
Cours
Principes fondamentaux des mégadonnées avec PySpark
4 h
65.2K
Apache Hadoop, souvent appelé Hadoop, est un puissant cadre open-source conçu pour traiter et stocker d'énormes ensembles de données en les répartissant sur des grappes de matériel de base abordable. Sa force réside dans son évolutivité et sa flexibilité, ce qui lui permet de travailler avec des données structurées et non structurées.
Dans ce billet, je vais passer en revue les principaux composants de Hadoop, à savoir le stockage, le traitement et la gestion des données à grande échelle. À la fin, vous aurez une idée claire de la façon dont cette technologie fondamentale s'inscrit dans les écosystèmes de big data.
Hadoop n'est pas un outil unique. Il s'agit d'un écosystème comprenant plusieurs modules qui fonctionnent ensemble pour gérer le stockage des données, le traitement et la coordination des ressources.
Hadoop se compose de quatre modules fondamentaux :
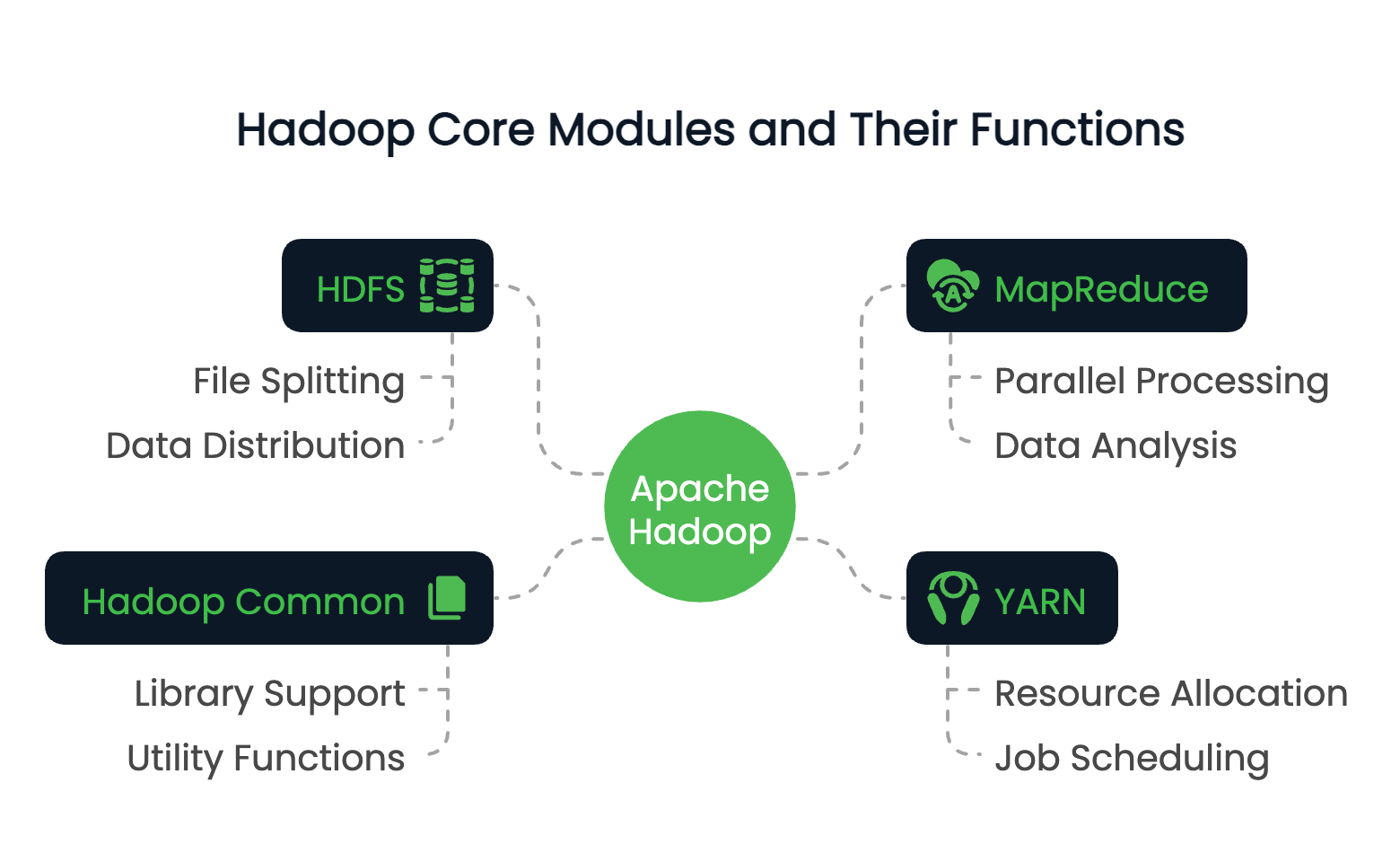
Ces modules fonctionnent ensemble pour créer un environnement informatique distribué capable de traiter des pétaoctets de données.
Pour découvrir comment le traitement des données distribuées se compare aux autres plateformes, le cours Big Data Fundamentals with PySpark fournit une introduction pratique qui complète votre compréhension de Hadoop.
Le rôle principal de Hadoop réside dans sa capacité à relever un défi majeurdans letraitement des données volumineuses, à savoir l'extensibilité.
Les systèmes traditionnels sont souvent confrontés à des ensembles de données qui dépassent la capacité d'une seule machine, tant en termes de stockage que de calcul. Hadoop résout ce problème en répartissant les données sur de nombreux nœuds et en exécutant les calculs en parallèle.
Hadoop peut donc traiter efficacement des téraoctets, voire des pétaoctets de données. Au-delà de son évolutivité, Hadoop offre également une grande tolérance aux pannes grâce à la réplication des données et permet aux entreprises de mettre en place une infrastructure de données rentable en utilisant du matériel de base.
Nous avons abordé le rôle et la structure de Hadoop, examinons maintenant certains de ses attributs les plus précieux. Il s'agit notamment de
Ces caractéristiques font d'Hadoop un outil bien adapté au traitement des données par lots, à l'analyse des journaux et aux pipelines ETL. Hadoop est un cas classiqueudy in distributed computing, où les calculs sont effectués sur plusieurs nœuds afin d'augmenter l'efficacité et l'échelle.
Examinons maintenant en détail chacun des modules de base de Hadoop.
Vous souhaitez valider vos connaissances sur Hadoop ou vous préparer à un rôle dans le domaine des données ? Voici 24 questions et réponses d'entretien Hadoop pour 2025 pour vous aider à démarrer.
Parmi les quatre composants principaux, HDFS est le principal système de stockage de Hadoop. Il est conçu pour stocker de manière fiable les grandes quantités de données réparties sur une grappe de machines dont nous avons parlé plus haut. Son architecture est conçue pour ce type d'accès à de grands ensembles de données et est optimisée pour la tolérance aux pannes, l'extensibilité et la localité des données.
L'architecture HDFS s'articule autour d'un modèle maître-esclave. Au sommet se trouve le NameNode, qui gère les métadonnées, c'est-à-dire l'arborescence du système de fichiers et les informations relatives à l'emplacement de chaque fichier. Il ne stocke pas les données réelles.
Les DataNodes sont les chevaux de bataille. Ils gèrent le stockage attaché aux nœuds et répondent aux demandes de lecture/écriture des clients. Chaque nœud de données envoie régulièrement des rapports au nœud de nom (NameNode) avec un battement de cœur et des rapports de bloc pour assurer un cursus cohérent.
Enfin, HDFS comprend un NameNode secondaire, à ne pas confondre avec un nœud de basculement. Au lieu de cela, il vérifie périodiquement les métadonnées du NameNode afin de réduire le temps de démarrage et la surcharge de mémoire.
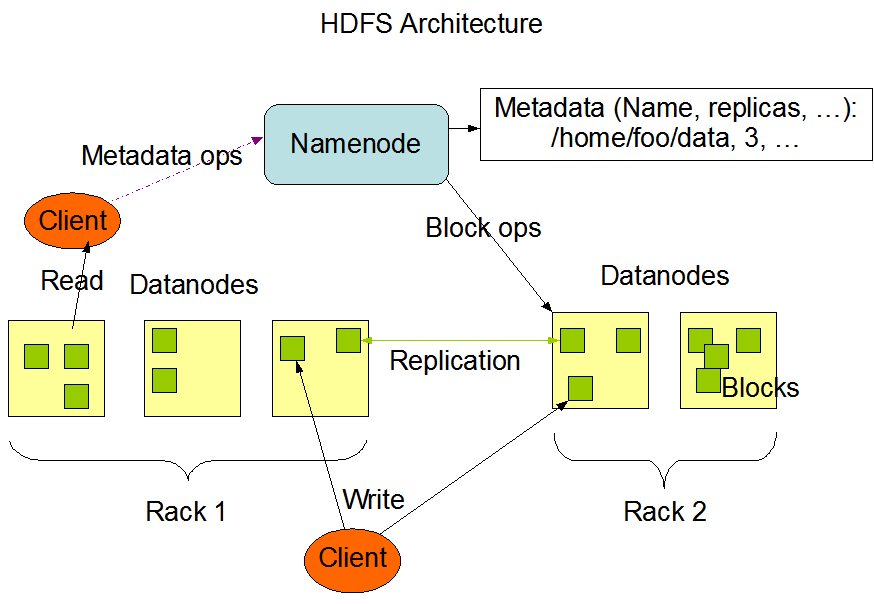
L'architecture HDFS. Source de l'imagee : Documentation Apache Hadoop
Lorsqu'un fichier est écrit dans HDFS, il est divisé en blocs detaille fixe de 64 Mo. Chaque bloc est ensuite réparti entre différents DataNodes. Cette stratégie de distribution favorise le parallélisme lors de l'accès aux données et renforce la tolérance aux pannes.
Les données dans HDFS ne sont pas stockées une seule fois. Chaque bloc est répliqué (la valeur par défaut est de trois copies) et réparti sur l'ensemble du cluster. Lors d'une opération de lecture, le système extrait les données de la réplique disponible la plus proche afin de maximiser le débit et de minimiser la latence. Les écritures vont d'abord sur une réplique, puis se propagent aux autres, ce qui garantit la durabilité sans goulots d'étranglement immédiats.
Cette conception au niveau des blocs permet également à HDFS d'évoluer horizontalement. De nouveaux nœuds peuvent être ajoutés à la grappe et le système rééquilibrera les données pour utiliser la capacité supplémentaire.
Pour une comparaison avec d'autres formats de big data, découvrezcomment Apache Parquetoptimise le stockage en colonnes pour les charges de travail analytiques.
HDFS a été conçu en tenant compte des défaillances. Dans les grands systèmes distribués, les défaillances de nœuds sont attendues et non exceptionnelles. HDFS assure la disponibilité des données grâce à son mécanisme de réplication. Si un DataNode tombe en panne, le NameNode détecte la panne par des battements de cœur manqués et planifie la réplication des blocs perdus vers les nœuds sains.
De plus, le système surveille en permanence l'état des blocs et lance la réplication si nécessaire. La stratégie de stockage redondant, associée à une surveillance proactive, garantit qu'aucun point de défaillance unique ne peut compromettre l'intégrité ou l'accès aux données.
Vient ensuite le moteur de traitement de Hadoop, MapReduce. Il permet un calcul distribué sur de grands ensembles de données en décomposant les tâches en opérations indépendantes plus petites qui peuvent être exécutées en parallèle.
Le modèle simplifie les transformations de données complexes et est particulièrement adapté au traitement par lots dans un environnement distribué.
MapReduce suit un modèle de programmation en deux phases : le modèle Map et Réduire et Reduce.
Au cours de la phase de cartographie, l'ensemble de données d'entrée est divisé en morceaux plus petits, et chaque morceau est traité pour produire des paires clé-valeur. Ces résultats intermédiaires sont ensuite mélangés et triés avant d'être transmis à la phase de réduction, où ils sont agrégés ou transformés en résultats finaux.
Ce modèle est très efficace pour des tâches telles que le comptage de la fréquence des mots, le filtrage des journaux ou l'assemblage d'ensembles de données à grande échelle.
Les développeurs mettent en œuvre une logique personnalisée par le biais des fonctions map() et reduce(), que le framework orchestre dans le cluster.
Lorsqu'une tâche MapReduce est soumise, les données d'entrée sont d'abord divisées en blocs. Un JobTracker (ou ResourceManager dans les versions compatibles avec YARN) coordonne ensuite la distribution de ces blocs entre les TaskTrackers ou NodeManagers disponibles.
Les tâches Map s'exécutent en parallèle sur les nœuds, en lisant les scissions d'entrée et en émettant des paires clé-valeur intermédiaires. Ces paires sont ensuite mélangées et triées automatiquement. Une fois cette phase achevée, les tâches de réduction commencent, avec l'extraction de données groupées et l'application d'une logique d'agrégation pour produire le résultat final.
Le processus garantit la localité des données en assignant les tâches à proximité de l'endroit où résident les données, minimisant ainsi la congestion du réseau et améliorant le débit. Les défaillances des tâches sont détectées et réaffectées automatiquement, ce qui contribue à la résilience du système.
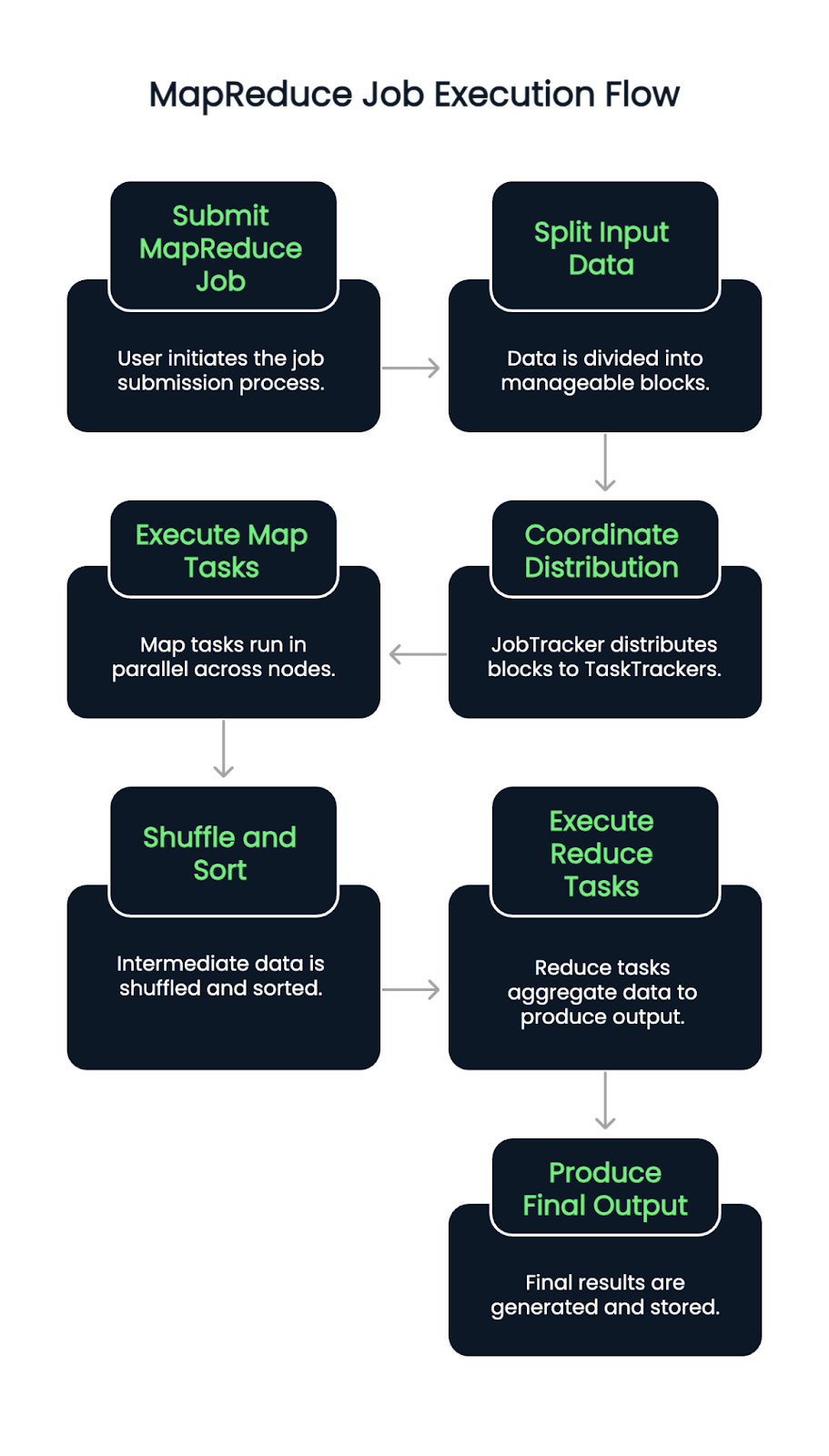
MapReduce offre plusieurs avantages évidents :
Mais elle s'accompagne aussi de compromis :
Décider entre Hadoop et Spark ? Lisez notre guide pour savoir quel cadre de Big Data vous convient le mieux.
YARN sert de couche de gestion des ressources de Hadoop. Il sépare la planification des tâches et l'allocation des ressources du modèle de traitement, ce qui permet à Hadoop de prendre en charge plusieurs moteurs de traitement de données au-delà de MapReduce.
YARN sert de plateforme centrale pour la gestion des ressources informatiques dans le cluster. Il alloue les ressources système disponibles à plusieurs applications et en coordonne l'exécution. Cette séparation des préoccupations aide Hadoop à évoluer efficacement et ouvre la porte à la prise en charge d'autres frameworks comme Apache Spark, Hive et Tez.
YARN présente trois composants :
Chaque application (comme un job MapReduce) possède son propre ApplicationMaster, ce qui permet d'améliorer l'isolation des pannes et le cursus des jobs.
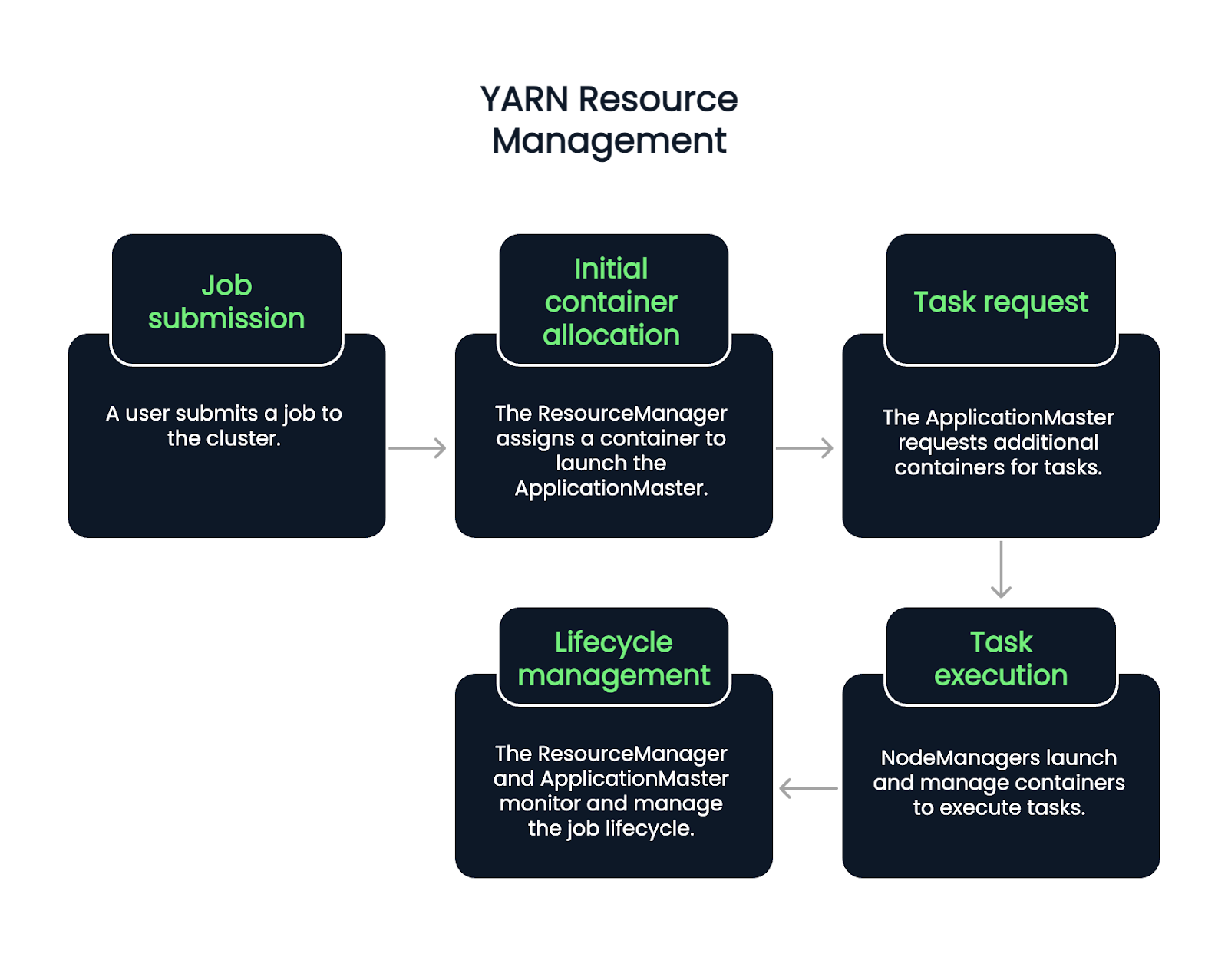
Le flux commence lorsqu'un utilisateur soumet un travail. Le ResourceManager accepte le travail et assigne un conteneur pour démarrer l'ApplicationMaster. À partir de là, l'ApplicationMaster demande à d'autres conteneurs d'exécuter des tâches, en fonction de la charge de travail actuelle et de la disponibilité.
Les NodeManagers lancent et gèrent ces conteneurs, qui exécutent des tâches individuelles. Tout au long du cycle de vie du travail, le ResourceManager et l'ApplicationMaster se chargent de la surveillance, de la reprise sur panne et de l'établissement de rapports d'achèvement. Il s'agit donc d'un processus en cinq étapes.
La colle qui unit tous les composants d'Hadoop est Hadoop Common. Il s'agit d'un ensemble de bibliothèques, de fichiers de configuration et d'utilitaires nécessaires à tous les modules.
Hadoop Common fournit le code de base et les outils qui permettent à HDFS, YARN et MapReduce de communiquer et de se coordonner. Il s'agit notamment de bibliothèques Java, de clients de systèmes de fichiers et d'API utilisées dans l'ensemble de l'écosystème.
Il assure également la cohérence et la compatibilité entre les modules, permettant aux développeurs de s'appuyer sur un ensemble commun de primitives.
Il est essentiel de configurer correctement Hadoop. Hadoop Common contient des fichiers de configuration tels que core-site.xml, qui définissent les comportements par défaut tels que les URI du système de fichiers et les paramètres d'entrée/sortie.
Les outils et scripts en ligne de commande inclus dans Hadoop Common prennent en charge des tâches telles que le démarrage des services, la vérification de l'état des nœuds et la gestion des travaux. La plupart de ces outils sont utilisés par les administrateurs système et les développeurs pour les opérations quotidiennes des clusters.
S'il s'agit de données massives, de traitement distribué ou d'analyse par lots, Hadoop est probablement utilisé. Plus précisément, Hadoop est utilisé dans divers secteurs pour traiter des volumes massifs de données structurées et non structurées. Sa conception distribuée et sa flexibilité open-source le rendent polyvalent pour les tâches à forte intensité de données.
Les entreprises des secteurs de la finance, de la santé, des télécommunications, du commerce électronique et des médias sociaux utilisent régulièrement Hadoop. Elle aide les banques à détecter les fraudes en temps réel, soutient la recherche génomique dans le domaine de la santé et permet aux moteurs de recommandation de fonctionner dans le commerce de détail en ligne.
Ces scénarios bénéficient de la capacité de Hadoop à traiter de grands ensembles de données avec une tolérance aux pannes et un parallélisme.
Pour une alternative moderne et cloud-native à Hadoop, essayez le cours Introduction à Databricks, qui prend en charge Spark et d'autres outils évolutifs.
Hadoop fonctionne rarement de manière isolée et peut s'intégrer à des centaines de programmes accessoires. En fonction de vos préférences et de votre environnement de codage, vous pouvez associer Hadoop avec :
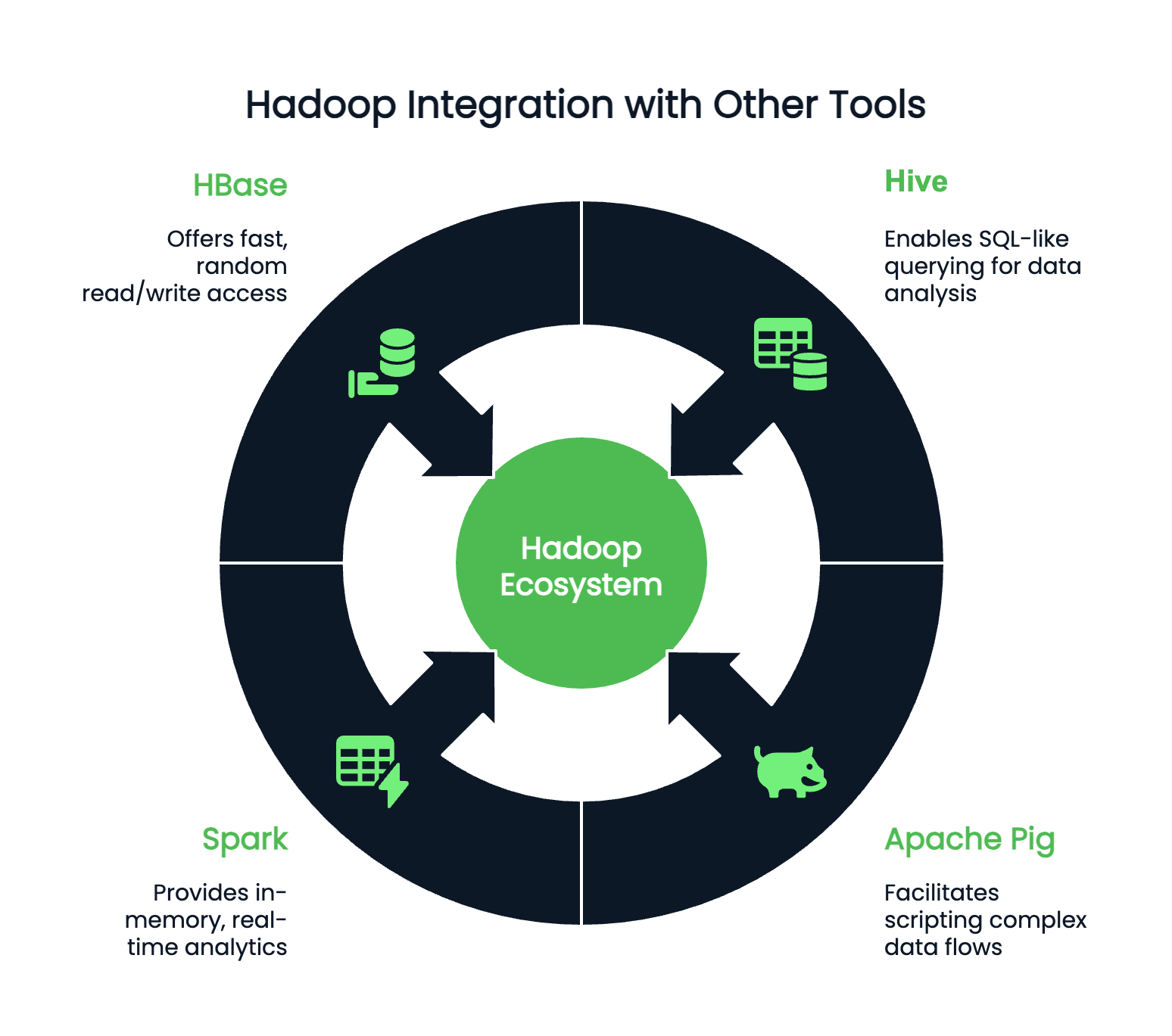
Si Hadoop n'est plus le mot à la mode, il n'en reste pas moins une technologie fondamentale dans le paysage du big data. Comprendre Hadoop reste incroyablement précieux pour tout professionnel des données travaillant avec des systèmes à grande échelle. Ses principaux composants - HDFS pour le stockage, MapReduce pour le traitement, YARN pour la gestion des ressources et Hadoop Common pour les utilitaires essentiels - continuent de façonner la manière dont les flux de données sont conçus et mis à l'échelle.
Avant de vous lancer dans le déploiement ou l'optimisation, prenez le temps de comprendre comment les données sont distribuées et configurées au sein d'un cluster Hadoop. Ces connaissances simplifient le dépannage et le réglage des performances et ouvrent la voie à l'intégration d'outils puissants comme Apache Spark et Hive pour des analyses plus sophistiquées.
Pour en savoir plussur le traitement des big data, consultez le site :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours