
Kurs
Grundlagen von Big Data mit PySpark
4 Std.
65.2K
Apache Hadoop, oft auch nur Hadoopgenannt , ist ein leistungsfähiges Open-Source-Framework, das für die Verarbeitung und Speicherung riesiger Datensätze entwickelt wurde, indem es diese über Cluster aus erschwinglicher Standardhardware verteilt. Seine Stärke liegt in der Skalierbarkeit und Flexibilität, so dass es sowohl mit strukturierten als auch mit unstrukturierten Daten arbeiten kann.
In diesem Beitrag gehe ich auf die wichtigsten Komponenten von Hadoop ein - wie es Daten in großem Umfang speichert, verarbeitet und verwaltet. Am Ende wirst du ein klares Bild davon haben, wie diese grundlegende Technologie in Big-Data-Ökosysteme passt.
Hadoop ist kein einzelnes Tool. Es ist ein Ökosystem, das mehrere Module umfasst, die zusammenarbeiten, um die Datenspeicherung, die Verarbeitung und die Koordination der Ressourcen zu verwalten.
Hadoop besteht aus vier grundlegenden Modulen:
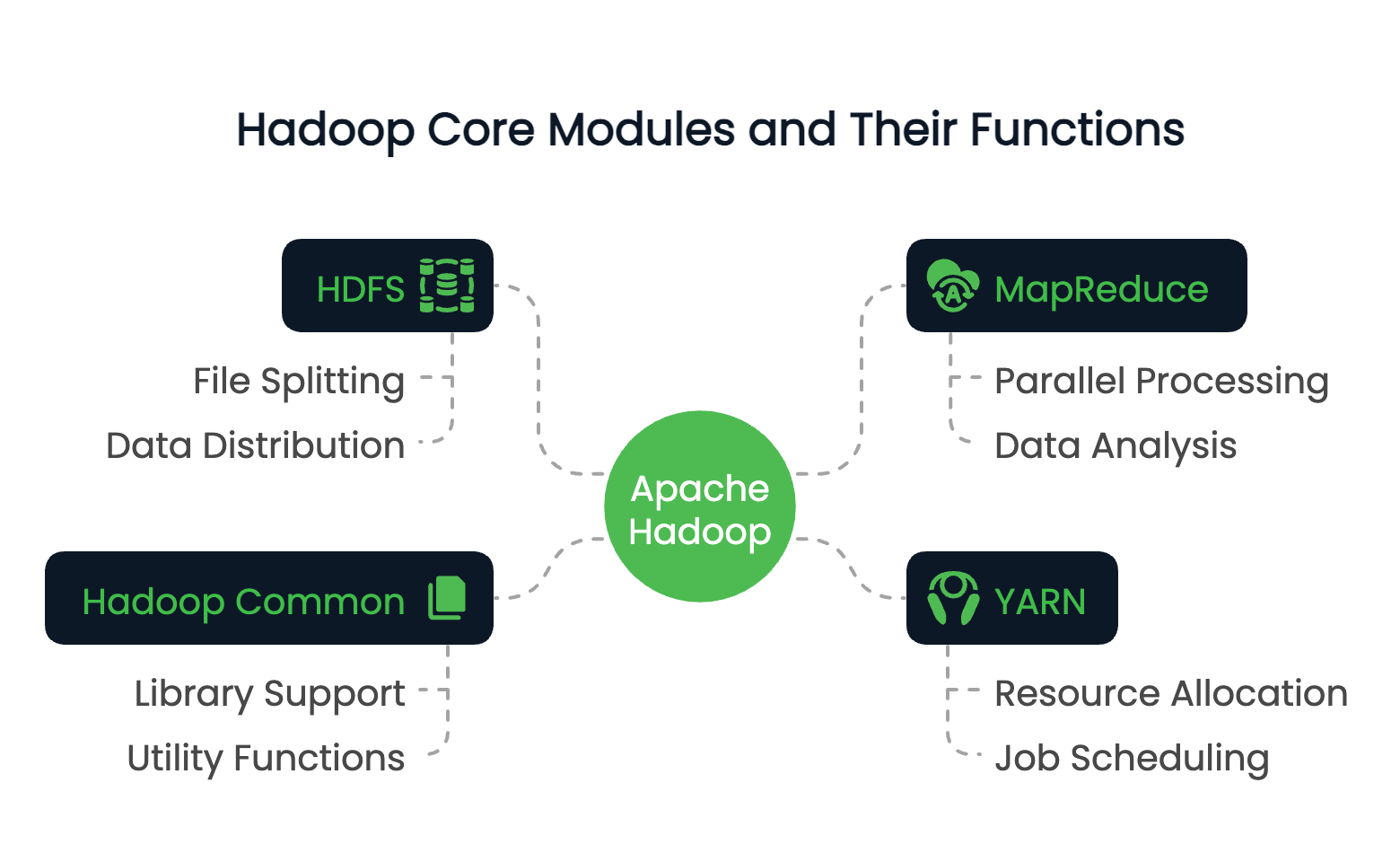
Diese Module arbeiten zusammen, um eine verteilte Datenverarbeitungsumgebung zu schaffen, die Petabytes an Daten verarbeiten kann.
Um herauszufinden, wie die verteilte Datenverarbeitung auf verschiedenen Plattformen funktioniert, bietet der Kurs Big Data Fundamentals with PySpark eine praktische Einführung, die dein Verständnis von Hadoop ergänzt.
Die Hauptrolle von Hadoop liegt in seiner Fähigkeit, eine zentrale Herausforderungbei derVerarbeitung großer Datenmengen zu bewältigen, nämlich die Skalierbarkeit.
Herkömmliche Systeme haben oft mit Datenmengen zu kämpfen, die die Kapazität einer einzelnen Maschine übersteigen, sowohl was die Speicherung als auch was die Rechenleistung angeht. Hadoop löst dieses Problem, indem es die Daten auf viele Knotenpunkte verteilt und die Berechnungen parallel ausführt.
Hadoop kann also Terabytes oder sogar Petabytes an Daten effizient verarbeiten. Neben seiner Skalierbarkeit verfügt Hadoop durch die Datenreplikation auch über eine hohe Fehlertoleranz und ermöglicht es Unternehmen, eine kostengünstige Dateninfrastruktur mit Standardhardware aufzubauen.
Wir haben die Rolle und die Struktur von Hadoop besprochen, jetzt wollen wir uns einige der wertvollsten Eigenschaften von Hadoop ansehen. Dazu gehören:
Dank dieser Funktionen eignet sich Hadoop besonders gut für die Batch-Datenverarbeitung, die Log-Analyse und ETL-Pipelines. Hadoop ist ein klassischesBeispiel für verteiltes Rechnen, bei dem die Berechnungen auf mehreren Knotenpunkten stattfinden, um die Effizienz und Skalierbarkeit zu erhöhen.
Schauen wir uns nun jedes der Kernmodule von Hadoop im Detail an.
Du willst deine Hadoop-Kenntnisse auffrischen oder dich auf eine Rolle im Datenbereich vorbereiten? Hier sind 24 Hadoop-Interviewfragen und -Antworten für 2025, die dir den Einstieg erleichtern.
Von den vier Hauptkomponenten ist HDFS das primäre Speichersystem von Hadoop. Es wurde entwickelt, um die riesigen Datenmengen in einem Cluster von Rechnern zuverlässig zu speichern, über die wir bereits gesprochen haben. Seine Architektur ist für diese Art des Zugriffs auf große Datenmengen ausgelegt und für Fehlertoleranz, Skalierbarkeit und Datenlokalisierung optimiert.
Die HDFS-Architektur basiert auf einem Master-Slave-Modell. Ganz oben sitzt der NameNode, der die Metadaten verwaltet - im Wesentlichen den Verzeichnisbaum des Dateisystems und Informationen über den Speicherort der einzelnen Dateien. Sie speichert nicht die eigentlichen Daten.
Die DataNodes sind die Arbeitstiere. Sie verwalten den an die Knotenpunkte angeschlossenen Speicher und bedienen die Lese- und Schreibanfragen der Kunden. Jeder DataNode meldet sich regelmäßig mit einem Heartbeat und Blockreports beim NameNode zurück, um eine konsistente Statusverfolgung zu gewährleisten.
Schließlich gibt es in HDFS einen Secondary NameNode, nicht zu verwechseln mit einem Failover Node. Stattdessen werden die Metadaten des NameNode in regelmäßigen Abständen überprüft, um die Startzeit und den Speicherbedarf zu reduzieren.
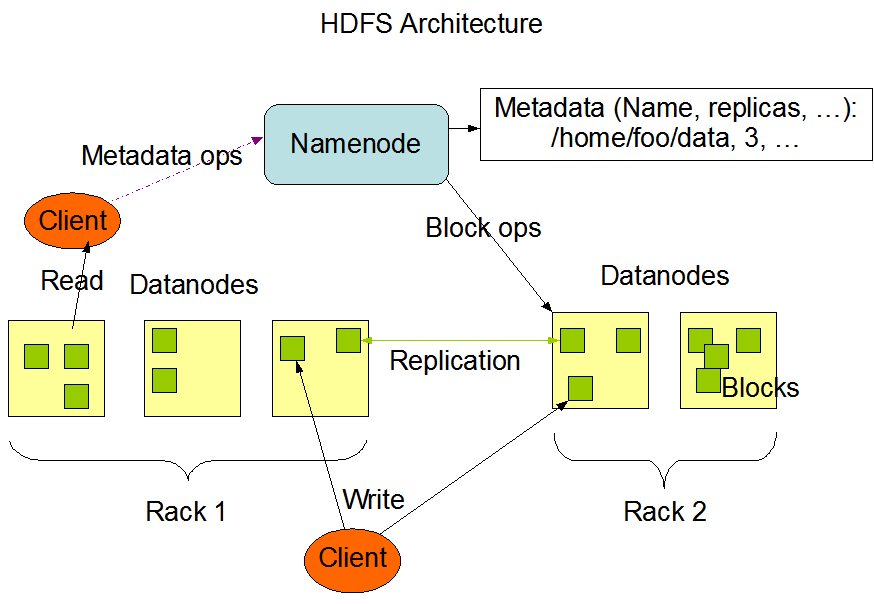
Die HDFS-Architektur. Bildquellee: Apache Hadoop Dokumentation
Wenn eine Datei in das HDFS geschrieben wird, wird sie in Blöckemit einer festen Größe von 64 MB unterteilt. Jeder Block wird dann auf verschiedene DataNodes verteilt. Diese Verteilungsstrategie unterstützt die Parallelität beim Datenzugriff und erhöht die Fehlertoleranz.
Die Daten im HDFS werden nicht nur einmal gespeichert. Jeder Block wird repliziert (die Standardeinstellung sind drei Kopien) und über den Cluster verteilt. Bei einem Lesevorgang zieht das System die Daten von der nächstgelegenen verfügbaren Replik ab, um den Durchsatz zu maximieren und die Latenzzeit zu minimieren. Schreibvorgänge gehen zuerst an eine Replik und werden dann an die anderen weitergegeben, um die Haltbarkeit ohne unmittelbare Engpässe zu gewährleisten.
Durch dieses Block-Level-Design kann HDFS auch horizontal skaliert werden. Neue Knoten können dem Cluster hinzugefügt werden, und das System gleicht die Daten neu ab, um die zusätzliche Kapazität zu nutzen.
Zum Vergleich mit anderen Big-Data-Formaten erfährst du, wie Apache Parquetdie kolumnare Speicherung für analytische Workloads optimiert.
HDFS ist auf Fehler ausgelegt. In großen verteilten Systemen sind Ausfälle von Knotenpunkten keine Ausnahme, sondern zu erwarten. HDFS stellt die Datenverfügbarkeit durch seinen Replikationsmechanismus sicher. Wenn ein DataNode ausfällt, erkennt der NameNode den Ausfall über fehlende Heartbeats und plant die Replikation der verlorenen Blöcke auf gesunde Knoten.
Außerdem überwacht das System ständig den Zustand der Blöcke und leitet bei Bedarf eine Replikation ein. Die redundante Speicherstrategie in Kombination mit proaktiver Überwachung stellt sicher, dass kein einzelner Ausfallpunkt die Datenintegrität oder den Zugriff gefährden kann.
Als Nächstes kommt die Verarbeitungsmaschine von Hadoop, MapReduce. Sie ermöglicht verteilte Berechnungen über große Datenmengen, indem sie Aufgaben in kleinere, unabhängige Operationen aufteilt, die parallel ausgeführt werden können.
Das Modell vereinfacht komplexe Datentransformationen und ist besonders für die Stapelverarbeitung in einer verteilten Umgebung geeignet.
MapReduce folgt einem zweiphasigen Programmiermodell: Die Map und Reduzieren Phasen.
In der Map-Phase wird der Eingabedatensatz in kleinere Chunks unterteilt, und jeder Chunk wird verarbeitet, um Schlüssel-Wert-Paare zu erzeugen. Diese Zwischenergebnisse werden dann gemischt und sortiert, bevor sie an die Reduce-Phase weitergeleitet werden, wo sie aggregiert oder in endgültige Ergebnisse umgewandelt werden.
Dieses Modell ist sehr effektiv für Aufgaben wie das Zählen von Worthäufigkeiten, das Filtern von Protokollen oder das Zusammenführen von Datensätzen in großem Umfang.
Entwickler implementieren benutzerdefinierte Logik über map() und reduce() Funktionen, die das Framework im gesamten Cluster orchestriert.
Wenn ein MapReduce-Job eingereicht wird, werden die Eingabedaten zunächst in Blöcke aufgeteilt. Ein JobTracker (oder ResourceManager in YARN-fähigen Versionen) koordiniert dann die Verteilung dieser Blöcke auf die verfügbaren TaskTracker oder NodeManager.
Die Map-Aufgaben werden parallel über die Knoten hinweg ausgeführt, wobei sie Eingabesplits lesen und Schlüssel-Wert-Paare ausgeben. Diese Paare werden dann automatisch gemischt und sortiert. Sobald diese Phase abgeschlossen ist, beginnen die Reduce-Aufgaben, bei denen gruppierte Daten herangezogen werden und eine Aggregationslogik angewendet wird, um die endgültige Ausgabe zu erzeugen.
Das Verfahren garantiert die Lokalisierung der Daten, indem es Aufgaben in der Nähe der Daten zuweist, wodurch die Überlastung des Netzwerks minimiert und der Durchsatz verbessert wird. Ausfälle von Aufgaben werden automatisch erkannt und neu zugewiesen und tragen so zur Ausfallsicherheit des Systems bei.
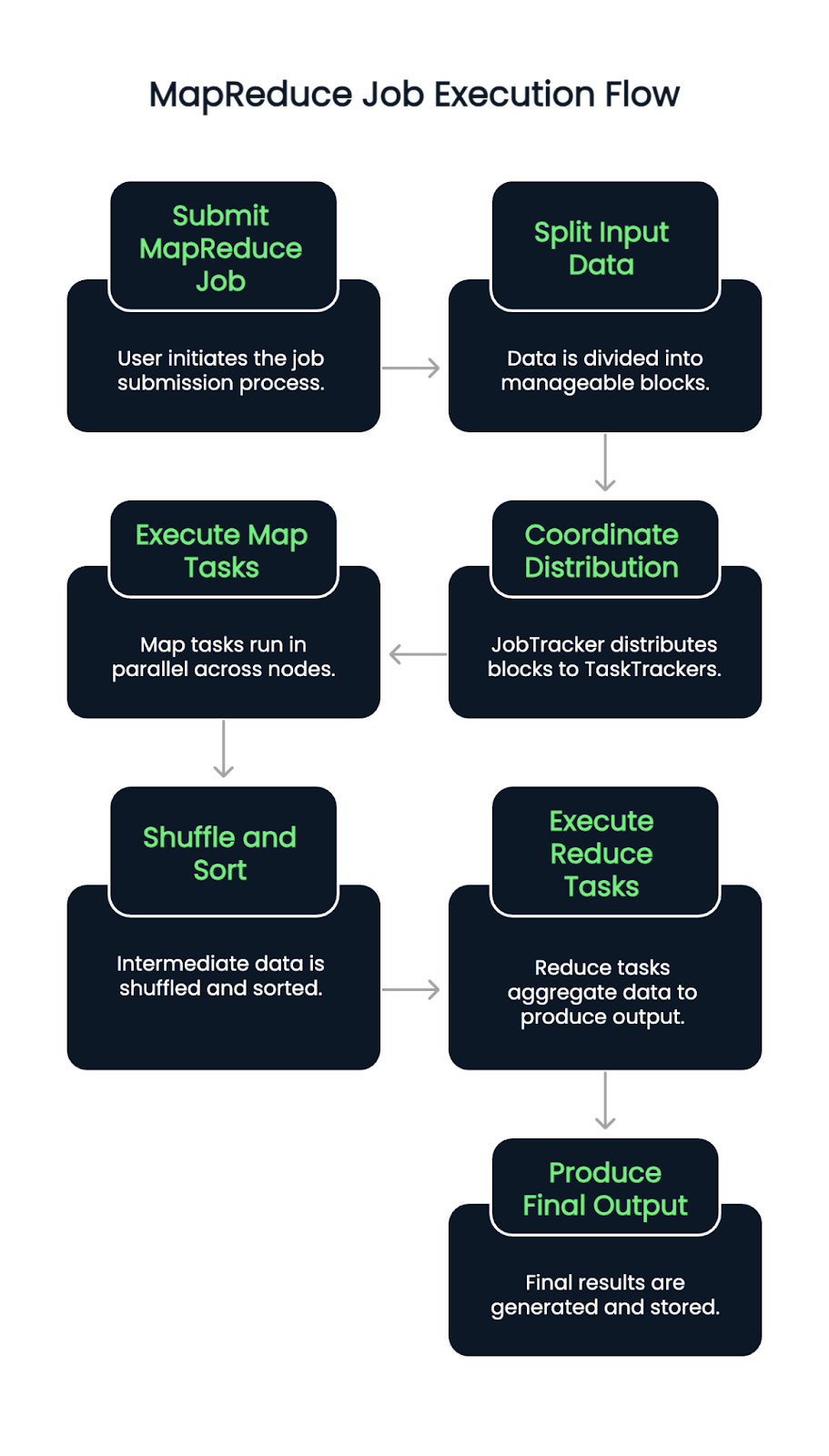
MapReduce bietet mehrere klare Vorteile:
Aber es bringt auch Nachteile mit sich:
Die Entscheidung zwischen Hadoop und Spark? Lies unseren Leitfaden darüber, welches Big-Data-Framework das richtige für dich ist.
YARN dient als Hadoops Ressourcenmanagementschicht. Es trennt die Auftragsplanung und Ressourcenzuweisung vom Verarbeitungsmodell und hilft Hadoop dabei, mehrere Datenverarbeitungs-Engines über MapReduce hinaus zu unterstützen.
YARN fungiert als zentrale Plattform für die Verwaltung der Rechenressourcen im gesamten Cluster. Er teilt die verfügbaren Systemressourcen mehreren Anwendungen zu und koordiniert die Ausführung. Diese Trennung hilft Hadoop bei der effizienten Skalierung und öffnet die Tür zur Unterstützung anderer Frameworks wie Apache Spark, Hive und Tez.
YARN führt drei Komponenten ein:
Jede Anwendung (wie ein MapReduce-Job) hat ihren eigenen ApplicationMaster, was eine bessere Fehlerisolierung und Jobverfolgung ermöglicht.
Der Fluss beginnt, wenn ein Nutzer einen Auftrag einreicht. Der ResourceManager nimmt den Auftrag an und weist einen Container zu, um den ApplicationMaster zu starten. Von dort aus fordert der ApplicationMaster je nach aktueller Arbeitslast und Verfügbarkeit weitere Container zur Ausführung von Aufgaben an.
NodeManager starten und verwalten diese Container, die einzelne Aufgaben ausführen. Während des gesamten Lebenszyklus eines Auftrags kümmern sich der ResourceManager und der ApplicationMaster um die Überwachung, die Wiederherstellung von Fehlern und die Berichterstattung über den Abschluss. Es handelt sich also um einen fünfstufigen Prozess.
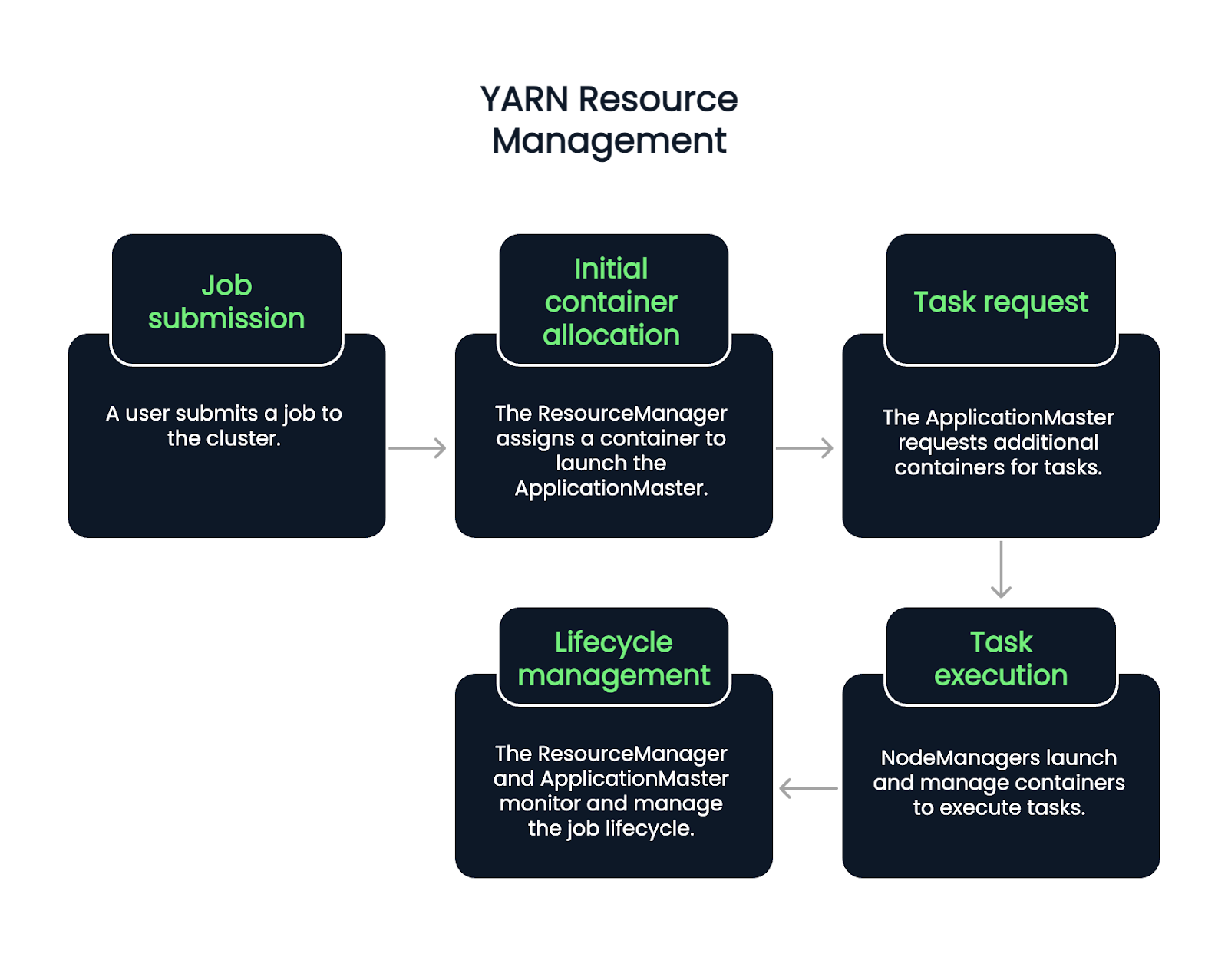
Der Klebstoff, der alle Komponenten von Hadoop zusammenhält, ist Hadoop Common. Es ist eine Sammlung von Bibliotheken, Konfigurationsdateien und Dienstprogrammen, die von allen Modulen benötigt werden.
Hadoop Common stellt den grundlegenden Code und die Werkzeuge bereit, mit denen HDFS, YARN und MapReduce kommunizieren und sich koordinieren können. Dazu gehören Java-Bibliotheken, Dateisystem-Clients und APIs, die im gesamten Ökosystem verwendet werden.
Außerdem sorgt es für Konsistenz und Kompatibilität zwischen den Modulen und ermöglicht es Entwicklern, auf einem gemeinsamen Satz von Primitiven aufzubauen.
Die korrekte Konfiguration von Hadoop ist entscheidend. Hadoop Common beherbergt Konfigurationsdateien wie core-site.xml, die Standardverhaltensweisen wie Dateisystem-URIs und E/A-Einstellungen festlegen.
Die in Hadoop Common enthaltenen Befehlszeilentools und Skripte unterstützen Aufgaben wie das Starten von Diensten, die Überprüfung des Zustands von Knoten und die Verwaltung von Jobs. Die meisten dieser Tools werden von Systemadministratoren und Entwicklern für den alltäglichen Clusterbetrieb genutzt.
Wenn es um große Datenmengen, verteilte Verarbeitung oder Batch-Analysen geht, wird wahrscheinlich Hadoop verwendet. Hadoop wird in verschiedenen Branchen eingesetzt, um große Mengen an strukturierten und unstrukturierten Daten zu verarbeiten. Sein verteiltes Design und seine Open-Source-Flexibilität machen es vielseitig für datenintensive Aufgaben einsetzbar.
Unternehmen aus den Bereichen Finanzen, Gesundheitswesen, Telekommunikation, E-Commerce und soziale Medien nutzen Hadoop routinemäßig. Sie hilft Banken, Betrug in Echtzeit aufzudecken, unterstützt die Genomforschung im Gesundheitswesen und ermöglicht Empfehlungsmaschinen im Online-Handel.
Diese Szenarien profitieren von der Fähigkeit von Hadoop, große Datenmengen mit Fehlertoleranz und Parallelität zu verarbeiten.
Wenn du eine moderne, Cloud-native Alternative zu Hadoop suchst, solltest du den Kurs Introduction to Databricks besuchen, der Spark und andere skalierbare Tools unterstützt.
Hadoop arbeitet selten isoliert und kann mit Hunderten von Zusatzprogrammen integriert werden. Je nach deinen Vorlieben und deiner Programmierumgebung kannst du Hadoop mit anderen Programmen kombinieren:
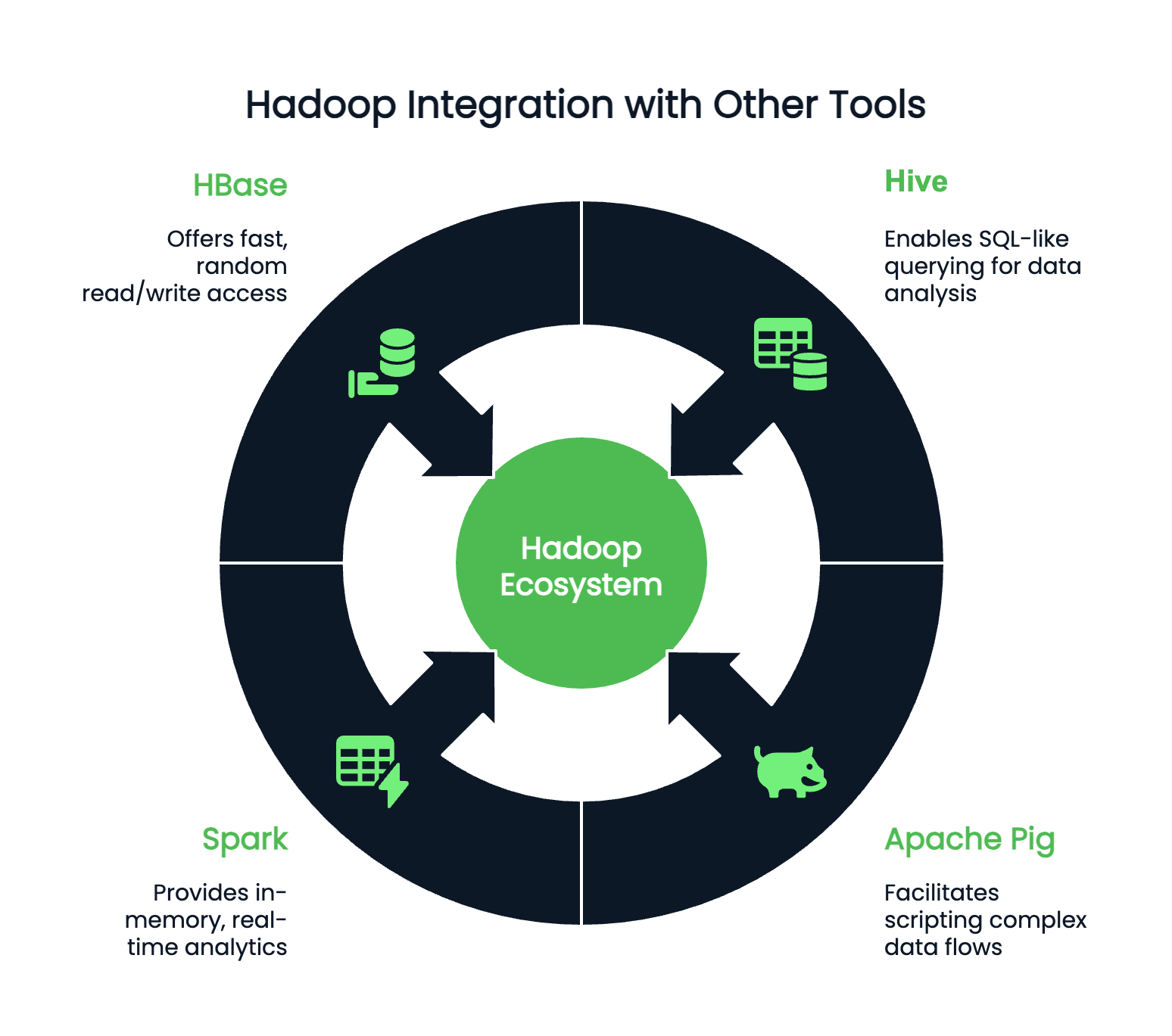
Auch wenn Hadoop nicht mehr das Schlagwort ist, das es einmal war, bleibt es eine grundlegende Technologie in der Big-Data-Landschaft. Ein Verständnis von Hadoop ist nach wie vor unglaublich wertvoll für jeden Datenexperten, der mit großen Systemen arbeitet. Seine Kernkomponenten - HDFS für die Speicherung, MapReduce für die Verarbeitung, YARN für die Ressourcenverwaltung und Hadoop Common für wichtige Hilfsprogramme - prägen nach wie vor die Art und Weise, wie Daten-Workflows entworfen und skaliert werden.
Bevor du mit der Implementierung oder Optimierung beginnst, solltest du dir die Zeit nehmen, um zu verstehen, wie die Daten in einem Hadoop-Cluster verteilt und konfiguriert werden. Dieses Wissen vereinfacht die Fehlerbehebung und Leistungsoptimierung und ebnet den Weg für die Integration leistungsstarker Tools wie Apache Spark und Hive für anspruchsvollere Analysen.
Mehrüber die Verarbeitung von Big Data erfährst du hier:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
