
Curso
Fundamentos do PySpark
4 h
157.5K
O processamento de Big Data geralmente envolve o trabalho com dados não estruturados, que podem ser difíceis de gerenciar e analisar. Exclusões acidentais ou outros erros podem ocorrer a qualquer momento, o que representa um grande risco para a integridade dos dados.
O Apache Iceberg e o Delta Lake são formatos de tabela de código aberto usados principalmente para gerenciar data lakes e lakehouses em grande escala. Ambas as plataformas oferecem recursos como evolução de esquema, viagem no tempo e transações ACID para enfrentar os desafios de lidar com conjuntos de dados maciços. Embora cada um tenha vantagens exclusivas, eles compartilham um objetivo comum: manter a consistência dos dados entre os conjuntos de dados.
Neste artigo, explicarei os principais recursos, as semelhanças e as diferenças arquitetônicas entre o Apache Iceberg e o Delta Lake para ajudar você a escolher a ferramenta certa para suas necessidades.

Desenvolvido pela Netflix e posteriormente doado à Apache Software Foundation, o Iceberg tem como objetivo solucionar os desafios do gerenciamento de lagos de dados em grande escala. É um formato de alto desempenho para grandes tabelas analíticas que gerencia e consulta com eficiência conjuntos de dados maciços. Seus recursos abordam muitas das limitações das abordagens tradicionais de armazenamento de data lake.
Vamos entender o Apache Iceberg em mais detalhes.
Aqui estão alguns dos recursos mais importantes do Apache Iceberg, que são muito úteis para os engenheiros de dados quando trabalham com conjuntos de dados.
loyalty_points, poderá fazê-lo sem afetar os dados existentes ou interromper as consultas atuais. Essa flexibilidade é especialmente útil para projetos de dados de longo prazo que precisam se adaptar ao longo do tempo.Esses recursos tornam o Iceberg particularmente bom para a análise de dados em larga escala, especialmente se você lida com dados que mudam com frequência ou que precisam ser acessados de várias maneiras durante longos períodos.
Confira a publicação do blog Apache Iceberg Explained para que você possa se aprofundar nessa tecnologia interessante.

Desenvolvido pela Databricks, o Delta Lake funciona perfeitamente com o Spark, o que o torna uma opção popular para organizações que já investiram no ecossistema do Spark. É uma camada de armazenamento de código aberto que traz transações ACID (Atomicidade, Consistência, Isolamento, Durabilidade) para o Apache Spark e cargas de trabalho de Big Data.
Os data lakehouses baseados no Delta Lake otimizam o armazenamento de dados e a aprendizagem automática para manter a qualidade dos dados por meio de metadados dimensionáveis, controle de versão e aplicação de esquema.
Aqui estão os principais recursos que fazem do Delta Lake uma boa solução para o processamento de dados moderno:
O curso Big Data Fundamentals with PySpark aprofunda o processamento moderno de dados com o Spark. É uma ótima atualização sobre essa poderosa tecnologia.
Como o Apache Iceberg e o Delta Lake gerenciam grandes quantidades de dados, vamos examinar suas semelhanças fundamentais.
Ambas as ferramentas podem oferecer consistência total dos dados usando transações ACID e controle de versão. No entanto, o Iceberg usa a abordagem merge-on-read, enquanto o Delta Lake usa a estratégia merge-on-write.
Como resultado, cada um deles lida com o desempenho e o gerenciamento de dados de forma diferente. O Iceberg pode oferecer suporte completo à evolução do esquema, enquanto o Delta Lake impõe a conformidade do esquema.
A funcionalidade de viagem no tempo permite que os usuários consultem versões históricas dos dados. Isso o torna inestimável para auditoria, depuração e até mesmo reprodução de experimentos. Tanto o Iceberg quanto o Delta Lake suportam viagens no tempo, o que significa que você pode acessar estados anteriores dos dados sem se preocupar.
O Apache Iceberg e o Delta Lake são tecnologias de código aberto. Isso significa que qualquer pessoa pode usá-los gratuitamente e até mesmo ajudar a melhorá-los. Além disso, o fato de ser de código aberto significa que você não está vinculado ao produto de uma empresa e tem mais liberdade para trocar ou combinar ferramentas conforme necessário. E como o código deles é público, você pode até mesmo otimizá-lo para suas necessidades específicas.
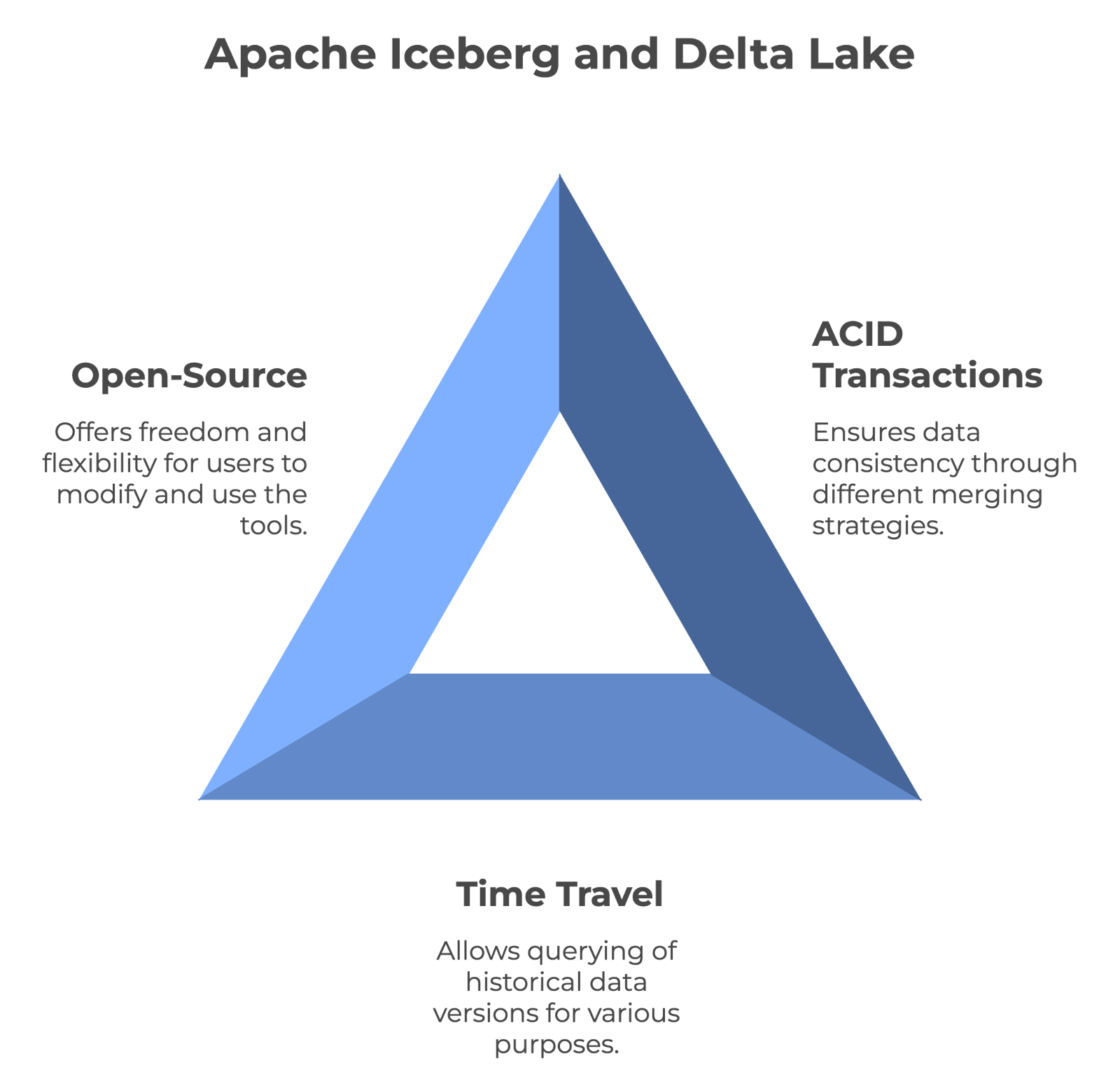
As principais características compartilhadas pelo Apache Iceberg e pelo Delta Lake. Imagem do autor criada com o napkin.ai.
Embora o Iceberg e o Delta Lake tenham semelhanças, eles diferem na arquitetura. Vamos ver como:
O Iceberg e o Delta Lake garantem a confiabilidade dos dados em data lakes, mas fazem isso por meio de mecanismos diferentes. Iceberg usa snapshots para transações atômicas para garantir que as alterações sejam totalmente confirmadas ou revertidas. Mas o Delta Lake usa logs de transações para garantir que somente as alterações validadas sejam confirmadas na tabela e oferece confiabilidade nas atualizações de dados.
O Apache Iceberg emprega uma estrutura hierárquica de metadados, que inclui arquivos de manifesto, listas de manifesto e arquivos de metadados. Esse design agiliza o processamento de consultas, eliminando operações dispendiosas, como listagem e renomeação de arquivos.
No entanto, o Delta Lake adota uma abordagem baseada em transações para registrar cada transação em um log. Para aumentar a eficiência da consulta e simplificar o gerenciamento de logs, ele consolida periodicamente esses logs emarquivos de ponto de verificação do Parquet , que capturam o estado completo da tabela.
O Iceberg é flexível com formatos de arquivo e pode trabalhar nativamente com arquivos Parquet, ORC e Avro. Isso é útil se você tiver dados em formatos diferentes ou se quiser mudar de formato no futuro sem alterar todo o sistema.
O Delta Lake armazena principalmente dados no formato Parquet porque o Parquet é eficiente, especialmente para consultas analíticas. Ele se concentra apenas em um formato para oferecer o melhor desempenho possível para esse tipo específico de arquivo.
Os lagos de dados em escala Iceberg e Delta Lake, mas empregam estratégias diferentes. O Iceberg prioriza a organização avançada de dados com recursos como particionamento e compactação, enquanto o Delta Lake enfatiza o alto desempenho por meio de seu mecanismo Delta, compactação automática e recursos de indexação.
Diferenças entre os núcleos do Apache Iceberg e do Lago Delta. Imagem do autor criada com o napkin.ai.
Devido aos seus recursos exclusivos, o Apache Iceberg se tornou rapidamente uma solução de referência para o gerenciamento moderno de data lake. Vamos examinar alguns de seus principais casos de uso para entender seus pontos fortes.
Veja por que o Iceberg é uma escolha popular para organizações que criam lagos de dados que operam em escala de nuvem:
As equipes que lidam com modelos de dados complexos consideram o Iceberg particularmente útil por causa do seguinte:
O Iceberg é compatível com diversas ferramentas, o que o torna uma opção versátil para o ecossistema de dados. Vamos dar uma olhada em algumas de suas principais integrações:
O Iceberg funciona perfeitamente com o seguinte:
Os principais provedores de nuvem a seguir oferecem suporte nativo para o Iceberg:
O Iceberg também fornece bibliotecas de clientes para diferentes linguagens de programação, como:
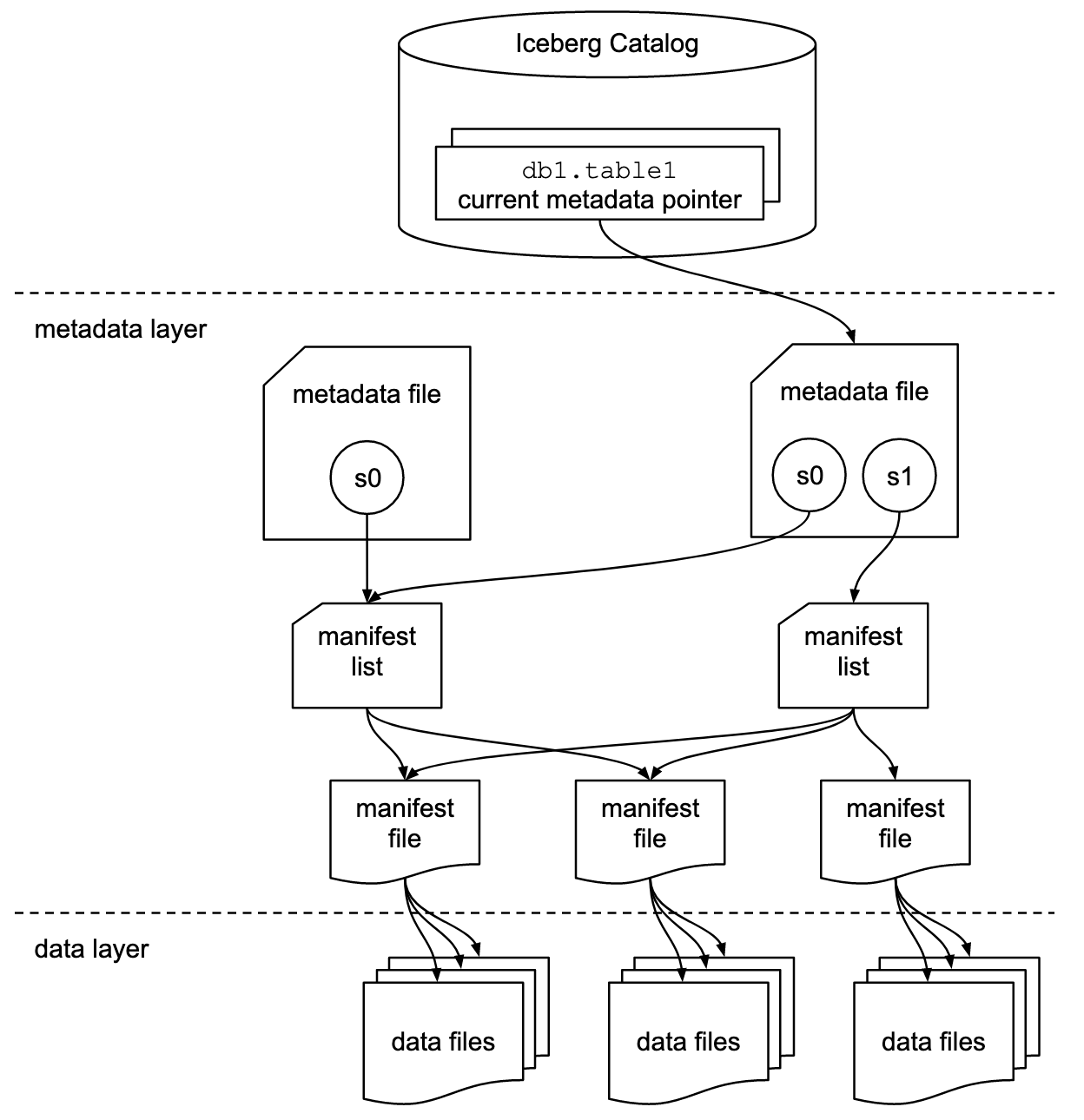
Especificação do formato de tabela do Apache Iceberg. Fonte da imagem: Documentação do iceberg.
O Delta Lake pode resolver desafios comuns e facilitar o gerenciamento de dados. Vamos examinar algumas situações importantes em que isso realmente ajuda.
Com o Delta Lake, você não precisa de sistemas separados para diferentes tipos de dados. Em vez disso, você pode ter um sistema que lide com tudo. Você pode adicionar novos dados às suas tabelas em tempo real, e eles estarão imediatamente prontos para análise. Isso significa que seus dados estão sempre atualizados.
Você pode criar um único fluxo de trabalho que lide com dados antigos e novos para tornar todo o sistema menos complexo e mais fácil de gerenciar. Essa abordagem unificada simplificará seus pipelines de dados.
O Delta Lake traz uma forte confiabilidade de dados para os data lakes por meio de transações ACID. Por exemplo:
O Delta Lake alcança essa confiabilidade ao garantir que todas as alterações sejam completamente aplicadas ou não sejam aplicadas. Além disso, ele garante que os dados sempre passem de um estado válido para outro e que as diferentes operações não interfiram umas nas outras.
O Delta Lake também funciona perfeitamente com o Apache Spark, uma grande vantagem para muitas organizações. Se você já estiver usando o Spark, adicionar o Delta Lake será simples e não exigirá grandes alterações na configuração existente. Sua equipe pode usar as mesmas ferramentas do Spark e os mesmos comandos SQL com os quais já está familiarizada.
Como resultado, isso fará com que os trabalhos do Spark sejam executados mais rapidamente, especialmente quando você estiver lidando com grandes quantidades de dados. Ele faz isso organizando os dados com mais eficiência e usando técnicas de indexação inteligentes.
Vamos resumir as principais diferenças entre o Apache Iceberg e o Delta Lake para ajudar você a entender rapidamente os pontos fortes e os principais recursos de seus formatos.
|
Recursos |
Apache Iceberg |
Delta Lake |
|
Transação ACID |
Sim |
Sim |
|
Viagem no tempo |
Sim |
Sim |
|
Controle de versão de dados |
Sim |
Sim |
|
Formato do arquivo |
Parquet, ORC, Avro |
Parquet |
|
Evolução do esquema |
Completo |
Parcial |
|
Integração com outros mecanismos |
Apache Spark, Trino, Flink |
Principalmente o Apache Spark |
|
Compatibilidade com a nuvem |
AWS, GCP, Azure |
AWS, GCP |
|
Mecanismos de consulta |
Spark, Trino, Flink |
Faísca |
|
Linguagem de programação |
SQL, Python, Java |
SQL, Python |
Observação: A melhor opção depende de suas necessidades, dos requisitos de escalabilidade e da estratégia de dados de longo prazo.
Ao escolher entre o Apache Iceberg e o Delta Lake, considere seu caso de uso específico e a pilha de tecnologia existente. A flexibilidade do Iceberg com formatos de arquivo e mecanismos de consulta o torna ideal para ambientes nativos da nuvem. No entanto, a forte integração do Delta Lake com o Apache Spark é uma boa opção para organizações que investem muito no ecossistema do Spark.
Você também pode conferir alguns recursos relevantes do DataCamp para fortalecer seu conhecimento atual sobre dados:
Feliz aprendizado!
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Tim Lu
11 min
blog
Javier Canales Luna
12 min
blog
Mona Khalil
5 min
blog
Kurtis Pykes
7 min
blog
Mike Shakhomirov
11 min
blog
DataCamp Team
12 min
