
Curso
Fundamentos de Big Data com PySpark
4 h
65.2K
O Apache Hadoop, muitas vezes chamado apenas de Hadoop, é uma poderosa estrutura de código aberto criada para processar e armazenar conjuntos de dados maciços, distribuindo-os em clusters de hardware acessível e de commodity. Seu ponto forte está na escalabilidade e na flexibilidade, permitindo que ele trabalhe com dados estruturados e não estruturados.
Nesta postagem, examinarei os principais componentes do Hadoop - como ele armazena, processa e gerencia dados em escala. Ao final, você terá uma visão clara de como essa tecnologia fundamental se encaixa nos ecossistemas de big data.
O Hadoop não é uma ferramenta única. É um ecossistema que inclui vários módulos que trabalham juntos para gerenciar o armazenamento de dados, o processamento e a coordenação de recursos.
O Hadoop consiste em quatro módulos básicos:
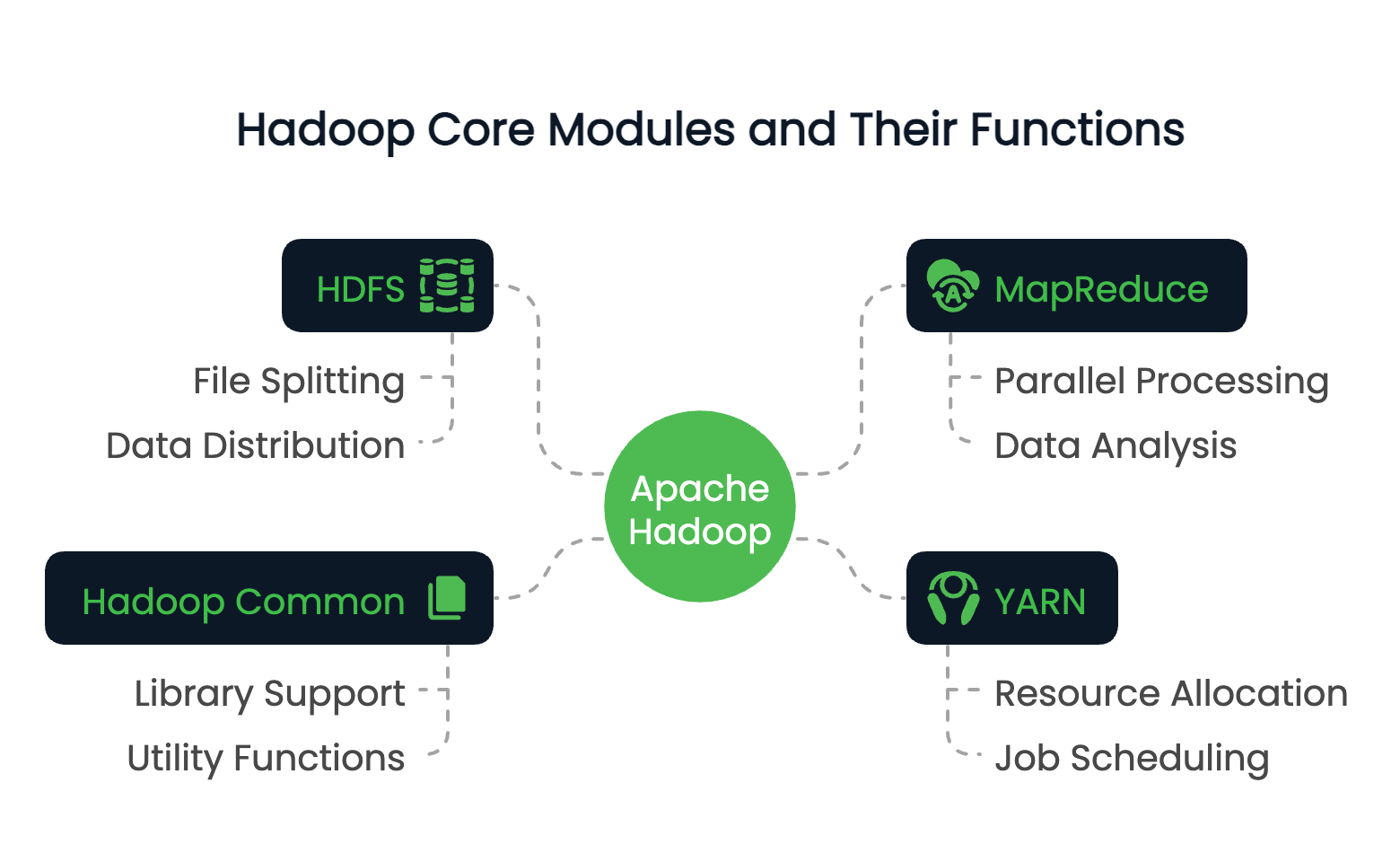
Esses módulos trabalham juntos para criar um ambiente de computação distribuída capaz de lidar com petabytes de dados.
Para explorar como o processamento de dados distribuídos se compara entre plataformas, o curso Big Data Fundamentals with PySpark oferece uma introdução prática que complementa seu conhecimento sobre o Hadoop.
A função principal do Hadoop está em sua capacidade de enfrentar um desafio centralnoprocessamento de big data, ou seja, a escalabilidade.
Os sistemas tradicionais geralmente enfrentam dificuldades com conjuntos de dados que excedem a capacidade de uma única máquina, tanto em termos de armazenamento quanto de computação. O Hadoop resolve isso distribuindo dados em vários nós e executando cálculos em paralelo.
Assim, o Hadoop pode processar terabytes ou até petabytes de dados com eficiência. Além de sua escalabilidade, o Hadoop também tem uma profunda tolerância a falhas por meio da replicação de dados e permite que as organizações criem uma infraestrutura de dados econômica usando hardware de commodity.
Já discutimos a função e a estrutura do Hadoop, agora vamos examinar alguns dos atributos mais valiosos do Hadoop. Isso inclui:
Esses recursos tornam o Hadoop adequado para processamento de dados em lote, análise de logs e pipelines de ETL. O Hadoop é um caso clássico de estudo de computação distribuída, em que a computação ocorre em vários nós para aumentar a eficiência e a escala.
Agora, vamos examinar detalhadamente cada um dos módulos principais do Hadoop.
Você quer validar seu conhecimento sobre o Hadoop ou se preparar para uma função de dados? Aqui estão 24 perguntas e respostas de entrevistas sobre o Hadoop para 2025, para que você possa começar.
Dos quatro componentes principais, o HDFS é o principal sistema de armazenamento do Hadoop. Ele foi projetado para armazenar de forma confiável as grandes quantidades de dados em um cluster de máquinas que discutimos anteriormente. Sua arquitetura é configurada para esse tipo de acesso a grandes conjuntos de dados e é otimizada para tolerância a falhas, escalabilidade e localidade de dados.
A arquitetura do HDFS gira em torno de um modelo mestre-escravo. Na parte superior está o NameNode, que gerencia os metadados - basicamente, a árvore de diretórios do sistema de arquivos e as informações sobre a localização de cada arquivo. Ele não armazena os dados reais.
Os DataNodes são os cavalos de batalha. Eles gerenciam o armazenamento anexado aos nós e atendem às solicitações de leitura/gravação dos clientes. Cada DataNode se reporta regularmente ao NameNode com um heartbeat e relatórios de bloco para garantir que você tenha um acompanhamento consistente do estado.
Por fim, o HDFS inclui um Secondary NameNode, que não deve ser confundido com um nó de failover. Em vez disso, ele faz checkpoints periódicos dos metadados do NameNode para reduzir o tempo de inicialização e a sobrecarga de memória.
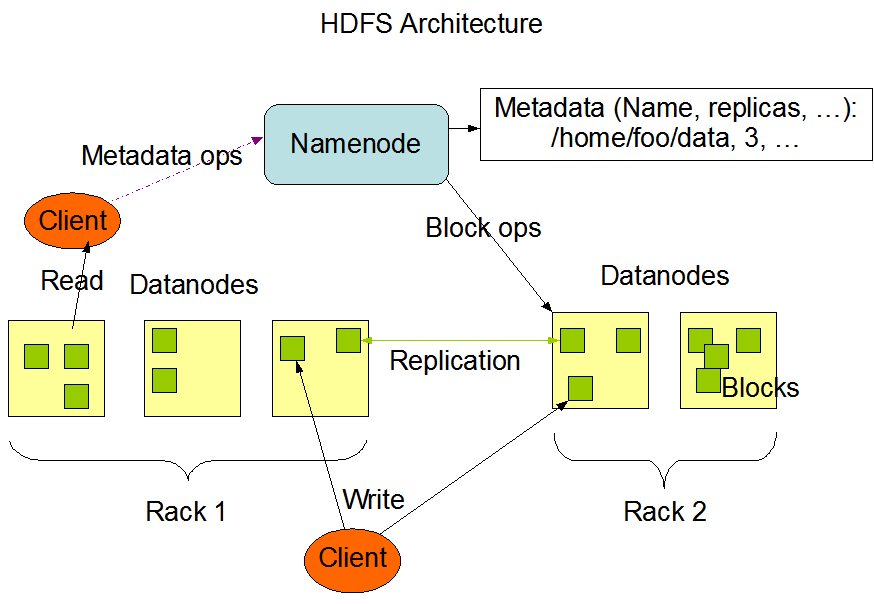
A arquitetura do HDFS. Fonte da imageme: Documentação do Apache Hadoop
Quando um arquivo é gravado no HDFS, ele é dividido em blocos de 64 MB detamanho fixo . Cada bloco é então distribuído entre diferentes DataNodes. Essa estratégia de distribuição oferece suporte ao paralelismo durante o acesso aos dados e aumenta a tolerância a falhas.
Os dados no HDFS não são armazenados apenas uma vez. Cada bloco é replicado (o padrão é três cópias) e distribuído pelo cluster. Durante uma operação de leitura, o sistema extrai dados da réplica disponível mais próxima para maximizar a taxa de transferência e minimizar a latência. As gravações vão primeiro para uma réplica e depois se propagam para as outras, garantindo a durabilidade sem gargalos imediatos.
Esse design em nível de bloco também permite que o HDFS seja dimensionado horizontalmente. Novos nós podem ser adicionados ao cluster, e o sistema reequilibrará os dados para usar a capacidade adicional.
Para comparação com outros formatos de big data, explorecomo o Apache Parquetotimiza o armazenamento colunar para cargas de trabalho de análise.
O HDFS foi criado pensando em falhas. Em grandes sistemas distribuídos, as falhas de nós são esperadas, não excepcionais. O HDFS garante a disponibilidade dos dados por meio de seu mecanismo de replicação. Se um DataNode cair, o NameNode detectará a falha por meio de heartbeats perdidos e programará a replicação de blocos perdidos para nós saudáveis.
Além disso, o sistema monitora constantemente a integridade do bloco e inicia a replicação conforme necessário. A estratégia de armazenamento redundante, combinada com o monitoramento proativo, garante que nenhum ponto único de falha possa comprometer a integridade ou o acesso aos dados.
O próximo é o mecanismo de processamento do Hadoop, o MapReduce. Ele permite a computação distribuída em grandes conjuntos de dados, dividindo as tarefas em operações menores e independentes que podem ser executadas em paralelo.
O modelo simplifica as transformações complexas de dados e é especialmente adequado para o processamento em lote em um ambiente distribuído.
O MapReduce segue um modelo de programação de duas fases: o Mapa e Reduzir fases.
Durante a fase de mapeamento, o conjunto de dados de entrada é dividido em partes menores, e cada parte é processada para produzir pares de valores-chave. Esses resultados intermediários são então embaralhados e classificados antes de serem passados para a fase de redução, onde são agregados ou transformados em resultados finais.
Esse modelo é altamente eficaz para tarefas como contagem de frequências de palavras, filtragem de registros ou união de conjuntos de dados em escala.
Os desenvolvedores implementam a lógica personalizada por meio das funções map() e reduce(), que a estrutura orquestra em todo o cluster.
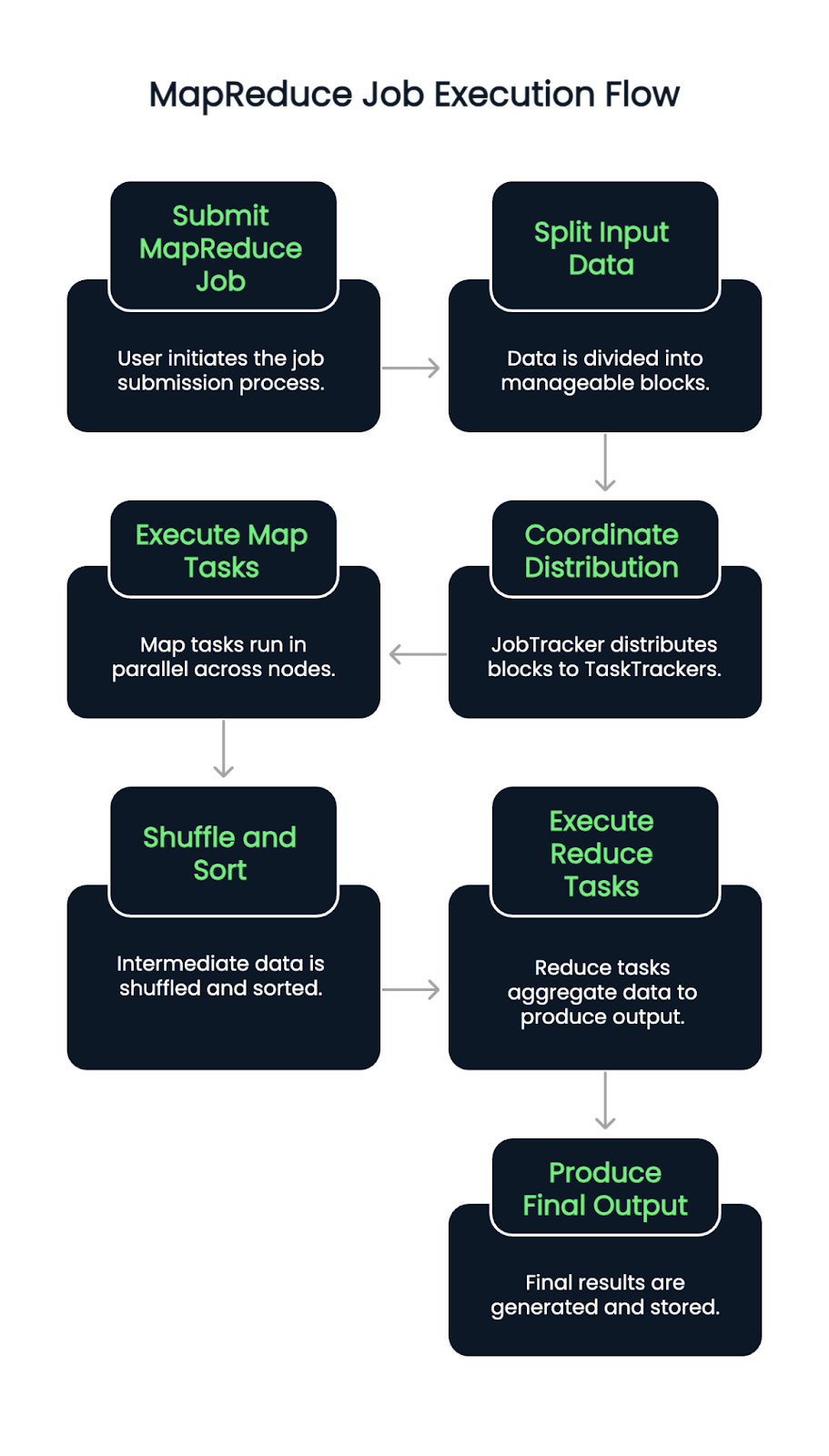
Quando um trabalho de MapReduce é enviado, os dados de entrada são primeiro divididos em blocos. Em seguida, um JobTracker (ou ResourceManager nas versões habilitadas para YARN) coordena a distribuição desses blocos entre os TaskTrackers ou NodeManagers disponíveis.
As tarefas Map são executadas em paralelo nos nós, lendo as divisões de entrada e emitindo pares de valores-chave intermediários. Em seguida, esses pares são embaralhados e classificados automaticamente. Uma vez concluída essa fase, começam as tarefas de redução, extraindo dados agrupados e aplicando a lógica de agregação para produzir o resultado final.
O processo garante a localidade dos dados atribuindo tarefas perto de onde os dados residem, minimizando o congestionamento da rede e melhorando a taxa de transferência. As falhas nas tarefas são detectadas e reatribuídas automaticamente, contribuindo para a resiliência do sistema.
O MapReduce oferece várias vantagens claras:
Porém, isso também traz desvantagens:
Você está decidindo entre o Hadoop e o Spark? Leia nosso guia sobre qual estrutura de Big Data é ideal para você.
O YARN funciona como a camada de gerenciamento de recursos do Hadoop. Ele separa o agendamento de tarefas e a alocação de recursos do modelo de processamento, ajudando o Hadoop a oferecer suporte a vários mecanismos de processamento de dados além do MapReduce.
O YARN atua como a plataforma central para gerenciar recursos de computação em todo o cluster. Ele aloca os recursos disponíveis do sistema para vários aplicativos e coordena a execução. Essa separação de preocupações ajuda o Hadoop a ser dimensionado com eficiência e abre as portas para que você ofereça suporte a outras estruturas, como Apache Spark, Hive e Tez.
O YARN apresenta três componentes:
Cada aplicativo (como um trabalho de MapReduce) tem seu próprio ApplicationMaster, o que permite melhor isolamento de falhas e rastreamento de trabalhos.
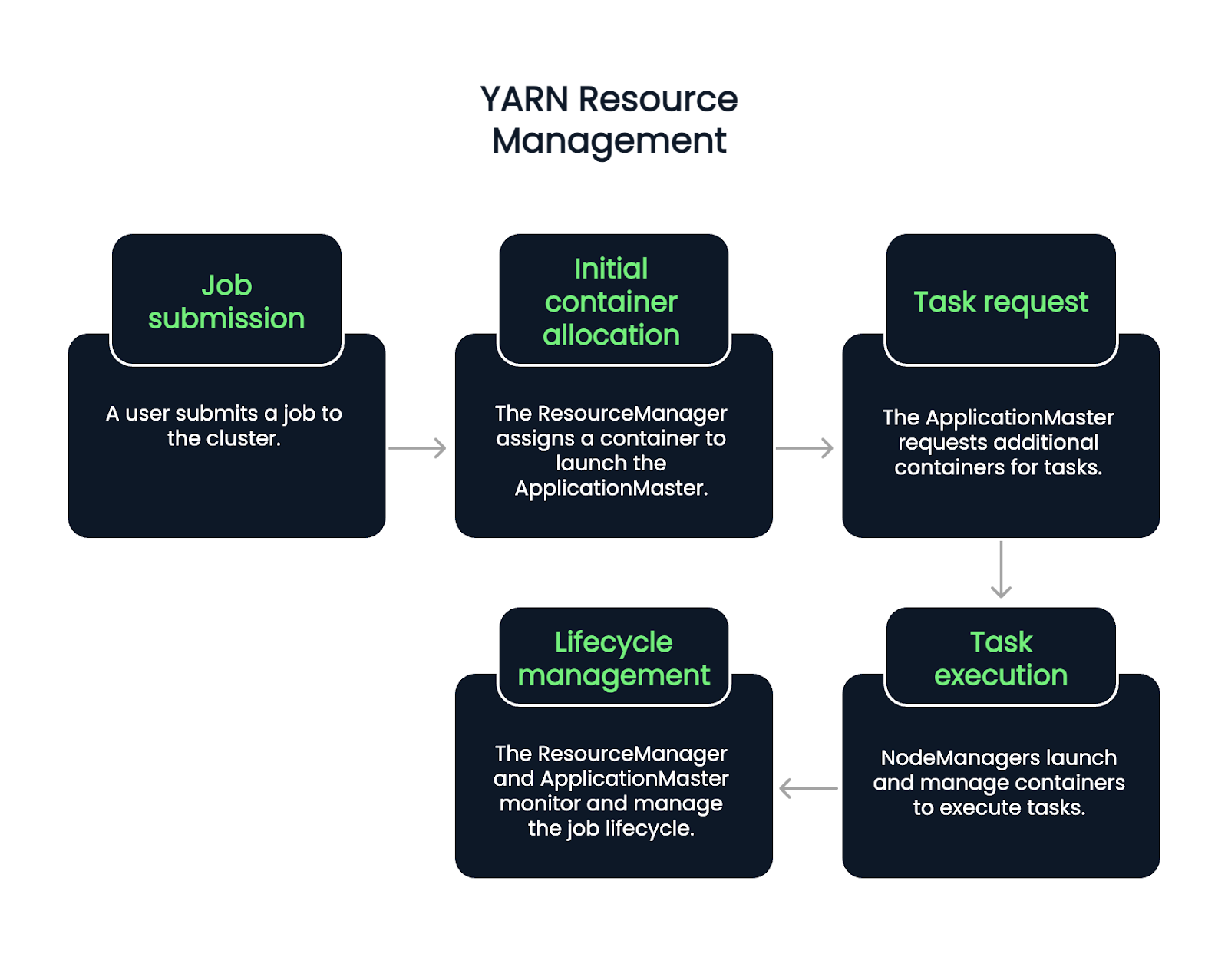
O fluxo começa quando um usuário envia um trabalho. O ResourceManager aceita o trabalho e atribui um contêiner para iniciar o ApplicationMaster. A partir daí, o ApplicationMaster solicita mais contêineres para executar tarefas, com base na carga de trabalho e na disponibilidade atuais.
Os NodeManagers iniciam e gerenciam esses contêineres, que executam tarefas individuais. Durante todo o ciclo de vida do trabalho, o ResourceManager e o ApplicationMaster cuidam do monitoramento, da recuperação de falhas e dos relatórios de conclusão. Portanto, trata-se de um processo de cinco etapas.
A cola que une todos os componentes do Hadoop é o Hadoop Common. É uma coleção de bibliotecas, arquivos de configuração e utilitários exigidos por todos os módulos.
O Hadoop Common fornece o código e as ferramentas fundamentais que permitem que o HDFS, o YARN e o MapReduce se comuniquem e se coordenem. Isso inclui bibliotecas Java, clientes do sistema de arquivos e APIs usadas em todo o ecossistema.
Ele também garante a consistência e a compatibilidade entre os módulos, permitindo que os desenvolvedores criem um conjunto compartilhado de primitivos.
A configuração adequada do Hadoop é fundamental. O Hadoop Common abriga arquivos de configuração como core-site.xml, que definem comportamentos padrão, como URIs do sistema de arquivos e configurações de E/S.
As ferramentas e os scripts de linha de comando incluídos no Hadoop Common suportam tarefas como iniciar serviços, verificar a integridade do nó e gerenciar trabalhos. A maioria dessas ferramentas é usada por administradores de sistemas e desenvolvedores para as operações diárias do cluster.
Se você usar conjuntos de dados maciços, processamento distribuído ou análise em lote, o Hadoop provavelmente será usado. Mais especificamente, o Hadoop é usado em vários setores para processar grandes volumes de dados estruturados e não estruturados. Seu design distribuído e sua flexibilidade de código aberto o tornam versátil para tarefas com uso intensivo de dados.
As organizações dos setores financeiro, de saúde, telecomunicações, comércio eletrônico e mídia social usam o Hadoop rotineiramente. Ele ajuda os bancos a detectar fraudes em tempo real, dá suporte à pesquisa genômica na área da saúde e habilita os mecanismos de recomendação no varejo on-line.
Esses cenários se beneficiam da capacidade do Hadoop de lidar com grandes conjuntos de dados com tolerância a falhas e paralelismo.
Para uma alternativa moderna e nativa da nuvem ao Hadoop, experimente o curso Introduction to Databricks, que oferece suporte ao Spark e a outras ferramentas dimensionáveis.
O Hadoop raramente funciona de forma isolada e pode se integrar a centenas de programas acessórios. Dependendo de suas preferências e do ambiente de codificação, você pode combinar o Hadoop com:
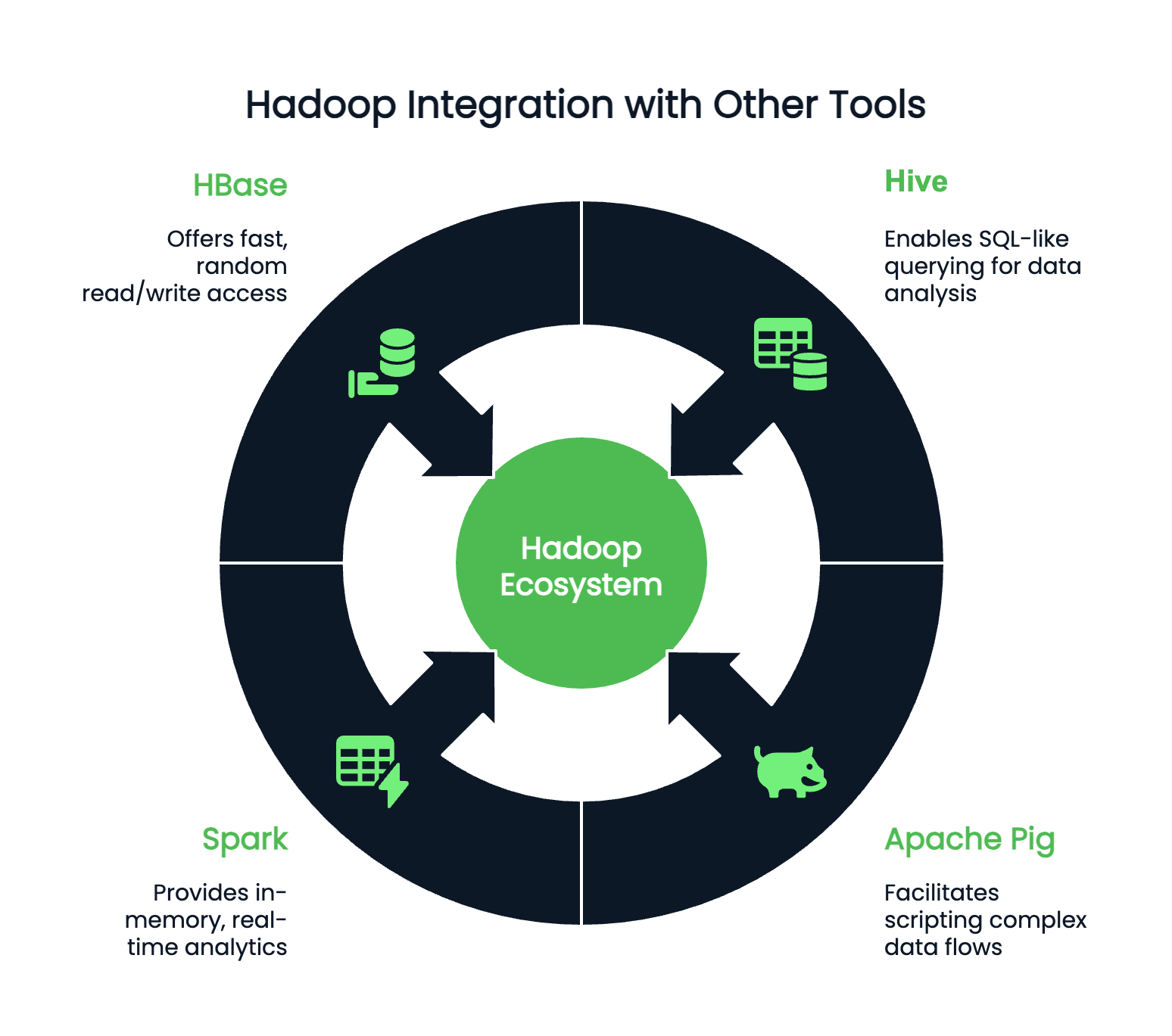
Embora o Hadoop possa não ser a palavra da moda que já foi, ele continua sendo uma tecnologia fundamental no cenário de Big Data. Entender o Hadoop ainda é incrivelmente valioso para qualquer profissional de dados que trabalhe com sistemas de grande escala. Seus componentes principais - HDFS para armazenamento, MapReduce para processamento, YARN para gerenciamento de recursos e Hadoop Common para utilitários essenciais - continuam a moldar a forma como os fluxos de trabalho de dados são projetados e dimensionados.
Antes de iniciar a implementação ou a otimização, reserve um tempo para entender como os dados são distribuídos e configurados em um cluster do Hadoop. Com esse conhecimento, você simplifica a solução de problemas e o ajuste de desempenho e abre caminho para a integração de ferramentas poderosas, como o Apache Spark e o Hive, para análises mais sofisticadas.
Para saber maissobre o processamento de Big Data, confira:
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
11 min
blog
Mike Shakhomirov
11 min
blog
DataCamp Team
12 min
blog
Joleen Bothma
9 min
Tutorial
Joleen Bothma
Tutorial
Zoumana Keita
