
Course
Big Data Fundamentals with PySpark
4 hr
65.2K
Apache Hadoop, often just called Hadoop, is a powerful open-source framework built to process and store massive datasets by distributing them across clusters of affordable, commodity hardware. Its strength lies in scalability and flexibility, enabling it to work with both structured and unstructured data.
In this post, I’ll walk through the key components that make Hadoop—how it stores, processes, and manages data at scale. By the end, you’ll have a clear picture of how this foundational technology fits into big data ecosystems.
Hadoop is not a single tool. It’s an ecosystem that includes multiple modules that work together to manage data storage, processing, and resource coordination.
Hadoop consists of four foundational modules:
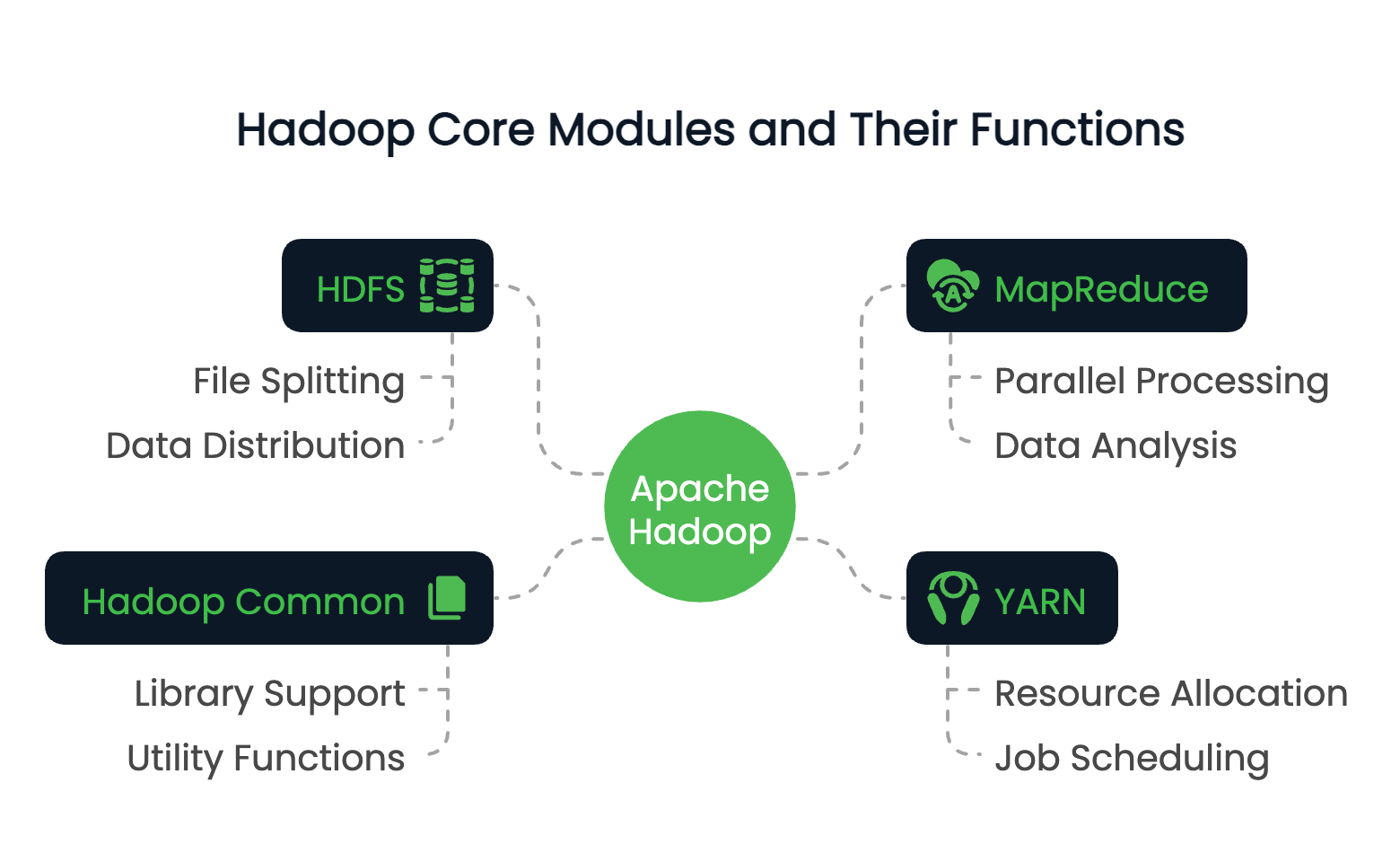
These modules work together to create a distributed computing environment capable of handling petabytes of data.
To explore how distributed data processing compares across platforms, the Big Data Fundamentals with PySpark course provides a hands-on introduction that complements your understanding of Hadoop.
The primary role of Hadoop lies in its ability to address a core challenge in big data processing, namely, scalability.
Traditional systems often struggle with datasets that exceed the capacity of a single machine, both in storage and computing. Hadoop resolves this by distributing data across many nodes and executing computations in parallel.
So Hadoop can process terabytes or even petabytes of data efficiently. Beyond its scalability, Hadoop also has a deep fault tolerance through data replication and allows organizations to build cost-effective data infrastructure using commodity hardware.
We’ve discussed the role and structure of Hadoop, now let’s look at some of Hadoop’s most valuable attributes. These include:
These features make Hadoop well-suited for batch data processing, log analysis, and ETL pipelines. Hadoop is a classic case study in distributed computing, where computation happens across multiple nodes to increase efficiency and scale.
Now, let’s look at each of the core modules of Hadoop in detail.
Want to validate your Hadoop knowledge or prep for a data role? Here are 24 Hadoop interview questions and answers for 2025 to get you started.
Of the four main components, HDFS is Hadoop’s primary storage system. It is designed to reliably store the vast amounts of data across a cluster of machines that we discussed earlier. Its architecture is set up for this type of access to large datasets and is optimized for fault tolerance, scalability, and data locality.
The HDFS architecture revolves around a master-slave model. At the top sits the NameNode, which manages metadata— essentially, the file system’s directory tree and information about each file’s location. It doesn’t store the actual data.
The DataNodes are the workhorses. They manage storage attached to the nodes and serve read/write requests from clients. Each DataNode regularly reports back to the NameNode with a heartbeat and block reports to ensure consistent state tracking.
Finally, HDFS includes a Secondary NameNode, not to be confused with a failover node. Instead, it periodically checkpoints the NameNode’s metadata to reduce startup time and memory overhead.
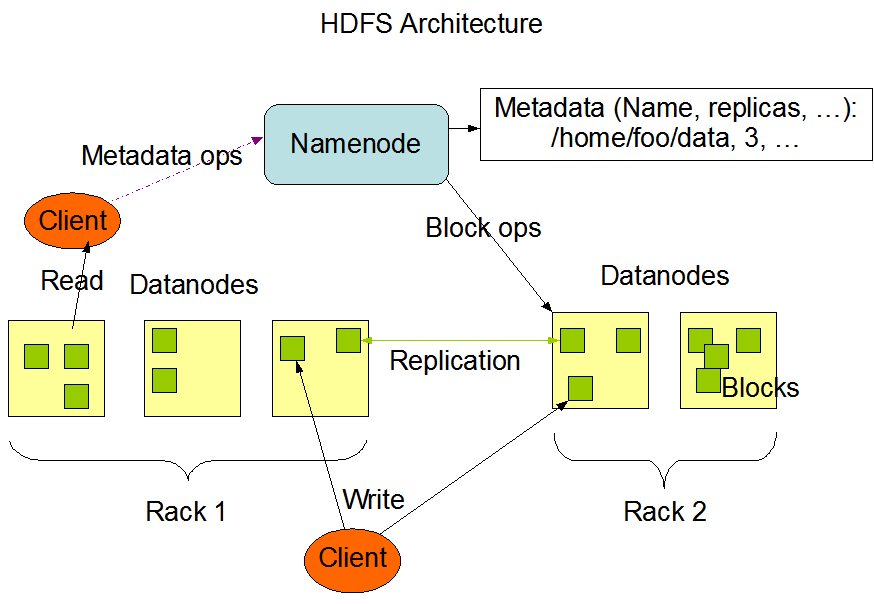
The HDFS architecture. Image source: Apache Hadoop documentation
When a file is written to HDFS, it’s broken into fixed-size 64MB blocks. Each block is then distributed across different DataNodes. This distribution strategy supports parallelism during data access and boosts fault tolerance.
Data in HDFS isn’t just stored once. Each block is replicated (the default is three copies) and spread across the cluster. During a read operation, the system pulls data from the nearest available replica to maximize throughput and minimize latency. Writes go to one replica first and then propagate to the others, ensuring durability without immediate bottlenecks.
This block-level design also allows HDFS to scale horizontally. New nodes can be added to the cluster, and the system will rebalance data to use additional capacity.
For comparison with other big data formats, explore how Apache Parquet optimizes columnar storage for analytics workloads.
HDFS is built with failure in mind. In large distributed systems, node failures are expected, not exceptional. HDFS ensures data availability through its replication mechanism. If a DataNode goes down, the NameNode detects the failure via missed heartbeats and schedules the replication of lost blocks to healthy nodes.
Plus, the system constantly monitors block health and initiates replication as needed. The redundant storage strategy, combined with proactive monitoring, ensures that no single point of failure can compromise data integrity or access.
Next up is Hadoop’s processing engine, MapReduce. It allows for distributed computation across large datasets by breaking down tasks into smaller, independent operations that can be executed in parallel.
The model simplifies complex data transformations and is especially suited for batch processing in a distributed environment.
MapReduce follows a two-phase programming model: the Map and Reduce phases.
During the Map phase, the input dataset is divided into smaller chunks, and each chunk is processed to produce key-value pairs. These intermediate results are then shuffled and sorted before being passed to the Reduce phase, where they are aggregated or transformed into final outputs.
This model is highly effective for tasks like counting word frequencies, filtering logs, or joining datasets at scale.
Developers implement custom logic through map() and reduce() functions, which the framework orchestrates across the cluster.
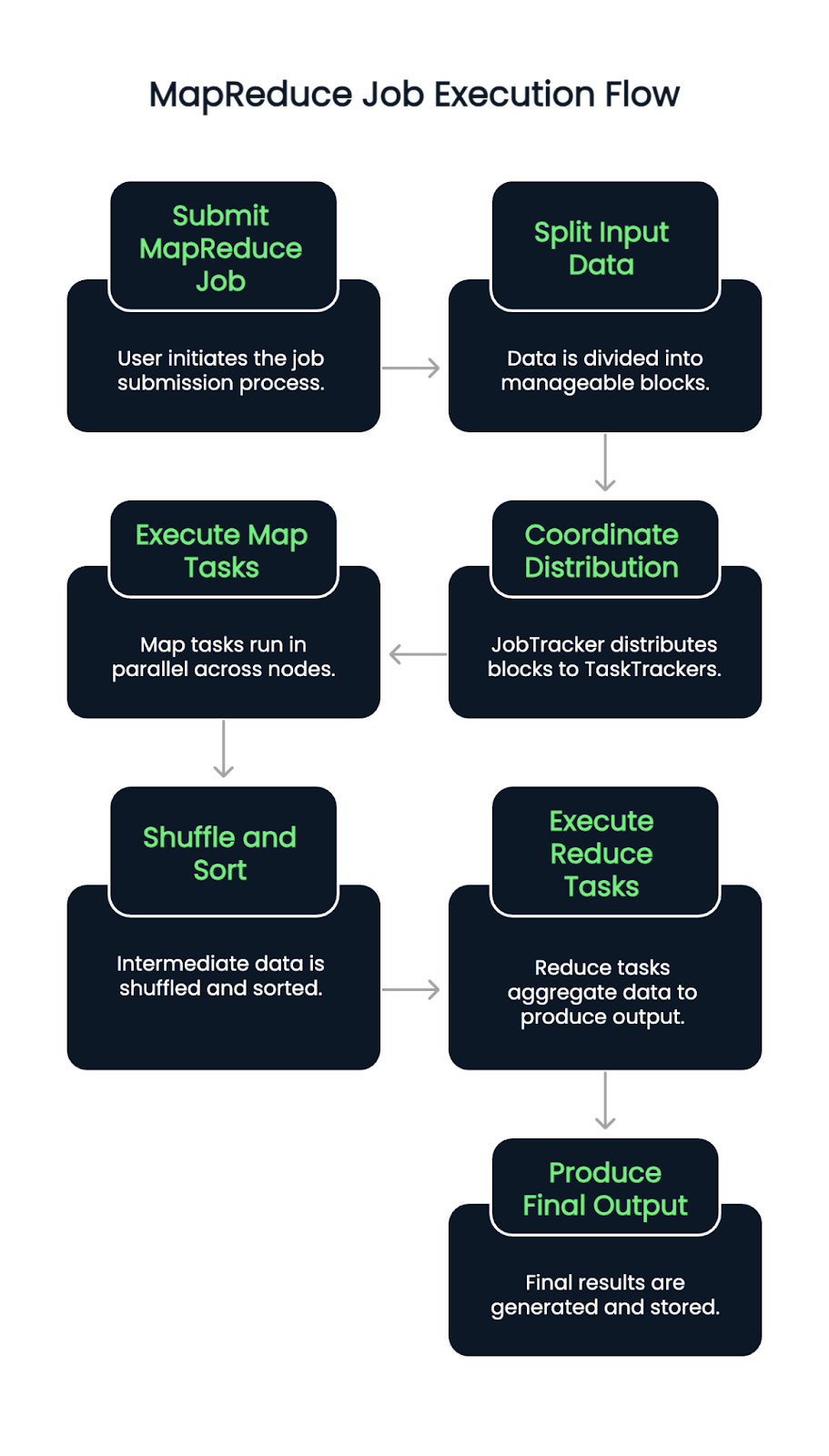
When a MapReduce job is submitted, the input data is first split into blocks. A JobTracker (or ResourceManager in YARN-enabled versions) then coordinates the distribution of these blocks across available TaskTrackers or NodeManagers.
The Map tasks execute in parallel across nodes, reading input splits and emitting intermediate key-value pairs. These pairs are then shuffled and sorted automatically. Once this phase is complete, the Reduce tasks begin, pulling in grouped data and applying aggregation logic to produce the final output.
The process guarantees data locality by assigning tasks close to where the data resides, minimizing network congestion and improving throughput. Task failures are detected and reassigned automatically, contributing to system resilience.
MapReduce offers several clear advantages:
But, it also comes with trade-offs:
Deciding between Hadoop and Spark? Read our guide on which Big Data framework is right for you.
YARN serves as Hadoop’s resource management layer. It separates job scheduling and resource allocation from the processing model, helping Hadoop support multiple data processing engines beyond MapReduce.
YARN acts as the central platform for managing compute resources across the cluster. It allocates available system resources to several applications and coordinates execution. This separation of concerns helps Hadoop scale efficiently and opens the door to support other frameworks like Apache Spark, Hive, and Tez.
YARN introduces three components:
Each application (like a MapReduce job) has its own ApplicationMaster, which allows for better fault isolation and job tracking.
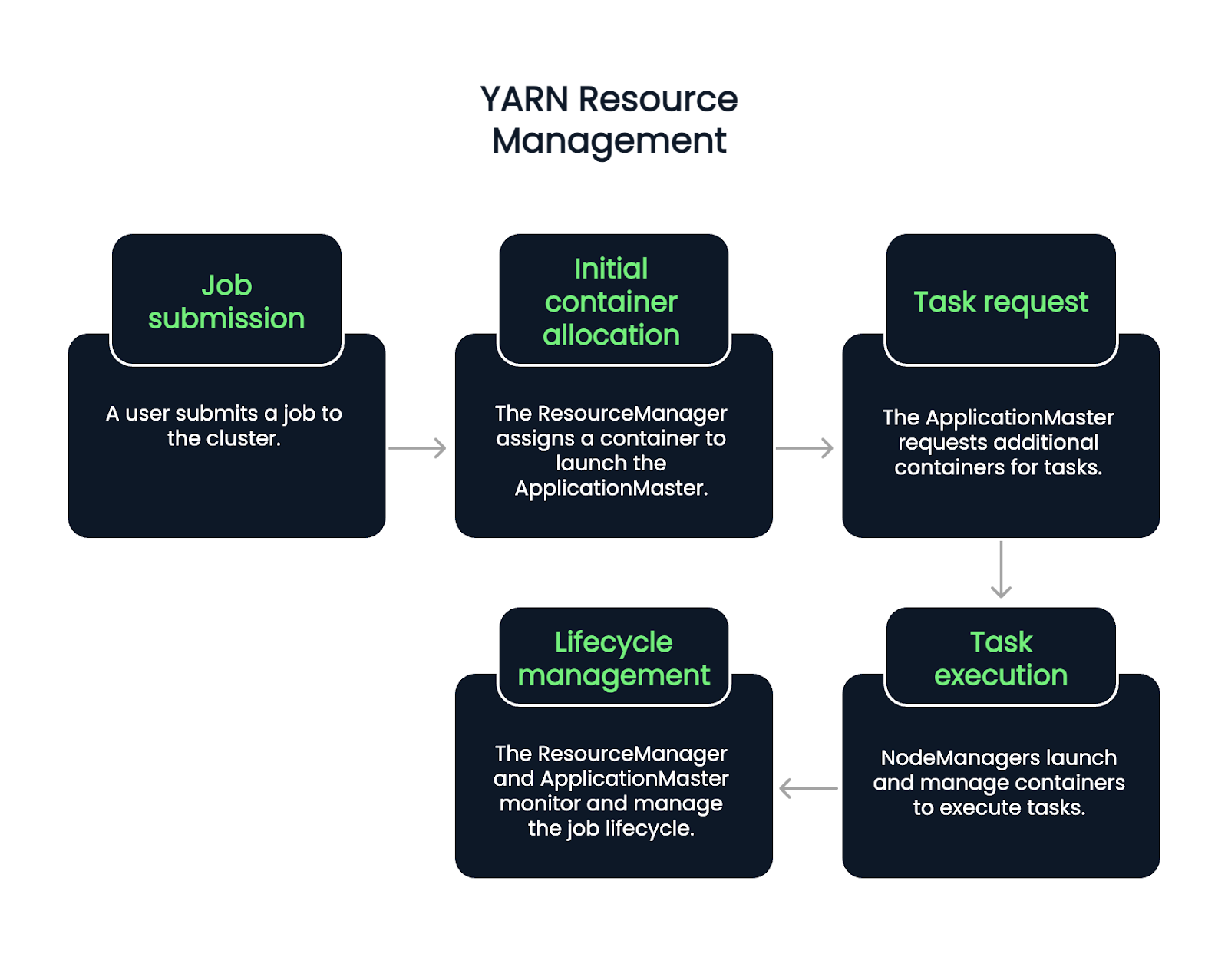
The flow begins when a user submits a job. The ResourceManager accepts the job and assigns a container to start the ApplicationMaster. From there, the ApplicationMaster requests more containers to execute tasks, based on the current workload and availability.
NodeManagers launch and manage these containers, which run individual tasks. Throughout the job lifecycle, the ResourceManager and ApplicationMaster handle monitoring, failure recovery, and completion reporting. So, it’s about a five-step process.
The glue that pulls all Hadoop’s components together is Hadoop Common. It’s a collection of libraries, configuration files, and utilities required by all modules.
Hadoop Common provides the foundational code and tools that allow HDFS, YARN, and MapReduce to communicate and coordinate. This includes Java libraries, file system clients, and APIs used across the ecosystem.
It also ensures consistency and compatibility between modules, allowing developers to build on a shared set of primitives.
Proper configuration of Hadoop is critical. Hadoop Common houses configuration files like core-site.xml, which define default behaviors such as filesystem URIs and I/O settings.
Command-line tools and scripts included in Hadoop Common support tasks like starting services, checking node health, and managing jobs. Most of these tools, system administrators, and developers rely on for day-to-day cluster operations.
If it uses massive datasets, distributed processing, or batch analytics, Hadoop is likely used. More specifically, Hadoop is used across various industries to process massive volumes of structured and unstructured data. Its distributed design and open-source flexibility make it versatile for data-intensive tasks.
Organizations in finance, healthcare, telecommunications, e-commerce, and social media routinely use Hadoop. It helps banks detect fraud in real time, supports genomic research in healthcare, and enables recommendation engines in online retail.
These scenarios benefit from Hadoop’s ability to handle large datasets with fault tolerance and parallelism.
For a modern, cloud-native alternative to Hadoop, try the Introduction to Databricks course, which supports Spark and other scalable tools.
Hadoop rarely works in isolation and can integrate with hundreds of accessory programs. Depending on your preferences and coding environment, you might pair Hadoop with:
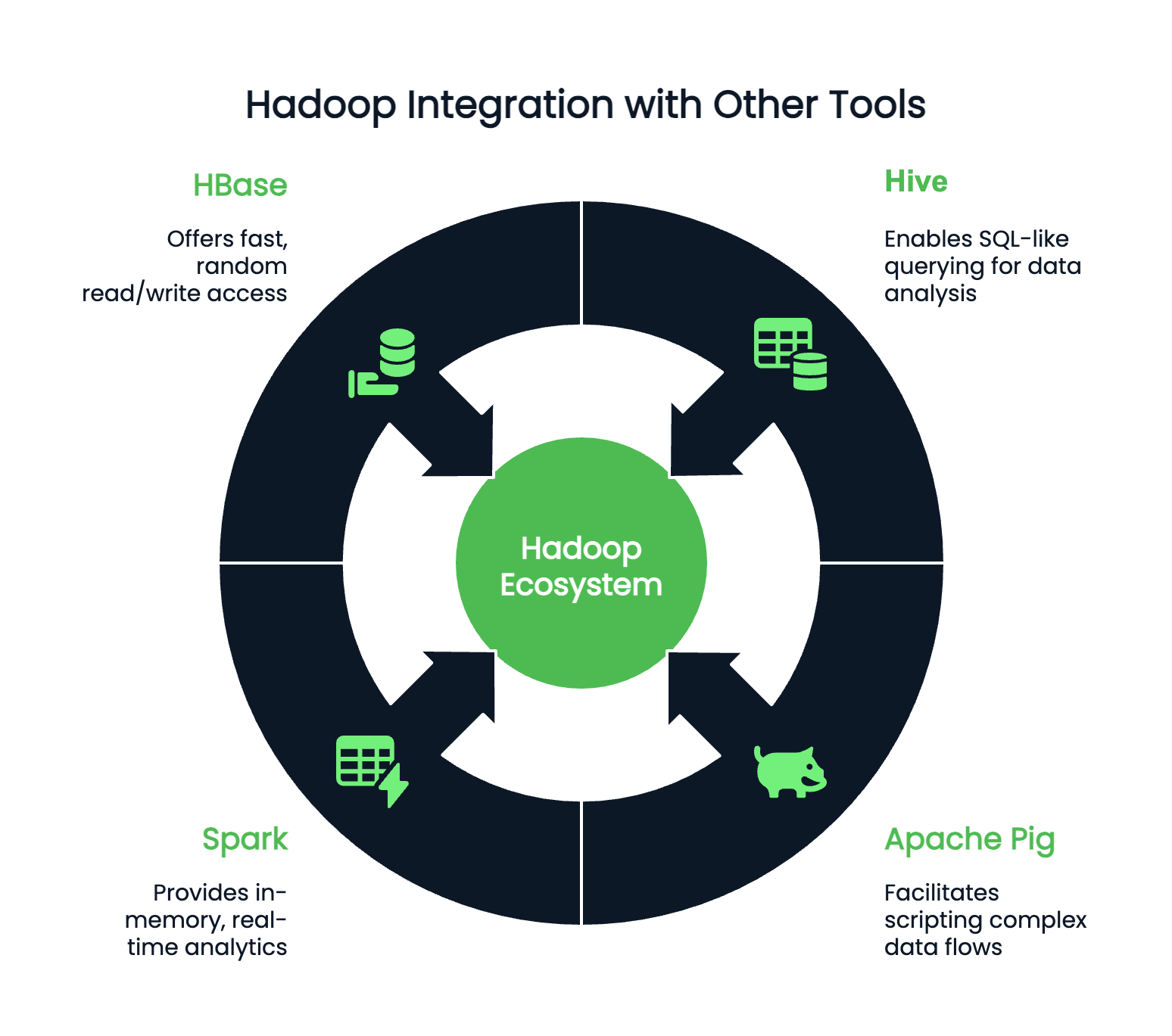
While Hadoop may not be the buzzword it once was, it remains a foundational technology in the big data landscape. Understanding Hadoop is still incredibly valuable for any data professional working with large-scale systems. Its core components—HDFS for storage, MapReduce for processing, YARN for resource management, and Hadoop Common for essential utilities—continue to shape how data workflows are designed and scaled.
Before jumping into deployment or optimization, take the time to understand how data is distributed and configured within a Hadoop cluster. That knowledge simplifies troubleshooting and performance tuning and paves the way for integrating powerful tools like Apache Spark and Hive for more sophisticated analytics.
For more on big data processing, check out:
Learn more about data engineering with these courses!
Course
Course
Course
blog
Josep Ferrer
11 min
blog
Bex Tuychiev
blog
Marie Fayard
8 min
blog
Bex Tuychiev
12 min
blog
Kurtis Pykes
15 min
Tutorial
DataCamp Team