
Curso
Fundamentos de PySpark
4 h
157.5K
El procesamiento de big data a menudo implica trabajar con datos no estructurados, que pueden ser difíciles de gestionar y analizar. En cualquier momento pueden producirse borrados accidentales u otros errores, lo que supone un grave riesgo para la integridad de los datos.
Apache Iceberg y Delta Lake son formatos de tablas de código abierto que se utilizan principalmente para gestionar lagos de datos a gran escala. Ambas plataformas ofrecen funciones como la evolución de esquemas, el viaje en el tiempo y las transacciones ACID para afrontar los retos de manejar conjuntos de datos masivos. Aunque cada uno de ellos tiene ventajas únicas, comparten un objetivo común: mantener la coherencia de los datos en todos los conjuntos de datos.
En este artículo, te explicaré las principales características, similitudes y diferencias arquitectónicas entre Apache Iceberg y Delta Lake para ayudarte a elegir la herramienta adecuada a tus necesidades.

Desarrollado por Netflix y posteriormente donado a la Fundación del Software Apache, Iceberg pretende resolver los retos de la gestión de lagos de datos a gran escala. Es un formato de alto rendimiento para grandes tablas analíticas que gestiona y consulta eficazmente conjuntos de datos masivos. Sus características abordan muchas de las limitaciones de los enfoques tradicionales de almacenamiento en lagos de datos.
Entendamos el Iceberg Apache con más detalle.
Éstas son algunas de las características más destacadas de Apache Iceberg, que son muy útiles para los ingenieros de datos cuando trabajan con conjuntos de datos.
loyalty_points, puedes hacerlo sin afectar a los datos existentes ni romper las consultas actuales. Esta flexibilidad es especialmente útil para proyectos de datos a largo plazo que necesitan adaptarse con el tiempo.Estas características hacen que Iceberg sea especialmente bueno para el análisis de datos a gran escala, sobre todo si tratas con datos que cambian con frecuencia o a los que hay que acceder de diversas formas durante largos periodos.
Consulta la entrada del blog Apache Iceberg Explicado para profundizar en esta apasionante tecnología.

Desarrollado por Databricks, Delta Lake funciona perfectamente con Spark, lo que lo convierte en una opción popular para las organizaciones que ya han invertido en el ecosistema Spark. Es una capa de almacenamiento de código abierto que aporta transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) a Apache Spark y a las cargas de trabajo de big data.
Los lagos de datos basados en Delta Lake agilizan el almacenamiento de datos y el aprendizaje automático para mantener la calidad de los datos mediante metadatos escalables, versionado y aplicación de esquemas.
Éstas son las características clave que hacen de Delta Lake una buena solución para el procesamiento moderno de datos:
El curso Fundamentos de Big Data con PySpark profundiza en el procesamiento moderno de datos con Spark. Es un gran repaso a esta potente tecnología.
Dado que tanto Apache Iceberg como Delta Lake gestionan grandes cantidades de datos, examinemos sus similitudes fundamentales.
Ambas herramientas pueden proporcionar una coherencia total de los datos mediante transacciones ACID y versionado. Sin embargo, Iceberg utiliza el enfoque de fusión en lectura, mientras que Delta Lake utiliza la estrategia de fusión en escritura.
Como resultado, cada uno gestiona el rendimiento y los datos de forma diferente. Iceberg puede proporcionar soporte completo para la evolución de esquemas, mientras que Delta Lake impone el cumplimiento de los esquemas.
La funcionalidad de viaje en el tiempo permite a los usuarios consultar versiones históricas de los datos. Esto lo hace inestimable para auditar, depurar e incluso reproducir experimentos. Tanto Iceberg como Delta Lake admiten el viaje en el tiempo, lo que significa que puedes acceder a estados anteriores de los datos sin preocuparte.
Apache Iceberg y Delta Lake son tecnologías de código abierto. Esto significa que cualquiera puede utilizarlos gratuitamente e incluso ayudar a mejorarlos. Además, ser de código abierto significa que no estás atado al producto de una empresa: tienes más libertad para cambiar o combinar herramientas según necesites. Y como su código es público, puedes incluso optimizarlo para tus necesidades específicas.
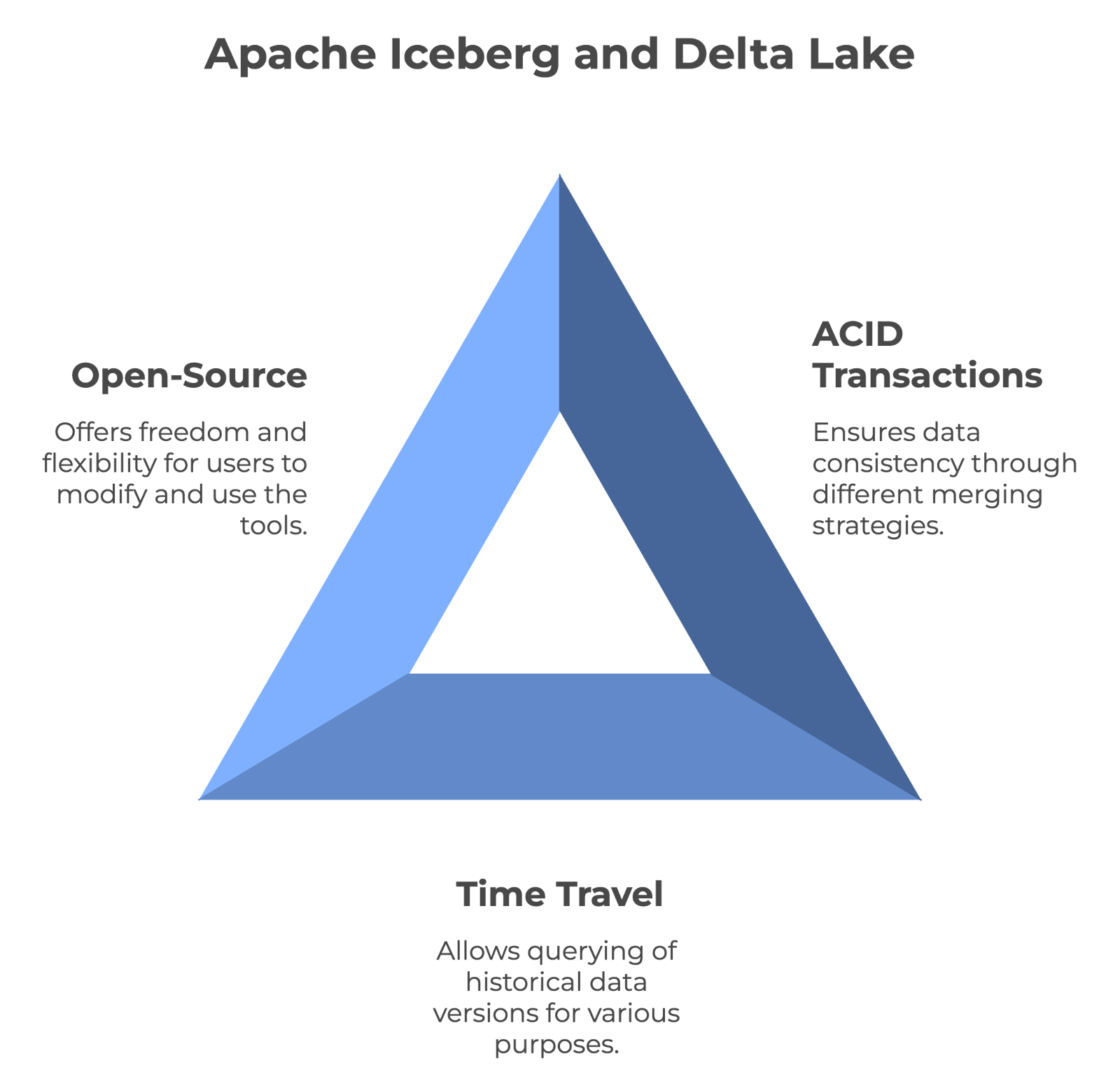
Las principales características que comparten Apache Iceberg y Delta Lake. Imagen del Autor creada con napkin.ai.
Aunque Iceberg y Delta Lake comparten similitudes, difieren en su arquitectura. Veamos cómo:
Iceberg y Delta Lake garantizan la fiabilidad de los datos en los lagos de datos, pero lo consiguen mediante mecanismos diferentes. Iceberg utiliza instantáneas para las transacciones atómicas con el fin de garantizar que los cambios se consignan o revierten completamente. Pero Delta Lake utiliza registros de transacciones para garantizar que sólo se consignan en la tabla los cambios validados y proporciona fiabilidad en las actualizaciones de datos.
Apache Iceberg emplea una estructura jerárquica de metadatos, que incluye archivos de manifiesto, listas de manifiesto y archivos de metadatos. Este diseño agiliza el procesamiento de las consultas, eliminando operaciones costosas como listar y renombrar archivos.
Sin embargo, Delta Lake adopta un enfoque basado en transacciones para registrar cada transacción en un registro. Para mejorar la eficacia de las consultas y simplificar la gestión de los registros, consolida periódicamente estos registros enarchivos de puntos de control Parquet , que capturan el estado completo de las tablas.
Iceberg es flexible con los formatos de archivo y puede trabajar de forma nativa con archivos Parquet, ORC y Avro. Esto es útil si tienes datos en distintos formatos o si quieres cambiar de formato en el futuro sin cambiar todo el sistema.
Delta Lake almacena los datos principalmente en formato Parquet porque éste es eficiente, especialmente para consultas analíticas. Sólo se centra en un formato para ofrecer el mejor rendimiento posible para ese tipo de archivo concreto.
Iceberg y Delta Lake son lagos de datos a escala, pero emplean estrategias diferentes. Iceberg prioriza la organización avanzada de datos con funciones como la partición y la compactación, mientras que Delta Lake hace hincapié en el alto rendimiento a través de su motor Delta, la autocompactación y las funciones de indexación.
Diferencias entre los núcleos de Apache Iceberg y Delta Lake. Imagen del Autor creada con napkin.ai.
Debido a sus características únicas, Apache Iceberg se ha convertido rápidamente en una solución de referencia para la gestión moderna de los lagos de datos. Examinemos algunos de sus principales casos de uso para comprender sus puntos fuertes.
He aquí por qué Iceberg es una opción popular para las organizaciones que construyen lagos de datos que operan a escala de nube:
Los equipos que trabajan con modelos de datos complejos encuentran Iceberg especialmente útil por lo siguiente:
Iceberg es compatible con herramientas diversificadas, lo que lo convierte en una opción versátil para el ecosistema de datos. Veamos algunas de sus principales integraciones:
Iceberg funciona perfectamente con lo siguiente:
Los siguientes proveedores principales de la nube ofrecen soporte nativo para Iceberg:
Iceberg también proporciona bibliotecas cliente para distintos lenguajes de programación, como:
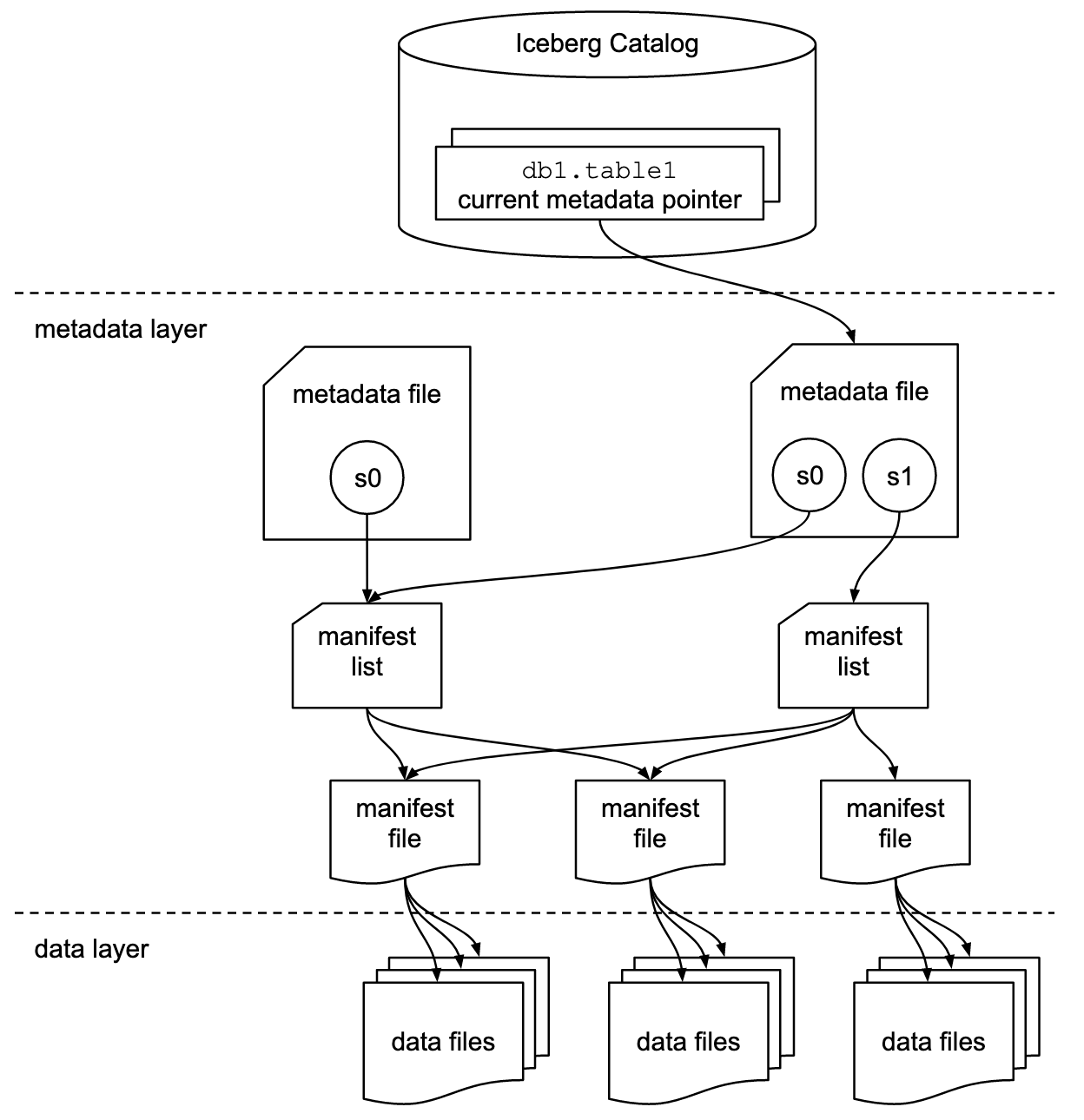
Especificación del formato de la tabla Apache Iceberg. Fuente de la imagen: Documentación de Iceberg.
Delta Lake puede resolver retos comunes y facilitar la gestión de datos. Examinemos algunas situaciones clave en las que realmente ayuda.
Con Delta Lake, no necesitas sistemas separados para distintos tipos de datos. En su lugar, puedes tener un sistema que se encargue de todo. Puedes añadir nuevos datos a tus tablas en tiempo real, y estarán inmediatamente listos para el análisis. Esto significa que tus datos están siempre actualizados.
Puedes crear un único flujo de trabajo que gestione datos antiguos y nuevos para que todo tu sistema sea menos complejo y más fácil de gestionar. Este enfoque unificado simplificará tus canalizaciones de datos.
Delta Lake aporta una gran fiabilidad a los lagos de datos mediante transacciones ACID. Por ejemplo:
Delta Lake consigue esta fiabilidad garantizando que todos los cambios se apliquen completamente o no se apliquen en absoluto. Además, garantiza que los datos pasen siempre de un estado válido a otro y que las distintas operaciones no interfieran entre sí.
Delta Lake también funciona a la perfección con Apache Spark, una gran ventaja para muchas organizaciones. Si ya utilizas Spark, añadir Delta Lake será sencillo y no requerirá grandes cambios en tu configuración actual. Tu equipo puede utilizar las mismas herramientas Spark y comandos SQL con los que están familiarizados.
Como resultado, hará que tus trabajos Spark se ejecuten más rápido, especialmente cuando se trate de grandes cantidades de datos. Lo hace organizando los datos de forma más eficiente y utilizando técnicas de indexación inteligentes.
Vamos a resumir las principales diferencias entre Apache Iceberg y Delta Lake para ayudarte a comprender rápidamente los puntos fuertes y las características clave de sus formatos.
|
Características |
Apache Iceberg |
Delta Lake |
|
Transacción ACID |
Sí |
Sí |
|
Viaje en el tiempo |
Sí |
Sí |
|
Versionado de datos |
Sí |
Sí |
|
Formato de archivo |
Parquet, ORC, Avro |
Parquet |
|
Evolución del esquema |
Completo |
Parcial |
|
Integración con otros motores |
Apache Spark, Trino, Flink |
Principalmente Apache Spark |
|
Compatibilidad con la nube |
AWS, GCP, Azure |
AWS, GCP |
|
Motores de consulta |
Spark, Trino, Flink |
Chispa |
|
Lenguaje de programación |
SQL, Python, Java |
SQL, Python |
Nota: La mejor elección depende de tus necesidades, requisitos de escalabilidad y estrategia de datos a largo plazo.
A la hora de elegir entre Apache Iceberg y Delta Lake, ten en cuenta tu caso de uso específico y la pila tecnológica existente. La flexibilidad de Iceberg con los formatos de archivo y los motores de consulta lo hacen ideal para los entornos nativos de la nube. Sin embargo, la estrecha integración de Delta Lake con Apache Spark es una buena opción para las organizaciones que hayan invertido mucho en el ecosistema Spark.
También puedes consultar algunos recursos relevantes del DataCamp para reforzar tu comprensión de los datos:
¡Feliz aprendizaje!
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Samuel Shaibu
10 min
blog
Kurtis Pykes
12 min
blog
Mona Khalil
5 min
blog
Tim Lu
11 min
blog
DataCamp Team
12 min
