
Track
Associate Data Engineer in SQL
30 hr
Processing data in real time gives us great opportunities. If a bank detects a weird purchase with our credit card, they can stop the transaction immediately. Or, if we are searching for a product, product suggestions can pop up as we browse the website. This speed means better decisions, happier customers, and a more efficient business.
Apache Kafka is a high-throughput, distributed data store optimized for collecting, processing, storing, and analyzing streaming data in real time. It allows different applications to publish and subscribe to streams of data, enabling them to communicate and react to events as they happen.
Because it efficiently manages data streams, Kafka has become very popular. It is used in different systems, from online shopping and social media to banking and healthcare.
Apache Kafka has become popular among those data practitioners who face the challenges of handling real-time data streams. We can explain its popularity by several key factors:
Apache Kafka is currently used in applications requiring real-time processing and analyzing data. But what features make it a powerful tool for handling streaming data? Let’s have a look at them:
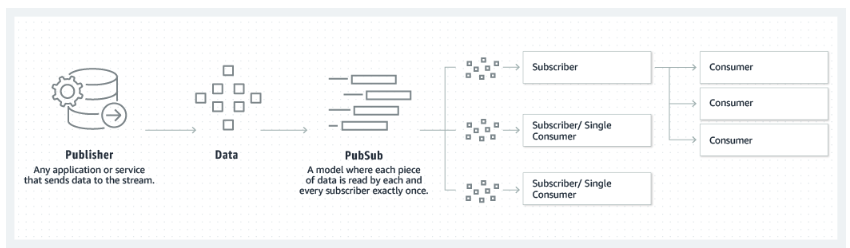
The publisher-subscriber model that Kafka relies on. Source: Amazon
Learning Apache Kafka makes you a valuable candidate for employers and companies that generate and process data at high rates. Apache Kafka, with its powerful features and widespread use, has become a key tool for building modern data architectures and applications.
I’ve mentioned that Kafka has become very popular in recent years. It’s estimated that Apache Kafka is currently used by over 80% of the Fortune 100 companies.
The increasing usage of Kafka across various industries, along with its role in enabling real-time data solutions, makes Kafka skills highly valuable in the job market. According to PayScale and ZipRecruiter, as of November 2024, the average salary of an engineer with Kafka skills in the United States is $100,000 per year.
We’ve already mentioned the strengths of Apache Kafka, but let’s look at a few specific examples of where you can use them:
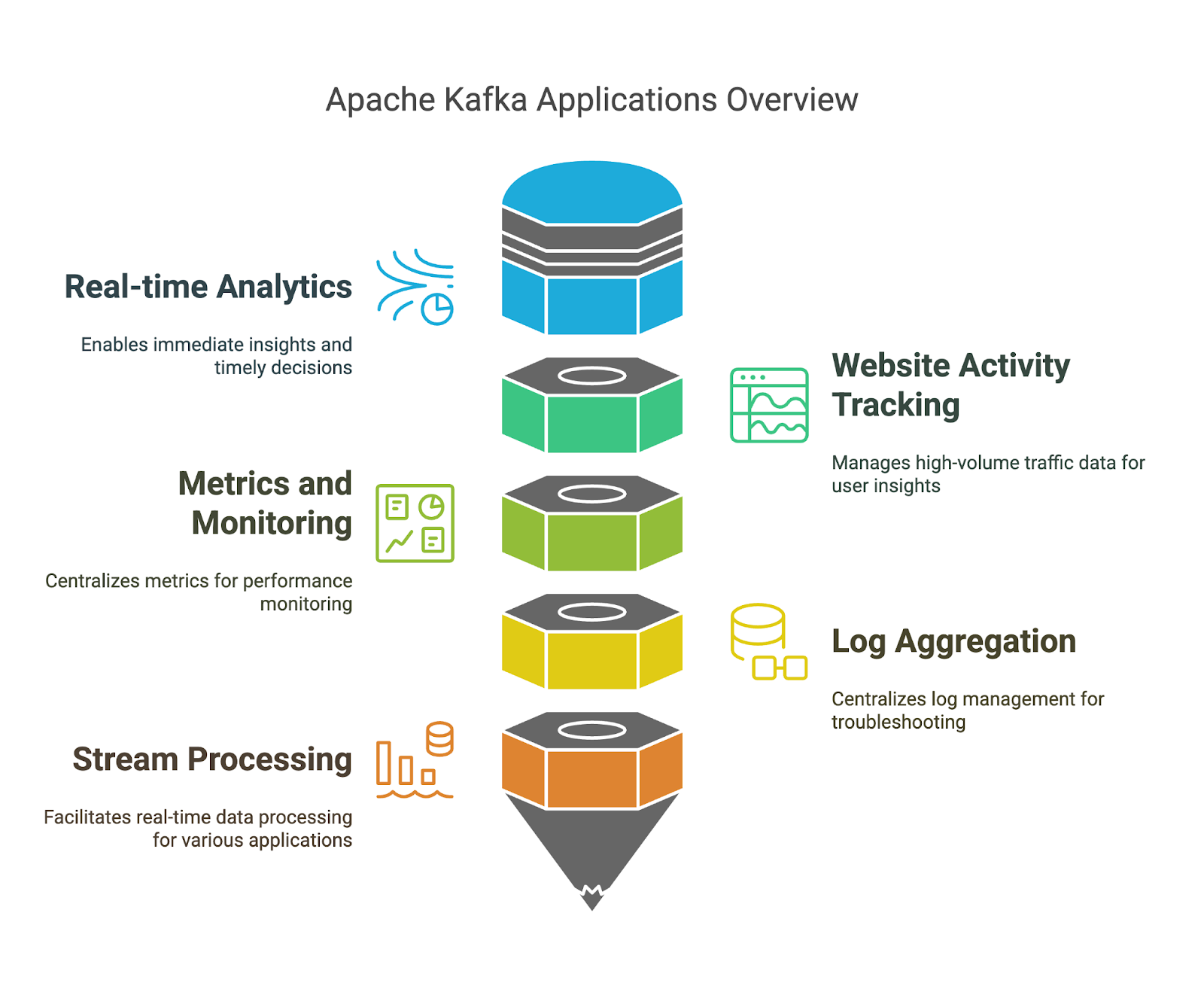
If you learn Apache Kafka methodically, you have more chances of success. Let’s focus on a few principles you can use in your learning journey.
Before you learn technical details, define your motivation for learning Apache Kafka. Ask yourself:
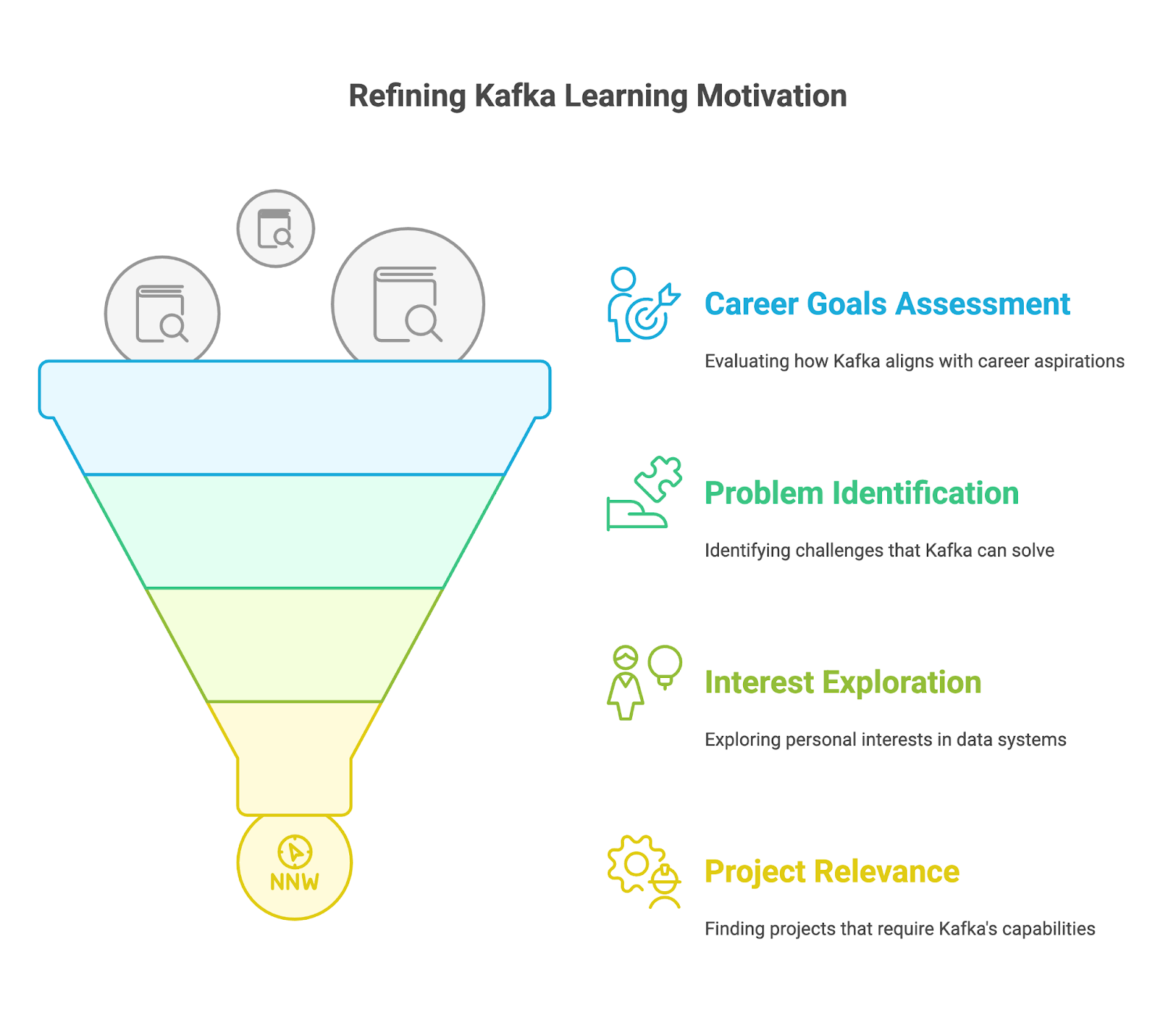
After you identify your goals, master the basics of Kafka and understand how they work.
To learn Apache Kafka, we first need to get it on our local machine. Because Kafka is developed using Java, we should ensure we have Java installed. Then, we need to download the Kafka binaries from the official website and extract them.
We now start ZooKeeper, followed by the Kafka server, using the provided scripts. Finally, we can use the command-line tools to create topics and try producing and consuming some messages to grasp the basics. DataCamp's Apache Kafka for Beginners article can help you get up to speed.
The first concept we should learn is the publisher-subscriber model in Kafka. This is one of the key reasons why Apache Kafka can handle streaming data efficiently. Understand how producers publish messages and consumers subscribe to these topics, receiving only messages relevant to their interests.
DataCamp's Introduction to Apache Kafka course provides an introduction, offering interactive exercises and practical examples.
When describing the publisher-subscriber model, we have mentioned some key Kafka components: Producer and Consumer. However, we should explore all core components. We should learn how Kafka organizes data into topics and partitions, and understand how partitions contribute to scalability and fault tolerance.
We should also understand how brokers form a cluster to provide high availability and fault tolerance.
Check the DataCamp's Introduction to Apache Kafka course as well as the Apache Kafka for Beginners Article to have a clear picture of these topics.
Once you're comfortable with the basics, it's time to explore intermediate Apache Kafka skills.
One of the key features of Apache Kafka is its ability to handle large volumes of streaming data. Kafka Connect is an open-source, free component of Apache Kafka that simplifies data integration between file systems, databases, search indexes, and key-value stores.
Learning how to use Connect can help us unlock efficient data flow for analytics, application integration, and building a robust, scalable data architecture. Check our Apache Kafka for Beginners Article for more details.
Another advanced feature of Kafka is Streams. We should learn how to build stream processing applications directly within Kafka with the help of Streams. It offers APIs and a high-level Domain-Specific Language for handling, converting, and evaluating continuous streams of data. Learn more details on Apache Kafka for Beginners Article.
As with any other technology, it is always good to keep track of its performance. To do that, we should learn how to monitor the health and performance of our Kafka cluster. We can explore tools and techniques for monitoring key metrics, managing topics and partitions, and ensuring optimal performance.
Taking courses about Apache Kafka is an excellent way to get familiar with the technology. However, to get proficient in Kafka, you need to solve challenging and skill-building problems, such as those you’ll face on real-world projects.
You can start by experimenting with simple data streaming tasks, like producing and consuming messages, then gradually increase complexity by exploring topics like partitioning, fault tolerance, and integration with external systems using Kafka Connect.
Here are some ways to practice your skills:
You will complete different projects as you keep moving in your Apache Kafka learning journey. To showcase your Apache Kafka skills and experience to potential employers, you should compile them into a portfolio. This portfolio should reflect your skills and interests and be tailored to the career or industry you're interested in.
Try to make your projects original and showcase your problem-solving skills. Include projects that demonstrate your proficiency in different aspects of Kafka, such as building data pipelines with Kafka Connect, developing streaming applications with Kafka Streams, or working with Kafka clusters. Document your projects thoroughly, providing context, methodology, code, and results. You can use platforms like GitHub to host your code and Confluent Cloud for a managed Kafka environment.
Learning Kafka is a continuous journey. Technology constantly evolves, and new features and applications are being developed regularly. Kafka is not the exception to that.
Once you’ve mastered the fundamentals, you can look for more challenging tasks and projects such as performance tuning for high-throughput systems, and implementing advanced stream processing with Kafka Streams. Focus on your goals and specialize in areas that are relevant to your career goals and interests.
Keep up to date with the new developments, like new features or KIP proposals, and learn how to apply them to your projects. Keep practicing, seek out new challenges and opportunities, and embrace the idea of making mistakes as a way to learn.
Even though each person has their way of learning, it’s always a good idea to have a plan or guide to follow for learning a new tool. I’ve created a potential learning plan outlining where to focus your time and efforts if you’re just starting with Apache Kafka.

I imagine that by now, you are ready to jump into learning Kafka and get your hands on a large dataset to practice your new skill. But before you do, let me highlight these tips that will help you navigate the path to Apache Kafka proficiency.
Kafka is a versatile tool that can be used in many ways. You should identify your specific goals and interests within the Kafka ecosystem. What aspect of Kafka are you most drawn to? Are you interested in data engineering, stream processing, or Kafka administration? A focused approach can help you gain the most relevant aspects and knowledge of Apache Kafka to fulfill your interests.
Consistency is key to mastering any new skill. You should set aside dedicated time to practice Kafka. Just a short amount of time every day will do. You don’t need to tackle complex concepts every day. You can do hands-on exercises, work through tutorials, and experiment with different Kafka features. The more you practice, the more comfortable you'll become with the platform.
This is one of the key tips, and you will read it several times in this guide. Practicing exercises is great for gaining confidence. However, applying your Kafka skills to real-world projects is what will make you excel at it.
Start with simple projects and questions and gradually take on more complex ones. This could involve setting up a simple producer-consumer application, then advancing to building a real-time data pipeline with Kafka Connect, or even designing a fault-tolerant streaming application with Kafka Streams. The key is to continuously challenge yourself and expand your practical Kafka skills.
Learning is often more effective when done collaboratively. Sharing your experiences and learning from others can accelerate your progress and provide valuable insights.
To exchange knowledge, ideas, and questions, you can join some groups related to Apache Kafka, and attend meet-ups and conferences. you can join online communities like the Confluent Slack channel or Confluent Forum where you can interact with other Kafka enthusiasts. You can also join virtual or in-person meet-ups, featuring talks by Kafka experts, or conferences, such as ApacheCon.
As with any other technology, learning Apache Kafka is an iterative process. Learning from your mistakes is an essential part of this process. Don't be afraid to experiment, try different approaches, and learn from your errors.
Try different configurations for your Kafka producers and consumers, explore various data serialization methods (JSON, Avro, Protobuf), and experiment with different partitioning strategies. Push your Kafka cluster to its limits with high message volumes, and observe how it handles the load. Analyze consumer lag, fine-tune configurations, and understand how your optimizations impact performance.
Take your time to truly grasp core concepts like topics, partitions, consumer groups, and the role of ZooKeeper. If you build now a solid foundation, it will be easier for you to understand more advanced topics and troubleshoot issues effectively. Break down the learning process into smaller steps, and allow yourself time to understand the information. A slow and steady approach often leads to deeper understanding and mastery.
Let’s cover a few efficient methods of learning Apache Kafka.
Online courses offer an excellent way to learn Apache Kafka at your speed. DataCamp offers a Kafka intermediate course. This course covers core concepts of Kafka, including the publisher-subscriber model, topics and partitions, brokers and clusters, producers, and consumers.
Tutorials are another great way to learn Apache Kafka, especially if you are new to the technology. They contain step-by-step instructions on how to perform specific tasks or understand certain concepts. For a start, consider these tutorials:
To have a deeper knowledge of the advantages of Apache Kafka, you should also understand what are the key similarities and differences with other technologies. You can read articles on how Kafka compares with other tools such as the following:
Books are an excellent resource for learning Apache Kafka. They offer in-depth knowledge and insights from experts alongside code snippets and explanations. Here are some of the most popular books on Kafka:
Because the adoption of Apache Kafka continues to grow, so do the career opportunities for professionals with Kafka skills, from specific Kafka engineers to software engineers. If you are evaluating the fit of your Kafka skills, consider these roles:

As a Kafka engineer, you are responsible for designing, building, and maintaining Kafka-based data streaming solutions with high availability and scalability. You will need to ensure the reliable and efficient flow of data within the company, as well as, monitor and optimize Kafka performance to ensure optimal throughput and latency.
As a data engineer, you are the architect of data infrastructure, responsible for designing and building the systems that handle a company’s data. Kafka often plays an important role in these data pipelines, enabling efficient and scalable real-time data streaming between different systems. You will need to ensure that Kafka integrates seamlessly with other components.
As a software engineer, you will use Kafka to build real-time applications like chat platforms and online games. You will need to integrate it into the application code to ensure smooth data flow by connecting with various messaging systems and APIs. You will also optimize these applications for scalability and performance, allowing them to handle large amounts of real-time data.
|
Role |
What you do |
Your key skills |
Tools you use |
|
Kafka Engineer |
Design and implement Kafka clusters for high availability and scalability. |
Kafka architecture, components, administration and configuration, stream processing concepts. |
Apache Kafka, Kafka Connect, Kafka Streams, ZooKeeper |
|
Data Engineer |
Design and implement data warehouses and data lakes, integrate Kafka with other data processing and storage systems |
Proficiency in data processing tools, experience with cloud platforms, and knowledge of Kafka. |
Apache Kafka, Apache Spark, Hadoop, Hive, Cloud platforms |
|
Software Engineer |
Design and develop applications that leverage Kafka for real-time data communication. |
Programming skills, distributed systems and applications, Kafka publisher-subscriber knowledge. |
Apache Kafka, Java, Python, Scala, RabbitMQ, ActiveMQ, Development tools and frameworks. |
While having a degree can be very valuable when pursuing a career in a data-related role that uses Apache Kafka, it's not the only path to succeed. More and more people from diverse backgrounds and with different experiences are starting to work in data-related roles. With dedication, consistent learning, and a proactive approach, you can land your dream job that uses Apache Kafka.
Stay updated with the latest developments in Kafka. Follow influential professionals who are involved with Apache Kafka on social media, read Apache Kafka-related blogs, and listen to Kafka-related podcasts.
Engage with influential figures, such as Neha Narkhede, who co-created Kafka and is also the CTO of Confluent. You'll gain insights into trending topics, emerging technologies, and the future direction of Apache Kafka. You can also read the Confluent blog, which offers in-depth articles and tutorials on a wide range of Kafka topics, from architecture and administration to use cases and best practices.
You should also check out industry events, such as webinars at Confluent or the annual Kafka Summit.
You need to stand out from other candidates. One good way to do it is to build a strong portfolio that showcases your skills and completed projects.
Your portfolio should contain projects that demonstrate your proficiency in building data pipelines, implementing stream processing applications, and integrating Kafka with other systems.
Hiring managers have to review hundreds of resumes and distinguish great candidates. Also, many times, your resume is passed through Applicant Tracking Systems (ATS), automated software systems used by many companies to review resumes and discard those that don't meet specific criteria. So, you should build a great resume and craft an impressive cover letter to impress both ATS and your recruiters.
Get Noticed by a hiring manager
If you get noticed by the hiring manager or your effective resume goes through the selection process, you should next prepare for a technical interview. To be ready, you can check this article on 20 Kafka Interview Questions for Data Engineers.
Learning Apache Kafka can open doors for better opportunities and career outcomes. The path to learning Kafka is rewarding but requires consistency and hands-on practice. Experimenting and solving challenges using this tool can accelerate your learning process and provide you with real-world examples to showcase your practical skills when you are looking for jobs.
Learn data engineering with these courses!
Track
Course
Course
blog
Maria Eugenia Inzaugarat
15 min
blog
Adel Nehme
15 min
blog
Maria Eugenia Inzaugarat
8 min
blog
Thalia Barrera
15 min
Tutorial
Kurtis Pykes
Tutorial
Derrick Mwiti

