Curso
Streaming de datos con AWS Kinesis y Lambda
4 h
9.2K
Si estás creando aplicaciones modernas, sabes lo importante que es manejar grandes volúmenes de datos de forma eficiente. Las plataformas de streaming de eventos son la solución a seguir para el procesamiento y análisis de datos en tiempo real.
En este artículo, exploraremos dos de las plataformas más populares en este espacio: Apache Kafka y Amazon Simple Queue Service (SQS). Compararemos los puntos fuertes y débiles de cada plataforma y te proporcionaremos ideas prácticas para ayudarte a tomar decisiones informadas para tus proyectos basados en datos.
Para quienes sepan exactamente lo que buscan y sólo busquen una comparación rápida entre Apache Kafka y Amazon SQS, la tabla siguiente les servirá de guía concisa. Sin embargo, si buscas una más detallada, sigue leyendo para ver una amplia comparación.
|
Categoría |
Kafka |
SQS |
Ganador |
|
Arquitectura |
Distribuido, pub-sub |
Centralizado, basado en pull |
Kafka |
|
Escalabilidad |
Altamente escalable para grandes volúmenes |
Altamente escalable para pequeños volúmenes |
Kafka para grandes, SQS para pequeños |
|
Persistencia de mensajes |
Periodos de retención configurables |
Períodos de conservación limitados |
Kafka |
|
Envío de mensajes |
Al menos una vez, exactamente una vez con transacciones |
Al menos una vez, exactamente una vez con deduplicación |
Corbata |
|
Grupos de consumidores |
Apoyado |
No se admite |
Kafka |
|
Integración |
Amplio ecosistema, conectores |
Estrecha integración con AWS |
Kafka para no AWS, SQS para AWS |
|
Facilidad de uso |
Curva de aprendizaje más pronunciada |
Totalmente gestionado, más fácil de poner en marcha |
SQS |
|
Coste |
Código abierto, costes de infraestructura |
Pay-as-you-go |
SQS para cargas de trabajo menores, Kafka para mayores |
|
Retención de mensajes |
Más largo |
14 días |
Kafka |
|
Soporte de protocolo |
Multiple |
Limitado |
Kafka |
|
Dificultad sintáctica |
Más complejo |
Simple y sencillo |
SQS |
Las plataformas de streaming de eventos como Apache Kafka y Amazon SQS son las mejores opciones en los entornos modernos basados en datos. Te permiten recopilar, procesar y analizar los datos a medida que se generan, lo que permite tomar decisiones más rápidamente y mejorar la capacidad de respuesta.
Éstas son algunas de las razones por las que las plataformas de streaming como Kafka y SQS son importantes:
Las plataformas de streaming de eventos permiten la recogida continua de datos y su procesamiento en tiempo real. Esta capacidad es relevante para aplicaciones que requieren información y acciones inmediatas, como comercio financiero financieros, detección de fraudesy monitorización de redes sociales. Al procesar los datos a medida que llegan, puedes tomar decisiones oportunas y responder con rapidez a los acontecimientos emergentes.
Estas plataformas admiten la comunicación asíncrona, desacoplando a los productores y consumidores de datos. Este desacoplamiento permite que los distintos componentes del sistema funcionen de forma independiente, mejorando la resistencia y la flexibilidad. La comunicación asíncrona también permite a los servicios escalar de forma independiente y evolucionar sin causar interrupciones a otros componentes.
Tanto Kafka como SQS están diseñados para ofrecer una gran escalabilidad y fiabilidad. Kafka puede gestionar millones de eventos por segundo escalando horizontalmente mediante la adición de más intermediarios. SQS se escala automáticamente para gestionar volúmenes de mensajes crecientes, lo que lo hace adecuado para cargas de trabajo variables. Estas capacidades garantizan que las plataformas puedan satisfacer las exigencias de las tareas de procesamiento de datos a gran escala.
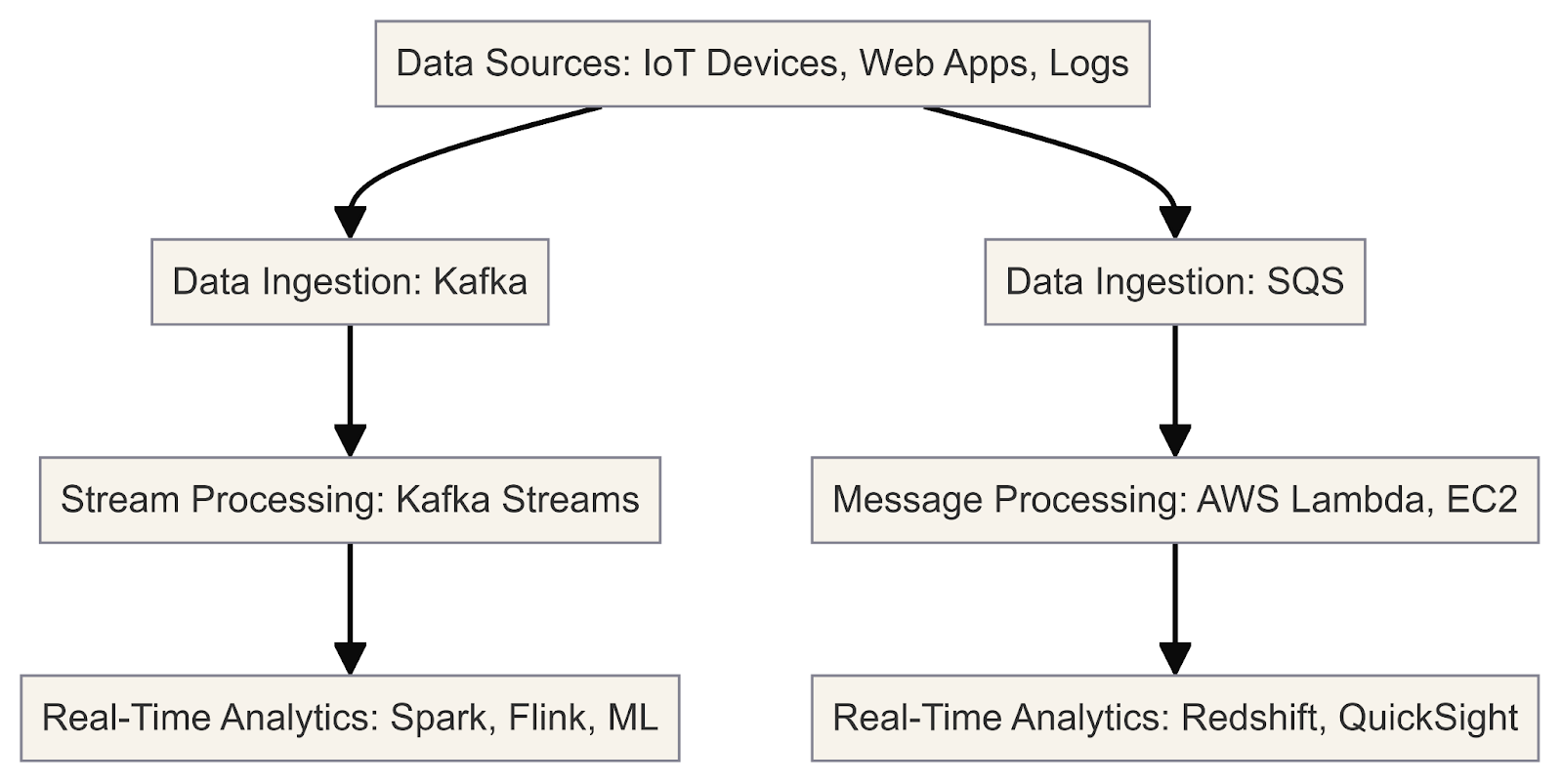
Este diagrama ilustra el flujo de trabajo de procesamiento y análisis de datos en tiempo real utilizando Kafka y SQS
Ahora que hemos aclarado la importancia de las plataformas de streaming, revisemos Kafka y SQS en detalle.
Apache Kafka es una plataforma de streaming de eventos distribuidos de código abierto diseñada para manejar grandes volúmenes de datos en tiempo real. Suele emplearse para tareas como la mensajería, la agregación de registros, el procesamiento de flujos y los registros de confirmaciones.
La arquitectura de Kafka está diseñada para ofrecer una gran escalabilidad y tolerancia a fallos, lo que la convierte en la solución ideal para las aplicaciones basadas en datos. Piensa en Kafka como una canalización de datos de alto rendimiento que te permite crear fácilmente canalizaciones de datos en tiempo real canalización de datos y aplicaciones en tiempo real.
Como desarrollador, puedes aprovechar los componentes básicos de Kafka para manejar eficazmente flujos de datos en tiempo real. He aquí un ejemplo práctico de cómo funciona Kafka con Python:
Visita el sitio web de Apache Kafka y descarga la última versión. Elige la descarga binaria que coincida con tu sistema operativo.
Extrae el archivo descargado a un directorio de tu elección. Este directorio será tu directorio de instalación de Kafka.
En un Terminal, navega hasta el directorio Kafka extraído e inicia los servicios Zookeeper y Kafka broker utilizando los scripts proporcionados:
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka broker
bin/kafka-server-start.sh config/server.propertiesTen en cuenta que Zookeeper está actualmente marcado como obsoleto y está previsto que se elimine en Apache Kafka 4.0. Para más detalles, consulta la documentación.
Los intermediarios son los servidores Kafka que se encargan del almacenamiento y la replicación de los flujos de datos. Puedes interactuar con los corredores mediante herramientas de línea de comandos o mediante programación, utilizando bibliotecas de clientes.
He aquí un ejemplo de uso de herramientas de línea de comandos para gestionar e interactuar con temas Kafka:
bin/kafka-topics.sh --create --topic my_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1bin/kafka-topics.sh --list --bootstrap-server localhost:9092bin/kafka-console-producer.sh --topic my_topic --bootstrap-server localhost:9092bin/kafka-console-consumer.sh --topic my_topic --bootstrap-server localhost:9092 --from-beginningAsegúrate de que tienes Python instalado en tu sistema. Las bibliotecas cliente Python de Kafka son compatibles con Python 3.7 y versiones posteriores.
Crea un entorno virtual para aislar las dependencias de tu proyecto. Puedes utilizar venv.
Esta es la biblioteca cliente Python oficial de Apache Kafka:
pip install kafka-pythonDependiendo de los requisitos de tu proyecto, puede que necesites instalar bibliotecas adicionales, como json, para la serialización/deserialización de JSON.
A continuación, utiliza el siguiente script para listar los intermediarios mediante programación:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# List the available brokers
brokers = admin_client.describe_cluster()
print("Brokers:", brokers['brokers'])Particiones son una forma que tiene Kafka de conseguir paralelismo y escalabilidad. Cada partición es una secuencia ordenada e inmutable de registros que se añade continuamente. Puedes configurar el número de particiones de un tema al crearlo:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# Create a new topic with 3 partitions
topic = NewTopic(name="social-media-posts", num_partitions=3, replication_factor=1)
admin_client.create_topics([topic])Comprender las particiones puede ayudarte a optimizar tus aplicaciones para mejorar el rendimiento y la tolerancia a fallos.
Con Kafka y las librerías Python necesarias instaladas, ya puedes empezar a escribir tus aplicaciones productoras y consumidoras de Kafka en Python.
Aquí tienes un ejemplo de cómo puedes crear un productor Kafka para publicar posts en redes sociales y un consumidor para procesarlos:
Los productores son los clientes que publican flujos de datos en temas Kafka. Pueden integrarse en tus aplicaciones, servicios o fuentes de datos para introducir datos en Kafka en tiempo real.
from kafka import KafkaProducer
import json
# Create a Kafka producer
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('utf-8'))
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Publish the social media post to the 'social-media-posts' topic
producer.send('social-media-posts', social_media_post)Los consumidores son los clientes que se suscriben a uno o varios temas y consumen flujos de datos de Kafka. Pueden implementar varios patrones de consumo en función de los requisitos de tu aplicación.
from kafka import KafkaConsumer
import json
# Create a Kafka consumer
consumer = KafkaConsumer('social-media-posts',
bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
# Consume and process social media posts
for message in consumer:
social_media_post = message.value
print(f"Received post: {social_media_post}")
# Process the social media post...Este código de ejemplo proporciona una visión completa de la instalación de Kafka, la configuración del entorno Python y la implementación de productores y consumidores de Kafka para el procesamiento de datos en tiempo real.
SQS es un servicio de servicio de cola de mensajes proporcionado por AWS. Te permite desacoplar y escalar microservicios, sistemas distribuidos y aplicaciones sin servidor.
En esencia, SQS es un sistema de colas distribuido que te permite enviar, almacenar y recibir mensajes entre componentes de software de forma asíncrona. Estos mensajes pueden ser cualquier dato de texto, notificaciones del sistema o incluso punteros a datos más grandes almacenados en otros servicios de AWS como S3 o DynamoDB.
Una ventaja clave de SQS es que elimina la necesidad de gestionar tu infraestructura de colas de mensajes. AWS maneja los aspectos subyacentes de administración de colas, escalado y tolerancia a fallos bajo el capó, permitiéndote centrarte en la lógica de tu aplicación.
SQS ofrece dos tipos de colas:
Una de las ventajas de SQS es que forma parte del el ecosistema de AWSy, por tanto, puede integrarse fácilmente con otros servicios de AWS. La forma en que se produce esa integración depende de si el servicio es productor o consumidor:
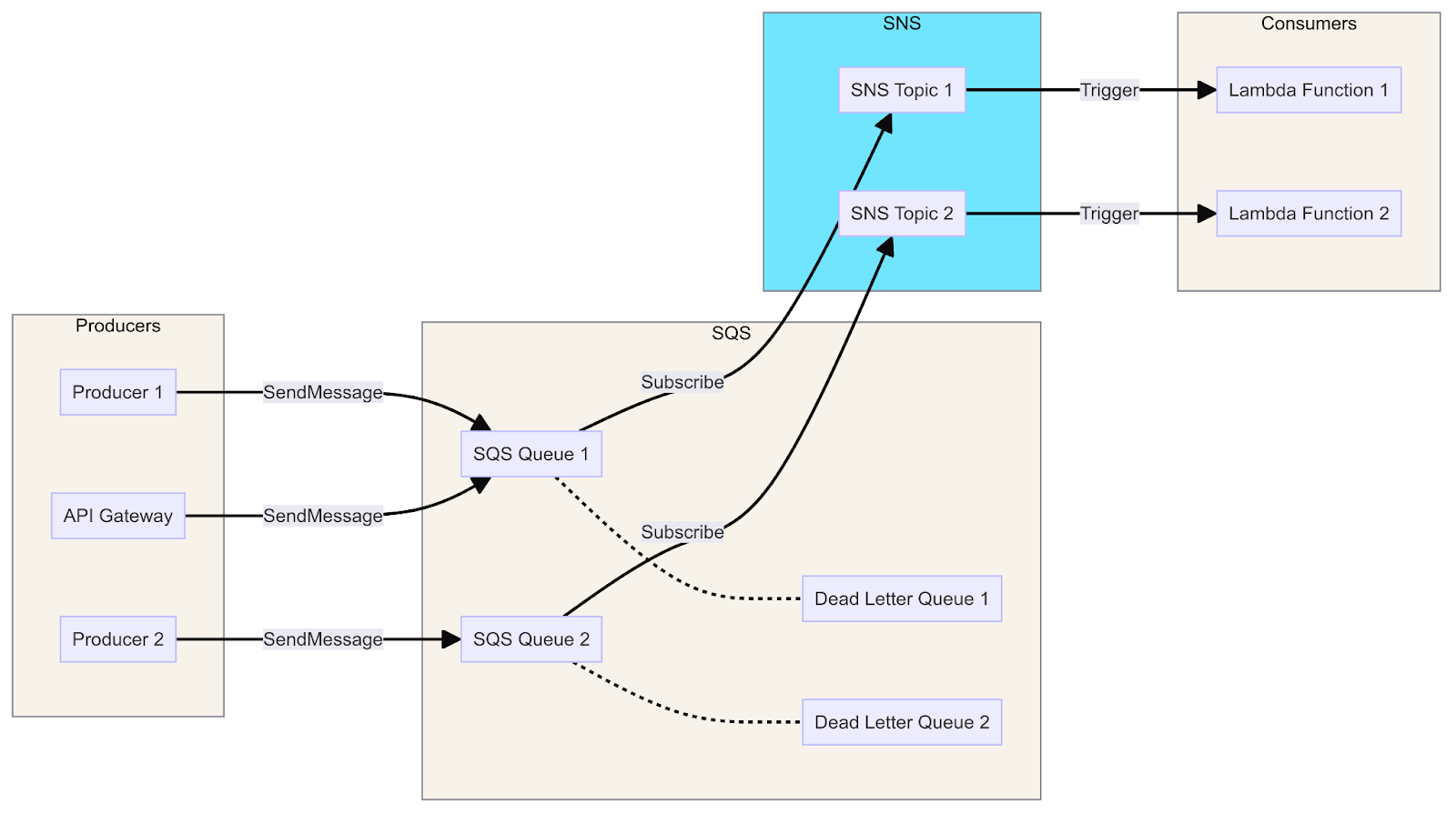
Un diagrama que muestra la integración de SQS con Lambda, SNS y API Gateway, ilustra el flujo de mensajes de los productores a los consumidores a través de colas, temas y funciones.
Ahora veamos a productores y consumidores en acción. Aquí tienes una guía para configurar y utilizar AWS SQS con Python, que incluye los pasos básicos para la instalación y un ejemplo de productor y consumidor para SQS:
Si aún no tienes una, crea una cuenta de AWS en Nivel gratuito de AWS.
Instala y configura la interfaz de línea de comandos (CLI) de AWS para administrar tus recursos de AWS.
# Install AWS CLI
pip install awscli
# Configure AWS CLI with your credentials
aws configureProporciona tu clave de acceso a AWS, la clave secreta, la región y el formato de salida cuando se te solicite.
Utilizaremos el boto3 el SDK oficial de AWS para Python, para interactuar con SQS utilizando Python.
boto3pip install boto3Crea una cola SQS mediante la consola de administración de AWS o mediante programación con boto3.
import boto3
# Create SQS client
sqs = boto3.client('sqs')
# Create a new queue
response = sqs.create_queue(
QueueName='social-media-posts',
Attributes={
'DelaySeconds': '0',
'MessageRetentionPeriod': '86400' # 1 day
}
)
print(response['QueueUrl'])Un productor envía mensajes a la cola SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Send message to SQS queue
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(social_media_post)
)
print(response['MessageId'])Un consumidor recibe y procesa mensajes de la cola SQS.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Receive messages from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=10,
WaitTimeSeconds=10
)
if 'Messages' in response:
for message in response['Messages']:
social_media_post = json.loads(message['Body'])
print(f"Received post: {social_media_post}")
# Process the social media post...
# Delete received message from queue
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=message['ReceiptHandle']
)
else:
print('No messages received')Así es como puedes crear fácilmente una cola SQS, enviar mensajes como productor y recibir mensajes como consumidor. El ejemplo anterior cubre los pasos básicos para empezar.
Para conocer los pasos detallados de la configuración, asegúrate de consultar la documentación de AWS SQS.
Ahora, comparemos Kafka y SQS y veamos sus similitudes.
Tanto Kafka como SQS son sistemas de cola de mensajes diseñados para facilitar la comunicación asíncrona entre los distintos componentes de un sistema distribuido. Actúan como intermediarios, permitiendo a los productores enviar mensajes y a los consumidores recibirlos y procesarlos.
Kafka y SQS desacoplan a productores y consumidores, permitiéndoles operar de forma independiente y escalar independientemente. Este desacoplamiento favorece el acoplamiento suelto, la tolerancia a fallos y la escalabilidad en los sistemas distribuidos.
Tanto Kafka como SQS proporcionan mecanismos para persistir los mensajes, garantizando que no se pierdan en caso de fallos o reinicios del sistema. Kafka almacena los mensajes en un registro de confirmación distribuido, mientras que SQS almacena los mensajes en una cola altamente duradera y disponible.
Kafka y SQS están diseñados para ser sistemas altamente escalables. Kafka puede escalar horizontalmente añadiendo más brokers al clúster, mientras que SQS puede escalar automáticamente para gestionar volúmenes de mensajes cada vez mayores.
Tanto Kafka como SQS ofrecen capacidades de integración con otros sistemas y servicios. Kafka tiene un amplio ecosistema de conectores e integraciones, mientras que SQS se integra perfectamente con otros servicios de AWS.
Aunque Kafka y SQS tienen diferentes garantías de ordenación por defecto, ambos sistemas proporcionan mecanismos para preservar la ordenación de los mensajes cuando es necesario. Kafka ofrece una entrega ordenada dentro de particiones, mientras que SQS ofrece colas FIFO para un procesamiento de mensajes estrictamente ordenado.
Kafka y SQS proporcionan capacidades de monitorización y métricas, lo que permite a los usuarios seguir y monitorizar el rendimiento y la salud de sus sistemas de mensajería.
Tanto Kafka como SQS ofrecen funciones de seguridad, como encriptación, control de acceso y mecanismos de autenticación, para proteger los datos en tránsito y en reposo.
Ahora, comparemos Kafka y SQS y observemos sus diferencias más importantes.
Kafka es una plataforma de streaming distribuido que sigue un modelo de publicación-suscripción. Consiste en un conjunto de intermediarios que almacenan y gestionan flujos de datos en temas. Los productores publican mensajes en los temas, y los consumidores se suscriben a los temas para recibir mensajes.
SQS es un servicio de mensajería totalmente gestionado proporcionado por AWS. Sigue un modelo basado en colas, en el que los mensajes se envían a una cola, y los consumidores sondean la cola para recibir mensajes.
Kafka proporciona una semántica de entrega "al menos una vez", lo que significa que los mensajes pueden entregarse una o más veces. También admite la entrega "exactamente una vez" mediante el uso de productores idempotentes y escrituras transaccionales.
SQS garantiza la entrega "al menos una vez". Para otros protocolos como HTTP/HTTPS, correo electrónico y SMS, Amazon SNS debe utilizarse junto con SQS.
Kafka mantiene el orden de los mensajes dentro de las particiones, garantizando que los mensajes se entreguen en el orden en que se produjeron.
SQS no garantiza el orden de los mensajes por defecto. Sin embargo, admite temas FIFO, que conservan el orden exacto de los mensajes.
Kafka almacena los mensajes en disco en un registro de confirmación distribuido, proporcionando durabilidad y tolerancia a fallos. Los mensajes pueden retenerse durante un periodo configurable, lo que permite a los consumidores rebobinar y reproducir los mensajes.
SQS no proporciona persistencia de mensajes a largo plazo. Los mensajes se almacenan temporalmente hasta que se entregan a todos los suscriptores o hasta que caducan (según el periodo de retención configurado).
Kafka está diseñado para escalar horizontalmente añadiendo más brokers al cluster. También admite temas de partición para el paralelismo y el equilibrio de carga.
SQS es un servicio totalmente gestionado que escala automáticamente para manejar volúmenes de mensajes crecientes sin necesidad de intervención manual.
Kafka tiene un rico ecosistema de conectores e integraciones con varias fuentes de datos, sumideros y marcos de procesamiento, como Apache Spark, Apache Flink y Apache Kafka Streams.
SQS se integra perfectamente con otros servicios de AWS, lo que te permite enviar notificaciones a varios puntos finales, incluidas las funciones de AWS Lambda, las colas de SQS y los puntos finales HTTP/HTTPS.
Kafka utiliza principalmente herramientas de interfaz de línea de comandos como kafka-topics para gestionar temas y otras tareas administrativas. Carece de una interfaz de usuario integrada dedicada, pero herramientas de terceros como Kafka Manager, Kafka Tool y Confluent Control Center ofrecen interfaces basadas en web para gestionar clusters de Kafka.
SQS, como servicio totalmente gestionado, se integra perfectamente con la consola de administración de AWS. Esta interfaz basada en web permite a los usuarios crear, configurar y supervisar fácilmente las colas SQS sin necesidad de herramientas adicionales.
Kafka ofrece bibliotecas cliente para varios lenguajes, como Java, Python y Go. Su sintaxis puede ser compleja debido a conceptos como temas, particiones, compensaciones y grupos de consumidores.
SQS proporciona SDK para varios lenguajes, como Java, Python y Node.js. Su sintaxis es más sencilla y se centra en enviar y recibir mensajes a y desde colas. La sintaxis de SQS es más sencilla, mientras que la de Kafka es más compleja debido a su naturaleza distribuida y a sus funciones avanzadas.
El precio de Kafka varía en función del modelo de despliegue (servicios autogestionados o gestionados como Confluent Cloud o Amazon MSK).
SQS sigue un modelo de precios de pago por uso basado en el número de peticiones y transferencias de datos.
Tras repasar las similitudes y diferencias, he aquí una comparación detallada entre Apache Kafka y Amazon SQS, centrándonos en cuál es el ganador para cada categoría, según el caso.
Kafka es un sistema de mensajería pub-sub distribuido que funciona con una arquitectura de registro distribuido, en la que los mensajes se conservan en un registro de confirmación distribuido.
Por otro lado, SQS es un sistema de mensajería basado en pull y totalmente gestionado, que se basa en una arquitectura de corredor de mensajes, con un servicio central que orquesta la gestión de colas.
La arquitectura distribuida de Kafka lo hace más escalable y tolerante a fallos, mientras que la arquitectura centralizada de SQS simplifica la gestión, pero puede convertirse en un cuello de botella.
Tanto Kafka como Amazon SQS ofrecen una gran escalabilidad. Kafka es conocido por sus capacidades de streaming de alto rendimiento, tolerante a fallos y escalable horizontalmente. Puede manejar grandes volúmenes de datos y tiene periodos de retención de datos ampliados.
Amazon SQS es célebre por su capacidad para manejar millones de mensajes por segundo y su escalado automático en respuesta al tráfico variable.
Kafka es más escalable para manejar grandes volúmenes de datos y proporcionar periodos de retención más largos, mientras que SQS es más fácil de escalar automáticamente para cargas de trabajo más pequeñas.
Kafka está diseñado para garantizar la persistencia de los datos mediante su sistema de registro replicado. Ofrece flexibilidad al permitir la configuración tanto del periodo de retención como del espacio en disco utilizado para el almacenamiento de datos.
Por otro lado, SQS garantiza la persistencia de los mensajes almacenándolos en varios centros de datos, lo que aumenta la durabilidad del sistema. Viene con un periodo de retención por defecto de 4 días, que puede ajustarse hasta un máximo de 14 días en función de las necesidades del usuario.
Ambas plataformas ofrecen persistencia de mensajes, pero Kafka proporciona más flexibilidad a la hora de configurar los periodos de retención y el almacenamiento.
Tanto Apache Kafka como Amazon SQS ofrecen sólidas capacidades de mensajería con entrega garantizada. Kafka garantiza la entrega de mensajes "al menos una vez" y puede lograr una semántica "exactamente una vez" mediante mecanismos como la escritura idempotente de mensajes y el soporte transaccional.
Por otra parte, SQS también garantiza la entrega de mensajes "al menos una vez" y proporciona una semántica de entrega "exactamente una vez" mediante sus mecanismos de deduplicación.
Ambas plataformas ofrecen garantías similares de entrega de mensajes, aunque Kafka proporciona funciones más avanzadas, como escrituras idempotentes y transacciones.
Una diferencia clave entre Kafka y SQS es cómo gestionan el consumo de mensajes.
Kafka utiliza grupos de consumidores para la lectura independiente desde distintas particiones, lo que permite el equilibrio de carga y la tolerancia a fallos. SQS carece de soporte integrado para grupos de consumidores, por lo que se necesitan colas separadas para cada consumidor para conseguir una funcionalidad similar.
Esto muestra los variados enfoques que adoptan Kafka y SQS para gestionar las interacciones de los consumidores con los mensajes.
La compatibilidad de Kafka con los grupos de consumidores lo hace más adecuado para escenarios que implican múltiples consumidores y equilibrio de carga.
Kafka cuenta con un ecosistema de integración más amplio y ofrece conectores para varios sistemas y marcos de datos. Por otra parte, SQS está estrechamente integrado con otros servicios de AWS, lo que facilita su incorporación a cualquier arquitectura basada en AWS.
SQS es el ganador para las arquitecturas basadas en AWS, mientras que Kafka ofrece más flexibilidad para integrarse con sistemas y marcos no basados en AWS.
Al comparar Kafka y SQS, está claro que responden a necesidades diferentes. Kafka exige un poco más en términos de instalación y configuración, presentando una curva de aprendizaje más pronunciada, sobre todo cuando se profundiza en conceptos de sistemas distribuidos.
Por otro lado, el SQS destaca por su sencillez. Como servicio totalmente gestionado, requiere una instalación y configuración mínimas, lo que lo convierte en una opción más accesible para casos de uso sencillos.
SQS es más fácil de usar y de iniciarse, mientras que Kafka requiere más experiencia en sistemas distribuidos y configuración.
Kafka, una plataforma de código abierto, necesita inversión en infraestructura y gestión, aunque puede ser más rentable para manejar cargas de trabajo a gran escala. Por otro lado, SQS ofrece un servicio totalmente gestionado con un modelo de precios de pago por uso, lo que lo hace potencialmente más económico para cargas de trabajo más pequeñas.
SQS suele ser más rentable para cargas de trabajo pequeñas, mientras que Kafka puede ser más rentable para cargas de trabajo a gran escala, dependiendo de los costes de infraestructura y gestión.
Para entender Kafka, profundiza en los sistemas distribuidos y el procesamiento de flujos. Es rico en conceptos como temas, particiones, compensaciones y grupos de consumidores. Por otro lado, SQS tiene una API fácil de usar, que simplifica el envío y la recepción de mensajes desde colas con SDKs en múltiples lenguajes de programación.
SQS es el ganador en términos de dificultad sintáctica. Ofrece una API más sencilla y fácil de usar, lo que facilita su integración en las aplicaciones. La sintaxis de Kafka puede ser más compleja debido a su naturaleza distribuida y a sus funciones avanzadas de streaming.
|
Kafka |
SQS |
|
Distribuido, pub-sub |
Centralizado, basado en pull |
|
Altamente escalable para grandes volúmenes |
Altamente escalable para pequeños volúmenes |
|
Periodos de retención configurables |
Períodos de conservación limitados |
|
Al menos una vez, exactamente una vez con transacciones |
Al menos una vez, exactamente una vez con deduplicación |
|
Apoyado |
No se admite |
|
Amplio ecosistema, conectores |
Estrecha integración con AWS |
|
Curva de aprendizaje más pronunciada |
Totalmente gestionado, más fácil de poner en marcha |
|
Código abierto, costes de infraestructura |
Pay-as-you-go |
|
Más largo |
14 días |
|
Multiple |
Limitado |
|
Más complejo |
Simple y sencillo |
En conclusión, si necesitas un servicio gestionado de rápida implementación que se integre bien en el ecosistema de AWS, AWS SQS es tu mejor opción. Simplifica la gestión de colas y se escala sin esfuerzo, por lo que es ideal para muchas aplicaciones estándar.
Alternativamente, si tu proyecto exige un alto rendimiento, baja latencia y la posibilidad de ajustar el sistema, Apache Kafka ofrece flexibilidad para el flujo y procesamiento de datos en tiempo real.
Elegir la herramienta adecuada dependerá de las necesidades específicas de tu proyecto, incluyendo factores como la facilidad de uso, el rendimiento, la escalabilidad y la integración. Tanto Kafka como SQS tienen sus puntos fuertes, y comprenderlos te ayudará a aprovechar la mejor plataforma para tu próximo proyecto basado en datos.
Para seguir aprendiendo sobre estos temas, consulta estos recursos:
¡Aprende más sobre la infraestructura y la gestión de los datos de flujo con estos cursos!
Curso
Curso
Curso
blog
Kurtis Pykes
12 min
blog
Gus Frazer
14 min
blog
Adejumo Ridwan Suleiman
13 min
blog
Tim Lu
11 min
Tutorial
Tim Lu
Tutorial
Natassha Selvaraj