
Programa
Engenheiro de dados associado em SQL
30 h
Processar dados em tempo real nos dá ótimas oportunidades. Se um banco perceber uma compra estranha com o nosso cartão de crédito, eles podem parar a transação na hora. Ou, se estivermos procurando um produto, sugestões de produtos podem aparecer enquanto navegamos pelo site. Essa rapidez significa melhores decisões, clientes mais satisfeitos e um negócio mais eficiente.
O Apache Kafka é um armazenamento de dados distribuído de alto rendimento, feito pra coletar, processar, guardar e analisar dados em tempo real. Permite que diferentes aplicativos publiquem e assinem fluxos de dados, possibilitando que eles se comuniquem e reajam a eventos à medida que eles acontecem.
Por gerenciar fluxos de dados de forma eficiente, o Kafka ficou super popular. É usado em vários sistemas, desde compras online e redes sociais até bancos e saúde.
O Apache Kafka ficou bem popular entre os profissionais de dados que precisam lidar com fluxos de dados em tempo real. A gente pode explicar a popularidade dele por vários fatores importantes:
O Apache Kafka é usado atualmente em aplicativos que precisam processar e analisar dados em tempo real. Mas quais recursos fazem dele uma ferramenta poderosa para lidar com dados de streaming? Vamos dar uma olhada neles:
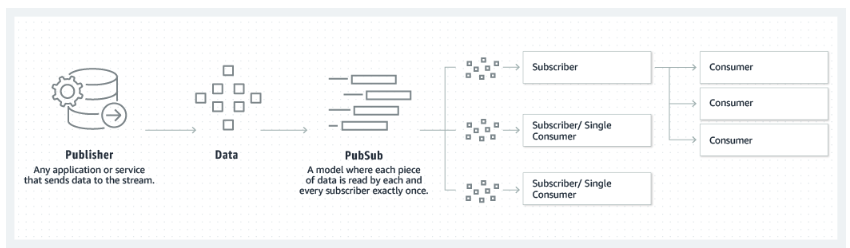
O modelo editor-assinante em que o Kafka se baseia. Fonte: Amazon
Aprender Apache Kafka faz de você um candidato valioso para empregadores e empresas que geram e processam dados em altas taxas. O Apache Kafka, com seus recursos poderosos e uso generalizado, virou uma ferramenta essencial pra construir arquiteturas de dados modernas e aplicativos.
Já falei que Kafka ficou super popular nos últimos anos. A gente acha que o Apache Kafka tá sendo usado por mais de 80% das empresas da Fortune 100.
O uso cada vez maior do Kafka em vários setores, junto com o papel dele em possibilitar soluções de dados em tempo real, faz com que as habilidades em Kafka sejam super valiosas no mercado de trabalho. De acordo com o PayScale e ZipRecruiter, em novembro de 2024, o salário médio de um engenheiro com habilidades em Kafka nos Estados Unidos era de US$ 100.000 por ano.
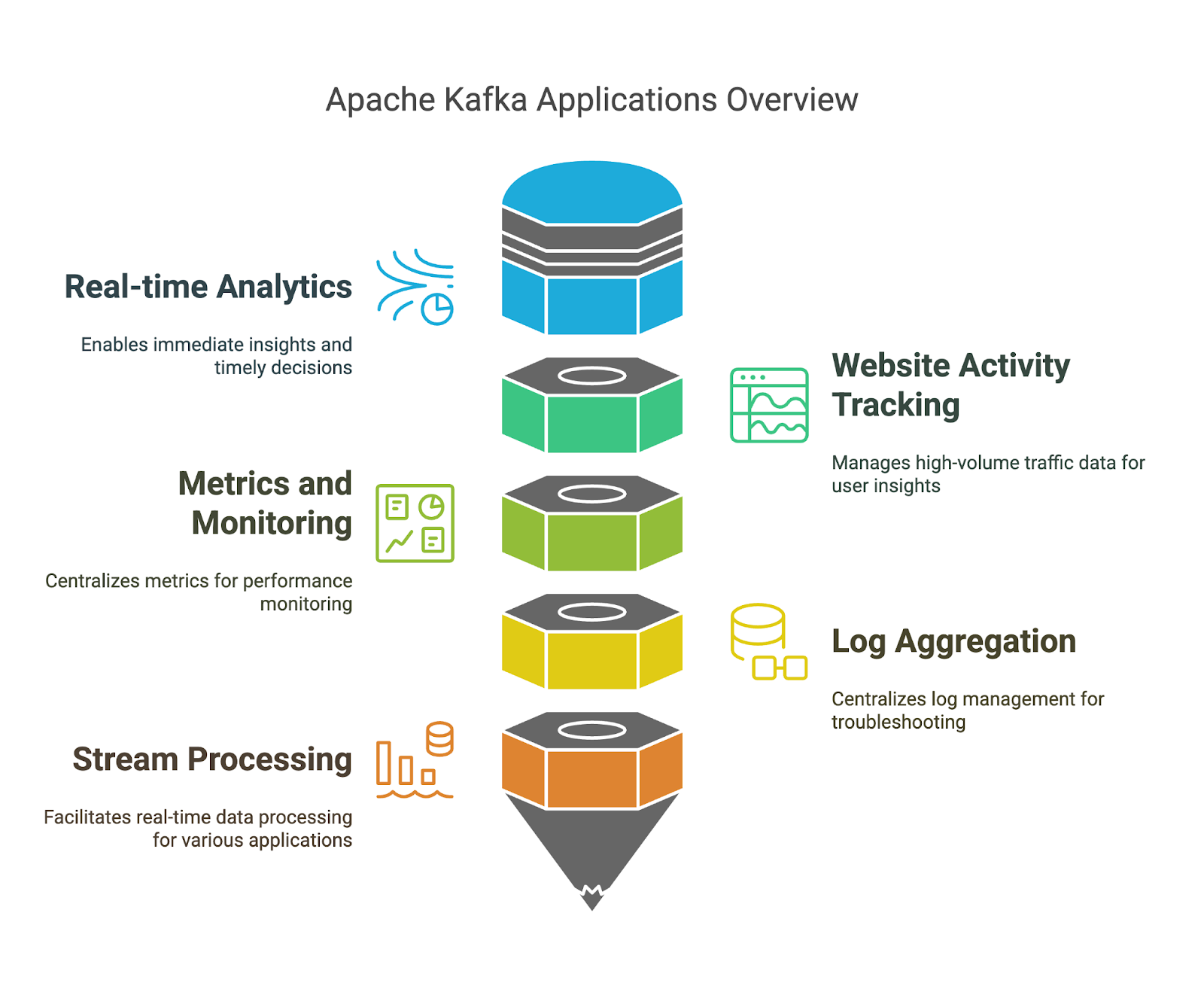
Já falamos sobre os pontos fortes do Apache Kafka, mas vamos ver alguns exemplos específicos de onde você pode usá-los:
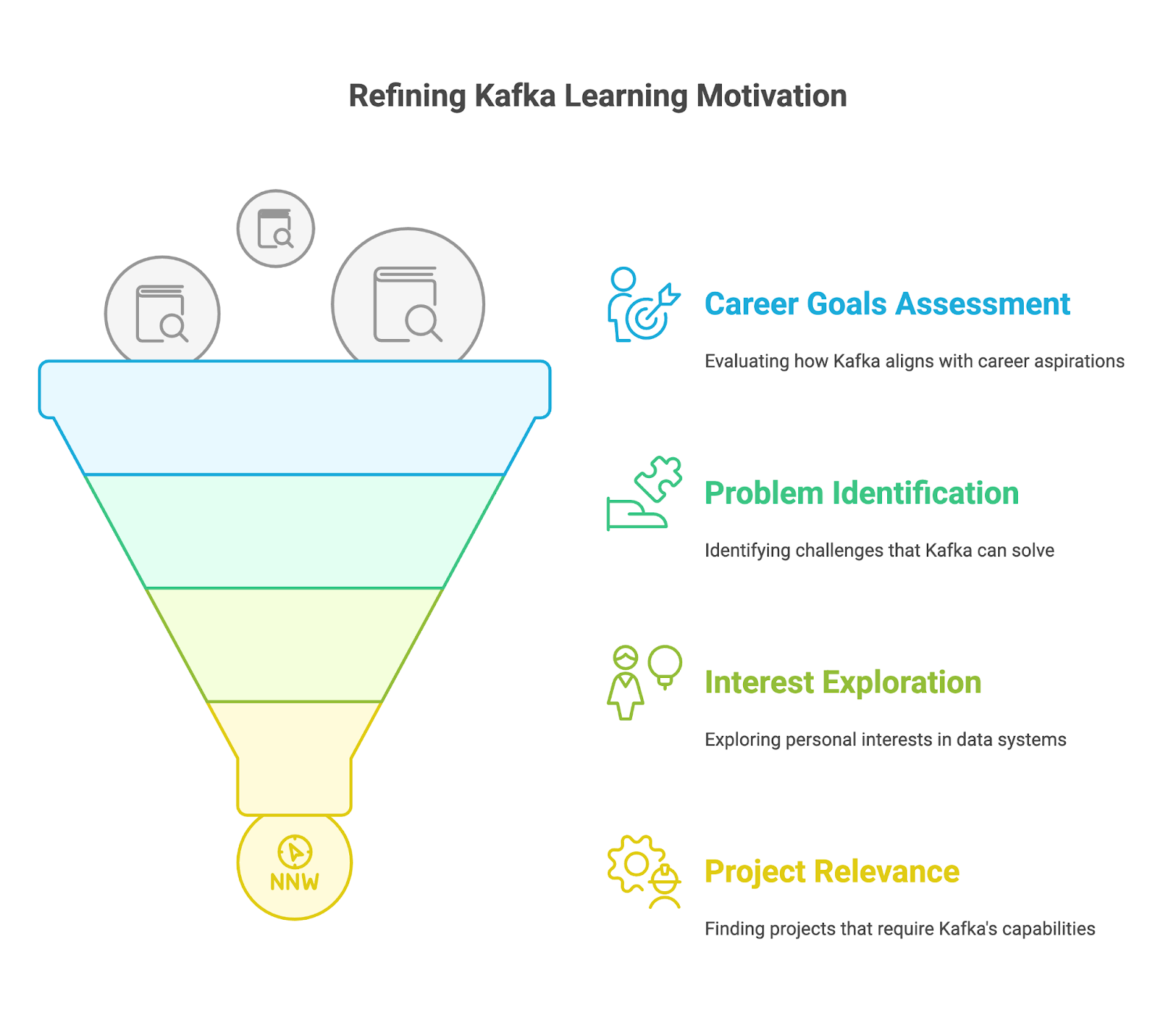
Se você aprender o Apache Kafka de forma organizada, vai ter mais chances de sucesso. Vamos focar em alguns princípios que você pode usar na sua jornada de aprendizado.
Antes de aprender os detalhes técnicos, pense por que você quer aprender o Apache Kafka. Pergunte a si mesmo:
Depois de definir seus objetivos, aprenda o básico do Kafka e entenda como ele funciona.
Pra aprender Apache Kafka, primeiro a gente precisa instalar ele na nossa máquina local. Como o Kafka é desenvolvido usando Java, você pode usar o JDK 7 ou mais recente. Java, devemos garantir que o Java esteja instalado. Depois, a gente precisa baixar os binários do Kafka do site oficial e extraí-los.
Agora vamos iniciar o ZooKeeper, seguido pelo servidor Kafka, usando os scripts fornecidos. Por fim, podemos usar as ferramentas de linha de comando para criar tópicos e tentar produzir e consumir algumas mensagens para entender o básico. DataCamp's Apache Kafka para iniciantes pode te ajudar a se atualizar.
O primeiro conceito que devemos aprender é o modelo editor-assinante no Kafka. Essa é uma das principais razões pelas quais o Apache Kafka consegue lidar com dados de streaming de forma eficiente. Entenda como os produtores publicam mensagens e os consumidores se inscrevem nesses tópicos, recebendo só as mensagens que são relevantes para os seus interesses.
Introdução ao DataCamp Introdução ao Apache Kafka oferece uma introdução, com exercícios interativos e exemplos práticos.
Ao falar sobre o modelo editor-assinante, mencionamos alguns componentes importantes do Kafka: Produtor e Consumidor. Mas, a gente deveria dar uma olhada em todos os componentes principais. A gente precisa aprender como o Kafka organiza os dados em tópicos e partições, e entender como as partições ajudam na escalabilidade e na tolerância a falhas.
Também devemos entender como os brokers formam um cluster para oferecer alta disponibilidade e tolerância a falhas.
Dá uma olhada no DataCamp's Introdução ao Apache Kafka e o artigo artigo Apache Kafka para iniciantes para entender melhor esses assuntos.
Quando você estiver confortável com o básico, é hora de explorar as habilidades intermediárias do Apache Kafka.
Uma das principais características do Apache Kafka é a capacidade de lidar com grandes volumes de dados em streaming. O Kafka Connect é um componente gratuito e de código aberto do Apache Kafka que simplifica a integração de dados entre sistemas de arquivos, bancos de dados, índices de pesquisa e armazenamentos de chave-valor.
Aprender a usar o Connect pode nos ajudar a desbloquear um fluxo de dados eficiente para análises, integração de aplicativos e construção de uma arquitetura de dados robusta e escalável. Dá uma olhada no nosso artigo Apache Kafka para iniciantes para mais detalhes.
Outro recurso avançado do Kafka é o Streams. A gente precisa aprender a criar aplicativos de processamento de fluxo direto no Kafka com a ajuda do Streams. Ele oferece APIs e uma linguagem específica de domínio de alto nível para lidar, converter e avaliar fluxos contínuos de dados. Saiba mais sobre Artigo Apache Kafka para iniciantes.
Como com qualquer outra tecnologia, é sempre bom programar o desempenho dela. Pra isso, a gente precisa aprender a monitorar a saúde e o desempenho do nosso cluster Kafka. Podemos explorar ferramentas e técnicas para monitorar métricas importantes, gerenciar tópicos e partições e garantir um desempenho ideal.
Fazer cursos sobre o Apache Kafka é uma ótima maneira de se familiarizar com a tecnologia. Mas, pra ficar craque no Kafka, você precisa resolver problemas desafiadores e que desenvolvam suas habilidades, tipo aqueles que você vai encontrar em projetos reais.
Você pode começar experimentando tarefas simples de streaming de dados, como produzir e consumir mensagens, e depois aumentar gradualmente a complexidade explorando tópicos como particionamento, tolerância a falhas e integração com sistemas externos usando o Kafka Connect.
Aqui estão algumas maneiras de praticar suas habilidades:
Você vai fazer vários projetos diferentes enquanto avança na sua jornada de aprendizado do Apache Kafka. Para mostrar suas habilidades e experiência com o Apache Kafka para possíveis empregadores, você deve juntar tudo em um portfólio. Esse portfólio deve mostrar suas habilidades e interesses e ser feito sob medida para a carreira ou setor que você curte.
Tente fazer projetos originais e mostrar suas habilidades pra resolver problemas. Inclua projetos que mostrem sua habilidade em diferentes partes do Kafka, tipo criar pipelines de dados com o Kafka Connect, desenvolver aplicativos de streaming com o Kafka Streams ou trabalhar com clusters do Kafka. Documente seus projetos com cuidado, colocando o contexto, a metodologia, o código e os resultados. Você pode usar plataformas como o GitHub para hospedar seu código e o Confluent Cloud para um ambiente Kafka gerenciado.
Aprender Kafka é uma jornada contínua. A tecnologia está sempre mudando, e novos recursos e aplicativos são criados o tempo todo. Kafka não é exceção a isso.
Depois de dominar os fundamentos, você pode procurar tarefas e projetos mais desafiadores, como ajuste de desempenho para sistemas de alto rendimento e implementação de processamento avançado de fluxo com Kafka Streams. Concentre-se em seus objetivos e especialize-se em áreas que sejam relevantes para suas metas profissionais e interesses.
Fique por dentro das novidades, tipo novos recursos ou propostas do KIP, e aprenda como usar isso nos seus projetos. Continue praticando, procure novos desafios e oportunidades e aceite a ideia de cometer erros como uma forma de aprender.
Mesmo que cada pessoa tenha sua maneira de aprender, é sempre uma boa ideia ter um plano ou guia para seguir ao aprender uma nova ferramenta. Criei um plano de aprendizagem potencial que mostra onde você deve focar seu tempo e esforços se estiver começando com o Apache Kafka.

Imagino que, a essa altura, você já esteja pronto para começar a aprender Kafka e colocar as mãos em um grande conjunto de dados para praticar sua nova habilidade. Mas antes disso, deixa eu te dar umas dicas que vão te ajudar a chegar lá e dominar o Apache Kafka.
O Kafka é uma ferramenta versátil que pode ser usada de várias maneiras. Você deve identificar seus objetivos e interesses específicos dentro do ecossistema Kafka. Qual aspecto de Kafka mais te atrai? Você curte engenharia de dados, processamento de fluxo ou administração do Kafka? Uma abordagem focada pode te ajudar a aprender os aspectos e conhecimentos mais relevantes do Apache Kafka para atender aos seus interesses.
A consistência é fundamental para dominar qualquer nova habilidade. Você deve reservar um tempo só para praticar Kafka. Basta dedicar um tempinho todos os dias. Você não precisa lidar com conceitos complexos todos os dias. Você pode fazer exercícios práticos, seguir tutoriais e experimentar diferentes recursos do Kafka. Quanto mais você praticar, mais à vontade ficará com a plataforma.
Essa é uma das dicas mais importantes, e você vai ver isso várias vezes neste guia. Fazer exercícios é ótimo pra ganhar confiança. Mas, usar suas habilidades em Kafka em projetos reais é o que vai fazer você se destacar nisso.
Comece com projetos e questões simples e, aos poucos, vá encarando os mais complexos. Isso pode envolver a criação de um aplicativo simples de produtor-consumidor, depois avançar para a construção de um pipeline de dados em tempo real com o Kafka Connect, ou até mesmo projetar um aplicativo de streaming tolerante a falhas com o Kafka Streams. O segredo é continuar se desafiando e expandindo suas habilidades práticas com o Kafka.
Aprender costuma ser mais eficaz quando feito em grupo. Compartilhar suas experiências e aprender com os outros pode acelerar seu progresso e trazer insights valiosos.
Pra trocar conhecimento, ideias e perguntas, você pode entrar em alguns grupos relacionados ao Apache Kafka e participar de encontros e conferências. Você pode entrar em comunidades online como o canal Confluent Slack ou Fórum Confluent, onde você pode interagir com outros entusiastas do Kafka. Você também pode participar de encontros virtuais ou presenciais encontros, com palestras de especialistas em Kafka, ou conferências, como a ApacheCon.
Como com qualquer outra tecnologia, aprender Apache Kafka é um processo que vai rolando. Aprender com seus erros é uma parte essencial desse processo. Não tenha medo de experimentar, tente diferentes abordagens e aprenda com seus erros.
Experimente diferentes configurações para seus produtores e consumidores Kafka, explore vários métodos de serialização de dados (JSON, Avro, Protobuf) e teste diferentes estratégias de particionamento. Leve seu cluster Kafka ao limite com grandes volumes de mensagens e veja como ele lida com a carga. Analise o atraso do consumidor, ajuste as configurações e entenda como suas otimizações afetam o desempenho.
Dá uma olhada com calma pra entender de verdade conceitos importantes como tópicos, partições, grupos de consumidores e o papel do ZooKeeper. Se você construir agora uma base sólida, vai ser mais fácil entender assuntos mais avançados e resolver problemas de forma eficaz. Divida o processo de aprendizagem em etapas menores e dê a si mesmo tempo para entender as informações. Uma abordagem lenta e constante geralmente leva a uma compreensão mais profunda e ao domínio.
Vamos ver alguns métodos eficientes para aprender Apache Kafka.
Os cursos online são uma ótima maneira de aprender Apache Kafka no seu ritmo. DataCamp oferece um curso intermediário sobre Kafka. Este curso aborda os conceitos básicos do Kafka, incluindo o modelo editor-assinante, tópicos e partições, corretores e clusters, produtores e consumidores.
Os tutoriais são outra ótima maneira de aprender Apache Kafka, principalmente se você é novo nessa tecnologia. Eles têm instruções passo a passo sobre como fazer tarefas específicas ou entender certos conceitos. Pra começar, dá uma olhada nesses tutoriais:
Para entender melhor as vantagens do Apache Kafka, você também precisa saber quais são as principais semelhanças e diferenças com outras tecnologias. Você pode ler artigos sobre como o Kafka se compara a outras ferramentas, como os seguintes:
Os livros são um ótimo jeito de aprender sobre o Apache Kafka. Eles oferecem conhecimento aprofundado e insights de especialistas, além de trechos de código e explicações. Aqui estão alguns dos livros mais populares sobre Kafka:
Como o Apache Kafka tá cada vez mais popular, as oportunidades de carreira pra quem sabe usar o Kafka também aumentam, desde engenheiros especializados em Kafka até engenheiros de software. Se você está avaliando suas habilidades em Kafka, considere estas funções:

Como engenheiro Kafka, você é responsável por projetar, construir e manter soluções de streaming de dados baseadas em Kafka com alta disponibilidade e escalabilidade. Você vai precisar garantir um fluxo de dados confiável e eficiente dentro da empresa, além de monitorar e otimizar o desempenho do Kafka para garantir um rendimento e uma latência ideais.
Como engenheiro de dados, você é o arquiteto da infraestrutura de dados, responsável por projetar e construir os sistemas que lidam com os dados de uma empresa. O Kafka costuma ter um papel importante nesses pipelines de dados, permitindo um fluxo de dados em tempo real eficiente e escalável entre diferentes sistemas. Você vai precisar garantir que o Kafka se integre perfeitamente com outros componentes.
Como engenheiro de software, você vai usar o Kafka para criar aplicativos em tempo real, como plataformas de bate-papo e jogos online. Você vai precisar integrá-lo ao código do aplicativo para garantir um fluxo de dados tranquilo, conectando-se a vários sistemas de mensagens e APIs. Você também vai otimizar esses aplicativos para escalabilidade e desempenho, permitindo que eles lidem com grandes quantidades de dados em tempo real.
|
Função |
O que você faz |
Suas principais habilidades |
Ferramentas que você usa |
|
Engenheiro Kafka |
Projete e implemente clusters Kafka para alta disponibilidade e escalabilidade. |
Arquitetura Kafka, componentes, administração e configuração, conceitos de processamento de fluxo. |
Apache Kafka, Kafka Connect, Kafka Streams, ZooKeeper |
|
Engenheiro de Dados |
Projetar e implementar warehouses e lagos de dados, integrar o Kafka com outros sistemas de processamento e armazenamento de dados |
Proficiência em ferramentas de processamento de dados, experiência com plataformas em nuvem e conhecimento de Kafka. |
Apache Kafka, Apache Spark, Hadoop, Colmeia, Plataformas em nuvem |
|
Engenheiro de Software |
Crie e desenvolva aplicativos que usam o Kafka para comunicação de dados em tempo real. |
Conhecimentos de programação, sistemas e aplicações distribuídos, conhecimento sobre o editor-assinante Kafka. |
Apache Kafka, Java, Python, Scala, RabbitMQ, ActiveMQ, Ferramentas e estruturas de desenvolvimento. |
Embora ter um diploma possa ser muito valioso quando se busca uma carreira em uma função relacionada a dados que usa o Apache Kafka, esse não é o único caminho para o sucesso. Cada vez mais pessoas de diferentes origens e experiências estão começando a trabalhar em funções relacionadas a dados. Com dedicação, aprendizado constante e uma abordagem proativa, você pode conseguir o emprego dos seus sonhos usando o Apache Kafka.
Fique por dentro das últimas novidades sobre o Kafka. Siga profissionais influentes que estão envolvidos com o Apache Kafka nas redes sociais, leia blogs relacionados ao Apache Kafka e ouça podcasts relacionados ao Kafka.
Interaja com pessoas influentes, como Neha Narkhede, que ajudou a criar o Kafka e também é CTO da Confluent. Você vai ficar por dentro dos assuntos do momento, tecnologias novas e o que vem por aí no Apache Kafka. Você também também ler o blog da Confluent, que oferece artigos detalhados e tutoriais sobre uma ampla variedade de tópicos do Kafka, desde arquitetura e administração até casos de uso e melhores práticas.
Você também deve conferir eventos do setor, como webinars em Confluent ou o Kafka Summit.
Você precisa se destacar dos outros candidatos. Uma boa maneira de fazer isso é montar um portfólio bacana que mostre suas habilidades e os projetos que você já fez.
Seu portfólio deve ter projetos que mostrem como você é bom em criar pipelines de dados, implementar aplicativos de processamento de fluxo e integrar o Kafka com outros sistemas.
Os gerentes de contratação precisam analisar centenas de currículos e escolher os melhores candidatos. Além disso, muitas vezes, seu currículo passa por Sistemas de Rastreamento de Candidatos (ATS), que são softwares automáticos que várias empresas usam pra analisar currículos e descartar aqueles que não atendem a critérios específicos. Então, você deve fazer um currículo incrível e escrever uma carta de apresentação impressionante pra impressionar tanto o ATS quanto os recrutadores.
Chame a atenção de um gerente de contratação
Se você chamar a atenção do gerente de contratação ou se o seu currículo for aprovado no processo de seleção, você deve se preparar para uma entrevista técnica. Para se preparar, dá uma olhada nesse artigo sobre 20 perguntas de entrevista sobre Kafka para engenheiros de dados.
Aprender Apache Kafka pode abrir portas para melhores oportunidades e resultados profissionais. O caminho para aprender Kafka é gratificante, mas precisa de consistência e prática. Experimentar e resolver desafios usando essa ferramenta pode acelerar seu processo de aprendizagem e te dar exemplos reais para mostrar suas habilidades práticas quando estiver procurando emprego.
Aprenda engenharia de dados com esses cursos!
Programa
Curso
Curso
blog
Adejumo Ridwan Suleiman
13 min
blog
Gus Frazer
11 min
blog
Moez Ali
11 min
blog
Çağlar Uslu
12 min
blog
Matt Crabtree
14 min
blog
Elena Kosourova
15 min

