
Curso
Fundamentos de big data con PySpark
4 h
65.2K
Apache Hadoop, a menudo llamado simplemente Hadoop, es un potente marco de código abierto creado para procesar y almacenar conjuntos de datos masivos distribuyéndolos en clusters de hardware asequible y básico. Su punto fuerte es la escalabilidad y la flexibilidad, que le permiten trabajar con datos estructurados y no estructurados.
En este post, repasaré los componentes clave de Hadoop: cómo almacena, procesa y gestiona datos a escala. Al final, tendrás una idea clara de cómo encaja esta tecnología fundacional en los ecosistemas de big data.
Hadoop no es una herramienta única. Es un ecosistema que incluye múltiples módulos que trabajan juntos para gestionar el almacenamiento de datos, el procesamiento y la coordinación de recursos.
Hadoop consta de cuatro módulos fundacionales:
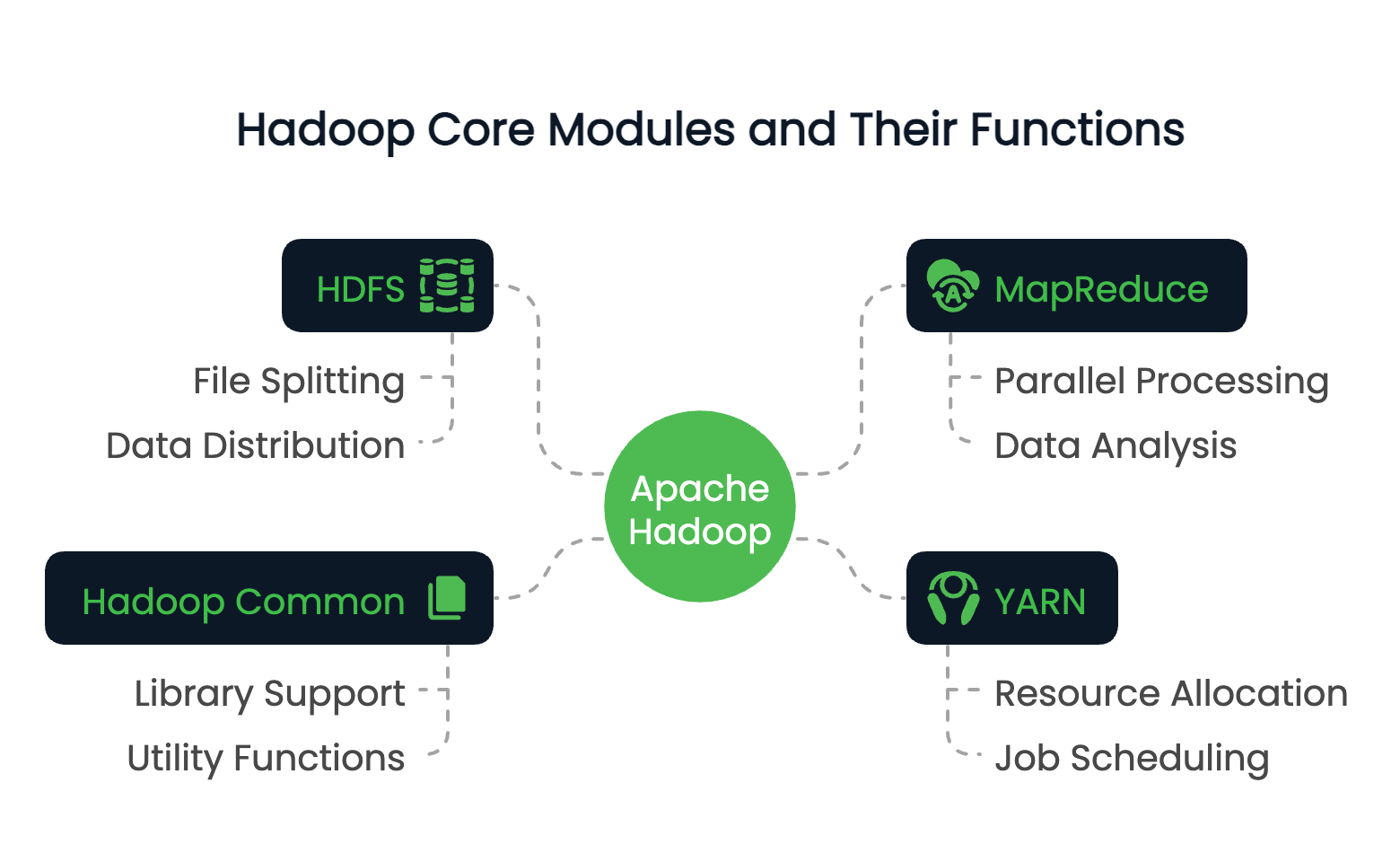
Estos módulos trabajan juntos para crear un entorno informático distribuido capaz de manejar petabytes de datos.
Para explorar cómo se compara el procesamiento de datos distribuidos entre plataformas, el curso Fundamentos de Big Data con PySpark proporciona una introducción práctica que complementa tus conocimientos de Hadoop.
El papel principal de Hadoop reside en su capacidad para abordar un reto fundamentalen elprocesamiento de big data, a saber, la escalabilidad.
Los sistemas tradicionales suelen tener dificultades con conjuntos de datos que superan la capacidad de una sola máquina, tanto en almacenamiento como en computación. Hadoop resuelve esto distribuyendo los datos entre muchos nodos y ejecutando los cálculos en paralelo.
Así, Hadoop puede procesar terabytes o incluso petabytes de datos de forma eficiente. Más allá de su escalabilidad, Hadoop también tiene una profunda tolerancia a los fallos mediante la replicación de datos y permite a las organizaciones construir infraestructuras de datos rentables utilizando hardware básico.
Ya hemos hablado del papel y la estructura de Hadoop, ahora veamos algunos de los atributos más valiosos de Hadoop. Entre ellas están:
Estas características hacen que Hadoop sea muy adecuado para el procesamiento de datos por lotes, el análisis de registros y las canalizaciones ETL. Hadoop es un caso clásico studio de computación distribuida, donde la computación se produce a través de múltiples nodos para aumentar la eficiencia y la escala.
Ahora, veamos en detalle cada uno de los módulos principales de Hadoop.
¿Quieres validar tus conocimientos sobre Hadoop o prepararte para un puesto relacionado con los datos? Aquí tienes 24 preguntas y respuestas de entrevistas sobre Hadoop para 2025 que te ayudarán a empezar.
De los cuatro componentes principales, HDFS es el sistema de almacenamiento principal de Hadoop. Está diseñado para almacenar de forma fiable las enormes cantidades de datos en un clúster de máquinas de las que hemos hablado antes. Su arquitectura está preparada para este tipo de acceso a grandes conjuntos de datos y está optimizada para la tolerancia a fallos, la escalabilidad y la localidad de los datos.
La arquitectura HDFS gira en torno a un modelo maestro-esclavo. En la parte superior se encuentra el NodoNombre, que gestiona los metadatos, es decir, el árbol de directorios del sistema de archivos y la información sobre la ubicación de cada archivo. No almacena los datos reales.
Los Nodos de Datos son los caballos de batalla. Gestionan el almacenamiento conectado a los nodos y atienden las peticiones de lectura/escritura de los clientes. Cada Nodo de Datos informa regularmente al Nodo de Nombre con un latido e informes de bloque para garantizar un seguimiento coherente del estado.
Por último, HDFS incluye un Nodo de Nombre Secundario, que no debe confundirse con un nodo de conmutación por error. En su lugar, comprueba periódicamente los metadatos de NameNode para reducir el tiempo de inicio y la sobrecarga de memoria.
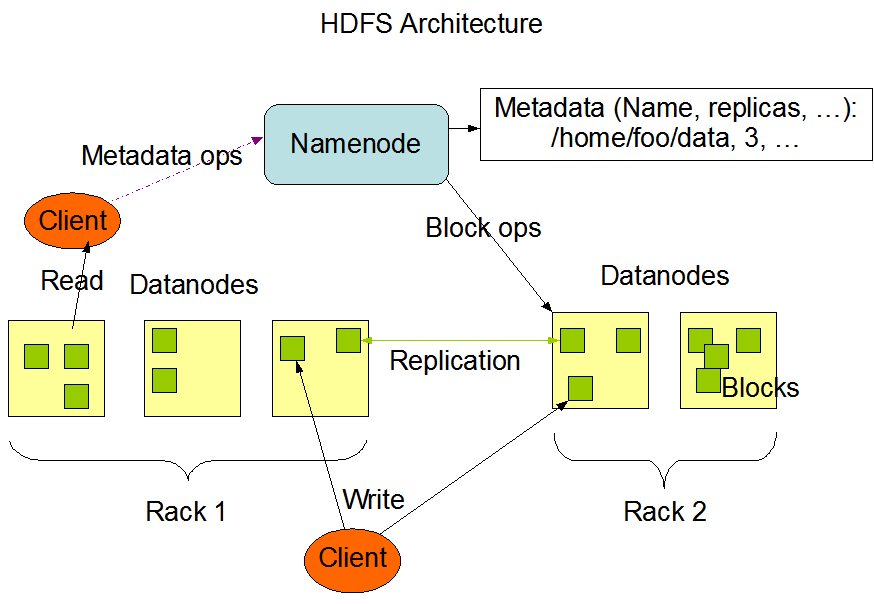
La arquitectura HDFS. Fuente de la imagene: Documentación sobre Apache Hadoop
Cuando se escribe un archivo en HDFS, se divide en bloques detamaño fijo de 64 MB. A continuación, cada bloque se distribuye entre distintos Nodos de Datos. Esta estrategia de distribución favorece el paralelismo en el acceso a los datos y aumenta la tolerancia a los fallos.
Los datos en HDFS no se almacenan una sola vez. Cada bloque se replica (por defecto son tres copias) y se distribuye por el clúster. Durante una operación de lectura, el sistema extrae los datos de la réplica disponible más cercana para maximizar el rendimiento y minimizar la latencia. Las escrituras van primero a una réplica y luego se propagan a las demás, garantizando la durabilidad sin cuellos de botella inmediatos.
Este diseño a nivel de bloque también permite a HDFS escalar horizontalmente. Se pueden añadir nuevos nodos al clúster, y el sistema reequilibrará los datos para utilizar la capacidad adicional.
Para compararlo con otros formatos de big data, exploracómo Apache Parquetoptimiza el almacenamiento columnar para cargas de trabajo analíticas.
HDFS está construido pensando en el fracaso. En los grandes sistemas distribuidos, los fallos de los nodos son esperables, no excepcionales. HDFS garantiza la disponibilidad de los datos mediante su mecanismo de replicación. Si un Nodo de Datos se cae, el Nodo de Nombre detecta el fallo mediante latidos perdidos y programa la replicación de los bloques perdidos a los nodos sanos.
Además, el sistema supervisa constantemente el estado de los bloques e inicia la replicación cuando es necesario. La estrategia de almacenamiento redundante, combinada con la supervisión proactiva, garantiza que ningún punto de fallo pueda comprometer la integridad de los datos o el acceso a ellos.
El siguiente es el motor de procesamiento de Hadoop, MapReduce. Permite el cálculo distribuido en grandes conjuntos de datos, dividiendo las tareas en operaciones más pequeñas e independientes que pueden ejecutarse en paralelo.
El modelo simplifica las transformaciones complejas de datos y es especialmente adecuado para el procesamiento por lotes en un entorno distribuido.
MapReduce sigue un modelo de programación en dos fases: la fase Mapa y Reducir fases.
Durante la fase de Mapa, el conjunto de datos de entrada se divide en trozos más pequeños, y cada trozo se procesa para producir pares clave-valor. Estos resultados intermedios se barajan y ordenan antes de pasar a la fase Reducir, donde se agregan o transforman en salidas finales.
Este modelo es muy eficaz para tareas como contar frecuencias de palabras, filtrar registros o unir conjuntos de datos a escala.
Los programadores implementan la lógica personalizada a través de las funciones map() y reduce(), que el marco orquesta en todo el clúster.
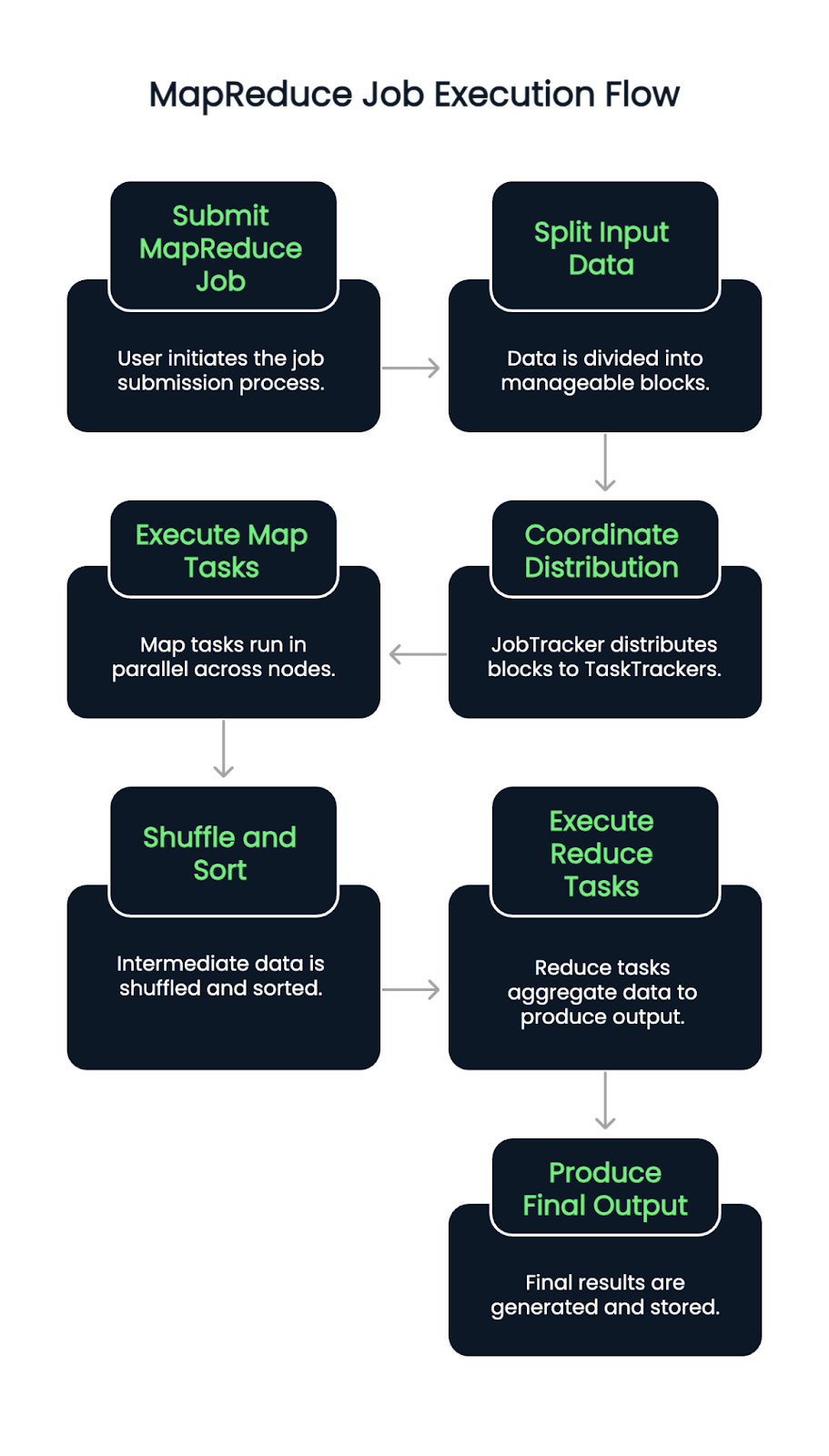
Cuando se envía un trabajo MapReduce, los datos de entrada se dividen primero en bloques. A continuación, un JobTracker (o ResourceManager en las versiones compatibles con YARN) coordina la distribución de estos bloques entre los TaskTrackers o NodeManagers disponibles.
Las tareas Mapa se ejecutan en paralelo a través de los nodos, leyendo las divisiones de entrada y emitiendo pares clave-valor intermedios. A continuación, estas parejas se barajan y clasifican automáticamente. Una vez completada esta fase, comienzan las tareas de Reducción, que extraen los datos agrupados y aplican la lógica de agregación para producir el resultado final.
El proceso garantiza la localidad de los datos asignando tareas cerca de donde residen los datos, minimizando la congestión de la red y mejorando el rendimiento. Los fallos en las tareas se detectan y reasignan automáticamente, contribuyendo a la resiliencia del sistema.
MapReduce ofrece varias ventajas claras:
Pero también tiene sus contrapartidas:
¿Decidir entre Hadoop y Spark? Lee nuestra guía sobre qué marco de Big Data es el más adecuado para ti.
YARN sirve como capa de gestión de recursos de Hadoop. Separa la programación de trabajos y la asignación de recursos del modelo de procesamiento, ayudando a Hadoop a soportar múltiples motores de procesamiento de datos más allá de MapReduce.
YARN actúa como plataforma central para gestionar los recursos informáticos de todo el clúster. Asigna los recursos disponibles del sistema a varias aplicaciones y coordina la ejecución. Esta separación de intereses ayuda a Hadoop a escalar eficientemente y abre la puerta a la compatibilidad con otros marcos como Apache Spark, Hive y Tez.
YARN introduce tres componentes:
Cada aplicación (como un trabajo MapReduce) tiene su propio ApplicationMaster, lo que permite un mejor aislamiento de fallos y seguimiento del trabajo.
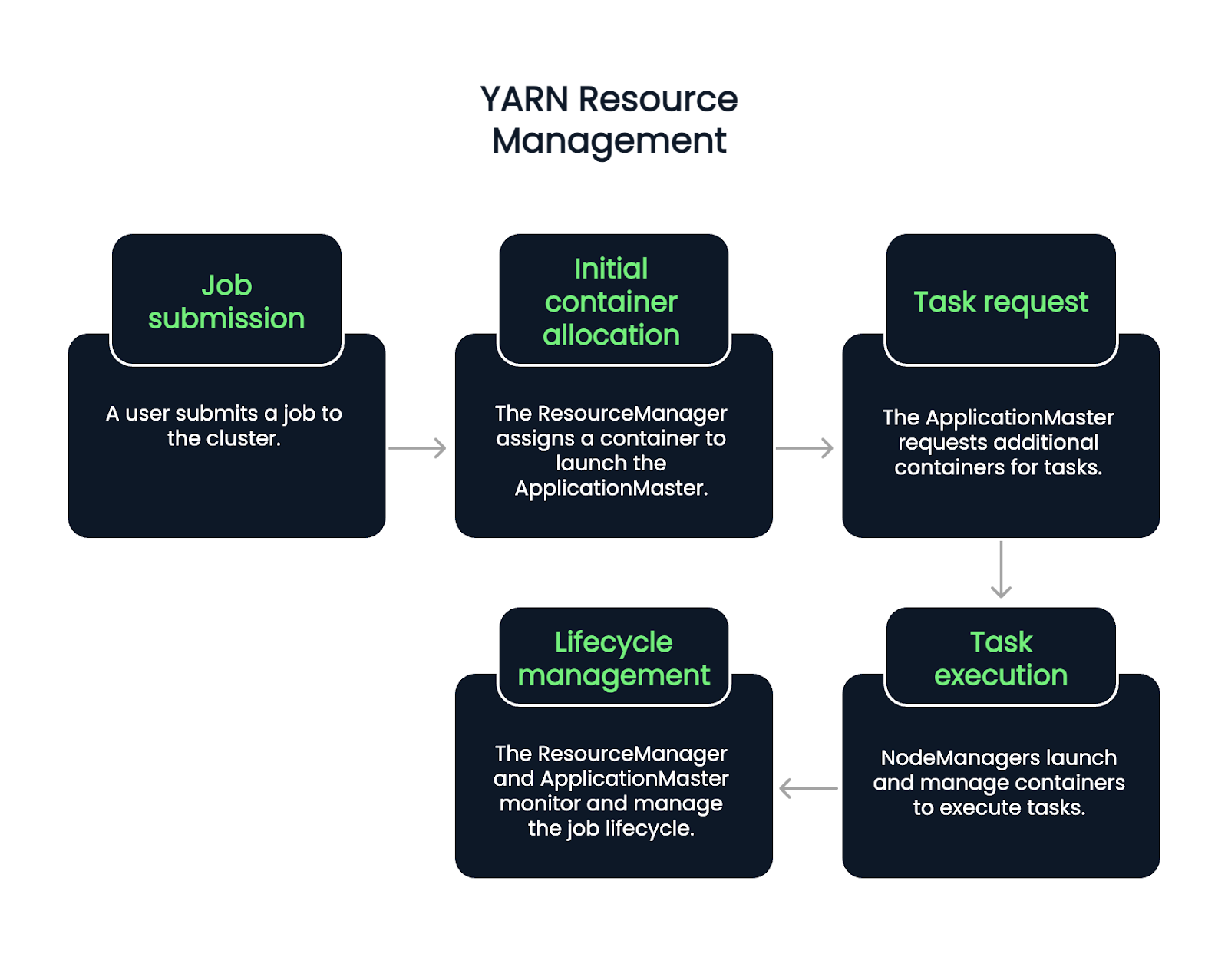
El flujo comienza cuando un usuario envía un trabajo. El Gestor de Recursos acepta el trabajo y asigna un contenedor para iniciar la AplicaciónMaster. A partir de ahí, el ApplicationMaster solicita más contenedores para ejecutar tareas, en función de la carga de trabajo actual y de la disponibilidad.
Los NodeManagers lanzan y gestionan estos contenedores, que ejecutan tareas individuales. A lo largo del ciclo de vida del trabajo, el ResourceManager y el ApplicationMaster se encargan de la supervisión, la recuperación de fallos y los informes de finalización. Se trata de un proceso de cinco pasos.
El pegamento que une todos los componentes de Hadoop es Hadoop Common. Es una colección de bibliotecas, archivos de configuración y utilidades que necesitan todos los módulos.
Hadoop Common proporciona el código base y las herramientas que permiten que HDFS, YARN y MapReduce se comuniquen y coordinen. Esto incluye bibliotecas Java, clientes del sistema de archivos y API utilizadas en todo el ecosistema.
También garantiza la coherencia y compatibilidad entre módulos, permitiendo a los programadores construir sobre un conjunto compartido de primitivas.
Una configuración adecuada de Hadoop es fundamental. Hadoop Common alberga archivos de configuración como core-site.xml, que definen comportamientos por defecto como URIs del sistema de archivos y ajustes de E/S.
Las herramientas de línea de comandos y los scripts incluidos en Hadoop Common permiten realizar tareas como iniciar servicios, comprobar el estado de los nodos y gestionar trabajos. Los administradores de sistemas y programadores confían en la mayoría de estas herramientas para las operaciones cotidianas del clúster.
Si utiliza conjuntos de datos masivos, procesamiento distribuido o análisis por lotes, es probable que se utilice Hadoop. Más concretamente, Hadoop se utiliza en diversos sectores para procesar volúmenes masivos de datos estructurados y no estructurados. Su diseño distribuido y su flexibilidad de código abierto lo hacen versátil para tareas con gran cantidad de datos.
Las organizaciones financieras, sanitarias, de telecomunicaciones, de comercio electrónico y de medios sociales utilizan Hadoop habitualmente. Ayuda a los bancos a detectar el fraude en tiempo real, respalda la investigación genómica en la sanidad y habilita motores de recomendación en el comercio minorista en línea.
Estos escenarios se benefician de la capacidad de Hadoop para manejar grandes conjuntos de datos con tolerancia a fallos y paralelismo.
Para una alternativa moderna y nativa de la nube a Hadoop, prueba el curso Introducción a Databricks, que admite Spark y otras herramientas escalables.
Hadoop rara vez funciona de forma aislada y puede integrarse con cientos de programas accesorios. Dependiendo de tus preferencias y entorno de codificación, podrías emparejar Hadoop con:
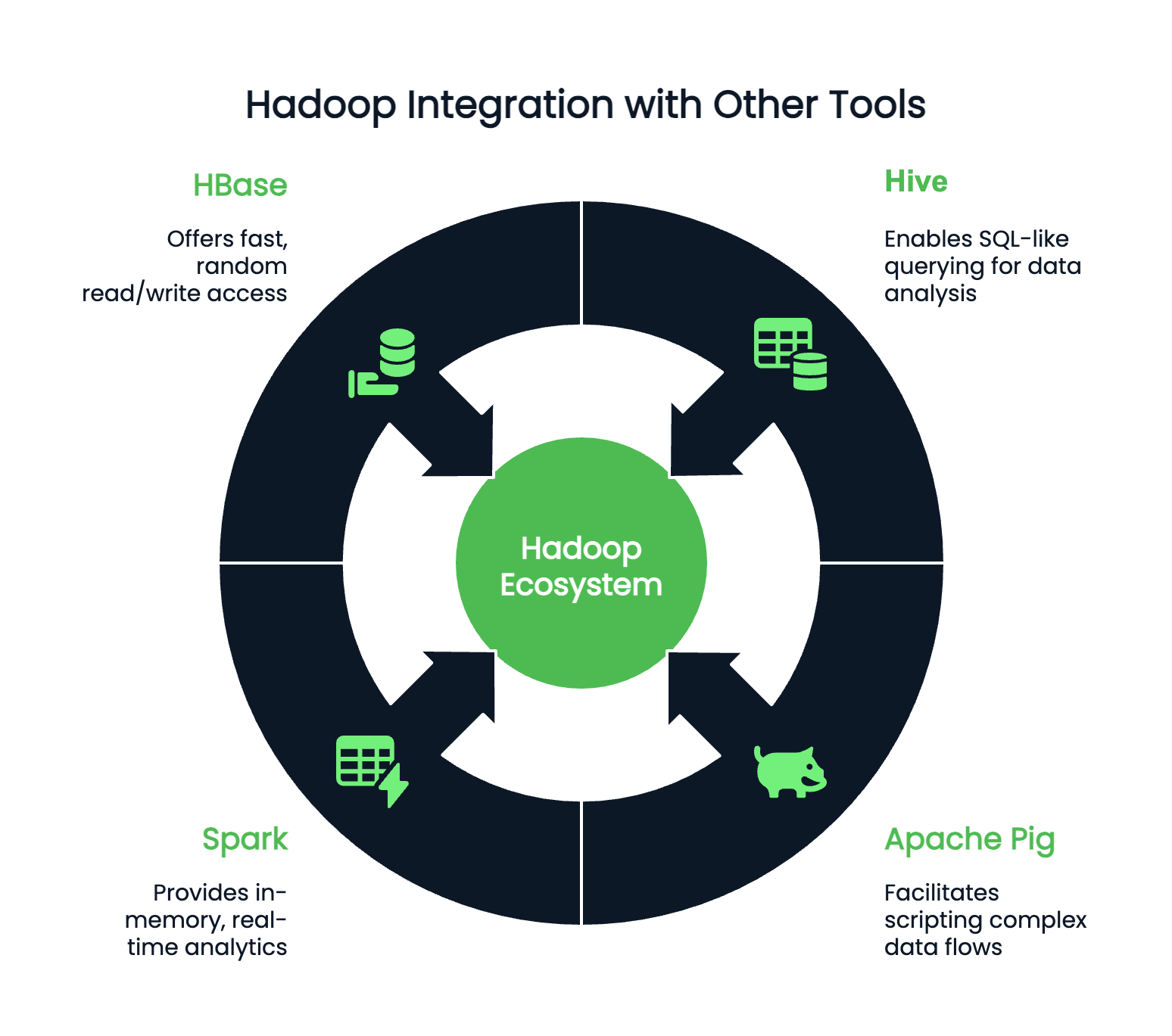
Aunque Hadoop ya no sea la palabra de moda que era, sigue siendo una tecnología fundamental en el panorama de los grandes datos. Comprender Hadoop sigue siendo increíblemente valioso para cualquier profesional de los datos que trabaje con sistemas a gran escala. Sus componentes principales -HDFS para el almacenamiento, MapReduce para el procesamiento, YARN para la gestión de recursos y Hadoop Common para las utilidades esenciales- siguen dando forma a cómo se diseñan y escalan los flujos de trabajo de datos.
Antes de lanzarte a la implantación u optimización, tómate tu tiempo para comprender cómo se distribuyen y configuran los datos dentro de un clúster Hadoop. Ese conocimiento simplifica la resolución de problemas y el ajuste del rendimiento, y allana el camino para integrar potentes herramientas como Apache Spark y Hive para análisis más sofisticados.
Parasaber mássobre el tratamiento de big data, consulta:
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Bhavishya Pandit
7 min
blog
DataCamp Team
12 min
Tutorial
Tim Lu
Tutorial
Joleen Bothma