
Lernpfad
Associate Data Engineer in SQL
30 Std.
Daten in Echtzeit zu verarbeiten, gibt uns echt tolle Möglichkeiten. Wenn eine Bank einen komischen Kauf mit unserer Kreditkarte merkt, kann sie die Transaktionsofort stoppen . Oder wenn wir nach einem Produkt suchen, können beim Surfen auf der Website Produktvorschläge eingeblendet werden. Diese Geschwindigkeit sorgt für bessere Entscheidungen, zufriedenere Kunden und ein effizienteres Geschäft.
Apache Kafka ist ein verteilter Datenspeicher mit hohem Durchsatz, der für das Sammeln, Verarbeiten, Speichern und Analysieren von Streaming-Daten in Echtzeit optimiert ist. Es lässt verschiedene Anwendungen Datenströme veröffentlichen und abonnieren, sodass sie miteinander reden und auf Ereignisse reagieren können, sobald sie passieren.
Weil Kafka Datenströme so gut im Griff hat, ist es echt beliebt geworden. Es wird in verschiedenen Systemen genutzt, vom Online-Shopping und sozialen Medien bis hin zum Bankwesen und Gesundheitswesen.
Apache Kafka ist bei Leuten, die mit Daten arbeiten und mit Echtzeit-Datenströmen zu kämpfen haben, echt beliebt geworden. Wir können seine Beliebtheit mit ein paar wichtigen Sachen erklären:
Apache Kafka wird gerade in Anwendungen genutzt, die Daten in Echtzeit verarbeiten und analysieren müssen. Aber welche Funktionen machen es zu einem starken Tool für den Umgang mit Streaming-Daten? Schauen wir sie uns mal an:
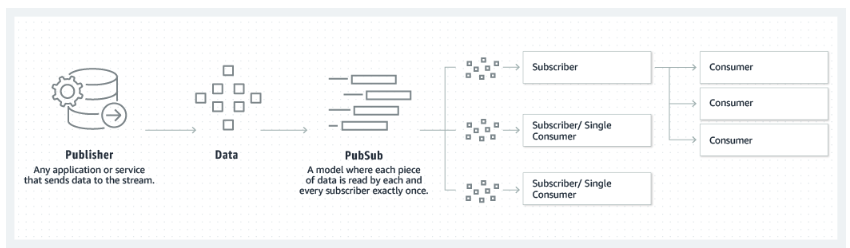
Das Publisher-Subscriber-Modell, auf das Kafka setzt. Quelle: Amazon
Wenn du Apache Kafka lernst, wirst du zu einem super Kandidaten für Arbeitgeber und Firmen, die viele Daten erzeugen und verarbeiten. Apache Kafka ist mit seinen coolen Funktionen und seiner weit verbreiteten Nutzung zu einem wichtigen Tool für den Aufbau moderne Datenarchitekturen und Anwendungen.
Ich hab schon mal gesagt, dass Kafka in den letzten Jahren echt beliebt geworden ist. Es wird geschätzt, dass Apache Kafka derzeit von über 80 % der Fortune-100-Unternehmen Unternehmen
Kafka wird in vielen Branchen immer beliebter und ist super wichtig für Echtzeit-Datenlösungen. Deshalb sind Leute, die sich mit Kafka auskennen, auf dem Arbeitsmarkt echt gefragt. Laut PayScale und ZipRecruiterbeträgt das durchschnittliche Jahresgehalt eines Ingenieurs mit Kafka-Kenntnissen in den USA im November 2024 100.000 US-Dollar.
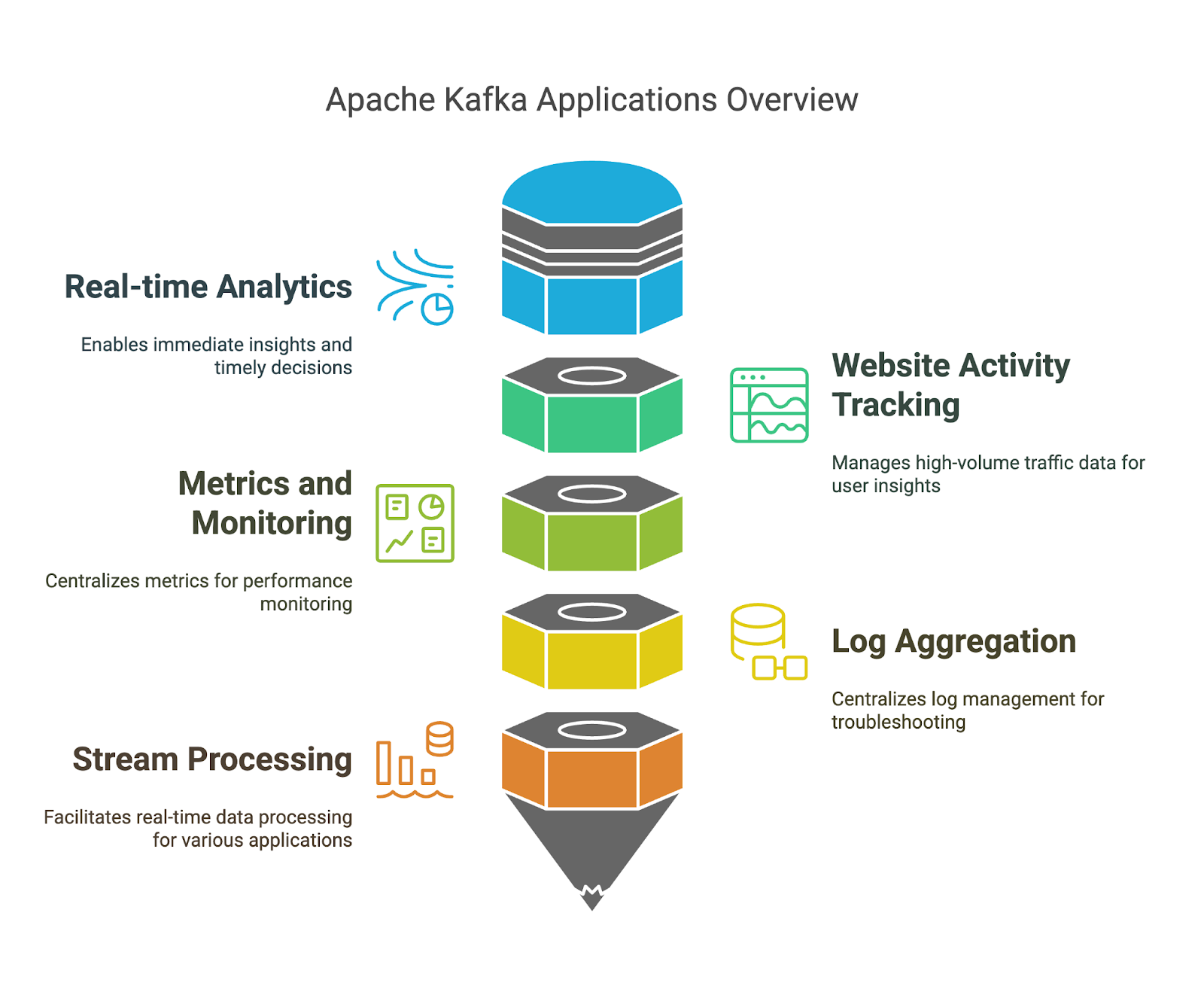
Wir haben schon die Vorteile von Apache Kafka angesprochen, aber schauen wir uns mal ein paar konkrete Beispiele an, wo du sie nutzen kannst:
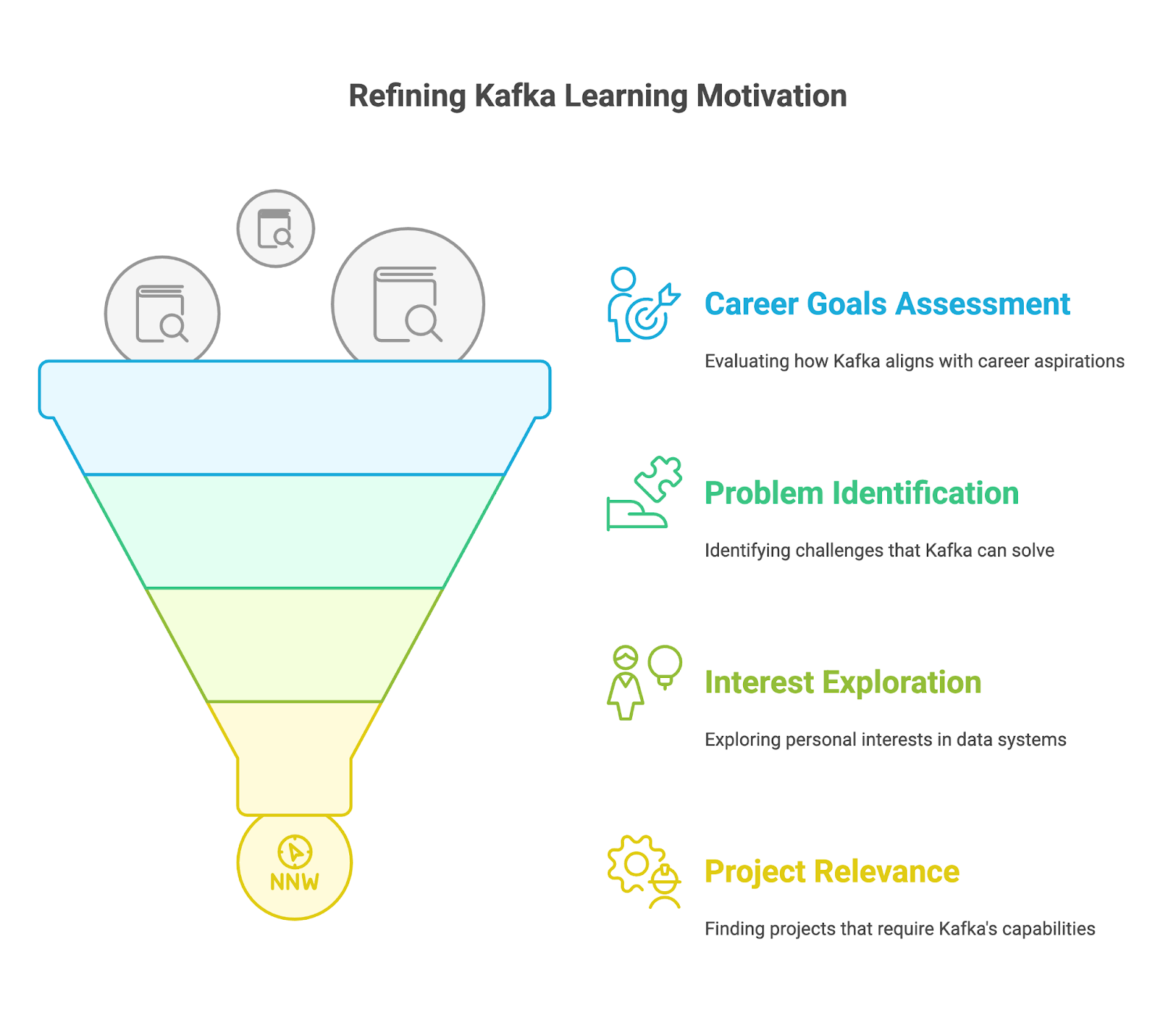
Wenn du Apache Kafka systematisch lernst, hast du bessere Chancen auf Erfolg. Schauen wir uns ein paar Prinzipien an, die du auf deinem Lernweg nutzen kannst.
Bevor du dich mit den technischen Details beschäftigst, überleg dir, warum du Apache Kafka lernen willst. Frag dich mal:
Nachdem du deine Ziele festgelegt hast, lerne die Grundlagen von Kafka und wie sie funktionieren.
Um Apache Kafka zu lernen, müssen wir es erst mal auf unseren Rechner laden. Weil Kafka mit Javaentwickelt wurde, sollten wir sicherstellen, dass Java installiert ist. Dann müssen wir die Kafka-Binärdateien von der offiziellen Website herunterladen und entpacken.
Jetzt starten wir ZooKeeper und dann den Kafka-Server mit den bereitgestellten Skripten. Zum Schluss können wir die Befehlszeilentools nutzen, um Themen zu erstellen und versuchen, ein paar Nachrichten zu produzieren und zu konsumieren, um die Grundlagen zu verstehen. DataCamp's Artikel „Apache Kafka für Anfänger” kann dir helfen, dich schnell zurechtzufinden.
Das erste Konzept, das wir uns merken sollten, ist das Publisher-Subscriber-Modell in Kafka. Das ist einer der Hauptgründe, warum Apache Kafka Streaming-Daten so gut verarbeiten kann. Verstehe, wie Produzenten Nachrichten veröffentlichen und Konsumenten diese Themen abonnieren, sodass sie nur Nachrichten bekommen, die für ihre Interessen relevant sind.
DataCamps Einführung in Apache Kafka bietet eine Einführung mit interaktiven Übungen und praktischen Beispielen.
Bei der Beschreibung des Publisher-Subscriber-Modells haben wir ein paar wichtige Kafka-Komponenten erwähnt: Produzent und Verbraucher. Wir sollten aber alle Kernkomponenten anschauen. Wir sollten uns damit beschäftigen, wie Kafka Daten in Themen und Partitionen organisiert, und verstehen, wie Partitionen zur Skalierbarkeit und Fehlertoleranz beitragen.
Wir sollten auch wissen, wie Broker einen Cluster bilden, um hohe Verfügbarkeit und Fehlertoleranz zu bieten.
Schau dir die Einführung in Apache Kafka von DataCamp an Einführung in Apache Kafka sowie den Artikel Artikel „Apache Kafka für Anfänger” an, um dir ein klares Bild von diesen Themen zu machen.
Sobald du dich mit den Grundlagen vertraut gemacht hast, kannst du dich mit den fortgeschrittenen Apache Kafka-Fähigkeiten beschäftigen.
Eines der wichtigsten Features von Apache Kafka ist, dass es riesige Mengen an Streaming-Daten verarbeiten kann. Kafka Connect ist eine kostenlose Open-Source-Komponente von Apache Kafka, die die Datenintegration zwischen Dateisystemen, Datenbanken, Suchindizes und Schlüsselwertspeichern einfacher macht.
Wenn wir Connect richtig nutzen, können wir einen effizienten Datenfluss für Analysen, die Integration von Anwendungen und den Aufbau einer robusten, skalierbaren Datenarchitektur schaffen. Schau dir unseren Artikel „Apache Kafka für Anfänger” für mehr Infos.
Eine weitere coole Funktion von Kafka sind Streams. Wir sollten lernen, wie man mit Streams direkt in Kafka Stream-Verarbeitungsanwendungen erstellt. Es bietet APIs und eine hochentwickelte domänenspezifische Sprache zum Verarbeiten, Konvertieren und Auswerten von kontinuierlichen Datenströmen. Mehr Infos findest du unter Artikel „Apache Kafka für Anfänger“.
Wie bei jeder anderen Technologie ist es immer gut, ihre Leistung im Auge zu behalten. Dafür sollten wir lernen, wie wir den Zustand und die Leistung unseres Kafka-Clusters im Auge behalten können. Wir können Tools und Techniken anschauen, um wichtige Kennzahlen zu überwachen, Themen und Partitionen zu verwalten und eine optimale Leistung sicherzustellen.
Kurse über Apache Kafka sind super, um sich mit der Technologie vertraut zu machen. Um Kafka richtig gut zu beherrschen, musst du aber knifflige Probleme lösen, die deine Fähigkeiten verbessern, so wie du sie auch in echten Projekten findest.
Du kannst mit einfachen Daten-Streaming-Aufgaben anfangen, wie zum Beispiel dem Erstellen und Verwenden von Nachrichten, und dann nach und nach die Komplexität erhöhen, indem du Themen wie Partitionierung, Fehlertoleranz und die Integration mit externen Systemen mithilfe von Kafka Connect erkundest.
Hier sind ein paar Möglichkeiten, deine Fähigkeiten zu trainieren:
Während du dich weiter mit Apache Kafka beschäftigst, wirst du verschiedene Projekte machen. Um potenziellen Arbeitgebern deine Apache Kafka-Kenntnisse und -Erfahrungen zu zeigen, solltest du sie in einem Portfolio zusammenfassen. Dieses Portfolio sollte deine Fähigkeiten und Interessen zeigen und auf den Job oder die Branche zugeschnitten sein, die dich interessieren.
Mach deine Projekte originell und zeig, wie gut du Probleme lösen kannst. Zeig Projekte, die zeigen, wie gut du dich mit verschiedenen Aspekten von Kafka auskennst, wie zum Beispiel beim Aufbau von Datenpipelines mit Kafka Connect, bei der Entwicklung von Streaming-Anwendungen mit Kafka Streams oder bei der Arbeit mit Kafka-Clustern. Dokumentiere deine Projekte gründlich und gib dabei den Kontext, die Methodik, den Code und die Ergebnisse an. Du kannst Plattformen wie GitHub nutzen, um deinen Code zu hosten, und Confluent Cloud für eine verwaltete Kafka-Umgebung.
Kafka zu lernen ist ein ständiger Prozess. Die Technik entwickelt sich ständig weiter, und es kommen immer wieder neue Funktionen und Anwendungen dazu. Kafka ist da keine Ausnahme.
Sobald du die Grundlagen drauf hast, kannst du dich an anspruchsvollere Aufgaben und Projekte wagen, wie zum Beispiel die Leistungsoptimierung für Systeme mit hohem Durchsatz und die Implementierung von fortgeschrittener Stream-Verarbeitung mit Kafka Streams. Konzentrier dich auf deine Ziele und spezialisier dich auf Bereiche, die für deine Karrierepläne und Interessen wichtig sind.
Bleib auf dem Laufenden über die neuesten Entwicklungen, wie neue Funktionen oder KIP-Vorschläge, und lerne, wie du sie in deinen Projekten anwenden kannst. Mach weiter so, such dir neue Herausforderungen und Chancen und sieh Fehler als Chance, um was Neues zu lernen.
Auch wenn jeder Mensch seine eigene Art zu lernen hat, ist es immer gut, einen Plan oder Leitfaden zu haben, an dem man sich beim Erlernen eines neuen Tools orientieren kann. Ich hab einen möglichen Lernplan zusammengestellt, der zeigt, wo du deine Zeit und Mühe reinlegen solltest, wenn du gerade erst mit Apache Kafka anfängst.

Ich denke, du bist jetzt bereit, dich mit Kafka zu beschäftigen und einen großen Datensatz zu nehmen, um deine neuen Fähigkeiten auszuprobieren. Bevor du das machst, will ich dir aber noch ein paar Tipps geben, die dir helfen werden, Apache Kafka richtig gut zu verstehen.
Kafka ist ein echt vielseitiges Tool, das man auf viele Arten nutzen kann. Du solltest deine spezifischen Ziele und Interessen innerhalb des Kafka-Ökosystems identifizieren. Welcher Aspekt von Kafka reizt dich am meisten? Interessierst du dich für Data Engineering, Stream Processing oder Kafka-Administration? Ein fokussierter Ansatz kann dir helfen, die wichtigsten Aspekte und Kenntnisse von Apache Kafka zu erlernen, um deine Interessen zu verwirklichen.
Um eine neue Fähigkeit richtig zu lernen, ist es wichtig, dranzubleiben. Du solltest dir Zeit nehmen, um Kafka zu üben. Ein bisschen Zeit jeden Tag reicht schon. Du musst dich nicht jeden Tag mit komplizierten Sachen rumschlagen. Du kannst praktische Übungen machen, Tutorials durcharbeiten und mit verschiedenen Kafka-Funktionen experimentieren. Je mehr du übst, desto besser wirst du mit der Plattform klarkommen.
Das ist einer der wichtigsten Tipps, und du wirst ihn in diesem Leitfaden mehrmals lesen. Übungen zu machen ist super, um Selbstvertrauen zu gewinnen. Aber erst wenn du deine Kafka-Kenntnisse in echten Projekten anwendest, wirst du richtig gut darin.
Fang mit einfachen Projekten und Fragen an und mach dich dann nach und nach an komplexere Sachen ran. Dazu könnte man eine einfache Produzent-Konsument-App aufsetzen, dann eine Echtzeit-Datenpipeline mit Kafka Connect bauen oder sogar eine fehlertolerante Streaming-App mit Kafka Streams entwickeln. Der Schlüssel ist, sich ständig selbst herauszufordern und seine praktischen Kafka-Kenntnisse zu erweitern.
Gemeinsam lernt man oft besser. Wenn du deine Erfahrungen teilst und von anderen lernst, kannst du schneller vorankommen und wertvolle Einblicke gewinnen.
Um Wissen, Ideen und Fragen auszutauschen, kannst du Gruppen beitreten, die sich mit Apache Kafka beschäftigen, und an Treffen und Konferenzen teilnehmen. Du kannst Online-Communities wie dem Confluent Slack-Kanal oder dem Confluent Forum treten, wo du dich mit anderen Kafka-Fans austauschen kannst. Du kannst auch an virtuellen oder persönlichen Treffenteilnehmen, bei denen Kafka-Experten Vorträge halten, oder Konferenzen wie die ApacheCon.
Wie bei jeder anderen Technologie ist auch das Lernen von Apache Kafka ein schrittweiser Prozess. Aus Fehlern zu lernen ist ein wichtiger Teil dieses Prozesses. Hab keine Angst davor, zu experimentieren, verschiedene Ansätze auszuprobieren und aus deinen Fehlern zu lernen.
Probier verschiedene Konfigurationen für deine Kafka-Produzenten und -Konsumenten aus, schau dir verschiedene Daten-Serialisierungsmethoden an (JSON, Avro, Protobuf) und probier verschiedene Partitionierungsstrategien aus. Bring deinen Kafka-Cluster mit vielen Nachrichten an seine Grenzen und schau dir an, wie er mit der Last klarkommt. Analysiere Verzögerungen bei den Verbrauchern, passe die Konfigurationen an und finde raus, wie sich deine Optimierungen auf die Leistung auswirken.
Nimm dir Zeit, um wichtige Sachen wie Themen, Partitionen, Verbrauchergruppen und die Rolle von ZooKeeper richtig zu verstehen. Wenn du jetzt eine solide Grundlage schaffst, wird es dir leichter fallen, fortgeschrittenere Themen zu verstehen und Probleme effektiv zu lösen. Teile den Lernprozess in kleinere Schritte auf und nimm dir Zeit, um die Infos zu verstehen. Ein langsamer und stetiger Ansatz führt oft zu einem tieferen Verständnis und einer besseren Beherrschung der Materie.
Schauen wir uns mal ein paar coole Methoden an, um Apache Kafka zu lernen.
Online-Kurse sind super, um Apache Kafka in deinem eigenen Tempo zu lernen. DataCamp bietet einen Kafka-Kurs für Fortgeschrittenean. Dieser Kurs behandelt die wichtigsten Konzepte von Kafka, darunter das Publisher-Subscriber-Modell, Themen und Partitionen, Broker und Cluster, Produzenten und Konsumenten.
Tutorials sind auch super, um Apache Kafka zu lernen, vor allem wenn du noch keine Erfahrung mit der Technologie hast. Sie haben Schritt-für-Schritt-Anleitungen, wie man bestimmte Aufgaben macht oder bestimmte Konzepte versteht. Schau dir mal diese Tutorials an:
Um die Vorteile von Apache Kafka besser zu verstehen, solltest du auch wissen, was die wichtigsten Gemeinsamkeiten und Unterschiede zu anderen Technologien sind. Du kannst Artikel darüber lesen, wie Kafka im Vergleich zu anderen Tools abschneidet, zum Beispiel die folgenden:
Bücher sind echt super, um Apache Kafka zu lernen. Sie bieten fundiertes Wissen und Einblicke von Experten sowie Code-Schnipsel und Erklärungen. Hier sind ein paar der beliebtesten Bücher über Kafka:
Da Apache Kafka immer beliebter wird, gibt's auch immer mehr Jobchancen für Leute mit Kafka-Kenntnissen, von speziellen Kafka-Ingenieuren bis hin zu Softwareentwicklern. Wenn du deine Kafka-Kenntnisse checken willst, schau dir mal diese Rollen an:

Als Kafka-Ingenieur bist du dafür zuständig, Kafka-basierte Daten-Streaming-Lösungen mit hoher Verfügbarkeit und Skalierbarkeit zu entwerfen, zu entwickeln und zu warten. Du musst dafür sorgen, dass die Daten innerhalb des Unternehmens zuverlässig und effizient fließen, und außerdem die Kafka-Leistung im Auge behalten und optimieren, um einen optimalen Durchsatz und eine optimale Latenz zu erreichen.
Als Dateningenieur bist du der Architekt der Dateninfrastruktur und dafür zuständig, die Systeme zu entwerfen und aufzubauen, die die Daten eines Unternehmens verarbeiten. Kafka ist oft ein wichtiger Teil dieser Datenpipelines und sorgt für effizientes und skalierbares Echtzeit-Daten-Streaming zwischen verschiedenen Systemen. Du musst dafür sorgen, dass Kafka nahtlos mit anderen Komponenten zusammenarbeitet.
Als Softwareentwickler wirst du Kafka nutzen, um Echtzeit-Apps wie Chat-Plattformen und Online-Spiele zu entwickeln. Du musst es in den Anwendungscode einbauen, um einen reibungslosen Datenfluss zu gewährleisten, indem du es mit verschiedenen Messaging-Systemen und APIs verbindest. Du wirst diese Anwendungen auch für Skalierbarkeit und Leistung optimieren, damit sie große Mengen an Echtzeitdaten verarbeiten können.
|
Rolle |
Was du machst |
Deine wichtigsten Fähigkeiten |
Die Tools, die du benutzt |
|
Kafka Engineer |
Entwickle und setz Kafka-Cluster für hohe Verfügbarkeit und Skalierbarkeit ein. |
Kafka-Architektur, Komponenten, Verwaltung und Konfiguration, Konzepte der Stream-Verarbeitung. |
Apache Kafka, Kafka Connect, Kafka Streams, ZooKeeper |
|
Dateningenieur |
Entwerfen und setz Data Warehouses und Data Lakes auf, verbinde Kafka mit anderen Datenverarbeitungs- und Speichersystemen. |
Du solltest gut mit Datenverarbeitungs-Tools klarkommen, Erfahrung mit Cloud-Plattformen haben und dich mit Kafka auskennen. |
Apache Kafka, Apache Spark, Hadoop, Bienenstock, Cloud-Plattformen |
|
Softwareentwickler |
Entwickle Apps, die Kafka für Echtzeit-Datenkommunikation nutzen. |
Programmierkenntnisse, verteilte Systeme und Anwendungen, Kafka Publisher-Subscriber-Kenntnisse. |
Apache Kafka, Java, Python, Scala, RabbitMQ, ActiveMQ, Entwicklungswerkzeuge und Frameworks. |
Ein Abschluss kann zwar echt hilfreich sein, wenn du eine Karriere in einem datenbezogenen Job anstrebst, bei dem Apache Kafka zum Einsatz kommt, aber es ist nicht der einzige Weg zum Erfolg. Immer mehr Leute mit unterschiedlichen Hintergründen und Erfahrungen fangen an, in Jobs rund um Daten zu arbeiten. Mit Engagement, kontinuierlichem Lernen und einer proaktiven Herangehensweise kannst du deinen Traumjob finden, bei dem Apache Kafka zum Einsatz kommt.
Bleib auf dem Laufenden über die neuesten Entwicklungen bei Kafka. Folge einflussreichen Profis, die sich mit Apache Kafka beschäftigen, auf Social Media, lies Blogs über Apache Kafka und hör dir Podcasts zu diesem Thema an.
Tausch dich mit einflussreichen Leuten aus, wie zum Beispiel Neha Narkhede, die Kafka mitentwickelt hat und auch CTO von Confluent ist. Du bekommst Einblicke in aktuelle Themen, neue Technologien und die Zukunftspläne von Apache Kafka. Du kannst auch lesen den Confluent-Blog lesen, der ausführliche Artikel und Tutorials zu einer Vielzahl von Kafka-Themen bietet, von Architektur und Verwaltung bis hin zu Anwendungsfällen und Best Practices.
Du solltest dir auch Branchenveranstaltungen wie Webinare unter Confluent oder dem jährlichen Kafka Summit.
Du musst dich von den anderen Bewerbern abheben. Eine gute Möglichkeit dafür ist, ein starkes Portfolio aufzubauen, das deine Fähigkeiten und abgeschlossenen Projekte zeigt.
Dein Portfolio sollte Projekte zeigen, die deine Fähigkeiten beim Aufbau von Datenpipelines, der Implementierung von Stream-Processing-Anwendungen und der Integration von Kafka in andere Systeme unter Beweis stellen.
Personalchefs müssen echt viele Lebensläufe durchgehen und die besten Kandidaten raussuchen. Außerdem wird dein Lebenslauf oft durch Bewerbermanagementsysteme (ATS) geschleust. Das sind automatisierte Softwaresysteme, die viele Firmen nutzen, um Lebensläufe zu checken und die, die bestimmte Kriterien nicht erfüllen, auszusortieren. Also, du solltest einen tollen Lebenslauf erstellen und ein beeindruckendes Anschreiben, um sowohl das ATS als auch deine Personalvermittler zu beeindrucken.
Mach dich bei einem Personalchef bemerkbar
Wenn du dem Personalchef auffällst oder dein guter Lebenslauf den Auswahlprozess übersteht, solltest du dich als Nächstes auf ein Fachgespräch vorbereiten. Um dich vorzubereiten, kannst du diesen Artikel lesen: 20 Kafka-Interviewfragen für Dateningenieure.
Das Lernen von Apache Kafka kann dir neue Möglichkeiten und bessere Karrierechancen bieten. Der Weg zum Erlernen von Kafka ist lohnenswert, erfordert aber Ausdauer und praktische Übung. Das Ausprobieren und Lösen von Aufgaben mit diesem Tool kann dir beim Lernen helfen und dir Beispiele aus der Praxis liefern, mit denen du deine praktischen Fähigkeiten bei der Jobsuche zeigen kannst.
Lerne mit diesen Kursen alles über Data Engineering!
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Laiba Siddiqui

