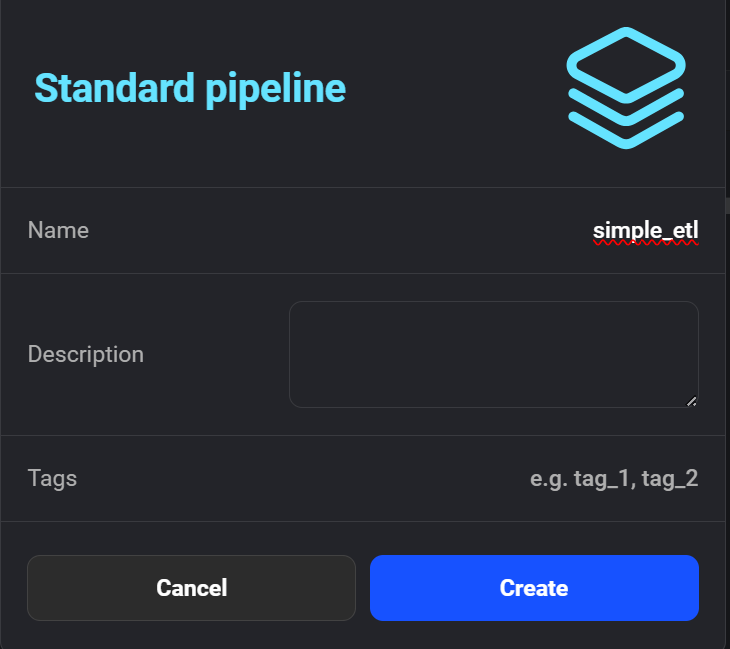
Création du nouveau pipeline dans Mage AI.
Ensuite, l'interface vous demandera d'ajouter un module pour commencer à coder. Sélectionnez le module "Data Loader" et écrivez le code Python suivant.
Nous déclarons ici une fonctioncreate_sample_csv(), qui constitue la première étape de notre pipeline. Nous utilisons le décorateur Mage AI @data_loader. Nous définissons également une fonction test_output() qui affirme que la sortie existe. Cela facilite la gestion de la dépendance des tâches.
import io
import pandas as pd
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def create_sample_csv() -> pd.DataFrame:
"""
Create a sample CSV file with duplicates and missing values
"""
csv_data = """
category,product,quantity,price
Electronics,Laptop,5,1000
Electronics,Smartphone,10,500
Clothing,T-shirt,50,20
Clothing,Jeans,30,50
Books,Novel,100,15
Books,Textbook,20,80
Electronics,Laptop,5,1000
Clothing,T-shirt,,20
Electronics,Tablet,,300
Books,Magazine,25,
"""
return pd.read_csv(io.StringIO(csv_data.strip()))
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'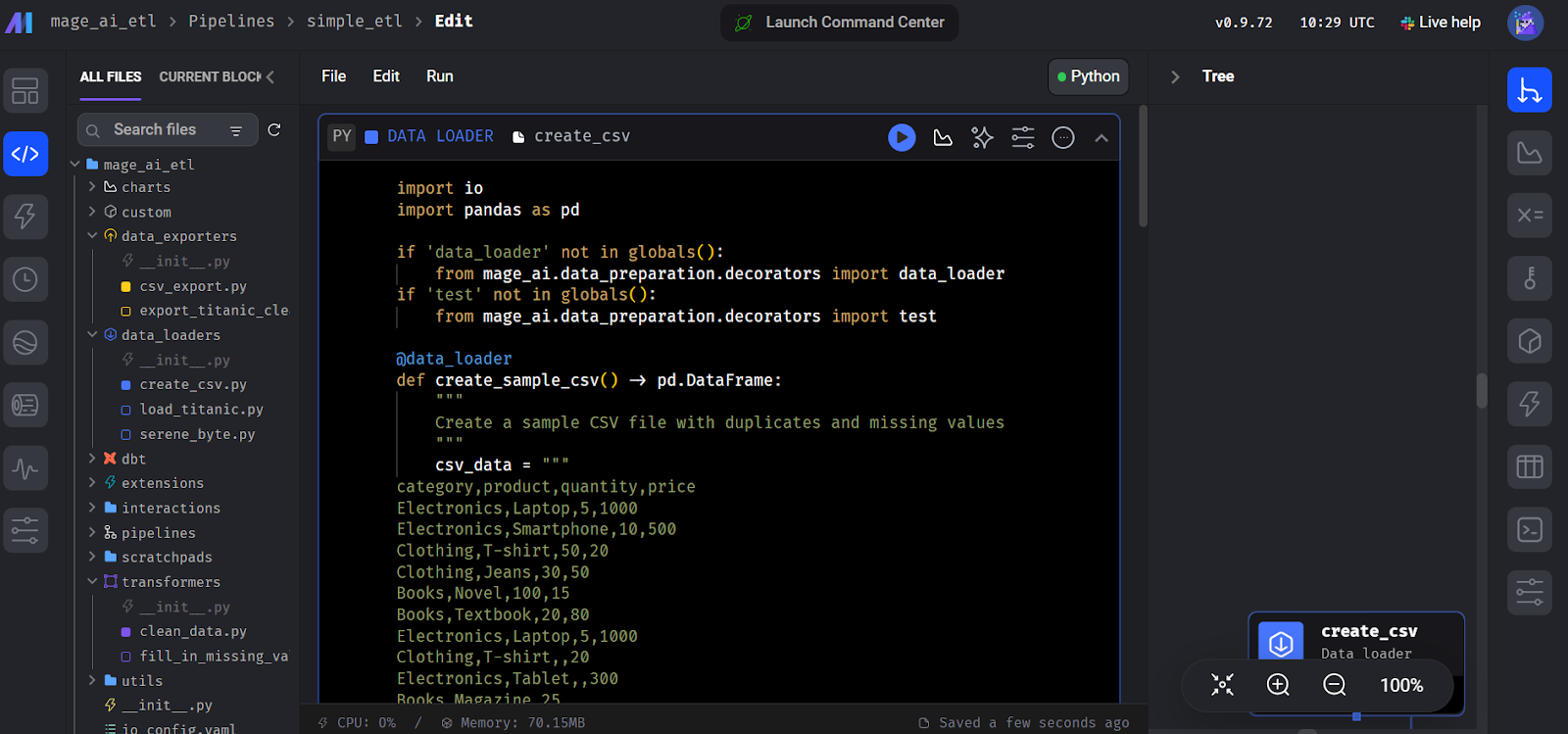
Création du bloc de chargement de données dans Mage AI.
Ensuite, créez un autre module appelé "Transformer" et ajoutez la fonction clean_data() comme le montre le code ci-dessous.
Vous pouvez ignorer la fonction test() il vous suffit d'ajouter la fonction principale du transformateur, clean_data().
import pandas as pd
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
"""
Clean and transform the data
"""
# Remove duplicates
df = df.drop_duplicates()
# Fill missing values with 0
df = df.fillna(0)
return df
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'De même, créez un module "Data Exporter" et ajoutez le code suivant. Le code déclare une fonction de chargement de données, export_data_to_csv(), qui enregistre les données transformées dans un fichier CSV .
import pandas as pd
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_csv(df: pd.DataFrame) -> None:
"""
Export the processed data to a CSV file
"""
df.to_csv('output_data.csv', index=False)
print("Data exported successfully to output_data.csv")Pour lancer le pipeline, allez dans l'onglet "Trigger" et cliquez sur "Run@once".
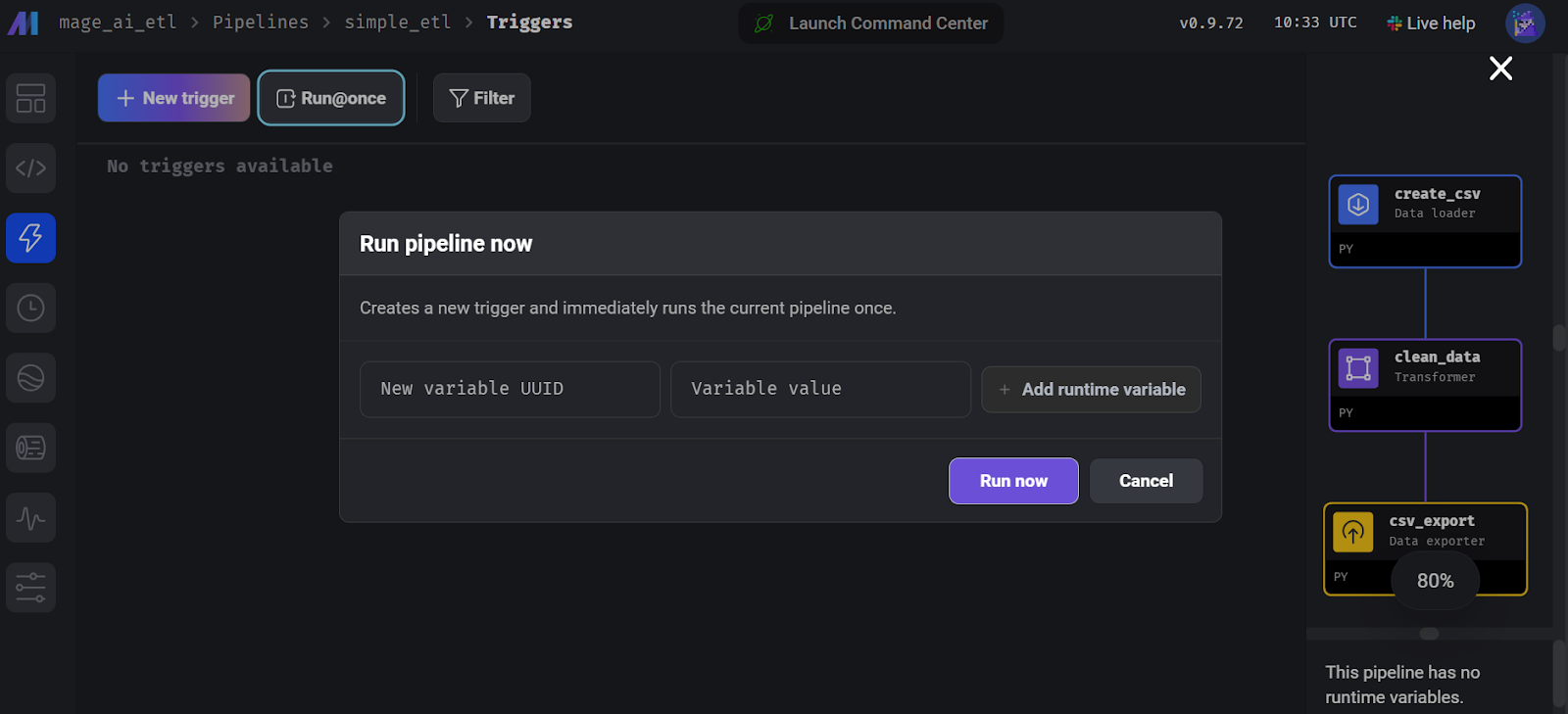
Exécution du pipeline dans Mage AI.
Pour consulter les journaux d'exécution, allez dans l'onglet "Exécutions" et cliquez sur le bouton "Journaux" du pipeline récemment exécuté.
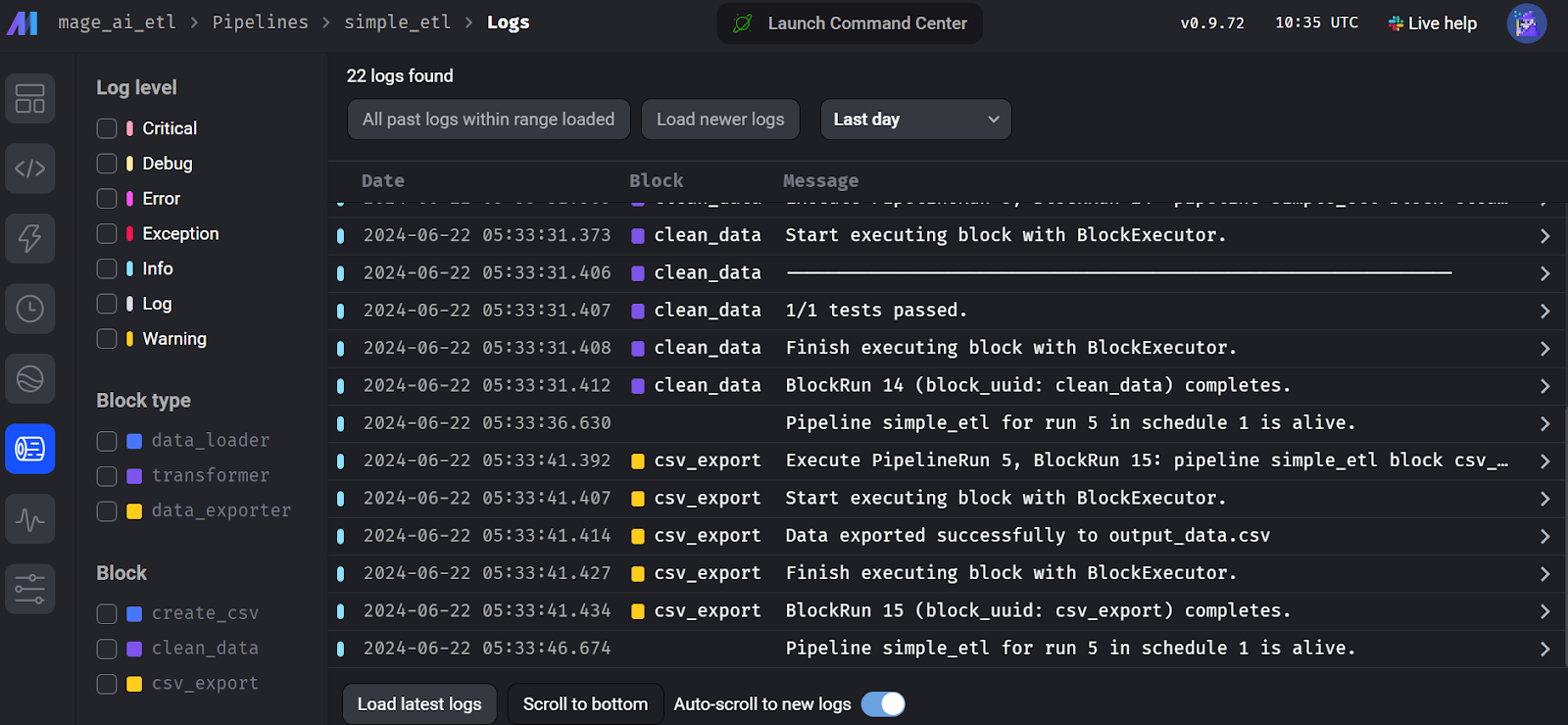
Journaux d'exécution du flux d'IA des mages.
Kedro est un autre cadre d'orchestration de données open-source populaire qui est légèrement différent des autres outils. Il a été créé pour les ingénieurs en apprentissage automatique et emprunte de nombreux concepts à l'ingénierie logicielle, en les appliquant aux projets d'apprentissage automatique.
Kedro est conçu pour être hautement modulaire, ce qui signifie que même pour exporter un ensemble de données, vous devez créer un catalogue de données qui spécifie l'emplacement et le type de données, garantissant une gestion standardisée et efficace des données tout au long du pipeline.
Pour comprendre comment Kedro s'inscrit dans l'écosystème de l'apprentissage automatique, vous pouvez explorer différents outils MLOps en lisant l'article. 25 Top MLOps Tools You Need to Know in 2024 (en anglais).
Par rapport à Airflow, l'API de Kedro est plus simple pour construire un pipeline de données. Il se concentre davantage sur l'ingénierie de l'apprentissage automatique et propose la catégorisation et le versionnage des données.
La partie codage est assez simple, mais des problèmes se posent lorsque vous voulez exécuter votre pipeline. Vous devez créer un catalogue de données, enregistrer le pipeline et déterminer la structure du projet Kedro. Je dirais qu'il est plus difficile que Dagster et Prefect. Cependant, je comprends pourquoi il est conçu de cette manière : pour que votre pipeline de données soit fiable et exempt d'erreurs.
Abid Ali Awan, Author
La construction d'un pipeline de données Kedro est une autre paire de manches. Le cadre est modulaire et vous devez comprendre la structure du projet et les différentes étapes impliquées pour exécuter le flux de travail avec succès.
Commencez par installer le paquetage Python de Kedro.
$ pip install kedroInitialiser le projet Kedro.
$ kedro new --name=kedro_etl --tools=none --example=n Déplacez-vous dans le répertoire du projet.
$ cd kedro-etl Créez un dossier dans le dossier pipelines appelé data_processing.
$ mkdir -p src/kedro_etl/pipelines/data_processing Créez un fichier Python appelé kedro_pipe.py et ouvrez-le dans votre IDE préféré, par exemple Visual Studio Code.
$ code src/kedro_etl/pipelines/data_processing/kedro_pipe.pyLe script Python doit contenir les fonctions d'extraction, de transformation et de chargement, qui sont des nœuds du pipeline. Dans ce cas, il s'agit des fonctions create_sample_data(),clean_data() et load_and_process_data().
Ensuite, nous joignons ces nœuds à l'aide de la classe Kedro Pipeline dans la fonctioncreate_pipeline(). Dans la fonction pipeline, nous définissons des nœuds, et chaque nœud possède inputs,outputs, et un nœud name.
import pandas as pd
import numpy as np
from kedro.pipeline import Pipeline, node
def create_sample_data():
data = {
'id': range(1, 101),
'name': [f'Person_{i}' for i in range(1, 101)],
'age': np.random.randint(18, 80, 100),
'salary': np.random.randint(20000, 100000, 100),
'missing_values': [np.nan if i % 10 == 0 else i for i in range(100)]
}
return pd.DataFrame(data)
def clean_data(df: pd.DataFrame):
# Remove rows with missing values
df_cleaned = df.dropna()
# Convert salary to thousands
df_cleaned['salary'] = df_cleaned['salary'] / 1000
# Capitalize names
df_cleaned['name'] = df_cleaned['name'].str.upper()
return df_cleaned
def load_and_process_data(df: pd.DataFrame):
# Calculate average salary
avg_salary = df['salary'].mean()
# Add a new column for salary category
df['salary_category'] = df['salary'].apply(
lambda x: 'High' if x > avg_salary else 'Low')
# Calculate age groups
df['age_group'] = pd.cut(df['age'], bins=[0, 30, 50, 100], labels=[
'Young', 'Middle', 'Senior'])
print(df)
return df
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=create_sample_data,
inputs=None,
outputs="raw_data",
name="create_sample_data_node",
),
node(
func=clean_data,
inputs="raw_data",
outputs="cleaned_data",
name="clean_data_node",
),
node(
func=load_and_process_data,
inputs="cleaned_data",
outputs="processed_data",
name="load_and_process_data_node",
),
]
)Si nous exécutons le pipeline sans créer le catalogue de données, il n'exportera pas nos données. Nous devons donc nous rendre dans le fichier conf/base/catalog.yml et le modifier en fournissant la configuration du jeu de données.
raw_data:
type: pandas.CSVDataset
filepath: ./data/kedro/sample_data.csv
cleaned_data:
type: pandas.CSVDataset
filepath: ./data/kedro/cleaned_data.csv
processed_data:
type: pandas.CSVDataset
filepath: ./data/kedro/processed_data.csvNous devons également inclure notre fichier Python nouvellement créé dans le registre du pipeline. Pour ce faire, allez dans le fichier src/simple_etl/pipeline_registry.py Python et incluez le code suivant.
"""Project pipelines."""
from __future__ import annotations
from kedro.pipeline import Pipeline
from kedro_etl.pipelines.data_processing import kedro_pipe
def register_pipelines() -> Dict[str, Pipeline]:
data_processing_pipeline = kedro_pipe.create_pipeline()
return {
"__default__": data_processing_pipeline,
"data_processing": data_processing_pipeline,
}Exécutez le pipeline et visualisez les journaux en direct dans le terminal en exécutant la commande suivante.
$ kedro run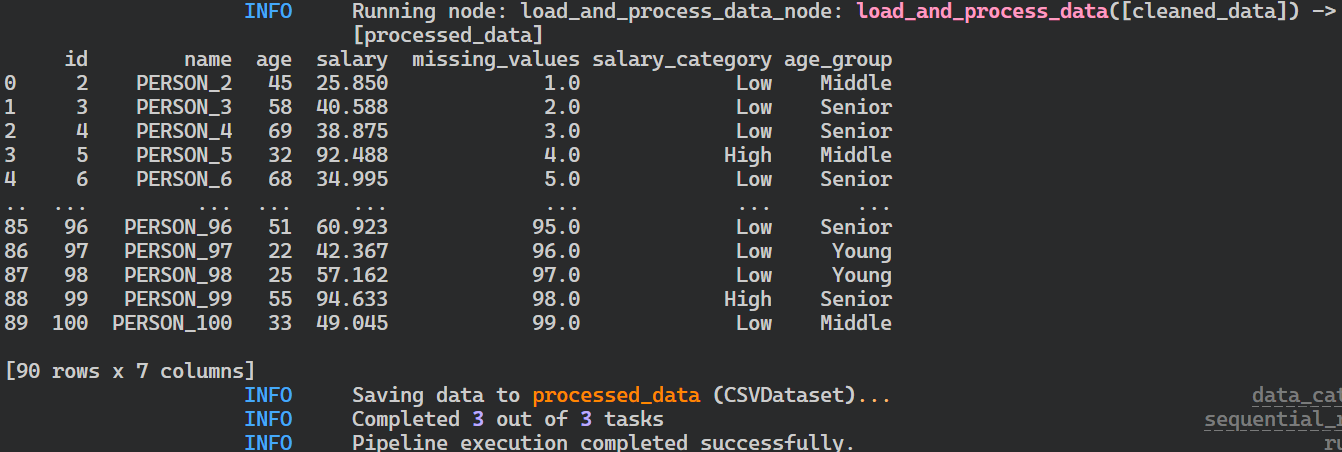
Journaux d'exécution du pipeline Kedro.
Après l'exécution du pipeline, vos fichiers seront stockés au format CSV à l'emplacement défini dans le catalogue de données.
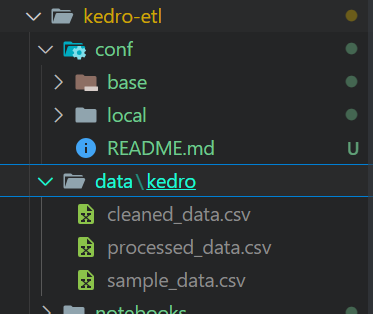
Fichiers de sortie de l'exécution du pipeline Kedro.
Si vous rencontrez des problèmes lors de l'exécution du pipeline, envisagez d'installer Kedro avec toutes les extensions.
$ pip install "kedro[all]"Nous pouvons visualiser et partager nos pipelines en installant l' outil kedro-viz .
$ pip install kedro-vizEnsuite, l'exécution de la commande suivante nous permettra de visualiser tous les pipelines de données et les nœuds de données. Il offre également une option de traçage des expériences et la possibilité de partager la visualisation du pipeline.
$ kedro viz run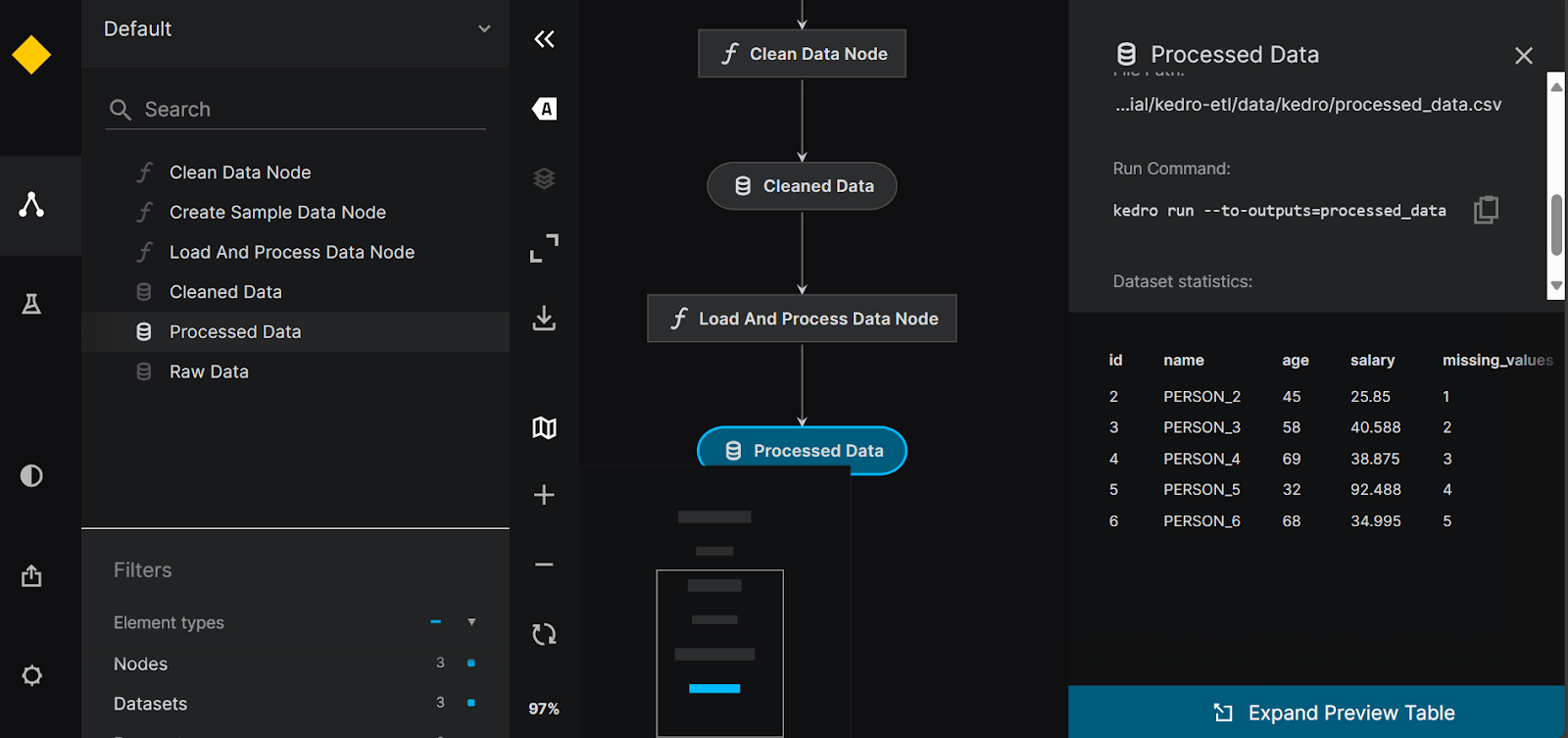
Visualisation du pipeline Kedro.
Luigi est un framework open-source, basé sur Python et développé par Spotify, qui excelle dans la gestion des processus batch de longue durée et des pipelines de données complexes. Il est performant en matière de résolution des dépendances, de gestion des flux de travail, de visualisation et de reprise sur panne, ce qui en fait un outil puissant pour l'orchestration des flux de travail de données.
Par rapport à Airflow, Luigi dispose d'une API minimale, d'un calendrier et d'une base d'utilisateurs fidèles qui vous aideront à résoudre tous les problèmes liés au pipeline d'orchestration des données.
Si vous êtes débutant en Python, vous aurez peut-être du mal à construire et à exécuter les pipelines. Toutefois, la documentation et les guides peuvent vous aider à démarrer rapidement. Les journaux fournissent des informations limitées et le tableau de bord n'est qu'un outil de visualisation des DAG et des dépendances.
Abid Ali Awan, Author
La création d'un pipeline de données Luigi nécessite une compréhension de la programmation orientée objet. Commençons par installer le paquetage Luigi Python.
$ pip install luigiPour développer un pipeline ETL simple dans Luigi, nous allons créer des tâches interconnectées. Au lieu de créer des fonctions Python en tant que tâches, nous allons créer une classe Python pour chaque étape du pipeline, FetchData,ProcessData et GenerateReport. Chaque classe aura trois fonctions appelées : requires(), output(), et run().
Les fonctions requires() et output() connectent les tâches et la fonctionrun() exécute le code de traitement. Enfin, nous construirons le pipeline en utilisant la dernière tâche du pipeline.
import luigi
import pandas as pd
import numpy as np
class FetchData(luigi.Task):
def output(self):
return luigi.LocalTarget('data/fetch_data.csv')
def run(self):
# Simulate fetching data by creating a sample CSV file
data = {
'column1': [1, 2, np.nan, 4],
'column2': ['A', 'B', 'C', np.nan]
}
df = pd.DataFrame(data)
df.to_csv(self.output().path, index=False)
class ProcessData(luigi.Task):
def requires(self):
return FetchData()
def output(self):
return luigi.LocalTarget('data/process_data.csv')
def run(self):
df = pd.read_csv(self.input().path)
# Fill missing values
df['column1'].fillna(df['column1'].mean(), inplace=True)
df['column2'].fillna('B', inplace=True)
df.to_csv(self.output().path, index=False)
class GenerateReport(luigi.Task):
def requires(self):
return ProcessData()
def output(self):
return luigi.LocalTarget('data/generate_report.txt')
def run(self):
df = pd.read_csv(self.input().path)
# Simple data analysis: calculate mean of column1 and value counts of column2
mean_column1 = df['column1'].mean()
value_counts_column2 = df['column2'].value_counts()
with self.output().open('w') as out_file:
out_file.write(f'Mean of column1: {mean_column1}\n')
out_file.write('Value counts of column2:\n')
out_file.write(value_counts_column2.to_string())
if __name__ == '__main__':
luigi.build([GenerateReport()], local_scheduler=True)Exécutez le code ci-dessus dans le carnet Jupyter ou créez le fichier Python et exécutez-le à l'aide du terminal.
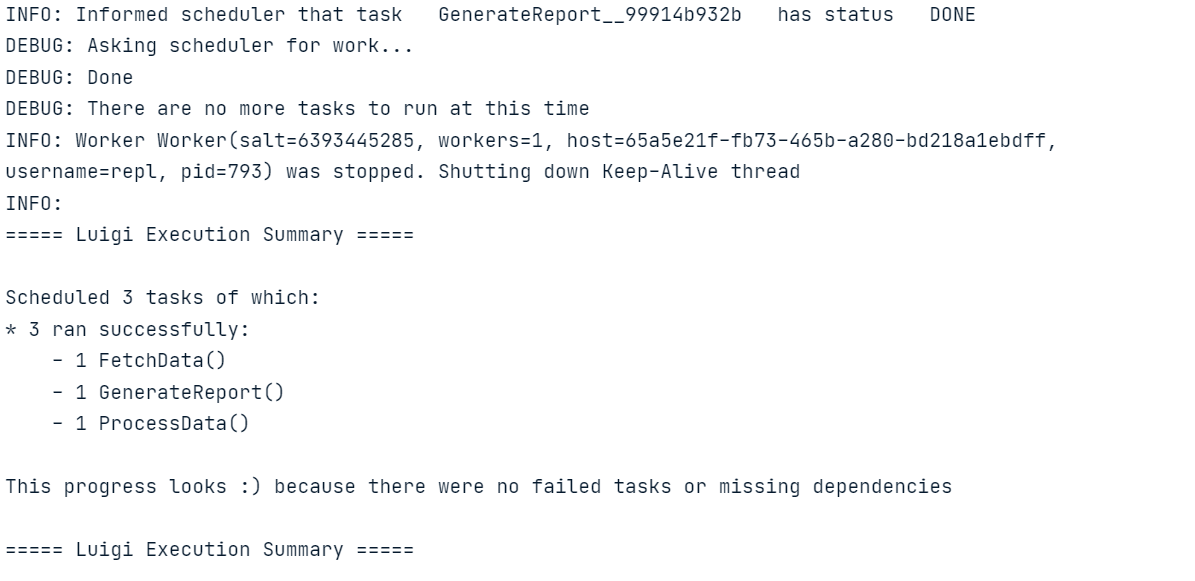
Comme pour Luigi, vous pouvez également apprendre à construire un pipeline ETL avec Apache Airflow. Ce tutoriel couvre les bases de l'extraction, de la transformation et du chargement de données avec Apache Airflow.
Nous devons initialiser le planificateur central Luigi afin de planifier les exécutions du pipeline ou de les déclencher à l'aide d'un événement.
Démarrez l'ordonnanceur en tapant la commande suivante dans le terminal.
$ luigid 2024-06-22 13:35:18,636 luigi[25056] INFO: logging configured by default settings
2024-06-22 13:35:18,636 luigi.scheduler[25056] INFO: No prior state file exists at /var/lib/luigi-server/state.pickle. Starting with empty state
2024-06-22 13:35:18,640 luigi.server[25056] INFO: Scheduler starting upPour lancer le pipeline, ouvrez un nouveau terminal et tapez la commande suivante. La commande Luigi nécessite un nom de fichier Python et la dernière tâche que nous voulons exécuter. Dans ce cas, le nom du fichier est luigi_pipe.py, et notre dernière tâche Luigi est GenerateReport.
$ python -m luigi --module luigi_pipe GenerateReportSi vous souhaitez visualiser l'état de l'exécution du pipeline et des tâches, il vous suffit de vous rendre à l'adresse suivante http://localhost:8082 dans votre navigateur.
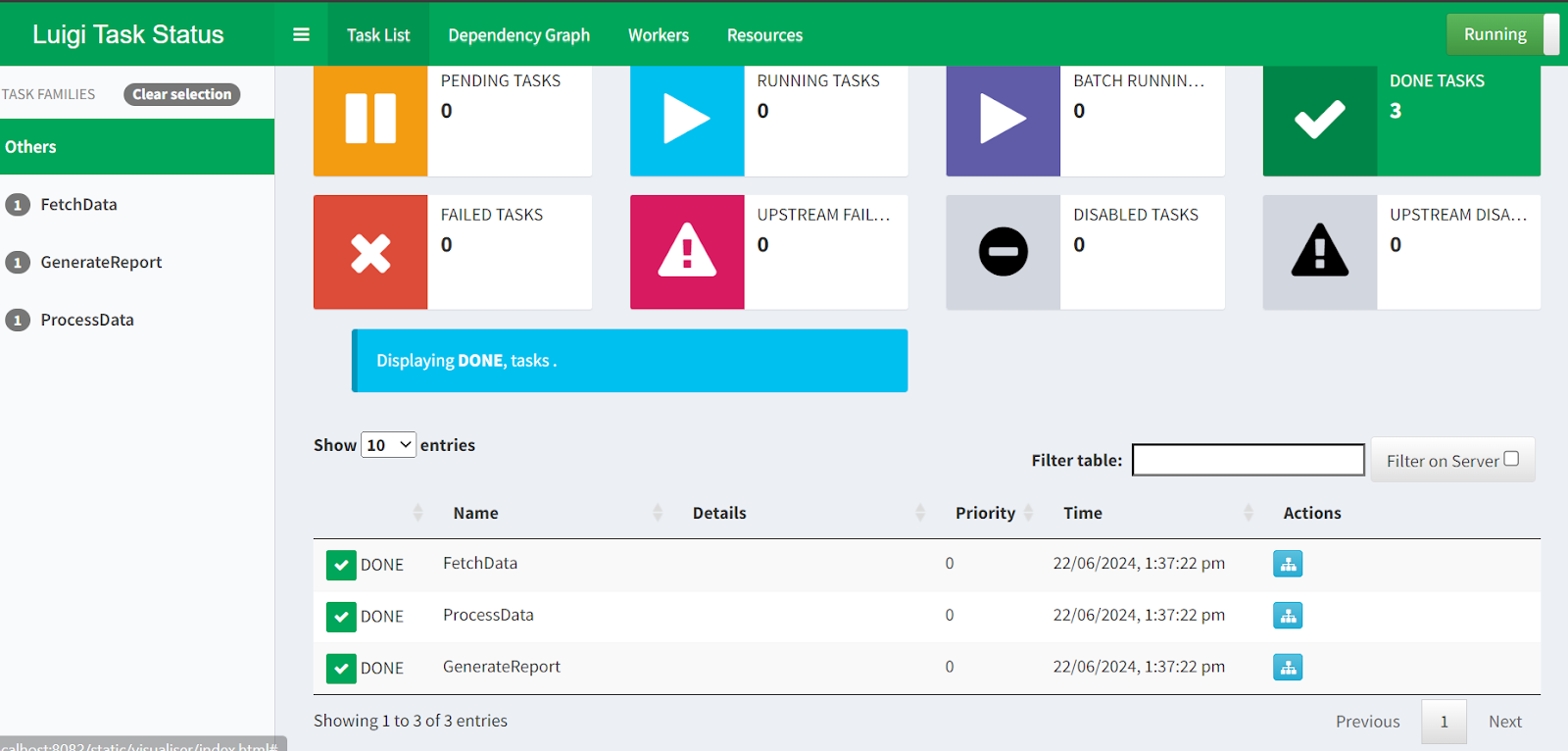
L'interface web du planificateur central Luigi.
Voilà qui conclut notre tour d'horizon des 5 meilleures alternatives à Airflow ! Si vous souhaitez approfondir l'un des exemples présentés dans cet article, voici quelques ressources à envisager :
Dans ce tutoriel, nous avons discuté des meilleures alternatives libres et gratuites à Airflow. Nous avons également appris à connaître chaque outil d'orchestration des données, et nous avons construit et exécuté un pipeline ETL simple. Des exemples de code vous aideront à choisir celui qui convient le mieux à votre cas d'utilisation.
Si vous êtes débutant, je vous suggère de commencer par Prefect ou Mage AI, car ils sont conviviaux et leur configuration est simple. Cependant, si vous recherchez des outils plus avancés qui adhèrent aux pratiques du génie logiciel, je vous recommande d'explorer Dagster, Kedro et Luigi.
Après avoir exploré cet article, la prochaine étape naturelle dans votre parcours d'ingénierie des données est d'obtenir une certification comme celle de DataCamp. Ingénieur de données en Python de DataCamp pour vous familiariser avec d'autres outils et construire un pipeline de données de bout en bout que vous pourrez déployer en production.
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cursus
Cours
Cours