Programa
Engenheiro de dados Em Python
40 h

Imagem do autor.
O Apache Airflow é uma ferramenta popular de orquestração de dados de código aberto projetada para criar, programar e monitorar pipelines de dados. Ele apresenta um painel que ajuda a gerenciar o estado dos fluxos de trabalho, tornando-o uma ferramenta perfeita para a maioria das necessidades de fluxo de trabalho.
No entanto, o Airflow carece de alguns recursos importantes que podem ser vitais para requisitos complexos e modernos de orquestração de dados.
Neste tutorial, exploraremos cinco alternativas ao Airflow que oferecem recursos aprimorados e abordam algumas de suas limitações. Além disso, aprenderemos a criar um pipeline ETL simples usando cada ferramenta, executá-lo e visualizá-lo em seu painel.
O Airflow é uma ferramenta poderosa para vários fluxos de trabalho de dados, mas tem várias limitações que podem fazer com que as empresas considerem alternativas.
Aqui estão alguns motivos pelos quais você pode escolher uma alternativa:
Antes de nos aprofundarmos na parte de codificação de outras ferramentas de orquestração de dados, é importante que você aprenda a escrever o pipeline de dados usando o Apache Airflow seguindo o guia Introdução ao Apache Airflow para que você possa comparar as alternativas de forma justa.
Se você for completamente novo no Airflow, considere fazer o breve curso Introdução ao Airflow em Python para que você aprenda os conceitos básicos de criação e programação de pipelines de dados.
Agora, vamos descrever as cinco principais alternativas ao Airflow e mostrar como você pode usá-las com exemplos práticos de código.
O Prefect é uma ferramenta de orquestração de fluxo de trabalho Python de código aberto criada para engenheiros modernos de dados e machine learning. Ele oferece uma API simples que permite que você crie um pipeline de dados rapidamente e o gerencie por meio de um painel interativo.
O Perfect oferece um modelo de execução híbrido, o que significa que você pode implantar o fluxo de trabalho na nuvem e executá-lo lá ou usar o repositório local.
Em comparação com o Airflow, o Prefect oferece recursos avançados, como dependências de tarefas automatizadas, acionadores baseados em eventos, notificações incorporadas, infraestrutura específica de fluxo de trabalho e compartilhamento de dados entre tarefas. Esses recursos fazem dele uma solução poderosa para gerenciar fluxos de trabalho complexos de forma eficiente e eficaz.
O Prefect é simples e oferece recursos avançados. Levei basicamente 5 minutos para executar o código de exemplo. Gosto especialmente da forma como a interface do usuário do painel foi projetada, como você pode configurar notificações, executar novamente pipelines, gerenciar e monitorar tudo por meio do painel.
Abid Ali Awan, Author
Leia Airflow vs. Prefect: Deciding Which is Right For Your Data Workflow blog para que você saiba mais sobre a comparação detalhada entre essas duas ferramentas de orquestração de dados .
Para iniciar nosso projeto Prefect, você deve instalar o pacote Python. Execute o seguinte comando em um terminal.
$ pip install -U prefectDepois disso, criaremos um script Python chamado prefect_etl.py e escreveremos o seguinte código.
from prefect import task, flow
import pandas as pd
# Extract data
@task
def extract_data():
# Simulating data extraction
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
return df
# Transform data
@task
def transform_data(df: pd.DataFrame):
# Example transformation: adding a new column
df["age_plus_ten"] = df["age"] + 10
return df
# Load data
@task
def load_data(df: pd.DataFrame):
# Simulating data load
print("Loading data to target destination:")
print(df)
# Defining the flow
@flow(log_prints=True)
def etl():
raw_data = extract_data()
transformed_data = transform_data(raw_data)
load_data(transformed_data)
# Running the flow
if __name__ == "__main__":
etl()O código acima define as funções de tarefa extract_data(),transform_data() e load_data()e as executa em série em uma função de fluxo denominada etl(). Essas funções são criadas usando os decoradores do Prefect Python.
Em resumo, estamos criando um DataFrame do pandas, transformando-o e, em seguida, exibindo o resultado final usando print. Essa é uma maneira simples de simular um pipeline de ETL.
Para executar o fluxo de trabalho, basta executar o script Python usando o seguinte comando.
$ python prefect_etl.py Como você pode ver, a execução do nosso fluxo de trabalho foi concluída com êxito.

Registros de execução de fluxo perfeitos.
Agora, implantaremos nosso fluxo de trabalho para que possamos executá-lo em um cronograma ou acioná-lo com base em um evento. A implementação do fluxo também nos permite monitorar e gerenciar vários fluxos de trabalho de forma centralizada.
Para implementar o fluxo, usaremos a CLI do Prefect. A função deploy requer o nome do arquivo Python, o nome da função de fluxo no arquivo e o nome da implantação. Nesse caso, estamos chamando essa implantação de "simple_etl".
$ prefect deploy prefect_etl.py:etl -n 'simple_etl'Depois de executar o script acima no terminal, podemos receber a mensagem de que não temos um pool de trabalho para executar a implantação. Para criar o pool de trabalho, use o seguinte comando.
$ prefect worker start --pool 'datacamp'Agora que temos um pool de trabalho, abriremos outra janela de terminal e executaremos a implantação. O comando prefect deployment run requer o "<flow-function-name>/<deployment-name>" como argumento, conforme mostrado no comando abaixo.
$ prefect deployment run 'etl/simple_etlComo resultado da execução da implantação, você receberá a mensagem de que o fluxo de trabalho está em execução. Normalmente, a execução de fluxo que é criada recebe um nome aleatório, no meu caso, witty-lorikeet.
Creating flow run for deployment 'etl/simple_etl'...
Created flow run 'witty-lorikeet'.
└── UUID: 4e0495b0-9c7e-4ed8-b9ab-5160994dc7f0
└── Parameters: {}
└── Job Variables: {}
└── Scheduled start time: 2024-06-22 14:05:01 PKT (now)
└── URL: <no dashboard available>Para ver o registro completo, volte para a janela do terminal em que você iniciou o pool de trabalhadores.
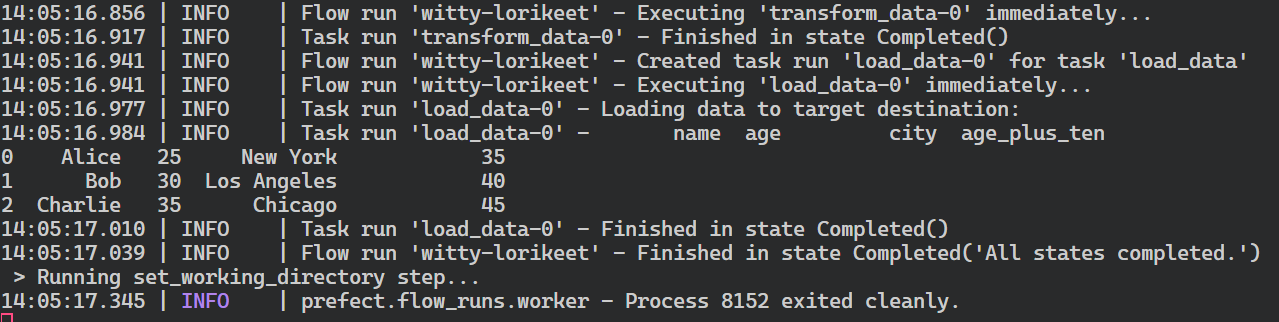
Resumo da execução do fluxo perfeito.
Você deve iniciar o servidor da Web do Prefect para visualizar a execução do fluxo de uma maneira mais fácil de usar e gerenciar outros fluxos de trabalho.
$ prefect server start Depois de executar o comando acima, você deverá ser redirecionado para o painel de controle do Prefect. Como alternativa, você pode ir diretamente para o site http://127.0.0.1:4200 em seu navegador.
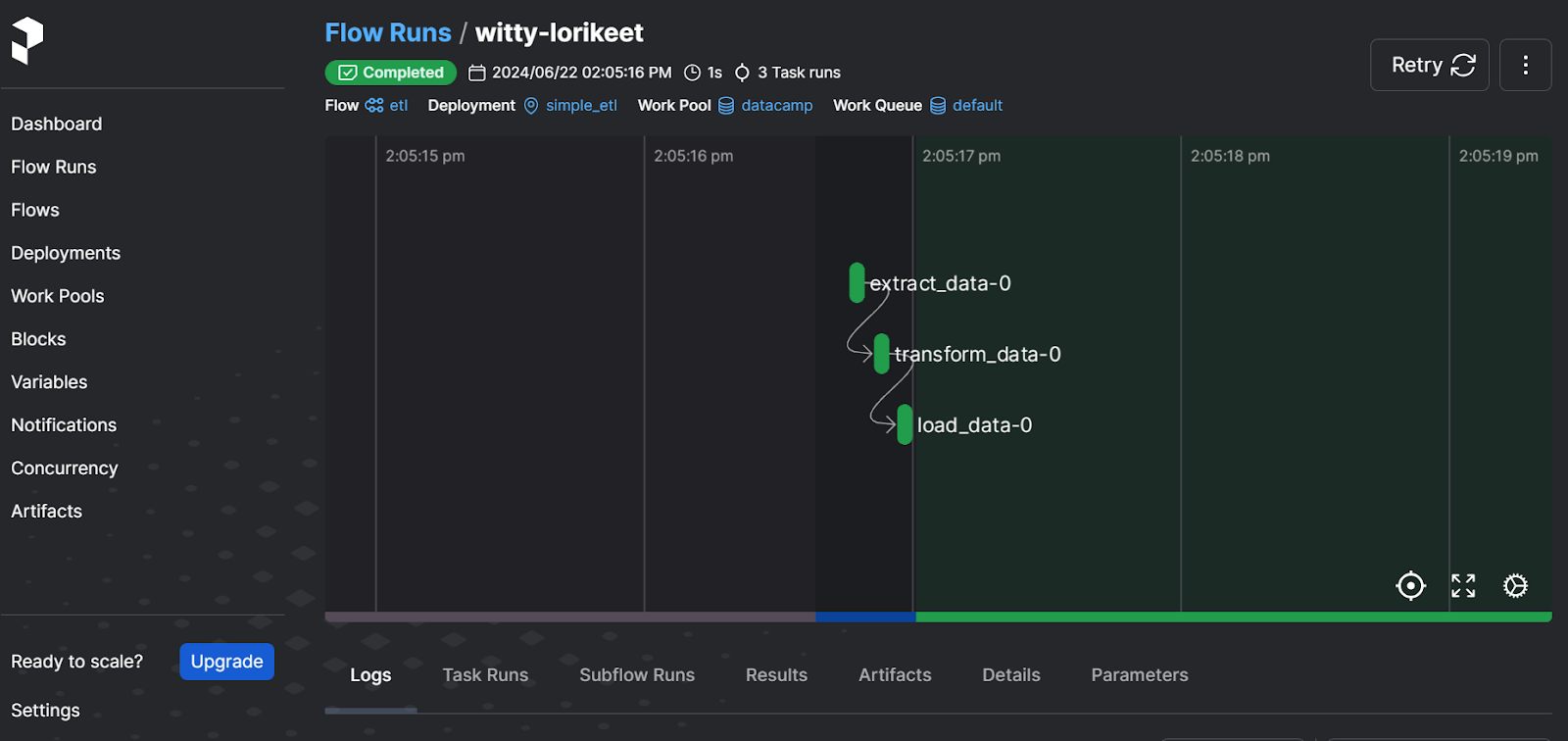
Interface do usuário do servidor da Web perfeita
O painel permite que você execute novamente o fluxo de trabalho, visualize os logs, verifique os pools de trabalho, defina notificações e selecione outras opções avançadas. É uma solução completa para suas necessidades modernas de orquestração de dados.
Para saber como criar e executar pipelines de machine learning usando o Prefect, você pode seguir o guia Como usar o Prefect para fluxos de trabalho de machine learning que você pode seguir.
Dasgter é uma estrutura de código aberto projetada para que os engenheiros de dados definam, programem e monitorem pipelines de dados. Ele é altamente dimensionável e facilita a colaboração entre várias equipes de dados.
O Dagster permite que os usuários definam seus ativos de dados como funções Python usando decoradores. Depois que esses ativos são definidos, os usuários podem executá-los sem problemas por meio de agendamento ou acionadores baseados em eventos.
Em comparação com o Airflow, o Dagster nos permite desenvolver, testar e revisar o pipeline localmente, oferece uma abordagem de orquestração baseada em ativos e é nativo da nuvem e de contêineres.
Em vez de pensar no fluxo de trabalho em termos de etapas e fluxos, tive que mudar minha maneira de pensar e criar um pipeline usando ativos de dados. Além disso, criar e executar um pipeline ETL simples foi bastante simples. Além disso, o servidor da Web é relativamente mínimo, mas fornece todas as informações para monitorar ativos, execuções e implementações.
Abid Ali Awan, Author
Criaremos um pipeline ETL simples, o executaremos e o visualizaremos usando o servidor da Web Dagster. Semelhante ao painel de controle do Prefect, o servidor da Web do Dagster oferece maneiras centralizadas de monitorar vários fluxos de trabalho e programar execuções e ativos.
Começaremos instalando o pacote Python.
$ pip install dagster -qEm seguida, criaremos três funções Python para extrair, transformar e carregar os dados. Essas funções são denominadas create_dirty_data(),clean_data()e load_cleaned_data()no código. Usando o decorador @asset, declararemos as funções como ativos de dados no Dagster.
Em seguida, criaremos o trabalho de ativos (job variável) usando todos os ativos (all_assets variável) e, em seguida, criaremos a definição do ativo (defs variável).
Você pode pular a parte de definição de ativos, mas ela se torna importante se você quiser agendar sua execução, executar vários trabalhos e configurar sensores.
import pandas as pd
import numpy as np
from dagster import asset, Definitions, define_asset_job, materialize
@asset
def create_dirty_data():
# Create a sample DataFrame with dirty data
data = {
'Name': [' John Doe ', 'Jane Smith', 'Bob Johnson ', ' Alice Brown'],
'Age': [30, np.nan, 40, 35],
'City': ['New York', 'los angeles', 'CHICAGO', 'Houston'],
'Salary': ['50,000', '60000', '75,000', 'invalid']
}
df = pd.DataFrame(data)
# Save the DataFrame to a CSV file
dirty_file_path = 'dag_data/dirty_data.csv'
df.to_csv(dirty_file_path, index=False)
return dirty_file_path
@asset
def clean_data(create_dirty_data):
# Read the dirty CSV file
df = pd.read_csv(create_dirty_data)
# Clean the data
df['Name'] = df['Name'].str.strip()
df['Age'] = pd.to_numeric(df['Age'], errors='coerce').fillna(df['Age'].mean())
df['City'] = df['City'].str.upper()
df['Salary'] = df['Salary'].replace('[\$,]', '', regex=True)
df['Salary'] = pd.to_numeric(df['Salary'], errors='coerce').fillna(0)
# Calculate average salary
avg_salary = df['Salary'].mean()
# Save the cleaned DataFrame to a new CSV file
cleaned_file_path = 'dag_data/cleaned_data.csv'
df.to_csv(cleaned_file_path, index=False)
return {
'cleaned_file_path': cleaned_file_path,
'avg_salary': avg_salary
}
@asset
def load_cleaned_data(clean_data):
cleaned_file_path = clean_data['cleaned_file_path']
avg_salary = clean_data['avg_salary']
# Read the cleaned CSV file to verify
df = pd.read_csv(cleaned_file_path)
print({
'num_rows': len(df),
'num_columns': len(df.columns),
'avg_salary': avg_salary
})
# Define all assets
all_assets = [create_dirty_data, clean_data, load_cleaned_data]
# Create a job that will materialize all assets
job = define_asset_job("all_assets_job", selection=all_assets)
# Create Definitions object
defs = Definitions(
assets=all_assets,
jobs=[job]
)
if __name__ == "__main__":
result = materialize(all_assets)
print("Pipeline execution result:", result.success)Você pode executar o código acima em um Jupyter Notebook ou criar o arquivo Python e executá-lo.
Como resultado da execução do código, obteremos um registro completo da execução do fluxo de trabalho.
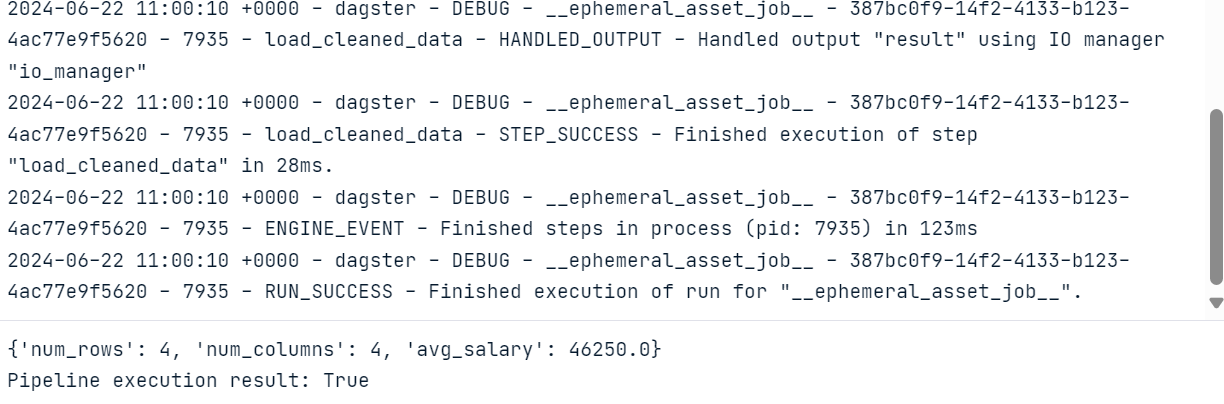
Para visualizar os ativos e as execuções de trabalho, precisamos instalar e executar o servidor da Web Dagster. O servidor da Web permite que você execute os trabalhos, materialize ativos individuais e monitore vários trabalhos ao mesmo tempo.
$ pip install dagster-webserverPara iniciar o servidor Dagster, usaremos a CLI do Daster e forneceremos a ele o local do arquivo Python. Nesse caso, nomeei o arquivo como dagster_pipe.py.
$ dagster dev -f dagster_pipe.py O comando acima iniciará automaticamente o servidor da Web em seu navegador. Como alternativa, você pode ir diretamente para o site http://127.0.0.1:3000 em seu navegador.
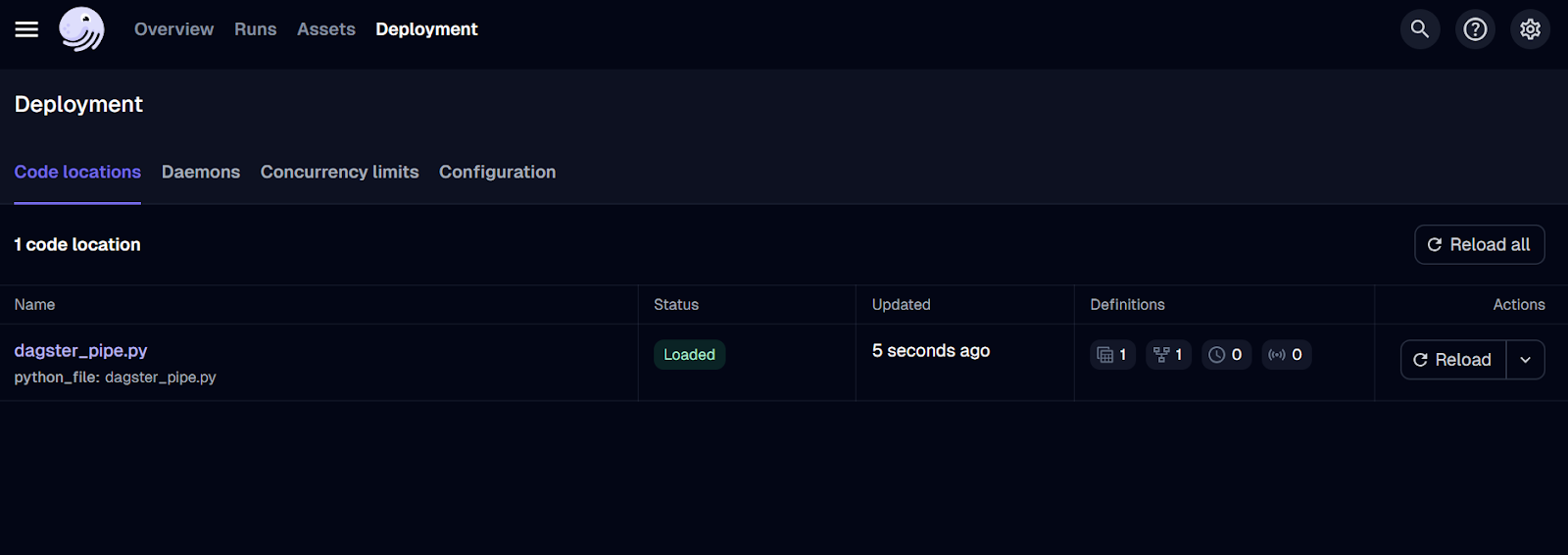
Interface do usuário do servidor da Web Dagster.
Só implantamos o trabalho até o momento. Para executar o fluxo de trabalho, vá até a guia "Runs" (Execuções) e clique no botão "Launch a new run" (Iniciar uma nova execução).
A execução deve ser concluída com sucesso! Para ver os registros, clique no ID da execução em que você está interessado.
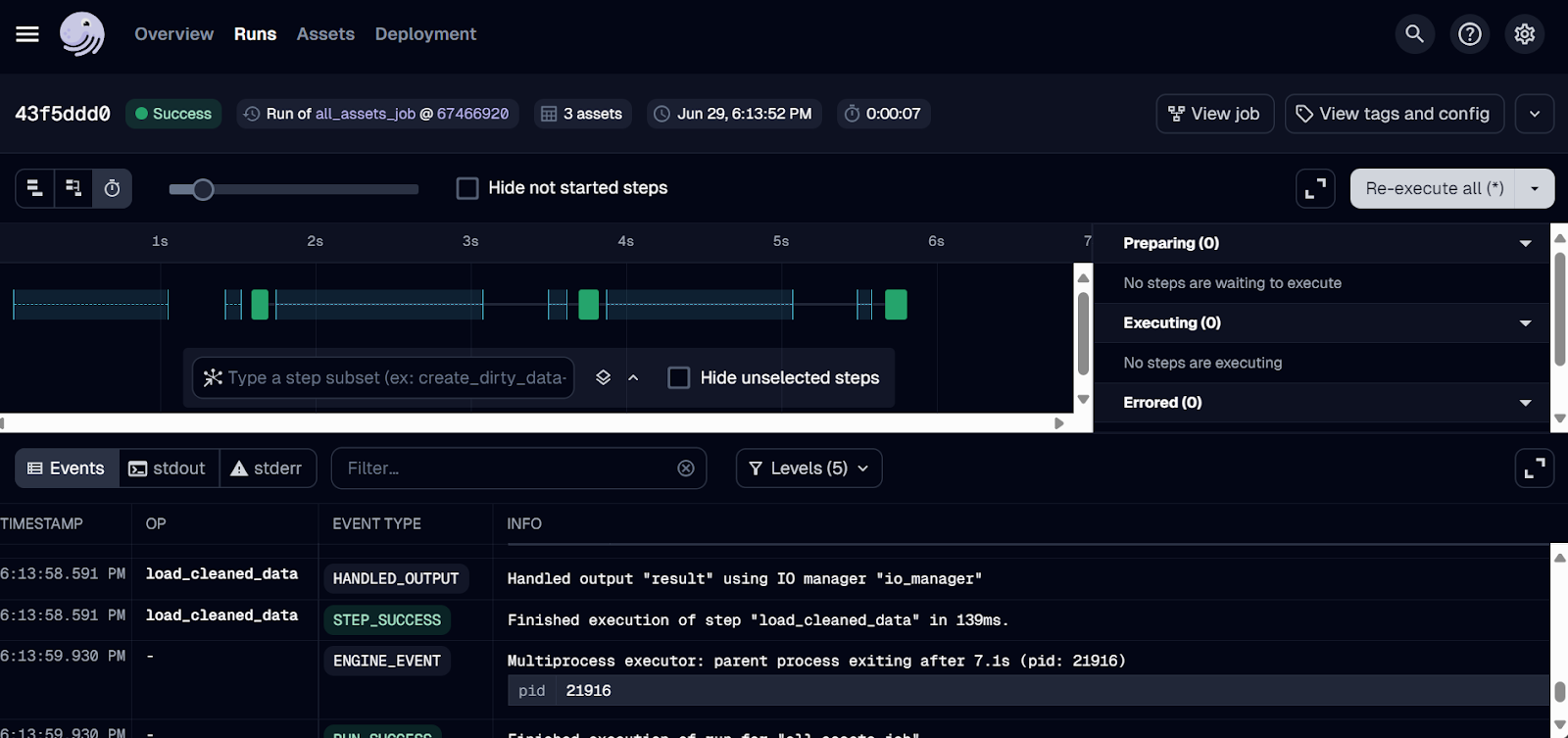
Registros de execução do Dagster.
O Mage AI é uma estrutura de orquestração de dados híbridos de código aberto. Híbrido significa que você obtém a flexibilidade de um Jupyter Notebook e o controle do código modular.
Qualquer pessoa, mesmo com conhecimento limitado de Python, pode criar, executar e monitorar pipelines de dados. Em vez de escrever e executar um arquivo Python diretamente, você criará um projeto Mage AI e o iniciará no painel, onde poderá criar, executar e gerenciar seus pipelines de dados.
Em comparação com o Airflow, o Mage AI oferece uma interface amigável e fácil de usar, o que o torna uma excelente opção para os iniciantes em engenharia de dados. Ele foi projetado com a escalabilidade em mente e é capaz de lidar com grandes volumes de dados e estruturas complexas de pipeline de forma eficiente.
Eu me senti estranho porque era completamente diferente do que eu estava acostumado. Tive que instalar e iniciar a interface de usuário da Web do Mage AI. Era para ser fácil, mas achei difícil criar e executar o pipeline de ETL. Por outro lado, posso ver por que esse design exclusivo pode ser atraente para pessoas que são novas no campo, pois é basicamente arrastar e soltar e pressionar botões.
Abid Ali Awan, Author
Iniciar a IA de mago é muito simples. Você só precisa instalar o pacote Python do Mage AI.
$ pip install mage-aiE inicie o projeto Mage AI.
$ mage start mage_ai_etl O comando acima iniciará o servidor da Web. Como mencionado anteriormente, toda a edição de código, execução e monitoramento de trabalhos são feitos por meio da interface de usuário do Mage AI.
IU de IA de mago.
Clique em "+ New pipeline" para criar seu primeiro pipeline de ETL. Chamei o meu de "simple_etl".
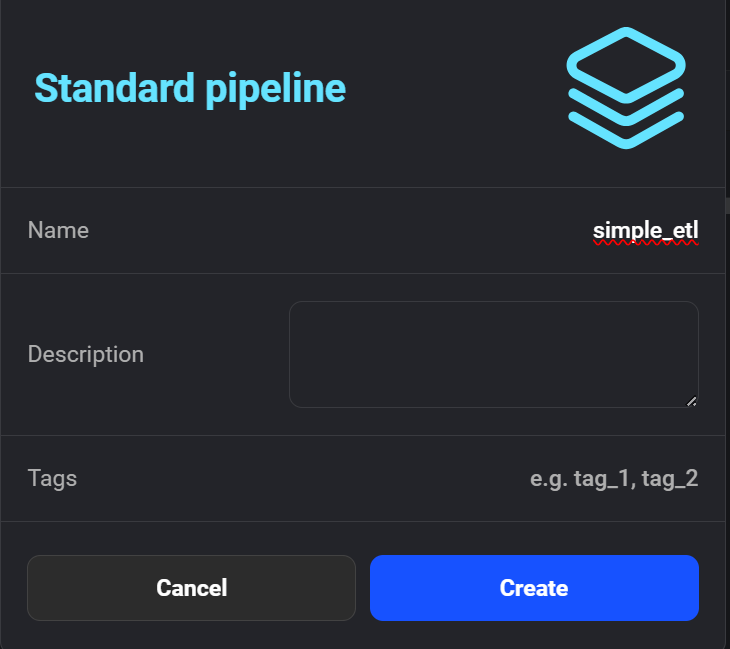
Criando o novo pipeline no Mage AI.
Em seguida, a interface solicitará que você adicione um módulo para começar a codificar. Selecione o módulo "Data Loader" e escreva o seguinte código Python.
Aqui, declaramos uma funçãocreate_sample_csv(), que é a primeira etapa do nosso pipeline. Usamos o decorador Mage AI @data_loader. Também definimos uma função test_output() que afirma se a saída existe. Isso ajuda no gerenciamento da dependência de tarefas.
import io
import pandas as pd
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def create_sample_csv() -> pd.DataFrame:
"""
Create a sample CSV file with duplicates and missing values
"""
csv_data = """
category,product,quantity,price
Electronics,Laptop,5,1000
Electronics,Smartphone,10,500
Clothing,T-shirt,50,20
Clothing,Jeans,30,50
Books,Novel,100,15
Books,Textbook,20,80
Electronics,Laptop,5,1000
Clothing,T-shirt,,20
Electronics,Tablet,,300
Books,Magazine,25,
"""
return pd.read_csv(io.StringIO(csv_data.strip()))
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'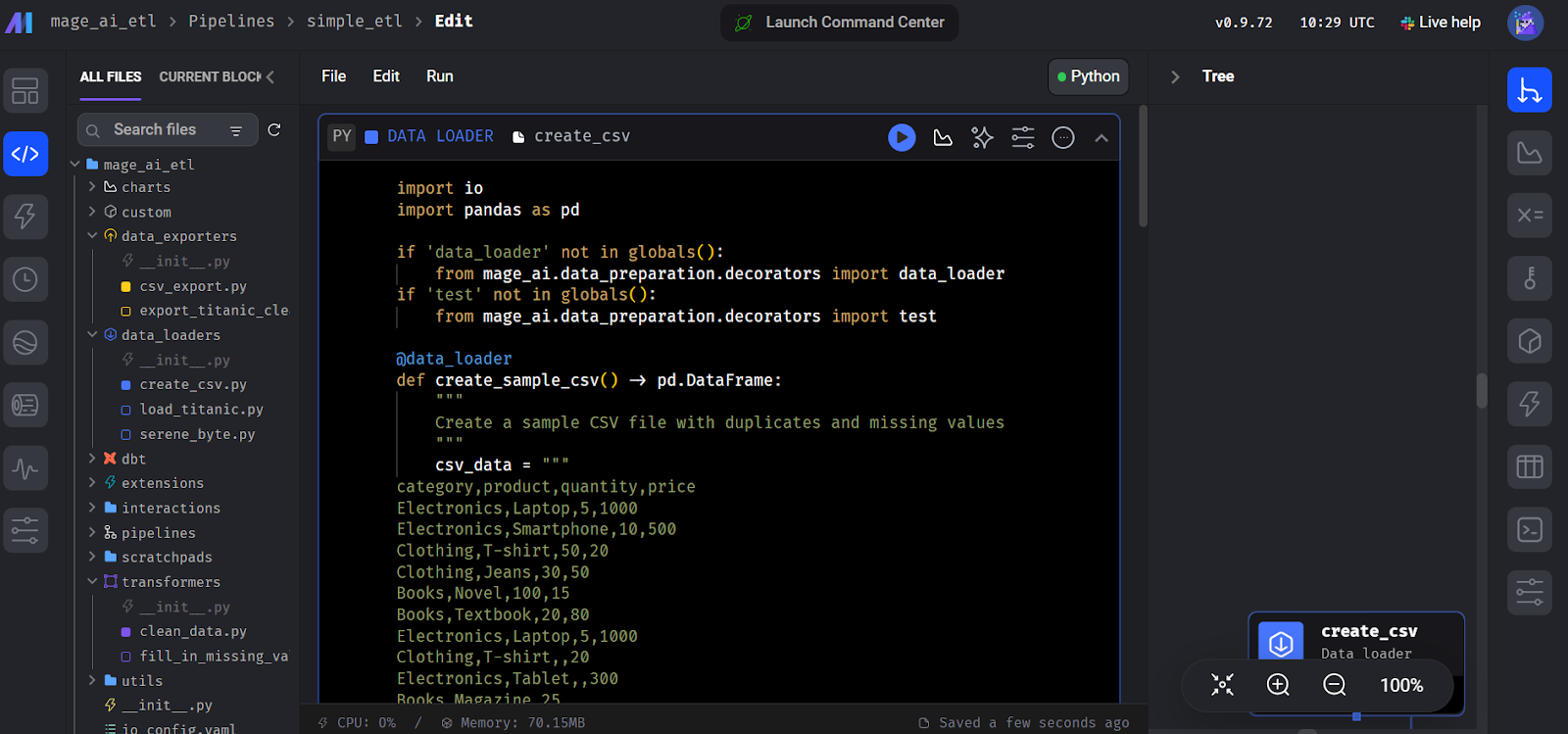
Criação do bloco do carregador de dados no Mage AI.
Em seguida, crie outro módulo chamado "Transformer" e adicione o método clean_data() conforme mostrado no código abaixo.
Você pode ignorar a função test() você só precisa adicionar a função transformadora principal, clean_data().
import pandas as pd
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
"""
Clean and transform the data
"""
# Remove duplicates
df = df.drop_duplicates()
# Fill missing values with 0
df = df.fillna(0)
return df
@test
def test_output(df) -> None:
"""
Template code for testing the output of the block.
"""
assert df is not None, 'The output is undefined'Da mesma forma, crie um módulo "Data Exporter" e adicione o seguinte código. O código declara uma função de carregamento de dados, export_data_to_csv(), que salva os dados transformados em um arquivo CSV .
import pandas as pd
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_csv(df: pd.DataFrame) -> None:
"""
Export the processed data to a CSV file
"""
df.to_csv('output_data.csv', index=False)
print("Data exported successfully to output_data.csv")Para executar o pipeline, vá até a guia "Trigger" e clique em "Run@once".
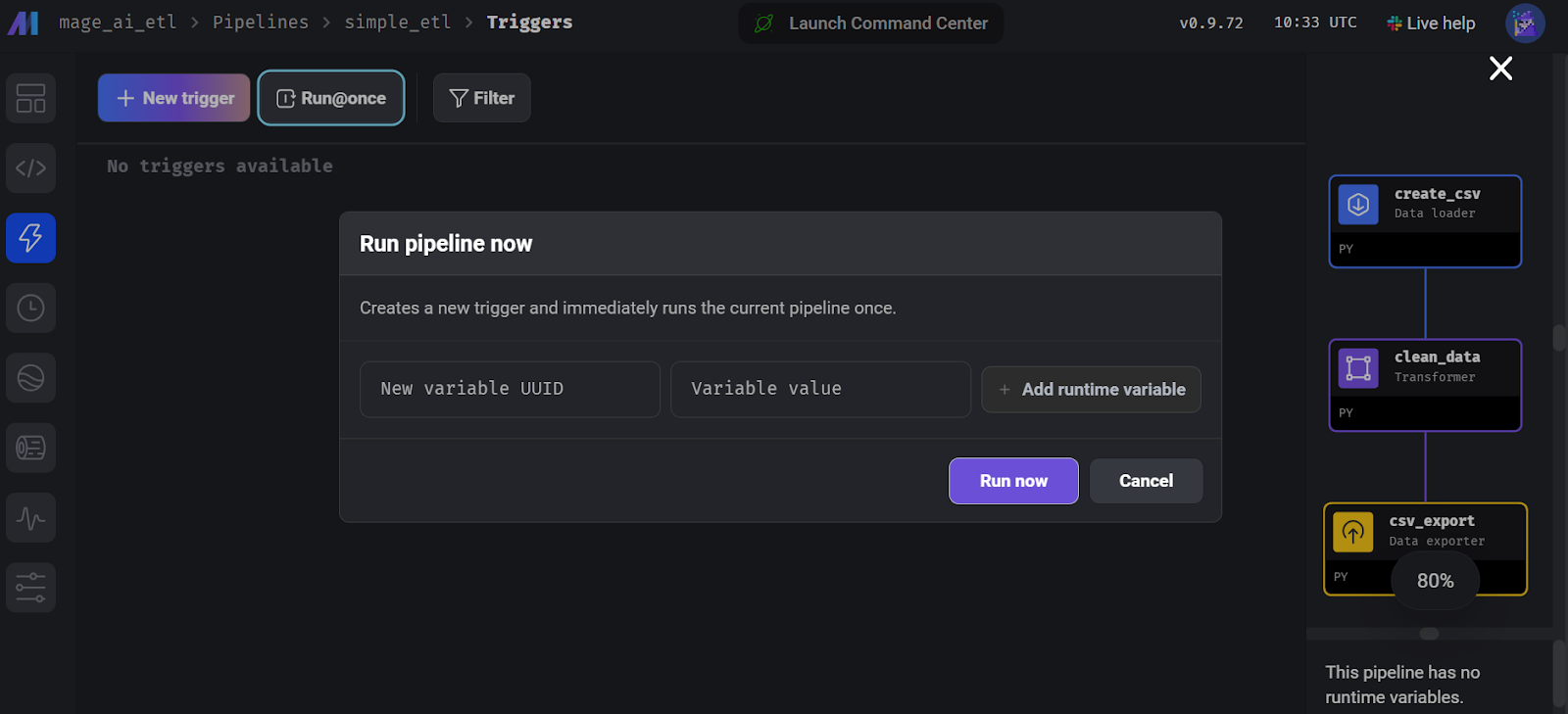
Executando o pipeline no Mage AI.
Para visualizar os registros de execução, vá para a guia "Runs" (Execuções) e clique no botão "Logs" (Registros) no pipeline executado recentemente.
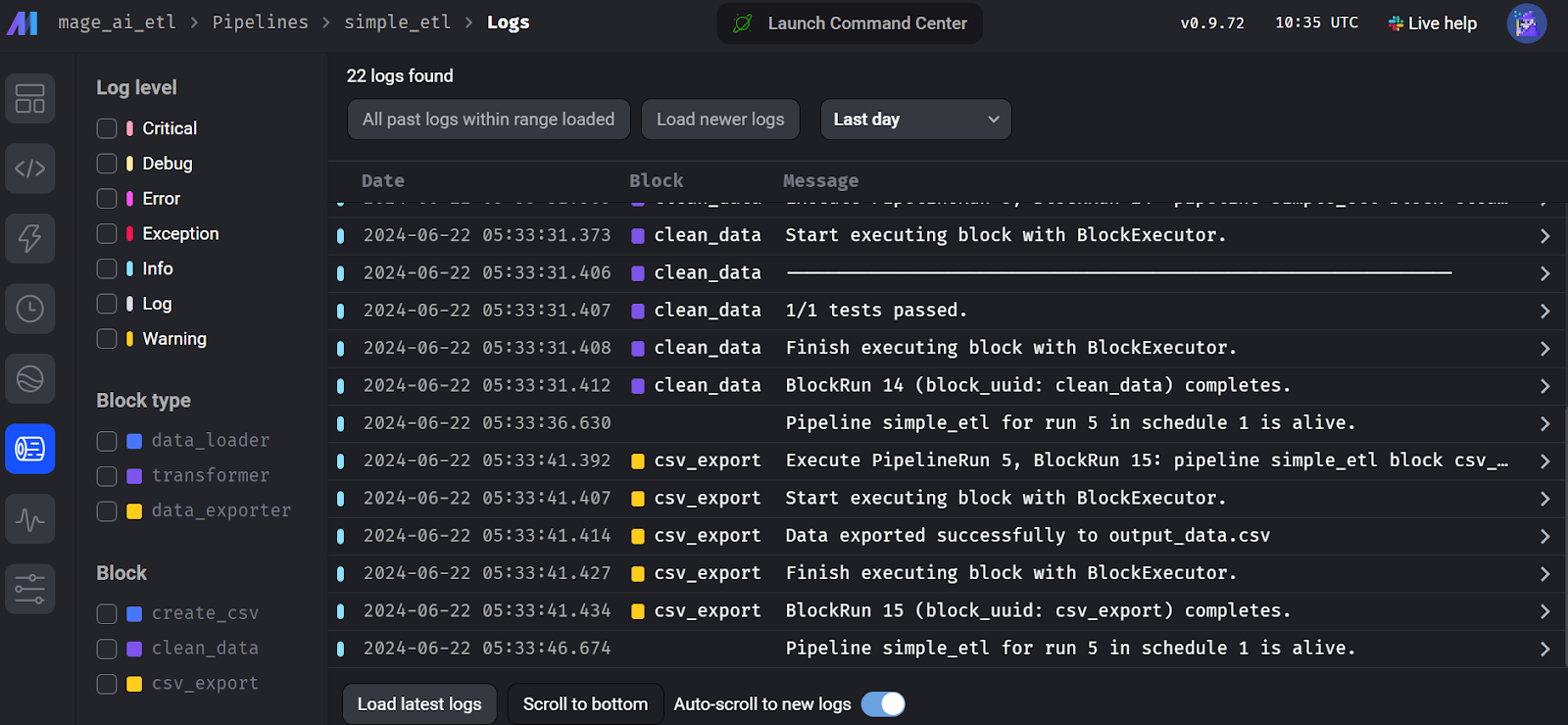
Registros de execução do fluxo de IA dos magos.
O Kedro é outra estrutura popular de orquestração de dados de código aberto que é um pouco diferente das outras ferramentas. Ele foi criado para engenheiros de machine learning e empresta muitos conceitos da engenharia de software, aplicando-os a projetos de machine learning.
O Kedro foi projetado para ser altamente modular, o que significa que, mesmo para exportar um conjunto de dados, você precisa criar um catálogo de dados que especifique o local e o tipo de dados, garantindo um gerenciamento de dados padronizado e eficiente em todo o pipeline.
Para entender como o Kedro se encaixa no ecossistema de machine learning, você pode explorar várias ferramentas de MLOps lendo o artigo 25 principais ferramentas de MLOps que você precisa conhecer em 2024.
Em comparação com o Airflow, a API do Kedro é mais simples para você criar um pipeline de dados. Ele se concentra mais na engenharia de machine learning e oferece categorização e controle de versão de dados.
A parte de codificação é bastante simples, mas surgem problemas quando você deseja executar o pipeline. Você precisa criar um catálogo de dados, registrar o pipeline e descobrir a estrutura do projeto Kedro. Eu diria que ele é mais desafiador do que o Dagster e o Prefect. No entanto, entendo por que ele foi projetado dessa forma: para tornar seu pipeline de dados confiável e livre de erros.
Abid Ali Awan, Author
Criar um pipeline de dados do Kedro é um jogo diferente. A estrutura é modular, e você precisa entender a estrutura do projeto e as várias etapas envolvidas para executar o fluxo de trabalho com êxito.
Comece instalando o pacote Python do Kedro.
$ pip install kedroInicialize o projeto Kedro.
$ kedro new --name=kedro_etl --tools=none --example=n Vá para o diretório do projeto.
$ cd kedro-etl Crie uma pasta dentro da pasta pipelines chamada data_processing.
$ mkdir -p src/kedro_etl/pipelines/data_processing Crie um arquivo Python chamado kedro_pipe.py e abra-o em seu IDE favorito, por exemplo, você pode usar o Visual Studio Code.
$ code src/kedro_etl/pipelines/data_processing/kedro_pipe.pyO script Python deve conter as funções de extração, transformação e carregamento, que são nós no pipeline. Nesse caso, essas são as funções create_sample_data(),clean_data() e load_and_process_data().
Em seguida, juntamos esses nós usando a classe Kedro Pipeline dentro da funçãocreate_pipeline(). Na função de pipeline, definimos nós, e cada nó tem inputs,outputs, e um nó name.
import pandas as pd
import numpy as np
from kedro.pipeline import Pipeline, node
def create_sample_data():
data = {
'id': range(1, 101),
'name': [f'Person_{i}' for i in range(1, 101)],
'age': np.random.randint(18, 80, 100),
'salary': np.random.randint(20000, 100000, 100),
'missing_values': [np.nan if i % 10 == 0 else i for i in range(100)]
}
return pd.DataFrame(data)
def clean_data(df: pd.DataFrame):
# Remove rows with missing values
df_cleaned = df.dropna()
# Convert salary to thousands
df_cleaned['salary'] = df_cleaned['salary'] / 1000
# Capitalize names
df_cleaned['name'] = df_cleaned['name'].str.upper()
return df_cleaned
def load_and_process_data(df: pd.DataFrame):
# Calculate average salary
avg_salary = df['salary'].mean()
# Add a new column for salary category
df['salary_category'] = df['salary'].apply(
lambda x: 'High' if x > avg_salary else 'Low')
# Calculate age groups
df['age_group'] = pd.cut(df['age'], bins=[0, 30, 50, 100], labels=[
'Young', 'Middle', 'Senior'])
print(df)
return df
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=create_sample_data,
inputs=None,
outputs="raw_data",
name="create_sample_data_node",
),
node(
func=clean_data,
inputs="raw_data",
outputs="cleaned_data",
name="clean_data_node",
),
node(
func=load_and_process_data,
inputs="cleaned_data",
outputs="processed_data",
name="load_and_process_data_node",
),
]
)Se executarmos o pipeline sem criar o catálogo de dados, ele não exportará nossos dados. Portanto, precisamos acessar o arquivo conf/base/catalog.yml e editá-lo, fornecendo a configuração do conjunto de dados.
raw_data:
type: pandas.CSVDataset
filepath: ./data/kedro/sample_data.csv
cleaned_data:
type: pandas.CSVDataset
filepath: ./data/kedro/cleaned_data.csv
processed_data:
type: pandas.CSVDataset
filepath: ./data/kedro/processed_data.csvTambém devemos incluir nosso arquivo Python recém-criado no registro do pipeline. Para fazer isso, acesse o arquivo Python src/simple_etl/pipeline_registry.py e inclua o seguinte código.
"""Project pipelines."""
from __future__ import annotations
from kedro.pipeline import Pipeline
from kedro_etl.pipelines.data_processing import kedro_pipe
def register_pipelines() -> Dict[str, Pipeline]:
data_processing_pipeline = kedro_pipe.create_pipeline()
return {
"__default__": data_processing_pipeline,
"data_processing": data_processing_pipeline,
}Execute o pipeline e visualize os registros em tempo real no terminal executando o seguinte comando.
$ kedro run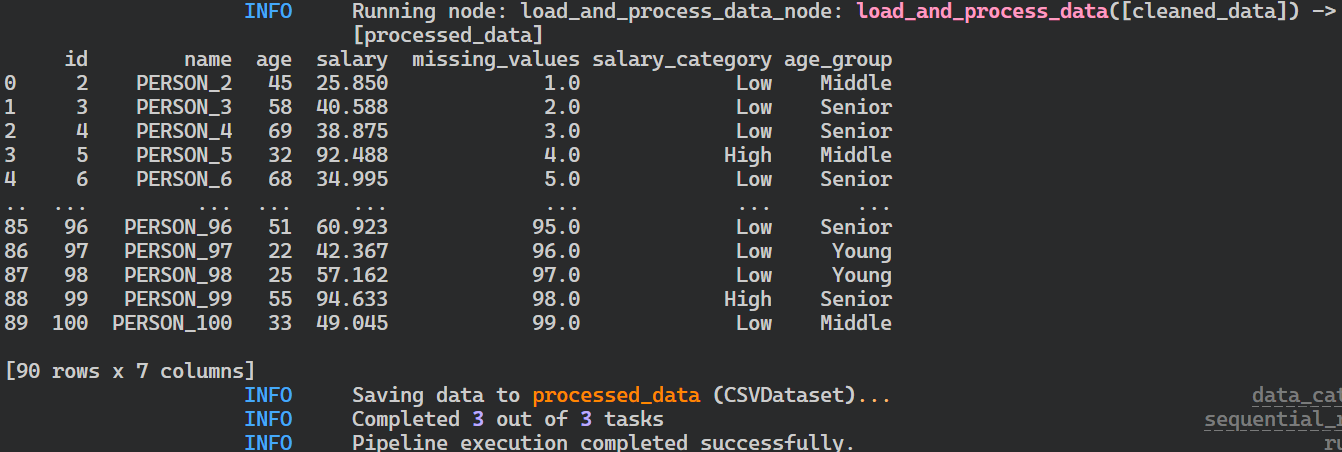
Registros da execução do pipeline do Kedro.
Depois de executar o pipeline, seus arquivos serão armazenados no formato de arquivo CSV no local definido no catálogo de dados.
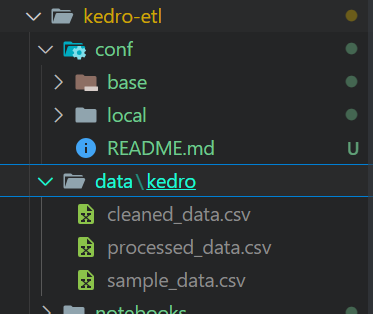
Arquivos de saída da execução do pipeline do Kedro.
Se você tiver problemas ao executar o pipeline, considere a possibilidade de instalar o Kedro com todas as extensões.
$ pip install "kedro[all]"Podemos visualizar e compartilhar nossos pipelines instalando a ferramenta kedro-viz .
$ pip install kedro-vizEm seguida, ao executar o comando a seguir, você poderá visualizar todos os pipelines de dados e nós de dados. Ele também oferece uma opção para rastreamento de experimentos e a capacidade de compartilhar a visualização do pipeline.
$ kedro viz run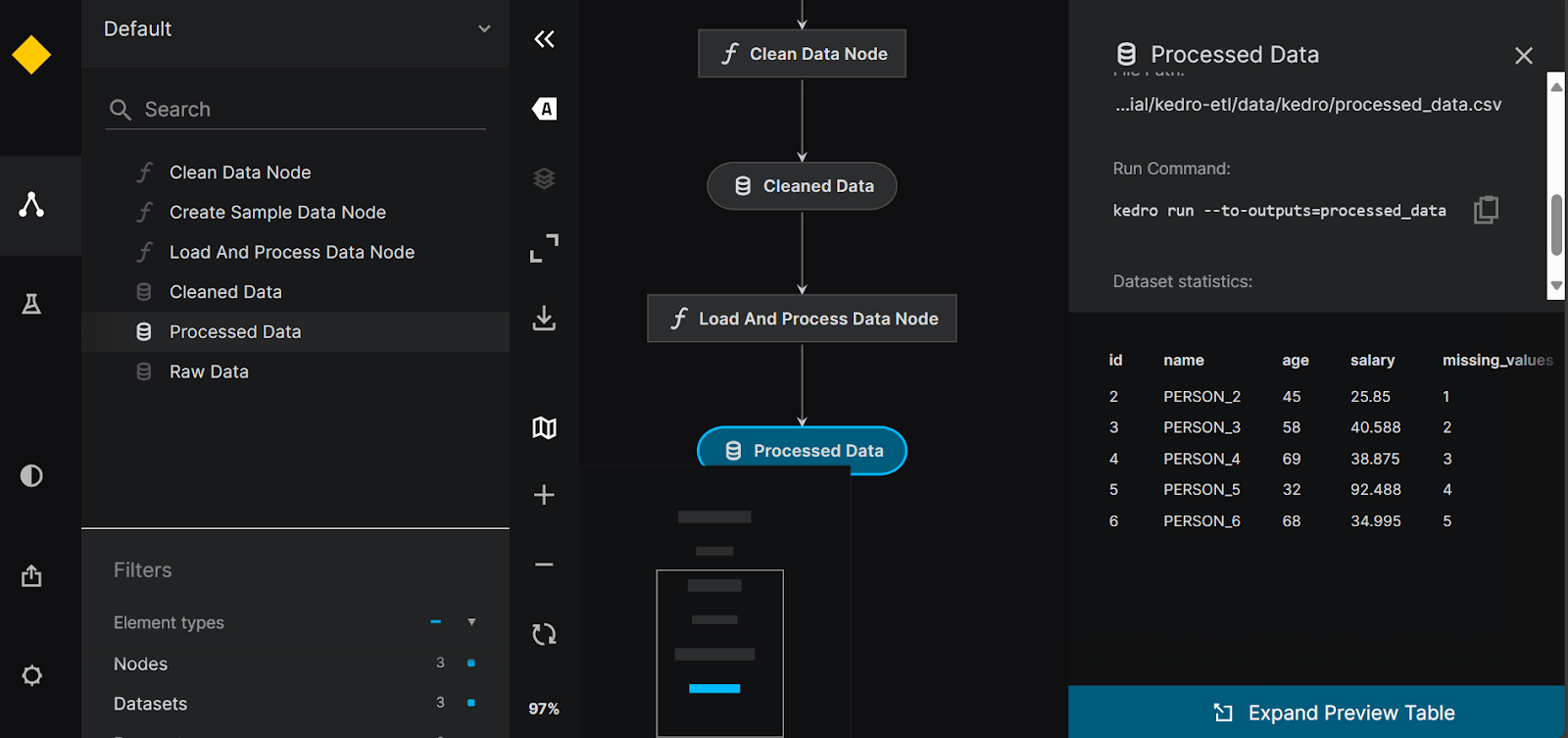
Visualização do pipeline do Kedro.
Luigi é uma estrutura de código aberto baseada em Python, desenvolvida pelo Spotify, que se destaca no gerenciamento de processos em lote de longa duração e pipelines de dados complexos. Ele é bom em resolução de dependências, gerenciamento de fluxo de trabalho, visualização e recuperação de falhas, o que o torna uma ferramenta poderosa para orquestrar fluxos de trabalho de dados.
Em comparação com o Airflow, o Luigi tem uma API mínima, agendamento de calendário e uma base de usuários fiéis que ajudarão você com qualquer problema relacionado ao pipeline de orquestração de dados.
Se você for um iniciante em Python, talvez tenha dificuldade para criar e executar os pipelines. No entanto, a documentação e os guias podem ajudar você a começar rapidamente. Os registros fornecem informações limitadas, e o painel é apenas uma ferramenta de visualização para DAGs e dependências.
Abid Ali Awan, Author
Para criar um pipeline de dados Luigi, você precisa entender de programação orientada a objetos. Vamos começar instalando o pacote Luigi Python.
$ pip install luigiPara desenvolver um pipeline ETL simples no Luigi, criaremos tarefas interconectadas. Em vez de criar funções Python como tarefas, criaremos uma classe Python para cada etapa do pipeline, FetchData,ProcessData e GenerateReport. Cada classe terá três funções chamadas: requires(), output(), e run().
As funções requires() e output() conectarão as tarefas, e a funçãorun() executará o código de processamento. No final, criaremos o pipeline usando a última tarefa do pipeline.
import luigi
import pandas as pd
import numpy as np
class FetchData(luigi.Task):
def output(self):
return luigi.LocalTarget('data/fetch_data.csv')
def run(self):
# Simulate fetching data by creating a sample CSV file
data = {
'column1': [1, 2, np.nan, 4],
'column2': ['A', 'B', 'C', np.nan]
}
df = pd.DataFrame(data)
df.to_csv(self.output().path, index=False)
class ProcessData(luigi.Task):
def requires(self):
return FetchData()
def output(self):
return luigi.LocalTarget('data/process_data.csv')
def run(self):
df = pd.read_csv(self.input().path)
# Fill missing values
df['column1'].fillna(df['column1'].mean(), inplace=True)
df['column2'].fillna('B', inplace=True)
df.to_csv(self.output().path, index=False)
class GenerateReport(luigi.Task):
def requires(self):
return ProcessData()
def output(self):
return luigi.LocalTarget('data/generate_report.txt')
def run(self):
df = pd.read_csv(self.input().path)
# Simple data analysis: calculate mean of column1 and value counts of column2
mean_column1 = df['column1'].mean()
value_counts_column2 = df['column2'].value_counts()
with self.output().open('w') as out_file:
out_file.write(f'Mean of column1: {mean_column1}\n')
out_file.write('Value counts of column2:\n')
out_file.write(value_counts_column2.to_string())
if __name__ == '__main__':
luigi.build([GenerateReport()], local_scheduler=True)Execute o código acima no Jupyter Notebook ou crie o arquivo Python e execute-o usando o terminal.
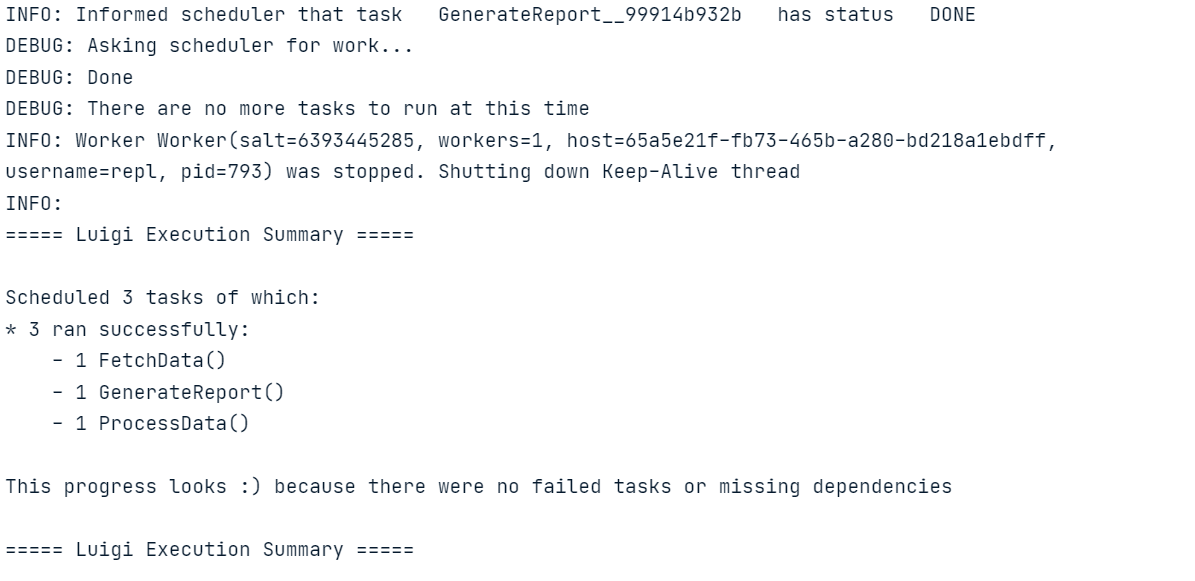
Da mesma forma que Luigi, você também pode aprender a criar um pipeline de ETL com o Apache Airflow. O tutorial aborda os conceitos básicos de extração, transformação e carregamento de dados com o Apache Airflow.
Precisamos inicializar o planejador central Luigi para agendar execuções de pipeline ou acioná-las com um evento.
Inicie o agendador digitando o seguinte comando no terminal.
$ luigid 2024-06-22 13:35:18,636 luigi[25056] INFO: logging configured by default settings
2024-06-22 13:35:18,636 luigi.scheduler[25056] INFO: No prior state file exists at /var/lib/luigi-server/state.pickle. Starting with empty state
2024-06-22 13:35:18,640 luigi.server[25056] INFO: Scheduler starting upPara executar o pipeline, abra um novo terminal e digite o seguinte comando. O comando Luigi requer um nome de arquivo Python e a última tarefa que você deseja executar. Nesse caso, o nome do arquivo é luigi_pipe.py, e nossa última tarefa Luigi é GenerateReport.
$ python -m luigi --module luigi_pipe GenerateReportSe quiser visualizar a execução do pipeline e o status da tarefa, você pode simplesmente acessar http://localhost:8082 em seu navegador.
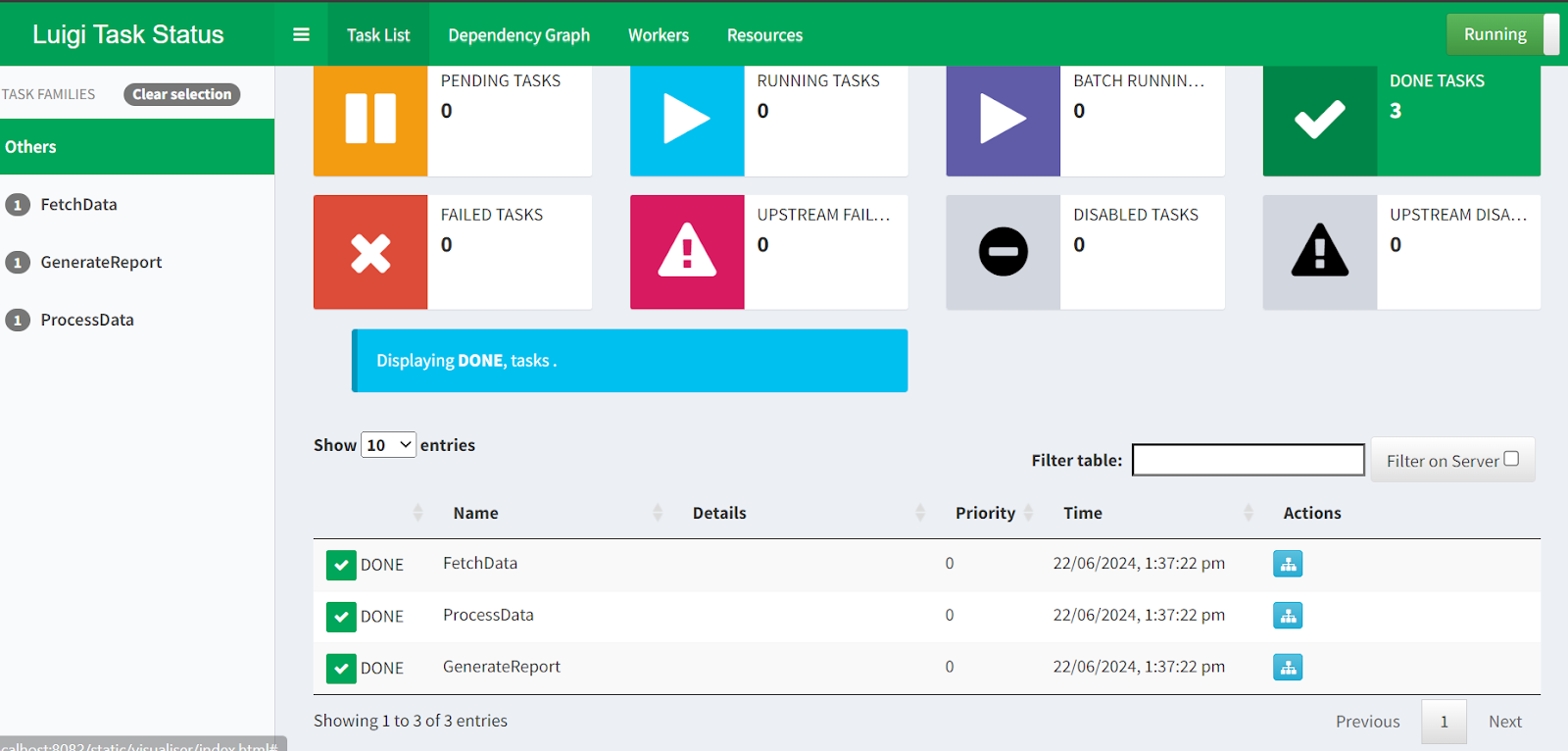
Luigi Central Planner webUI.
Com isso, você encerra nossa apresentação das 5 melhores alternativas ao Airflow! Se você quiser se aprofundar em qualquer um dos exemplos apresentados neste artigo, aqui estão alguns recursos a serem considerados:
Neste tutorial, discutimos as principais alternativas gratuitas e de código aberto ao Airflow. Também aprendemos sobre cada ferramenta de orquestração de dados e criamos e executamos um pipeline de ETL simples. Ver exemplos de código ajudará você a decidir qual deles funciona melhor para o seu caso de uso.
Se você for iniciante, sugiro que comece com o Prefect ou o Mage AI, pois eles são fáceis de usar e vêm com uma configuração simples. No entanto, se você estiver procurando ferramentas mais avançadas que sigam as práticas de engenharia de software, recomendo que explore o Dagster, o Kedro e o Luigi.
Depois de explorar este artigo, o próximo passo natural em sua jornada de engenharia de dados é obter uma certificação, como a do DataCamp. Engenheiro de dados em Python da DataCamp para conhecer outras ferramentas e criar um pipeline de dados de ponta a ponta que você possa implantar na produção.
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
DataCamp Team
12 min
blog
Javier Canales Luna
12 min
blog
Tim Lu
11 min
blog
Joyce Chiu
8 min
Tutorial
Karlijn Willems
