
programa
Ingeniero de Datos Asociado en SQL
30 h
El procesamiento de datos en tiempo real nos brinda grandes oportunidades. Si un banco detecta una compra extraña con nuestra tarjeta de crédito, puede detener la transaccióninmediatamente . O, si estamos buscando un producto, pueden aparecer sugerencias de productos mientras navegamos por el sitio web. Esta rapidez se traduce en mejores decisiones, clientes más satisfechos y un negocio más eficiente.
Apache Kafka es un almacén de datos distribuido de alto rendimiento optimizado para recopilar, procesar, almacenar y analizar datos en tiempo real. Permite que diferentes aplicaciones publiquen y se suscriban a flujos de datos, lo que les permite comunicarse y reaccionar ante los eventos a medida que se producen.
Gracias a su eficiente gestión de los flujos de datos, Kafka se ha vuelto muy popular. Se utiliza en diferentes sistemas, desde las compras en línea y las redes sociales hasta la banca y la asistencia sanitaria.
Apache Kafka se ha vuelto popular entre los profesionales de datos que se enfrentan al reto de gestionar flujos de datos en tiempo real. Podemos explicar tu popularidad por varios factores clave:
Apache Kafka se utiliza actualmente en aplicaciones que requieren el procesamiento y análisis de datos en tiempo real. Pero, ¿qué características lo convierten en una herramienta potente para gestionar datos en streaming? Echemos un vistazo a ellos:
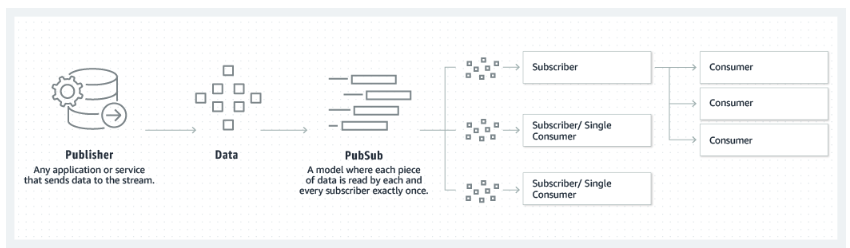
El modelo editor-suscriptor en el que se basa Kafka. Fuente: Amazon
Aprender Apache Kafka te convierte en un candidato valioso para los empleadores y las empresas que generan y procesan datos a gran velocidad. Apache Kafka, con sus potentes funciones y su uso generalizado, se ha convertido en una herramienta clave para crear las arquitecturas de datos modernas y aplicaciones.
He mencionado que Kafka se ha vuelto muy popular en los últimos años. Se estima que Apache Kafka es utilizado actualmente por más del el 80 % de las empresas de la lista Fortune 100.
El uso cada vez mayor de Kafka en diversos sectores, junto con su papel en la habilitación de soluciones de datos en tiempo real, hace que los conocimientos sobre Kafka sean muy valiosos en el mercado laboral. Según PayScale y ZipRecruiter, en noviembre de 2024, el salario medio de un ingeniero con conocimientos de Kafka en Estados Unidos era de 100 000 dólares al año.
Ya hemos mencionado las ventajas de Apache Kafka, pero veamos algunos ejemplos concretos en los que puedes utilizarlas:
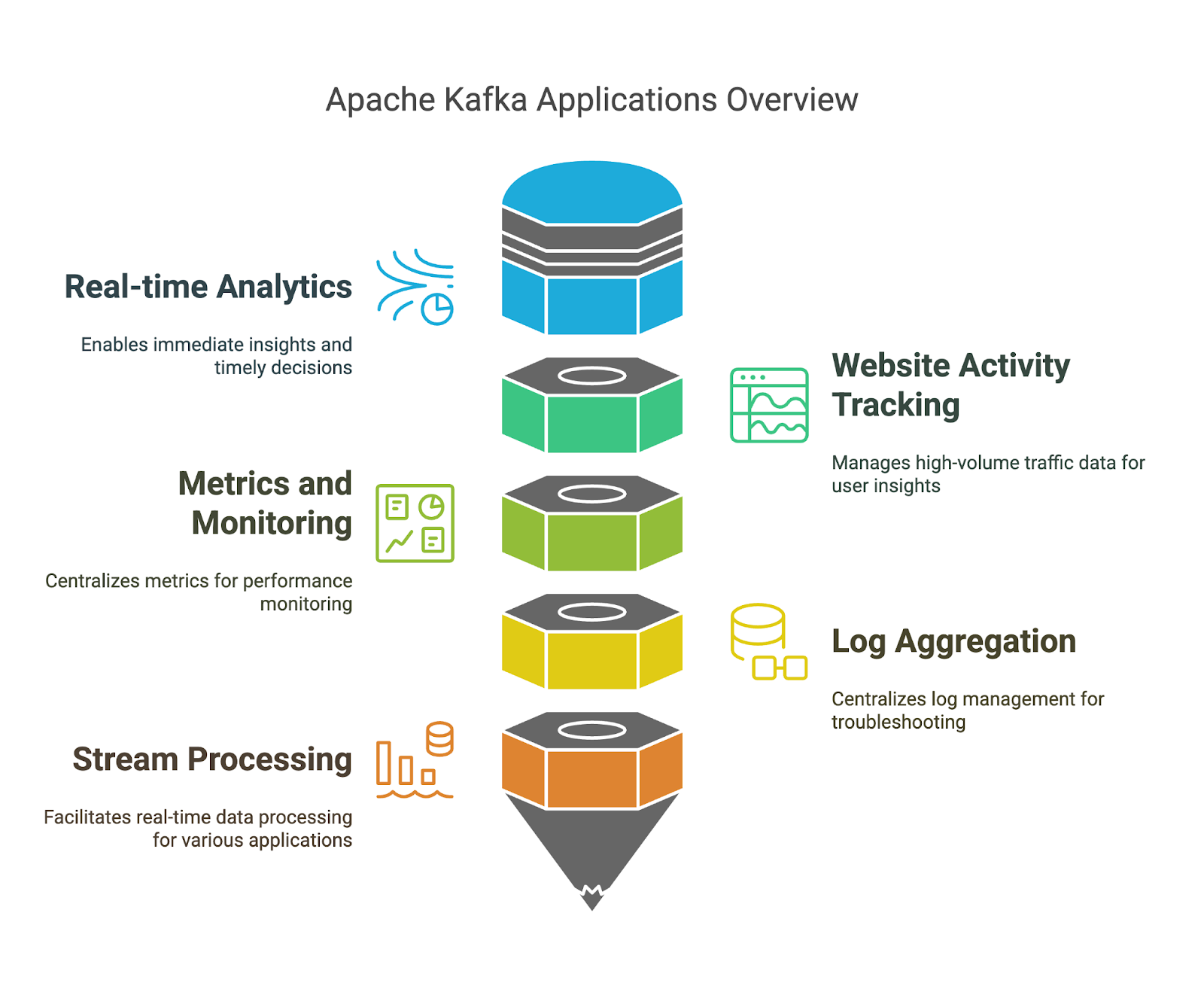
Si aprendes Apache Kafka de forma metódica, tendrás más posibilidades de éxito. Centrémonos en algunos principios que puedes utilizar en tu proceso de aprendizaje.
Antes de aprender los detalles técnicos, define tu motivación para aprender Apache Kafka. Pregúntate a ti mismo:
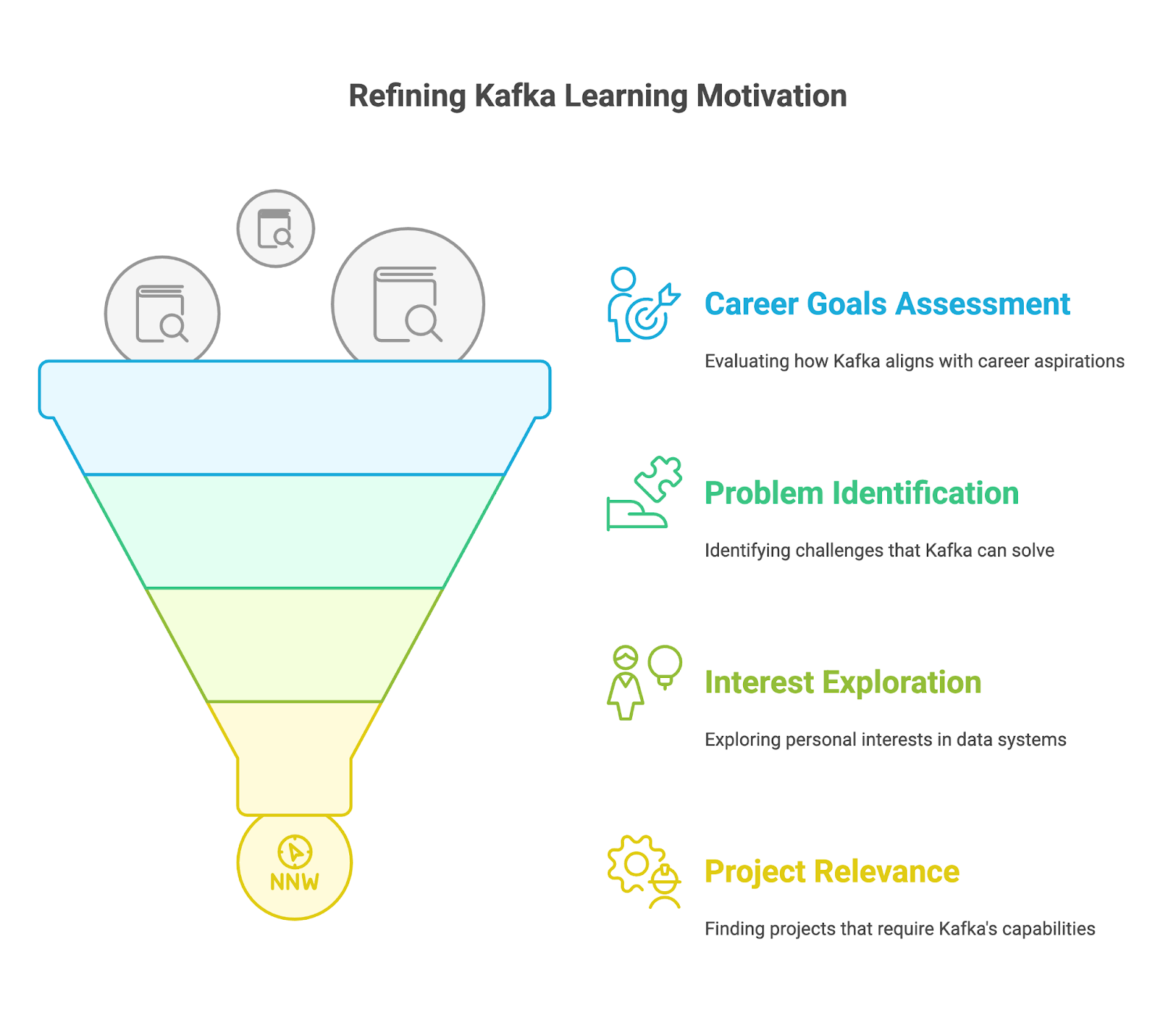
Una vez que hayas identificado tus objetivos, domina los conceptos básicos de Kafka y comprende cómo funcionan.
Para aprender Apache Kafka, primero necesitamos instalarlo en tu máquina local. Dado que Kafka se desarrolla utilizando Java, debemos asegurarnos de tener Java instalado. A continuación, hay que descargar los binarios de Kafka desde la sitio web oficial y extraerlos.
Ahora iniciamos ZooKeeper, seguido del servidor Kafka, utilizando los scripts proporcionados. Por último, podemos utilizar las herramientas de línea de comandos para crear temas e intentar producir y consumir algunos mensajes para comprender los conceptos básicos. DataCamp's Apache Kafka para principiantes puede ayudarte a ponerte al día.
El primer concepto que debemos aprender es el modelo editor-suscriptor en Kafka. Esta es una de las razones principales por las que Apache Kafka puede gestionar datos en streaming de forma eficiente. Comprender cómo los productores publican mensajes y los consumidores se suscriben a estos temas, recibiendo solo mensajes relevantes para sus intereses.
Introducción a Apache Kafka de DataCamp Introducción a Apache Kafka ofrece una introducción, con ejercicios interactivos y ejemplos prácticos.
Al describir el modelo editor-suscriptor, hemos mencionado algunos componentes clave de Kafka: Productor y consumidor. Sin embargo, debemos explorar todos los componentes básicos. Debemos aprender cómo Kafka organiza los datos en temas y particiones, y comprender cómo las particiones contribuyen a la escalabilidad y la tolerancia a fallos.
También debemos comprender cómo los brokers forman un clúster para proporcionar alta disponibilidad y tolerancia a fallos.
Consulta la introducción a Apache Kafka de DataCamp. Introducción a Apache Kafka , así como el artículo Apache Kafka para principiantes para tener una idea clara de estos temas.
Una vez que te sientas cómodo con los conceptos básicos, es hora de explorar las habilidades intermedias de Apache Kafka.
Una de las características clave de Apache Kafka es su capacidad para gestionar grandes volúmenes de datos en streaming. Kafka Connect es un componente gratuito y de código abierto de Apache Kafka que simplifica la integración de datos entre sistemas de archivos, bases de datos, índices de búsqueda y almacenes de claves-valores.
Aprender a utilizar Connect puede ayudarnos a desbloquear un flujo de datos eficiente para el análisis, la integración de aplicaciones y la creación de una arquitectura de datos robusta y escalable. Consulta nuestro artículo Apache Kafka para principiantes para obtener más detalles.
Otra característica avanzada de Kafka es Streams. Debemos aprender a crear aplicaciones de procesamiento de flujos directamente en Kafka con la ayuda de Streams. Ofrece API y un lenguaje específico de dominio de alto nivel para gestionar, convertir y evaluar flujos continuos de datos. Más información en Artículo Apache Kafka para principiantes.
Al igual que con cualquier otra tecnología, siempre es bueno realizar un seguimiento de su rendimiento. Para ello, debemos aprender a supervisar el estado y el rendimiento de vuestro clúster Kafka. Podemos explorar herramientas y técnicas para supervisar métricas clave, gestionar temas y particiones, y garantizar un rendimiento óptimo.
Realizar cursos sobre Apache Kafka es una forma excelente de familiarizarse con esta tecnología. Sin embargo, para dominar Kafka, es necesario resolver problemas desafiantes y que permitan desarrollar habilidades, como los que se te presentarán en proyectos del mundo real.
Puedes empezar experimentando con tareas sencillas de transmisión de datos, como producir y consumir mensajes, y luego aumentar gradualmente la complejidad explorando temas como la partición, la tolerancia a fallos y la integración con sistemas externos utilizando Kafka Connect.
Aquí tienes algunas formas de practicar tus habilidades:
Completarás diferentes proyectos a medida que avances en tu proceso de aprendizaje de Apache Kafka. Para mostrar tus habilidades y experiencia en Apache Kafka a posibles empleadores, debes recopilarlas en un portafolio. Este portafolio debe reflejar tus habilidades e intereses y estar adaptado a la carrera o industria que te interesa.
Intenta que tus proyectos sean originales y demuestren tu capacidad para resolver problemas. Incluye proyectos que demuestren tu dominio de diferentes aspectos de Kafka, como la creación de canalizaciones de datos con Kafka Connect, el desarrollo de aplicaciones de streaming con Kafka Streams o el trabajo con clústeres de Kafka. Documenta tus proyectos de forma exhaustiva, proporcionando contexto, metodología, código y resultados. Puedes utilizar plataformas como GitHub para alojar tu código y Confluent Cloud para un entorno Kafka gestionado.
Aprender Kafka es un viaje continuo. La tecnología evoluciona constantemente y se desarrollan nuevas funciones y aplicaciones con regularidad. Kafka no es una excepción.
Una vez que domines los fundamentos, podrás buscar tareas y proyectos más desafiantes, como el ajuste del rendimiento de sistemas de alto rendimiento y la implementación de procesamiento avanzado de flujos con Kafka Streams. Céntrate en tus objetivos y especialízate en áreas que sean relevantes para tus metas profesionales y tus intereses.
Mantente al día de las últimas novedades, como nuevas funciones o propuestas de KIP, y aprende a aplicarlas a tus proyectos. Sigue practicando, busca nuevos retos y oportunidades, y acepta la idea de cometer errores como una forma de aprender.
Aunque cada persona tiene su propia forma de aprender, siempre es buena idea contar con un plan o una guía que seguir para aprender a utilizar una nueva herramienta. He creado un posible plan de aprendizaje en el que se describe dónde centrar tu tiempo y tus esfuerzos si acabas de empezar con Apache Kafka.

Imagino que a estas alturas ya estás listo para lanzarte a aprender Kafka y hacerte con un gran conjunto de datos para practicar tus nuevas habilidades. Pero antes de hacerlo, permíteme destacar estos consejos que te ayudarán a recorrer el camino hacia el dominio de Apache Kafka.
Kafka es una herramienta versátil que se puede utilizar de muchas maneras. Debes identificar tus objetivos e intereses específicos dentro del ecosistema Kafka. ¿Qué aspecto de Kafka te atrae más? ¿Te interesa la ingeniería de datos, el procesamiento de flujos o la administración de Kafka? Un enfoque específico puede ayudarte a adquirir los aspectos y conocimientos más relevantes de Apache Kafka para satisfacer tus intereses.
La constancia es clave para dominar cualquier habilidad nueva. Debes reservar tiempo específico para practicar Kafka. Solo necesitas dedicarle un poco de tiempo cada día. No es necesario que abordes conceptos complejos todos los días. Puedes realizar ejercicios prácticos, seguir tutoriales y experimentar con diferentes funciones de Kafka. Cuanto más practiques, más cómodo te sentirás con la plataforma.
Este es uno de los consejos clave, y lo leerás varias veces en esta guía. Practicar ejercicios es ideal para ganar confianza. Sin embargo, aplicar tus conocimientos de Kafka a proyectos del mundo real es lo que te hará destacar en este campo.
Empieza con proyectos y preguntas sencillos y ve pasando gradualmente a otros más complejos. Esto podría implicar la creación de una sencilla aplicación de productor-consumidor, para luego pasar a construir un canal de datos en tiempo real con Kafka Connect, o incluso diseñar una aplicación de streaming tolerante a fallos con Kafka Streams. La clave está en desafiarte continuamente a ti mismo y ampliar tus habilidades prácticas con Kafka.
El aprendizaje suele ser más eficaz cuando se realiza de forma colaborativa. Compartir tus experiencias y aprender de los demás puede acelerar tu progreso y proporcionarte información valiosa.
Para intercambiar conocimientos, ideas y preguntas, puedes unirte a algunos grupos relacionados con Apache Kafka y asistir a reuniones y conferencias. Puedes unirte a comunidades en línea como el canal Slack de Confluent o Foro Confluent, donde podrás interactuar con otros entusiastas de Kafka. También puedes unirte a encuentros, con charlas de expertos en Kafka, o conferencias, como ApacheCon.
Al igual que con cualquier otra tecnología, aprender Apache Kafka es un proceso iterativo. Aprender de tus errores es una parte esencial de este proceso. No tengas miedo de experimentar, prueba diferentes enfoques y aprende de tus errores.
Prueba diferentes configuraciones para tus productores y consumidores de Kafka, explora varios métodos de serialización de datos (JSON, Avro, Protobuf) y experimenta con diferentes estrategias de partición. Lleva tu clúster Kafka al límite con grandes volúmenes de mensajes y observa cómo gestiona la carga. Analiza el retraso de los consumidores, ajusta las configuraciones y comprende cómo tus optimizaciones afectan al rendimiento.
Tómate tu tiempo para comprender realmente conceptos básicos como temas, particiones, grupos de consumidores y la función de ZooKeeper. Si construyes ahora una base sólida, te resultará más fácil comprender temas más avanzados y resolver problemas de forma eficaz. Divide el proceso de aprendizaje en pasos más pequeños y date tiempo para comprender la información. Un enfoque lento y constante suele conducir a una comprensión y un dominio más profundos.
Veamos algunos métodos eficaces para aprender Apache Kafka.
Los cursos en línea ofrecen una excelente manera de aprender Apache Kafka a tu propio ritmo. DataCamp ofrece un curso intermedio de Kafka. Este curso abarca los conceptos básicos de Kafka, incluyendo el modelo editor-suscriptor, temas y particiones, corredores y clústeres, productores y consumidores.
Los tutoriales son otra forma estupenda de aprender Apache Kafka, especialmente si eres nuevo en esta tecnología. Contienen instrucciones paso a paso sobre cómo realizar tareas específicas o comprender determinados conceptos. Para empezar, ten en cuenta estos tutoriales:
Para conocer más a fondo las ventajas de Apache Kafka, también debes comprender cuáles son las principales similitudes y diferencias con otras tecnologías. Puedes leer artículos sobre cómo se compara Kafka con otras herramientas, como los siguientes:
Los libros son un recurso excelente para aprender Apache Kafka. Ofrecen conocimientos profundos y opiniones de expertos, junto con fragmentos de código y explicaciones. Estos son algunos de los libros más populares sobre Kafka:
Debido a que la adopción de Apache Kafka sigue creciendo, también lo hacen las oportunidades profesionales para los profesionales con conocimientos de Kafka, desde ingenieros especializados en Kafka hasta ingenieros de software. Si estás evaluando si tus habilidades en Kafka son adecuadas, ten en cuenta estas funciones:

Como ingeniero de Kafka, serás responsable de diseñar, crear y mantener soluciones de transmisión de datos basadas en Kafka con alta disponibilidad y escalabilidad. Deberás garantizar un flujo de datos fiable y eficiente dentro de la empresa, así como supervisar y optimizar el rendimiento de Kafka para garantizar un rendimiento y una latencia óptimos.
Como ingeniero de datos, eres el arquitecto de la infraestructura de datos, responsable de diseñar y construir los sistemas que gestionan los datos de una empresa. Kafka suele desempeñar un papel importante en estas canalizaciones de datos, ya que permite una transmisión de datos en tiempo real eficiente y escalable entre diferentes sistemas. Deberás asegurarte de que Kafka se integre perfectamente con otros componentes.
Como ingeniero de software, utilizarás Kafka para crear aplicaciones en tiempo real, como plataformas de chat y juegos en línea. Tendrás que integrarlo en el código de la aplicación para garantizar un flujo de datos fluido mediante la conexión con diversos sistemas de mensajería y API. También optimizarás estas aplicaciones para mejorar su escalabilidad y rendimiento, lo que les permitirá gestionar grandes cantidades de datos en tiempo real.
|
Función |
Lo que haces |
Tus habilidades clave |
Herramientas que utilizas |
|
Kafka Engineer |
Diseñar e implementar clústeres Kafka para garantizar una alta disponibilidad y escalabilidad. |
Arquitectura Kafka, componentes, Administración y configuración, conceptos de procesamiento de flujos. |
Apache Kafka, Kafka Connect, Kafka Streams, ZooKeeper |
|
Ingeniero de datos |
Diseñar e implementar almacenes de datos y lagos de datos, integrar Kafka con otros sistemas de procesamiento y almacenamiento de datos. |
Dominio de herramientas de procesamiento de datos, experiencia con plataformas de nube y conocimientos de Kafka. |
Apache Kafka, Apache Spark, Hadoop, Colmena, Nubes |
|
Ingeniero de software |
Diseña y desarrolla aplicaciones que aprovechen Kafka para la comunicación de datos en tiempo real. |
Conocimientos de programación, sistemas y aplicaciones distribuidos, y el modelo editor-suscriptor de Kafka. |
Apache Kafka, Java, Python, Scala, RabbitMQ, ActiveMQ, Herramientas y marcos de desarrollo. |
Aunque tener un título universitario puede ser muy valioso a la hora de desarrollar una carrera profesional en un puesto relacionado con los datos que utilice Apache Kafka, no es la única vía para alcanzar el éxito. Cada vez más personas de diversos orígenes y con diferentes experiencias están empezando a trabajar en puestos relacionados con los datos. Con dedicación, aprendizaje constante y un enfoque proactivo, puedes conseguir el trabajo de tus sueños utilizando Apache Kafka.
Mantente al día de las últimas novedades sobre Kafka. Sigue en las redes sociales a profesionales influyentes relacionados con Apache Kafka, lee blogs sobre Apache Kafka y escucha podcasts relacionados con Kafka.
Interactúa con figuras influyentes, como Neha Narkhede, cofundadora de Kafka y directora de tecnología de Confluent. Obtendrás información sobre temas de actualidad, tecnologías emergentes y la dirección futura de Apache Kafka. Tú también también leer el blog de Confluent, que ofrece artículos y tutoriales detallados sobre una amplia gama de temas relacionados con Kafka, desde la arquitectura y la administración hasta casos de uso y mejores prácticas.
También deberías echar un vistazo a los eventos del sector, como los seminarios web de Confluent o la cumbre anual Cumbre Kafka.
Tienes que destacar entre los demás candidatos. Una buena forma de hacerlo es crear un buen portafolio que muestre tus habilidades y los proyectos que has completado.
Tu portafolio debe contener proyectos que demuestren tu competencia en la creación de canalizaciones de datos, la implementación de aplicaciones de procesamiento de flujos y la integración de Kafka con otros sistemas.
Los responsables de contratación tienen que revisar cientos de currículos y distinguir a los mejores candidatos. Además, en muchas ocasiones, tu currículum pasa por los sistemas de seguimiento de candidatos (ATS), unos programas informáticos automatizados que utilizan muchas empresas para revisar los currículums y descartar aquellos que no cumplen unos criterios específicos. Por lo tanto, debes crear un buen currículum y redactar una impresionante carta de presentación para impresionar tanto al ATS como a tus reclutadores.
Llama la atención de un responsable de contratación
Si llamas la atención del responsable de contratación o tu currículum eficaz supera el proceso de selección, lo siguiente que debes hacer es prepararte para una entrevista técnica. Para estar preparado, puedes consultar este artículo sobre 20 preguntas de entrevista sobre Kafka para ingenieros de datos.
Aprender Apache Kafka puede abrirte las puertas a mejores oportunidades y resultados profesionales. El camino para aprender Kafka es gratificante, pero requiere constancia y práctica. Experimentar y resolver retos con esta herramienta puede acelerar tu proceso de aprendizaje y proporcionarte ejemplos reales para demostrar tus habilidades prácticas cuando busques trabajo.
¡Aprende ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
Adejumo Ridwan Suleiman
13 min
blog
Gus Frazer
11 min
blog
Elena Kosourova
15 min
blog
Matt Crabtree
15 min
blog
Adel Nehme
15 min
blog
Javier Canales Luna
15 min


