
Cours
Introduction à PySpark
4 h
157.5K
Le traitement des Big Data implique souvent de travailler avec des données non structurées, qui peuvent être difficiles à gérer et à analyser. Des suppressions accidentelles ou d'autres erreurs peuvent se produire à tout moment, ce qui représente un risque majeur pour l'intégrité des données.
Apache Iceberg et Delta Lake sont des formats de tableaux open-source principalement utilisés pour la gestion de lacs de données et de lacustres à grande échelle. Les deux plateformes offrent des fonctionnalités telles que l'évolution des schémas, le voyage dans le temps et les transactions ACID pour relever les défis liés au traitement d'énormes ensembles de données. Bien que chacune d'entre elles présente des avantages uniques, elles ont un objectif commun : maintenir la cohérence des données entre les ensembles de données.
Dans cet article, j'expliquerai les principales caractéristiques, similitudes et différences architecturales entre Apache Iceberg et Delta Lake afin de vous aider à choisir l'outil le mieux adapté à vos besoins.

Développé par Netflix, puis donné à la Apache Software Foundation, Iceberg vise à résoudre les problèmes liés à la gestion de lacs de données à grande échelle. Il s'agit d'un format performant pour les tableaux analytiques de grande taille qui permet de gérer et d'interroger efficacement des ensembles de données massifs. Ses caractéristiques répondent à de nombreuses limitations des approches traditionnelles de stockage des lacs de données.
Comprenons Apache Iceberg plus en détail.
Voici quelques-unes des principales fonctionnalités d'Apache Iceberg, qui sont très utiles aux ingénieurs de données lorsqu'ils travaillent avec des ensembles de données.
loyalty_points, vous pouvez le faire sans affecter les données existantes ni interrompre les requêtes en cours. Cette flexibilité est particulièrement utile pour les projets de données à long terme qui doivent s'adapter au fil du temps.Ces caractéristiques font d'Iceberg un outil particulièrement adapté à l'analyse de données à grande échelle, en particulier si vous traitez des données qui changent fréquemment ou qui doivent être consultées de différentes manières sur de longues périodes.
Consultez l'article du blog Apache Iceberg Explained pour vous plonger dans cette technologie passionnante.

Développé par Databricks, Delta Lake fonctionne de manière transparente avec Spark, ce qui en fait un choix populaire pour les organisations déjà investies dans l'écosystème Spark. Il s'agit d'une couche de stockage open-source qui apporte les transactions ACID (atomicité, cohérence, isolation, durabilité) à Apache Spark et aux charges de travail big data.
Les entrepôts de données basés sur Delta Lake rationalisent l'entreposage de données et l'apprentissage automatique afin de maintenir la qualité des données grâce à des métadonnées évolutives, à la gestion des versions et à l'application des schémas.
Voici les principales caractéristiques qui font de Delta Lake une bonne solution pour le traitement moderne des données :
Le cours Big Data Fundamentals with PySpark approfondit le traitement moderne des données avec Spark. Il s'agit d'une excellente mise à jour de cette puissante technologie.
Apache Iceberg et Delta Lake gérant tous deux de grandes quantités de données, examinons leurs similitudes fondamentales.
Les deux outils peuvent assurer une cohérence totale des données à l'aide de transactions ACID et de versions. Toutefois, Iceberg utilise l' approche de fusion à la lecture, tandis que Delta Lake utilise la stratégie de fusion à l'écriture.
Par conséquent, chacun d'entre eux gère différemment les performances et la gestion des données. Iceberg peut fournir un support complet pour l'évolution des schémas, tandis que Delta Lake assure la conformité des schémas.
La fonctionnalité de voyage dans le temps permet aux utilisateurs d'interroger des versions historiques des données. Il s'agit donc d'un outil précieux pour l'audit, le débogage et même la reproduction d'expériences. Iceberg et Delta Lake prennent tous deux en charge le voyage dans le temps, ce qui signifie que vous pouvez accéder à des états antérieurs des données sans vous inquiéter.
Apache Iceberg et Delta Lake sont des technologies à code source ouvert. Cela signifie que tout le monde peut les utiliser gratuitement et même contribuer à les améliorer. En outre, le fait d'être un logiciel libre signifie que vous n'êtes pas lié au produit d'une seule entreprise - vous êtes plus libre de changer d'outil ou de le combiner selon vos besoins. Et comme leur code est public, vous pouvez même l'optimiser pour vos besoins spécifiques.
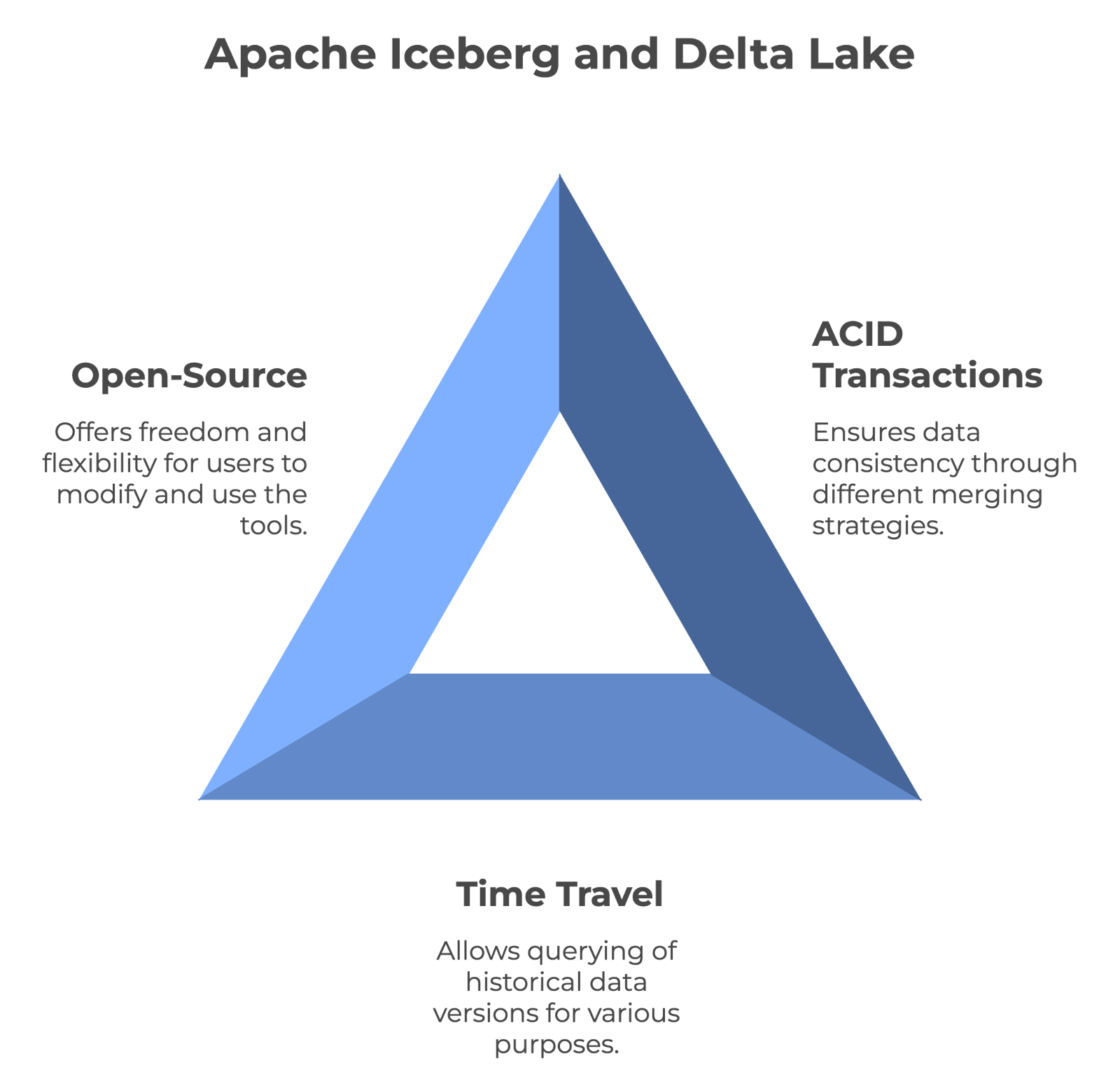
Les principales caractéristiques communes à l'iceberg Apache et au lac Delta. Image créée par l'auteur avec napkin.ai.
Si les lacs Iceberg et Delta présentent des similitudes, ils diffèrent par leur architecture. Voyons comment :
Iceberg et Delta Lake garantissent la fiabilité des données dans les lacs de données, mais ils y parviennent par des mécanismes différents. Iceberg utilise des instantanés pour les transactions atomiques afin de s'assurer que les changements sont entièrement validés ou annulés. Mais Delta Lake utilise les tableaux de transactions pour s'assurer que seules les modifications validées sont validées dans le tableau, ce qui garantit la fiabilité des mises à jour de données.
Apache Iceberg utilise une structure de métadonnées hiérarchique, qui comprend des fichiers de manifeste, des listes de manifeste et des fichiers de métadonnées. Cette conception permet de rationaliser le traitement des requêtes en éliminant les opérations coûteuses telles que l'énumération et le renommage des fichiers.
Cependant, Delta Lake adopte une approche basée sur les transactions pour enregistrer chaque transaction dans un journal. Pour améliorer l'efficacité des requêtes et simplifier la gestion des journaux, il consolide périodiquement ces tableaux dans desfichiers de points de contrôle Parquet , qui capturent l'état complet du tableau.
Iceberg est flexible avec les formats de fichiers et peut travailler nativement avec des fichiers Parquet, ORC et Avro. C'est utile si vous avez des données dans différents formats ou si vous souhaitez changer de format à l'avenir sans modifier l'ensemble de votre système.
Delta Lake stocke principalement les données au format Parquet parce que ce format est efficace, en particulier pour les requêtes analytiques. Il se concentre uniquement sur un format afin d'offrir les meilleures performances possibles pour ce type de fichier spécifique.
Les lacs de données Iceberg et Delta Lake sont à l'échelle des lacs de données mais utilisent des stratégies différentes. Iceberg donne la priorité à l'organisation avancée des données avec des fonctionnalités telles que le partitionnement et le compactage, tandis que Delta Lake met l'accent sur la haute performance grâce à son moteur Delta, au compactage automatique et aux capacités d'indexation.
Différences entre les carottes de l'Apache Iceberg et du Delta Lake. Image créée par l'auteur avec napkin.ai.
Grâce à ses caractéristiques uniques, Apache Iceberg est rapidement devenu une solution de choix pour la gestion moderne des lacs de données. Examinons quelques-uns de ses principaux cas d'utilisation pour comprendre ses points forts.
Voici pourquoi Iceberg est un choix populaire pour les organisations qui construisent des lacs de données fonctionnant à l'échelle du cloud :
Les équipes qui traitent des modèles de données complexes trouvent Iceberg particulièrement utile pour les raisons suivantes :
Iceberg est compatible avec divers outils, ce qui en fait un choix polyvalent pour l'écosystème des données. Jetons un coup d'œil à quelques-unes de ses principales intégrations :
Iceberg fonctionne de manière transparente avec les éléments suivants :
Les principaux fournisseurs de cloud suivants offrent une prise en charge native d'Iceberg :
Iceberg fournit également des bibliothèques de clients pour différents langages de programmation, tels que :
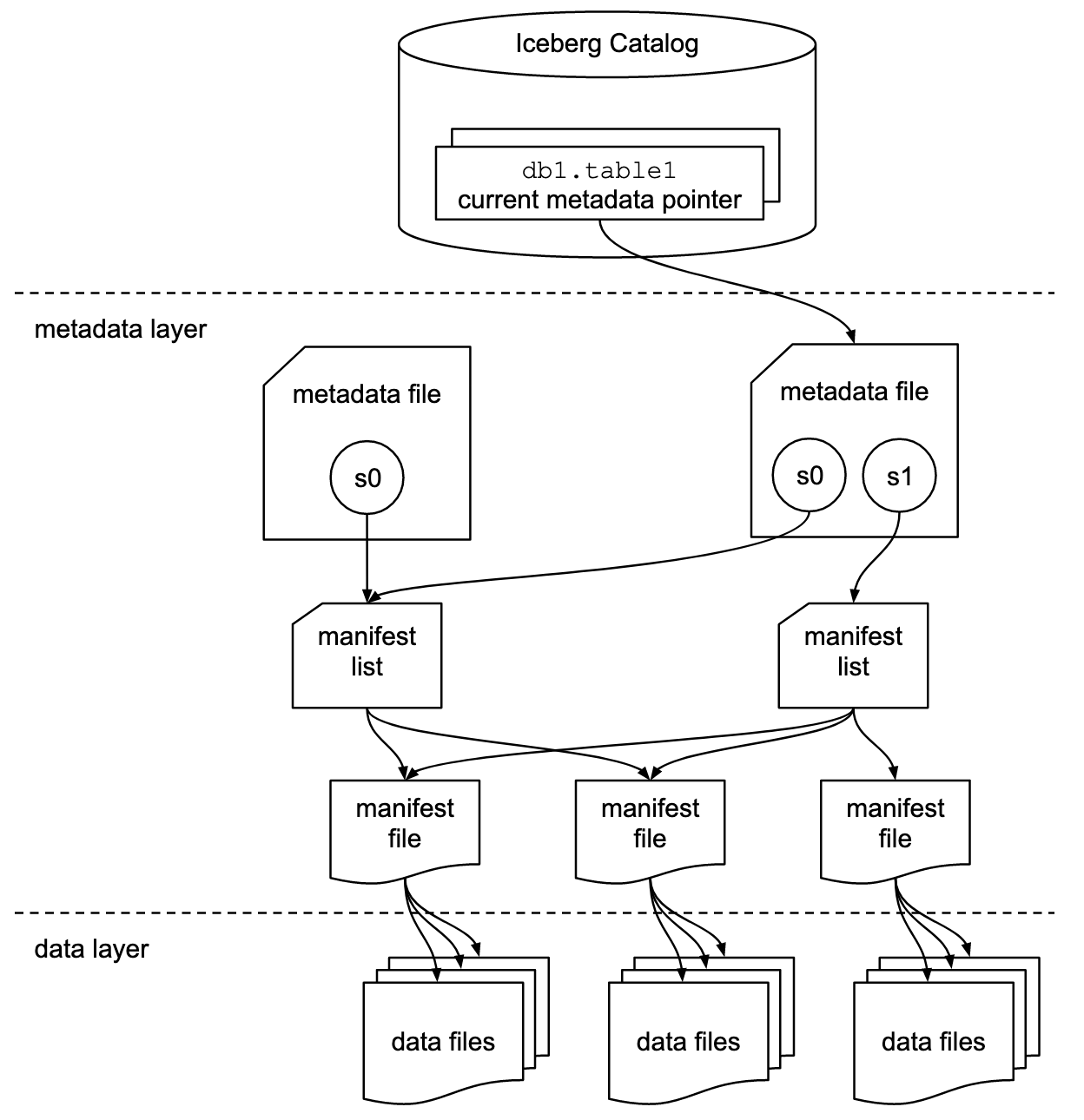
Spécification du format des tableaux Apache Iceberg. Source de l'image : Documentation sur les icebergs.
Delta Lake peut résoudre des problèmes courants et faciliter la gestion des données. Examinons quelques situations clés où il est vraiment utile.
Avec Delta Lake, vous n'avez pas besoin de systèmes distincts pour les différents types de données. Au lieu de cela, vous pouvez disposer d'un système unique qui gère tout. Vous pouvez ajouter de nouvelles données à vos tableaux en temps réel, et elles sont immédiatement prêtes à être analysées. Vos données sont donc toujours à jour.
Vous pouvez créer un flux de travail unique qui traite les anciennes et les nouvelles données afin de rendre l'ensemble de votre système moins complexe et plus facile à gérer. Cette approche unifiée simplifiera vos pipelines de données.
Delta Lake apporte une grande fiabilité aux lacs de données grâce aux transactions ACID. Par exemple :
Le lac Delta assure cette fiabilité en garantissant que tous les changements sont appliqués intégralement ou pas du tout. En outre, il garantit que les données passent toujours d'un état valide à un autre et que les différentes opérations n'interfèrent pas les unes avec les autres.
Delta Lake fonctionne également de manière transparente avec Apache Spark, ce qui constitue un avantage considérable pour de nombreuses organisations. Si vous utilisez déjà Spark, l'ajout de Delta Lake sera simple et ne nécessitera pas de changements majeurs dans votre configuration existante. Votre équipe peut utiliser les mêmes outils Spark et les mêmes commandes SQL que ceux qu'elle connaît déjà.
Par conséquent, il permettra à vos jobs Spark de s'exécuter plus rapidement, en particulier lorsqu'il s'agit de traiter de grandes quantités de données. Pour ce faire, il organise les données de manière plus efficace et utilise des techniques d'indexation intelligentes.
Résumons les principales différences entre Apache Iceberg et Delta Lake pour vous aider à comprendre rapidement les points forts de leurs formats et leurs principales caractéristiques.
|
Caractéristiques |
Iceberg Apache |
Delta Lake |
|
Transaction ACID |
Oui |
Oui |
|
Voyage dans le temps |
Oui |
Oui |
|
Version des données |
Oui |
Oui |
|
Format de fichier |
Parquet, ORC, Avro |
Parquet |
|
Évolution du schéma |
Complet |
Partiel |
|
Intégration avec d'autres moteurs |
Apache Spark, Trino, Flink |
Principalement Apache Spark |
|
Compatibilité avec le cloud |
AWS, GCP, Azure |
AWS, GCP |
|
Moteurs de recherche |
Spark, Trino, Flink |
Spark |
|
Langage de programmation |
SQL, Python, Java |
SQL, Python |
Note : Le meilleur choix dépend de vos besoins, de vos exigences en matière d'évolutivité et de votre stratégie de données à long terme.
Lorsque vous choisissez entre Apache Iceberg et Delta Lake, tenez compte de votre cas d'utilisation spécifique et de votre pile technologique existante. La flexibilité d'Iceberg en matière de formats de fichiers et de moteurs de requête le rend idéal pour les environnements cloud-native. Cependant, l'intégration étroite de Delta Lake avec Apache Spark est une bonne option pour les organisations fortement investies dans l'écosystème Spark.
Vous pouvez également consulter des ressources DataCamp pertinentes pour renforcer votre compréhension des données :
Bon apprentissage !
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours