
Cursus
Ingénieur de données associé en SQL
30 h
Le traitement des données en temps réel nous offre de grandes opportunités. Si une banque détecte une transaction inhabituelle effectuée avec notre carte de crédit, elle peutimmédiatement bloquer la transaction . Ou, si nous recherchons un produit, des suggestions de produits peuvent apparaître lorsque nous parcourons le site Web. Cette rapidité se traduit par de meilleures décisions, des clients plus satisfaits et une entreprise plus efficace.
Apache Kafka est un magasin de données distribué à haut débit optimisé pour la collecte, le traitement, le stockage et l'analyse en temps réel de données en continu. Il permet à différentes applications de publier et de s'abonner à des flux de données, leur permettant ainsi de communiquer et de réagir aux événements au fur et à mesure qu'ils se produisent.
Grâce à sa gestion efficace des flux de données, Kafka a acquis une grande popularité. Il est utilisé dans divers systèmes, allant du commerce en ligne et des réseaux sociaux aux services bancaires et aux soins de santé.
Apache Kafka est devenu populaire parmi les professionnels des données qui sont confrontés aux défis liés au traitement des flux de données en temps réel. Nous pouvons expliquer sa popularité par plusieurs facteurs clés :
Apache Kafka est actuellement utilisé dans des applications nécessitant le traitement et l'analyse de données en temps réel. Quelles sont les fonctionnalités qui en font un outil performant pour la gestion des données en continu ? Examinons-les :
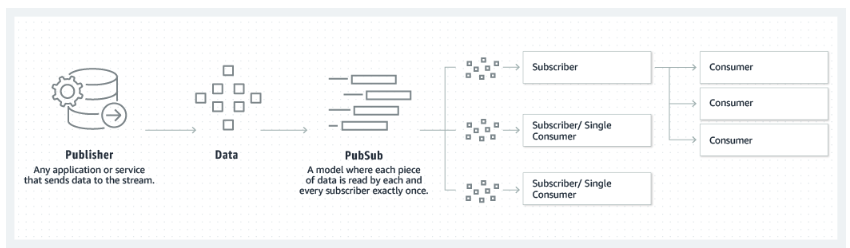
Le modèle éditeur-abonné sur lequel s'appuie Kafka. Source : Amazon
L'apprentissage d'Apache Kafka vous positionne comme un candidat de choix pour les employeurs et les entreprises qui génèrent et traitent des données à un rythme soutenu. Apache Kafka, grâce à ses fonctionnalités puissantes et son utilisation répandue, est devenu un outil essentiel pour la création d'architectures de données modernes. des architectures de données et d'applications.
J'ai mentionné que Kafka est devenu très populaire ces dernières années. On estime qu'Apache Kafka est actuellement utilisé par plus de 80 % des entreprises du classement Fortune 100.
L'utilisation croissante de Kafka dans divers secteurs, ainsi que son rôle dans la mise en place de solutions de données en temps réel, rendent les compétences Kafka très recherchées sur le marché du travail. Selon PayScale et ZipRecruiter, en novembre 2024, le salaire moyen d'un ingénieur possédant des compétences en Kafka aux États-Unis était de 100 000 dollars par an.
Nous avons déjà évoqué les points forts d'Apache Kafka, mais examinons quelques exemples concrets d'utilisation :
En apprenant Apache Kafka de manière méthodique, vous augmentez vos chances de réussite. Concentrons-nous sur quelques principes que vous pouvez appliquer dans votre parcours d'apprentissage.
Avant d'aborder les détails techniques, veuillez définir votre motivation pour apprendre Apache Kafka. Veuillez vous poser la question suivante :
Une fois vos objectifs définis, veuillez acquérir les bases de Kafka et comprendre son fonctionnement.
Pour apprendre Apache Kafka, il est nécessaire de l'installer sur notre ordinateur local. Étant donné que Kafka est développé à l'aide de Java, il est important de s'assurer que Java est correctement installé. Ensuite, il est nécessaire de télécharger les binaires Kafka depuis le site officiel et de les extraire.
Nous allons maintenant démarrer ZooKeeper, puis le serveur Kafka, à l'aide des scripts fournis. Enfin, nous pouvons utiliser les outils en ligne de commande pour créer des rubriques et tenter de produire et de consommer quelques messages afin de comprendre les principes fondamentaux. DataCamp's L'article Apache Kafka pour débutants de DataCamp peut vous aider à vous familiariser avec le sujet.
Le premier concept que nous devons acquérir est le modèle éditeur-abonné dans Kafka. C'est l'une des principales raisons pour lesquelles Apache Kafka est en mesure de traiter efficacement les données en continu. Comprenez comment les producteurs publient des messages et comment les consommateurs s'abonnent à ces sujets, recevant uniquement les messages pertinents pour leurs intérêts.
Introduction à Apache Kafka par DataCamp Introduction à Apache Kafka propose une introduction, avec des exercices interactifs et des exemples pratiques.
Lors de la description du modèle éditeur-abonné, nous avons mentionné certains composants clés de Kafka : Producteur et consommateur. Cependant, il est important d'examiner tous les composants essentiels. Il est important de comprendre comment Kafka organise les données en thèmes et en partitions, et de saisir comment les partitions contribuent à l'évolutivité et à la tolérance aux pannes.
Il est également important de comprendre comment les courtiers forment un cluster afin d'assurer une haute disponibilité et une tolérance aux pannes.
Veuillez consulter le cours d'introduction à Apache Kafka de DataCamp. Introduction à Apache Kafka ainsi que l'article article Apache Kafka pour débutants pour obtenir une vision claire de ces sujets.
Une fois que vous maîtrisez les bases, il est temps d'approfondir vos connaissances sur Apache Kafka.
L'une des principales caractéristiques d'Apache Kafka est sa capacité à traiter de grands volumes de données en continu. Kafka Connect est un composant open source et gratuit d'Apache Kafka qui simplifie l'intégration des données entre les systèmes de fichiers, les bases de données, les index de recherche et les magasins de valeurs-clés.
Apprendre à utiliser Connect peut nous aider à optimiser le flux de données pour l'analyse, l'intégration d'applications et la création d'une architecture de données robuste et évolutive. Veuillez consulter notre article Apache Kafka pour débutants pour plus de détails.
Une autre fonctionnalité avancée de Kafka est Streams. Nous devrions apprendre à développer des applications de traitement de flux directement dans Kafka à l'aide de Streams. Il propose des API et un langage spécifique de haut niveau pour traiter, convertir et évaluer des flux de données continus. Pour en savoir plus, veuillez consulter l'article l'article Apache Kafka pour les débutants.
Comme pour toute autre technologie, il est toujours judicieux de suivre ses performances. Pour ce faire, il est important d'apprendre à surveiller la santé et les performances de notre cluster Kafka. Nous pouvons examiner les outils et les techniques permettant de surveiller les indicateurs clés, de gérer les sujets et les partitions, et de garantir des performances optimales.
Suivre des cours sur Apache Kafka constitue un excellent moyen de se familiariser avec cette technologie. Cependant, pour maîtriser Kafka, il est nécessaire de résoudre des problèmes complexes et stimulants, tels que ceux que vous rencontrerez dans le cadre de projets réels.
Vous pouvez commencer par tester des tâches simples de streaming de données, telles que la production et la consommation de messages, puis augmenter progressivement la complexité en explorant des sujets tels que le partitionnement, la tolérance aux pannes et l'intégration avec des systèmes externes à l'aide de Kafka Connect.
Voici quelques méthodes pour exercer vos compétences :
Vous réaliserez différents projets tout au long de votre parcours d'apprentissage d'Apache Kafka. Afin de mettre en valeur vos compétences et votre expérience en matière d'Apache Kafka auprès d'employeurs potentiels, il est recommandé de les compiler dans un portfolio. Ce portfolio doit refléter vos compétences et vos centres d'intérêt, et être adapté à la carrière ou au secteur qui vous intéresse.
Veuillez vous efforcer de rendre vos projets originaux et de mettre en avant vos compétences en matière de résolution de problèmes. Veuillez inclure des projets qui démontrent votre maîtrise des différents aspects de Kafka, tels que la création de pipelines de données avec Kafka Connect, le développement d'applications de streaming avec Kafka Streams ou l'utilisation de clusters Kafka. Veuillez documenter vos projets de manière exhaustive, en fournissant le contexte, la méthodologie, le code et les résultats. Vous pouvez utiliser des plateformes telles que GitHub pour héberger votre code et Confluent Cloud pour un environnement Kafka géré.
L'apprentissage de Kafka est un processus continu. La technologie évolue constamment, et de nouvelles fonctionnalités et applications sont régulièrement développées. Kafka ne fait pas exception à cette règle.
Une fois que vous maîtrisez les principes fondamentaux, vous pouvez vous orienter vers des tâches et des projets plus complexes, tels que l'optimisation des performances pour les systèmes à haut débit et la mise en œuvre d'un traitement avancé des flux avec Kafka Streams. Concentrez-vous sur vos objectifs et spécialisez-vous dans des domaines pertinents pour vos objectifs de carrière et vos centres d'intérêt.
Restez informé des dernières nouveautés, telles que les nouvelles fonctionnalités ou les propositions KIP, et découvrez comment les appliquer à vos projets. Continuez à vous exercer, recherchez de nouveaux défis et opportunités, et considérez les erreurs comme un moyen d'apprendre.
Même si chaque individu a sa propre méthode d'apprentissage, il est toujours judicieux de disposer d'un plan ou d'un guide à suivre pour apprendre à utiliser un nouvel outil. J'ai élaboré un plan d'apprentissage potentiel qui indique où concentrer votre temps et vos efforts si vous débutez avec Apache Kafka.

J'imagine qu'à présent, vous êtes prêt à vous lancer dans l'apprentissage de Kafka et à vous procurer un ensemble de données volumineux afin de mettre en pratique vos nouvelles compétences. Cependant, avant de vous lancer, permettez-moi de vous présenter ces conseils qui vous aideront à maîtriser Apache Kafka.
Kafka est un outil polyvalent qui peut être utilisé de multiples façons. Il est important que vous identifiiez vos objectifs et vos intérêts spécifiques au sein de l'écosystème Kafka. Quel aspect de Kafka vous attire le plus ? Êtes-vous intéressé par l'ingénierie des données, le traitement des flux ou l'administration Kafka ? Une approche ciblée peut vous aider à acquérir les connaissances et les aspects les plus pertinents d'Apache Kafka pour répondre à vos intérêts.
La constance est essentielle pour maîtriser toute nouvelle compétence. Il est recommandé de consacrer du temps à la pratique de Kafka. Quelques instants chaque jour suffisent. Il n'est pas nécessaire d'aborder des concepts complexes quotidiennement. Vous pouvez réaliser des exercices pratiques, suivre des tutoriels et tester différentes fonctionnalités de Kafka. Plus vous vous entraînerez, plus vous vous sentirez à l'aise avec la plateforme.
Il s'agit d'un conseil essentiel, que vous retrouverez à plusieurs reprises dans ce guide. La pratique d'exercices est un excellent moyen de gagner en confiance. Cependant, c'est en appliquant vos compétences Kafka à des projets concrets que vous parviendrez à les maîtriser parfaitement.
Commencez par des projets et des questions simples, puis passez progressivement à des projets et des questions plus complexes. Cela pourrait impliquer la mise en place d'une application simple de type producteur-consommateur, puis la création d'un pipeline de données en temps réel avec Kafka Connect, ou même la conception d'une application de streaming tolérante aux pannes avec Kafka Streams. La clé réside dans le fait de se remettre continuellement en question et d'approfondir ses compétences pratiques en Kafka.
L'apprentissage est souvent plus efficace lorsqu'il est effectué de manière collaborative. Partager vos expériences et apprendre des autres peut accélérer vos progrès et vous apporter des informations précieuses.
Pour échanger des connaissances, des idées et poser des questions, vous pouvez rejoindre des groupes liés à Apache Kafka et participer à des rencontres et des conférences. Vous pouvez également rejoindre des communautés en ligne telles que le canal Slack Confluent. canal Slack Confluent ou forum Confluent où vous pourrez interagir avec d'autres passionnés de Kafka. Vous pouvez également participer à des rencontres virtuelles ou en personne. rencontres, proposant des conférences données par des experts Kafka, ou à des conférences, telles que ApacheCon.
Comme pour toute autre technologie, l'apprentissage d'Apache Kafka est un processus itératif. Apprendre de ses erreurs est une partie essentielle de ce processus. N'hésitez pas à expérimenter, à essayer différentes approches et à tirer des leçons de vos erreurs.
Veuillez tester différentes configurations pour vos producteurs et consommateurs Kafka, explorer diverses méthodes de sérialisation des données (JSON, Avro, Protobuf) et expérimenter différentes stratégies de partitionnement. Veuillez exploiter votre cluster Kafka à son maximum avec des volumes de messages élevés et observez comment il gère la charge. Analysez le retard des consommateurs, affinez les configurations et comprenez l'impact de vos optimisations sur les performances.
Veuillez prendre le temps de bien comprendre les concepts fondamentaux tels que les thèmes, les partitions, les groupes de consommateurs et le rôle de ZooKeeper. Si vous établissez dès maintenant des bases solides, il vous sera plus facile de comprendre les sujets plus avancés et de résoudre efficacement les problèmes. Divisez le processus d'apprentissage en étapes plus petites et accordez-vous le temps nécessaire pour assimiler les informations. Une approche lente et régulière conduit souvent à une compréhension et une maîtrise plus approfondies.
Examinons quelques méthodes efficaces pour apprendre Apache Kafka.
Les cours en ligne constituent un excellent moyen d'apprendre Apache Kafka à votre rythme. DataCamp propose un cours intermédiaire sur Kafka. Ce cours aborde les concepts fondamentaux de Kafka, notamment le modèle éditeur-abonné, les sujets et les partitions, les courtiers et les clusters, les producteurs et les consommateurs.
Les tutoriels constituent un autre excellent moyen d'apprendre Apache Kafka, en particulier si vous débutez avec cette technologie. Ils contiennent des instructions détaillées sur la manière d'effectuer des tâches spécifiques ou de comprendre certains concepts. Pour commencer, veuillez consulter ces tutoriels :
Pour mieux comprendre les avantages d'Apache Kafka, il est également important de connaître les principales similitudes et différences avec d'autres technologies. Vous pouvez consulter des articles comparant Kafka à d'autres outils, tels que les suivants :
Les livres constituent une excellente ressource pour apprendre Apache Kafka. Ils offrent des connaissances approfondies et des informations provenant d'experts, ainsi que des extraits de code et des explications. Voici quelques-uns des ouvrages les plus populaires sur Kafka :
L'adoption d'Apache Kafka ne cessant de croître, les opportunités de carrière pour les professionnels possédant des compétences Kafka, qu'il s'agisse d'ingénieurs Kafka spécialisés ou d'ingénieurs logiciels, se multiplient également. Si vous évaluez l'adéquation de vos compétences Kafka, veuillez considérer les rôles suivants :

En tant qu'ingénieur Kafka, vous êtes chargé de concevoir, de développer et de maintenir des solutions de streaming de données basées sur Kafka, offrant une haute disponibilité et une grande évolutivité. Vous devrez garantir la fiabilité et l'efficacité du flux de données au sein de l'entreprise, ainsi que surveiller et optimiser les performances de Kafka afin d'assurer un débit et une latence optimaux.
En tant qu'ingénieur de données, vous êtes l'architecte de l'infrastructure de données, chargé de concevoir et de construire les systèmes qui gèrent les données d'une entreprise. Kafka joue souvent un rôle important dans ces pipelines de données, permettant un streaming de données en temps réel efficace et évolutif entre différents systèmes. Il est nécessaire de veiller à ce que Kafka s'intègre parfaitement aux autres composants.
En tant qu'ingénieur logiciel, vous utiliserez Kafka pour développer des applications en temps réel telles que des plateformes de chat et des jeux en ligne. Il sera nécessaire de l'intégrer au code de l'application afin de garantir un flux de données fluide en le connectant à divers systèmes de messagerie et API. Vous optimiserez également ces applications en termes d'évolutivité et de performances, leur permettant ainsi de traiter de grandes quantités de données en temps réel.
|
Rôle |
Ce que vous faites |
Vos compétences clés |
Outils que vous utilisez |
|
Kafka Engineer |
Concevoir et mettre en œuvre des clusters Kafka pour une haute disponibilité et une évolutivité optimales. |
Architecture Kafka, composants, administration et configuration, concepts de traitement des flux. |
Apache Kafka, Kafka Connect, Kafka Streams, ZooKeeper |
|
Ingénieur de données |
Concevoir et mettre en œuvre des entrepôts de données et des lacs de données, intégrer Kafka à d'autres systèmes de traitement et de stockage de données. |
Maîtrise des outils de traitement des données, expérience des plateformes cloud et connaissance de Kafka. |
Apache Kafka, Apache Spark, Hadoop, Ruche, Plateformes cloud |
|
Ingénieur logiciel |
Concevez et développez des applications qui exploitent Kafka pour la communication de données en temps réel. |
Compétences en programmation, systèmes et applications distribués, connaissance de Kafka en tant qu'éditeur-abonné. |
Apache Kafka, Java, Python, Scala, RabbitMQ, ActiveMQ, Outils et cadres de développement. |
Bien qu'un diplôme puisse être très utile pour poursuivre une carrière dans un poste lié aux données qui utilise Apache Kafka, ce n'est pas la seule voie pour réussir. De plus en plus de personnes issues de divers horizons et ayant des expériences différentes commencent à occuper des postes liés aux données. Grâce à votre dévouement, à votre apprentissage continu et à votre approche proactive, vous pouvez décrocher l'emploi de vos rêves qui utilise Apache Kafka.
Restez informé des derniers développements concernant Kafka. Suivez les professionnels influents impliqués dans Apache Kafka sur les réseaux sociaux, consultez les blogs consacrés à Apache Kafka et écoutez les podcasts liés à Kafka.
Interagissez avec des personnalités influentes, telles que Neha Narkhede, co-fondatrice de Kafka et directrice technique de Confluent. Vous obtiendrez des informations sur les sujets d'actualité, les technologies émergentes et l'orientation future d'Apache Kafka. Vous pouvez également consulter le blog Confluent, qui propose des articles approfondis et des tutoriels sur un large éventail de sujets liés à Kafka, de l'architecture et l'administration aux cas d'utilisation et aux meilleures pratiques.
Nous vous recommandons également de consulter les événements du secteur, tels que les webinaires proposés par Confluent ou le sommet annuel Kafka Summit.
Il est essentiel que vous vous démarquiez des autres candidats. Une bonne façon d'y parvenir est de constituer un solide portfolio qui met en valeur vos compétences et les projets que vous avez menés à bien.
Votre portfolio devrait inclure des projets qui démontrent votre maîtrise dans la création de pipelines de données, la mise en œuvre d'applications de traitement de flux et l'intégration de Kafka à d'autres systèmes.
Les responsables du recrutement doivent examiner de nombreux CV et identifier les meilleurs candidats. De plus, votre CV est souvent soumis à des systèmes de suivi des candidats (ATS), des logiciels automatisés utilisés par de nombreuses entreprises pour examiner les CV et éliminer ceux qui ne répondent pas à des critères spécifiques. Il est donc important de rédiger un CV de qualité et une lettre de motivation convaincante. lettre de motivation convaincante afin d'impressionner à la fois l'ATS et vos recruteurs.
Attirez l'attention d'un responsable du recrutement
Si vous retenez l'attention du responsable du recrutement ou si votre CV convaincant passe le processus de sélection, vous devriez ensuite vous préparer à un entretien technique. Pour vous préparer, vous pouvez consulter cet article sur 20 questions d'entretien Kafka pour les ingénieurs de données.
Apprendre Apache Kafka peut vous ouvrir les portes vers de meilleures opportunités et perspectives de carrière. L'apprentissage de Kafka est enrichissant, mais nécessite de la constance et une pratique intensive. Expérimenter et résoudre des défis à l'aide de cet outil peut accélérer votre processus d'apprentissage et vous fournir des exemples concrets pour mettre en valeur vos compétences pratiques lorsque vous recherchez un emploi.
Apprenez l'ingénierie des données grâce à ces cours.
Cursus
Cours
Cours