programa
Ingeniero de datos en Python
40 h
Hadoop y Spark son dos de los marcos más destacados en big data que manejan el procesamiento de datos a gran escala de formas muy diferentes. Mientras que a Hadoop se le puede atribuir la democratización del paradigma de la informática distribuida mediante un sólido sistema de almacenamiento llamado HDFS y un modelo computacional llamado MapReduce, Spark está cambiando las reglas del juego con su arquitectura en memoria y su modelo de programación flexible.
Este tutorial profundiza en las diferencias entre Hadoop y Spark, incluyendo su arquitectura, rendimiento, consideraciones de coste e integraciones. Al final, el lector tendrá una comprensión clara de las ventajas y desventajas de cada uno, y de los tipos de casos de uso en los que destaca cada marco; esta comprensión te ayudará con las decisiones estratégicas a medida que construyas tus soluciones de big data.
Antes de entrar en detalles concretos, exploremos los conceptos fundamentales y los orígenes de Hadoop y Spark para comprender cómo estos potentes marcos abordan los retos de los grandes datos.

Hadoop es un marco de código abierto diseñado para almacenar y procesar grandes conjuntos de datos en clusters de ordenadores. Desde su desarrollo en 2006, Hadoop ha permitido a las organizaciones manejar volúmenes de datos masivos que abrumarían a una sola máquina. Al distribuir los datos entre varios nodos, no sólo mejora la capacidad de procesamiento, sino que también proporciona redundancia, garantizando la fiabilidad del sistema incluso cuando fallan máquinas individuales.
Los componentes clave del marco Hadoop incluyen:
Una de las principales ventajas de Hadoop es su rentabilidad, ya que permite a las organizaciones utilizar hardware estándar y básico en lugar de costosos equipos especializados. Este enfoque práctico se extiende también a su filosofía de procesamiento.
El diseño orientado a lotes de Hadoop destaca en situaciones en las que el rendimiento global importa más que la velocidad de procesamiento en bruto, lo que lo hace especialmente valioso para el análisis de datos históricos y el complejo ETL (Extraer, Transformar, Cargar) que no requieren resultados inmediatos.

Apache Spark surgió en 2010 como respuesta a las limitaciones del enfoque de Hadoop para el procesamiento de big data. Desarrollado inicialmente en UC Berkeley antes de convertirse en un proyecto Apache, Spark abordó la fuerte dependencia de Hadoop MapReduce de las operaciones en disco. Su gran innovación fue la implementación del cálculo en memoria, que reduce drásticamente el tiempo de procesamiento de muchas cargas de trabajo de datos al minimizar la necesidad de leer y escribir en el disco.
Spark proporciona una plataforma unificada con varios componentes estrechamente integrados en torno a su motor central de procesamiento:
Este diseño cohesivo significa que los equipos pueden abordar diversos retos de datos utilizando un único marco, en lugar de hacer malabarismos con múltiples herramientas especializadas.
A pesar de sus diferencias, Spark y Hadoop suelen trabajar juntos como tecnologías complementarias y no como competidoras. Dado que Spark no incluye su propio sistema de almacenamiento, suele depender de HDFS de Hadoop para el almacenamiento persistente de datos.
Además, Spark puede funcionar con el gestor de recursos YARN de Hadoop, lo que facilita a las organizaciones mejorar los entornos Hadoop existentes con la potencia de procesamiento de Spark. Esta compatibilidad crea una práctica vía de actualización que permite a las empresas adoptar las ventajas de Spark sin abandonar su inversión en infraestructura Hadoop.
Al evaluar los marcos de big data, el rendimiento se convierte a menudo en un factor decisivo para las organizaciones con necesidades de procesamiento de datos sensibles al tiempo.
MapReduce de Hadoop funciona como un sistema de procesamiento basado en disco, leyendo datos del disco, procesándolos y escribiendo los resultados de nuevo en el disco entre cada etapa de cálculo. Esta E/S de disco crea una latencia significativa, sobre todo para los algoritmos iterativos que requieren múltiples pasadas sobre los mismos datos.
Aunque es eficaz para el procesamiento por lotes de conjuntos de datos masivos, este enfoque sacrifica la velocidad en favor de la fiabilidad y el rendimiento.
Spark, por el contrario, realiza los cálculos principalmente en memoria, reduciendo drásticamente la necesidad de operaciones en disco. Para muchas cargas de trabajo, en particular algoritmos iterativos como los utilizados en el aprendizaje automático, Spark puede ejecutar tareas hasta 100 veces más rápido que Hadoop MapReduce.
Esta ventaja de rendimiento es especialmente pronunciada cuando el procesamiento debe producirse casi en tiempo real o cuando los algoritmos requieren varias pasadas por el mismo conjunto de datos.
El diseño de Hadoop asume una disponibilidad de memoria limitada, lo que lo hace eficiente en memoria pero más lento. Depende en gran medida del almacenamiento en disco, lo que le permite procesar conjuntos de datos mucho mayores que la RAM disponible, intercambiando constantemente datos entre la memoria y el disco.
Este enfoque hace que Hadoop sea adecuado para procesar conjuntos de datos extremadamente grandes en clusters con recursos de memoria limitados.
Las ventajas de rendimiento de Spark provienen de su agresivo uso de la memoria. Al almacenar en caché los datos en la RAM a lo largo de las etapas de procesamiento, Spark elimina las costosas operaciones de disco. Sin embargo, esto requiere recursos de memoria suficientes para albergar conjuntos de datos de trabajo.
Cuando surgen limitaciones de memoria, la ventaja de rendimiento de Spark disminuye a medida que empieza a verter datos al disco, aunque su gestión inteligente de la memoria sigue superando normalmente al enfoque de Hadoop que da prioridad al disco.
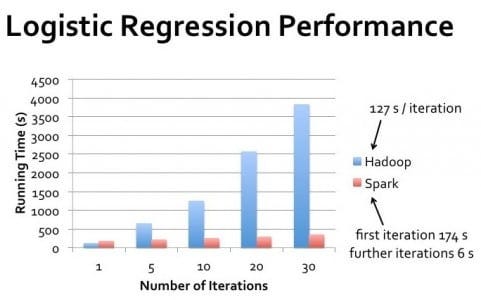
La diferencia de rendimiento en el mundo real entre Hadoop y Spark varía significativamente en función de los casos de uso específicos. Para el procesamiento por lotes de una sola pasada de conjuntos de datos masivos en los que los datos superan con creces la memoria disponible, el rendimiento de Hadoop puede acercarse al de Spark.
Sin embargo, para el procesamiento iterativo, las consultas interactivas y el procesamiento de flujos, Spark ofrece sistemáticamente un rendimiento superior.
Hay que tener en cuenta que el rendimiento no sólo depende de la velocidad bruta. Hadoop destaca en escenarios que requieren una alta tolerancia a fallos y en los que el procesamiento puede producirse en ventanas por lotes claramente definidas.
Spark funciona mejor cuando se necesitan resultados rápidos, como la exploración interactiva de datos, la analítica en tiempo real y las aplicaciones de aprendizaje automático en las que los algoritmos realizan múltiples pasadas por los conjuntos de datos.
Tanto Hadoop como Spark se basan en clusters para procesar grandes volúmenes de datos de forma eficiente, pero gestionan estos recursos de forma diferente, lo que afecta tanto al rendimiento como a la administración.
Un clúster es un conjunto de ordenadores interconectados (nodos) que funcionan juntos como un único sistema. En el procesamiento de big data, la agrupación se hace necesaria cuando los volúmenes de datos superan lo que una sola máquina puede manejar eficientemente. Al distribuir las cargas de trabajo computacionales entre varias máquinas, los clusters permiten a las organizaciones procesar petabytes de datos que, de otro modo, sería imposible gestionar.
La agrupación en clústeres también proporciona tolerancia a fallos y alta disponibilidad. Si una máquina falla, otras del clúster pueden asumir su carga de trabajo, garantizando un funcionamiento continuo. Esta resistencia es crucial para los entornos de producción, donde el tiempo de inactividad puede ser costoso.
Además, la agrupación en clústeres permite el escalado horizontal -añadir más máquinas para aumentar la potencia de procesamiento-, que suele ser más rentable que actualizar los sistemas individuales.
Para los aspirantes a profesionales en este campo, comprender la agrupación es una habilidad fundamental en ingeniería de datos.
Los clusters Hadoop siguen una arquitectura maestro-esclavo con funciones especializadas para los distintos nodos. El NameNode sirve como maestro para HDFSmanteniendo metadatos sobre ubicaciones de archivos y permisos. Los Nodos de Datos almacenan los bloques de datos reales e informan al Nodo de Nombre.
Para el procesamiento, el Gestor de Recursos asigna los recursos del clúster, mientras que los NodeManagers de las máquinas individuales ejecutan las tareas.
HDFS replica los datos en varios DataNodes, manteniendo normalmente tres copias de cada bloque de datos. Esta estrategia de replicación garantiza la disponibilidad de los datos aunque fallen nodos individuales, aunque requiere capacidad de almacenamiento adicional.
El diseño del clúster de Hadoop hace hincapié en la localización de los datos, intentando programar las tareas computacionales en los mismos nodos donde residen los datos para minimizar la transferencia de red.
Tradicionalmente, la administración de clústeres Hadoop requería una gran experiencia (los profesionales suelen prepararse para preguntas de la entrevista Hadoop para demostrar estos conocimientos), aunque las distribuciones modernas incluyen herramientas de gestión para simplificar la configuración y la supervisión.
Escalar un clúster Hadoop implica añadir nuevos nodos y reequilibrar los datos en toda la infraestructura ampliada, lo que puede ser un proceso manual que requiere una planificación cuidadosa.
Spark puede funcionar en varias configuraciones de clúster, incluido el modo autónomo, en Hadoop YARN, Apache Mesos o Kubernetes. En todas las implantaciones, Spark sigue un modelo controlador-ejecutor. El programa controlador contiene la función principal de la aplicación y crea un SparkContext que se coordina con el gestor del cluster para asignar recursos.
Una vez asignados los recursos, se lanzan los ejecutores Spark en los nodos trabajadores. Estos ejecutores son procesos de la JVM que ejecutan tareas y almacenan datos en memoria o disco. A diferencia de Hadoop, que mantiene una presencia persistente en los nodos del clúster, los ejecutores de Spark pueden asignarse y liberarse dinámicamente en función de las necesidades de la aplicación, lo que mejora potencialmente la utilización de los recursos.
Los lectores interesados pueden explorar más a fondo las capacidades de Spark a través de tutoriales prácticos como Apache Spark para el Aprendizaje Automático.
Spark no incluye su propio sistema de almacenamiento distribuido, sino que aprovecha soluciones existentes como HDFS, Amazon S3u otros sistemas de almacenamiento compatibles. Esta separación de arquitectura entre computación y almacenamiento proporciona flexibilidad, pero requiere una configuración cuidadosa para garantizar patrones óptimos de acceso a los datos.
Herramientas como Spark SQL y sparklyr ofrecen formas cómodas de interactuar con esta arquitectura.
El enfoque de Hadoop para la gestión de clusters está más centrado en la infraestructura, con una asignación de recursos relativamente estática y un enfoque en la localidad de los datos. Este diseño funciona bien para trabajos por lotes de larga duración en clusters estables en los que los nodos cambian raramente.
Sin embargo, puede ser menos sensible a las cargas de trabajo variables y requiere más intervención manual al escalar.
Spark ofrece una gestión de recursos más dinámica, especialmente cuando se ejecuta en plataformas de orquestación modernas como Kubernetes. Puede ajustar la asignación de recursos en función de las demandas actuales y liberar recursos cuando no se necesiten.
Esta elasticidad es valiosa para organizaciones con cargas de trabajo fluctuantes o infraestructuras compartidas que dan servicio a múltiples aplicaciones.
Comprender estas diferencias es crucial para los profesionales que desean obtener la certificación de certificación de Ingeniero de Datos o prepararse para preguntas de la entrevista Spark.
Para las organizaciones que se inician en el big data, las opciones de despliegue más flexibles y el modelo de programación más sencillo de Spark suelen facilitar los comienzos.
Sin embargo, en entornos con volúmenes de datos extremadamente grandes en los que la gestión del almacenamiento es una preocupación primordial, el maduro ecosistema HDFS de Hadoop sigue ofreciendo ventajas que complementan las capacidades de procesamiento de Spark. Para una comparación de Spark con otras tecnologías de streaming, los lectores pueden encontrar comparaciones como Flink vs. Spark. Chispa informativa.
Aunque en las secciones anteriores se trataron las implicaciones para el rendimiento, comprender los modelos de procesamiento fundamentales de cada marco ayuda a explicar por qué tienen una arquitectura tan diferente.
MapReduce sigue un paradigma de programación rígido con dos fases principales: mapear y reducir. La fase de mapa aplica una función a cada registro en paralelo, generando pares clave-valor intermedios.
Estos pares se someten a una fase obligatoria de barajado y ordenación, en la que se agrupan los datos con las mismas claves.
Por último, la fase de reducción agrega estos valores agrupados para producir salidas finales. Este enfoque estructurado significa que las operaciones complejas requieren encadenar varios trabajos MapReduce.
Desarrollar aplicaciones MapReduce suele implicar escribir código de bajo nivel que defina explícitamente las funciones de mapeo y reducción.
Mientras que frameworks como Apache Pig y Apache Hive proporcionan abstracciones de más alto nivel, la ejecución subyacente aún sigue el estricto patrón MapReduce, que impone limitaciones al diseño de algoritmos y a las oportunidades de optimización.
Presentación de Spark Conjuntos de Datos Distribuidos Resistentes (RDD) como su abstracción central: colecciones particionadas e inmutables que pueden rastrear su linaje para su recuperación. A diferencia de MapReduce, Spark no impone un patrón de procesamiento rígido, sino que ofrece dos tipos de operaciones: transformaciones (que crean nuevos RDD) y acciones (que devuelven valores).
Esta flexibilidad permite diversos patrones de procesamiento más allá del paradigma mapa-reducción.
Spark ha evolucionado más allá de los RDD para ofrecer abstracciones de nivel superior como marcos de datos y conjuntos de datosque proporcionan un procesamiento consciente del esquema con optimizaciones similares a las de las bases de datos relacionales. Estas abstracciones, combinadas con bibliotecas especializadas para streaming SQL, aprendizaje automáticoy procesamiento de grafos, permiten a los desarrolladores expresar flujos de trabajo complejos con mucho menos código que las implementaciones equivalentes de MapReduce, manteniendo un modelo de programación unificado en los distintos paradigmas de procesamiento.
Al evaluar los marcos de big data, las organizaciones deben considerar no sólo las capacidades técnicas, sino también las implicaciones financieras de su despliegue y funcionamiento.
Hadoop y Spark tienen preferencias de hardware fundamentalmente diferentes que repercuten en los costes de infraestructura. Hadoop se diseñó para dar prioridad al almacenamiento en disco frente a la memoria, lo que lo hace muy adecuado para hardware básico con RAM limitada pero una capacidad de disco duro considerable.
Esta arquitectura puede reducir la inversión inicial en hardware, especialmente cuando se procesan conjuntos de datos extremadamente grandes en los que las soluciones basadas en memoria serían prohibitivamente caras.
El modelo de procesamiento en memoria de Spark ofrece ventajas de rendimiento, pero requiere mucha más RAM por nodo. Un clúster Spark correctamente configurado suele exigir servidores con configuraciones de memoria considerables, a menudo de 16 GB a 256 GB por nodo, dependiendo de las características de la carga de trabajo.
Aunque los costes de la memoria han disminuido con el tiempo, este requisito aún puede aumentar los gastos de hardware en comparación con las implantaciones de Hadoop centradas en el disco.
Los costes operativos van más allá de la adquisición de hardware e incluyen el mantenimiento continuo, la electricidad, la refrigeración y el espacio del centro de datos. Los clusters Hadoop tienden a tener huellas físicas más grandes debido a su dependencia de numerosos servidores básicos con amplio almacenamiento.
Esta mayor huella se traduce en mayores costes de energía, refrigeración y espacio en el bastidor.
Los clústeres de Spark a veces pueden alcanzar las mismas capacidades de procesamiento con menos nodos debido a su uso más eficiente de los recursos informáticos, reduciendo potencialmente la huella del centro de datos y los costes asociados. Sin embargo, las máquinas de mayor especificación necesarias pueden consumir más energía por nodo, contrarrestando parcialmente este ahorro.
La complejidad de la implantación y el mantenimiento puede repercutir significativamente en el coste total de propiedad. El ecosistema de Hadoop requería tradicionalmente conocimientos especializados en programación Java y administración Unix, con ciclos de desarrollo que podían ser largos debido a la naturaleza verbosa de la programación MapReduce.
Spark ofrece API más accesibles en PythonScala, R y Java, reduciendo potencialmente el tiempo de desarrollo y los costes de personal asociados.
El modelo de programación más intuitivo puede disminuir tanto la curva de aprendizaje como el tiempo de desarrollo, permitiendo a las organizaciones implantar soluciones más rápidamente con menos personal especializado.
Para las organizaciones sensibles a los costes, los enfoques híbridos suelen ofrecer la mejor relación calidad-precio. Utilizar HDFS para el almacenamiento mientras se aprovecha Spark para el procesamiento puede combinar el almacenamiento rentable de Hadoop con la eficiencia de procesamiento de Spark. Las implementaciones basadas en la nube en servicios como AWS EMR, Azure HDInsight o Google Dataproc permiten a las organizaciones pagar sólo por los recursos utilizados, sin grandes gastos de capital por adelantado.
Las organizaciones también deben tener en cuenta los costes de escalabilidad. Tradicionalmente, Hadoop requiere intervención manual para escalar, lo que añade sobrecarga operativa. La compatibilidad de Spark con plataformas de orquestación de contenedores como Kubernetes permite un escalado más automatizado y elástico que puede ajustar mejor el aprovisionamiento de recursos a la demanda real, reduciendo potencialmente la capacidad desperdiciada.
Aquí tienes una tabla comparativa que resume sus diferencias:
|
Función |
Hadoop |
Chispa |
|
Modelo de procesamiento |
Procesamiento por lotes mediante MapReduce |
Procesamiento en memoria mediante RDDs, DataFrames y Datasets |
|
Rendimiento |
Más lento debido a la E/S de disco entre etapas |
Hasta 100 veces más rápido para cargas de trabajo iterativas y en memoria |
|
Uso de la memoria |
Centrado en el disco, requiere poca memoria |
Memoria intensiva, altos requisitos de RAM |
|
Facilidad de desarrollo |
Verboso; requiere escribir explícitamente la lógica de mapeo y reducción |
APIs de alto nivel en Python, Scala, R, Java; menos boilerplate |
|
Tolerancia a fallos |
Replicación de datos mediante HDFS |
El linaje RDD permite el recálculo en caso de fallo |
|
Procesamiento en tiempo real |
No es ideal; sólo por lotes |
Admite el procesamiento en tiempo real mediante Spark Streaming |
|
Gestor de clústeres |
YARN |
Independiente, YARN, Mesos o Kubernetes |
|
Almacenamiento |
Viene con HDFS |
Depende del almacenamiento externo (por ejemplo, HDFS, S3, GCS) |
|
Coste |
Menor coste de hardware (máquinas básicas, basadas en disco) |
Mayor coste de memoria pero mejor utilización de los recursos por carga de trabajo |
|
Lo mejor para |
Trabajos por lotes, almacenamiento a gran escala, análisis de datos históricos |
Aprendizaje automático, procesamiento de flujos, análisis interactivo |
|
Integración |
Sólido ecosistema Hadoop (Hive, Pig, etc.) |
APIs unificadas para SQL, MLlib, GraphX y Streaming en una única plataforma |
Hadoop y Spark representan enfoques complementarios para el procesamiento de big data y no competidores estrictos. Hadoop destaca por su rentable sistema de almacenamiento (HDFS) y su procesamiento por lotes para conjuntos de datos masivos en los que el rendimiento importa más que la velocidad.
Spark brilla por sus capacidades de procesamiento en memoria que ofrecen un rendimiento superior para algoritmos iterativos, análisis interactivos y necesidades de procesamiento en tiempo real.
DataCamp ofrece varios recursos si quieres saber más sobre estas dos tecnologías:
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Gus Frazer
14 min
blog
Kurtis Pykes
12 min
blog
Kurtis Pykes
15 min
Tutorial
Natassha Selvaraj
Tutorial
Olivia Smith