
Kurs
Einführung in PySpark
4 Std.
157.5K
Bei der Verarbeitung von Big Data wird oft mit unstrukturierten Daten gearbeitet, deren Verwaltung und Analyse eine Herausforderung darstellen kann. Versehentliche Löschungen oder andere Fehler können jederzeit auftreten und stellen ein großes Risiko für die Datenintegrität dar.
Apache Iceberg und Delta Lake sind Open-Source-Tabellenformate, die hauptsächlich für die Verwaltung großer Data Lakes und Lakehouses verwendet werden. Beide Plattformen bieten Funktionen wie Schema-Evolution, Zeitreisen und ACID-Transaktionen, um die Herausforderungen beim Umgang mit großen Datenmengen zu bewältigen. Jede hat ihre eigenen Vorteile, aber sie haben ein gemeinsames Ziel: die Erhaltung der Datenkonsistenz über verschiedene Datensätze hinweg.
In diesem Artikel erkläre ich die wichtigsten Funktionen, Gemeinsamkeiten und architektonischen Unterschiede zwischen Apache Iceberg und Delta Lake, damit du das richtige Tool für deine Bedürfnisse auswählen kannst.

Iceberg wurde von Netflix entwickelt und später an die Apache Software Foundation gespendet, um die Herausforderungen bei der Verwaltung großer Data Lakes zu lösen. Es ist ein hochleistungsfähiges Format für große Analysetabellen, das große Datenmengen effizient verwaltet und abfragt. Seine Funktionen beseitigen viele der Einschränkungen herkömmlicher Data-Lake-Speicheransätze.
Lass uns den Apache Iceberg genauer verstehen.
Hier sind einige der wichtigsten Funktionen von Apache Iceberg, die für Datentechniker bei der Arbeit mit Datensätzen sehr hilfreich sind.
loyalty_points Feld hinzufügen möchtest, kannst du das tun, ohne dass sich das auf bestehende Daten auswirkt oder aktuelle Abfragen unterbrochen werden. Diese Flexibilität ist besonders nützlich für langfristige Datenprojekte, die im Laufe der Zeit angepasst werden müssen.Dank dieser Funktionen eignet sich Iceberg besonders gut für umfangreiche Datenanalysen, vor allem, wenn du mit Daten arbeitest, die sich häufig ändern oder auf die du über lange Zeiträume hinweg auf verschiedene Arten zugreifen musst.
Im Blogbeitrag "Apache Iceberg Explained " erfährst du mehr über diese spannende Technologie.

Delta Lake wurde von Databricks entwickelt und arbeitet nahtlos mit Spark zusammen, was es zu einer beliebten Wahl für Unternehmen macht, die bereits in das Spark-Ökosystem investiert haben. Es ist eine Open-Source-Speicherschicht, die ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability) für Apache Spark und Big-Data-Workloads ermöglicht.
Delta Lake-basierte Data Lakehouses rationalisieren Data Warehousing und maschinelles Lernen, um die Datenqualität durch skalierbare Metadaten, Versionierung und Schemaerzwingung zu erhalten.
Hier sind die wichtigsten Merkmale, die Delta Lake zu einer guten Lösung für die moderne Datenverarbeitung machen:
Der Kurs Big Data Fundamentals with PySpark geht tief in die moderne Datenverarbeitung mit Spark. Es ist eine tolle Auffrischung dieser leistungsstarken Technologie.
Da Apache Iceberg und Delta Lake beide große Datenmengen verwalten, wollen wir ihre grundlegenden Gemeinsamkeiten untersuchen.
Beide Tools können mit ACID-Transaktionen und Versionierung volle Datenkonsistenz gewährleisten. Iceberg verwendet jedoch den Merge-on-Read-Ansatz, während Delta Lake die Merge-on-Write-Strategie verwendet .
Daher handhabt jeder die Leistung und das Datenmanagement anders. Iceberg kann eine vollständige Schemaentwicklung unterstützen, während Delta Lake die Schemakonformität durchsetzt.
Mit der Zeitreisefunktion können Nutzer historische Versionen von Daten abfragen. Das macht sie unschätzbar wertvoll für die Prüfung, Fehlersuche und sogar für die Reproduktion von Experimenten. Sowohl Iceberg als auch Delta Lake unterstützen Zeitreisen, d.h. du kannst unbesorgt auf frühere Datenstände zugreifen.
Apache Iceberg und Delta Lake sind Open-Source-Technologien. Das heißt, jeder kann sie kostenlos nutzen und sogar helfen, sie zu verbessern. Außerdem bedeutet Open-Source, dass du nicht an das Produkt eines Unternehmens gebunden bist - du hast mehr Freiheit, die Tools nach Bedarf zu wechseln oder zu kombinieren. Und da ihr Code öffentlich ist, kannst du ihn sogar für deine eigenen Bedürfnisse optimieren.
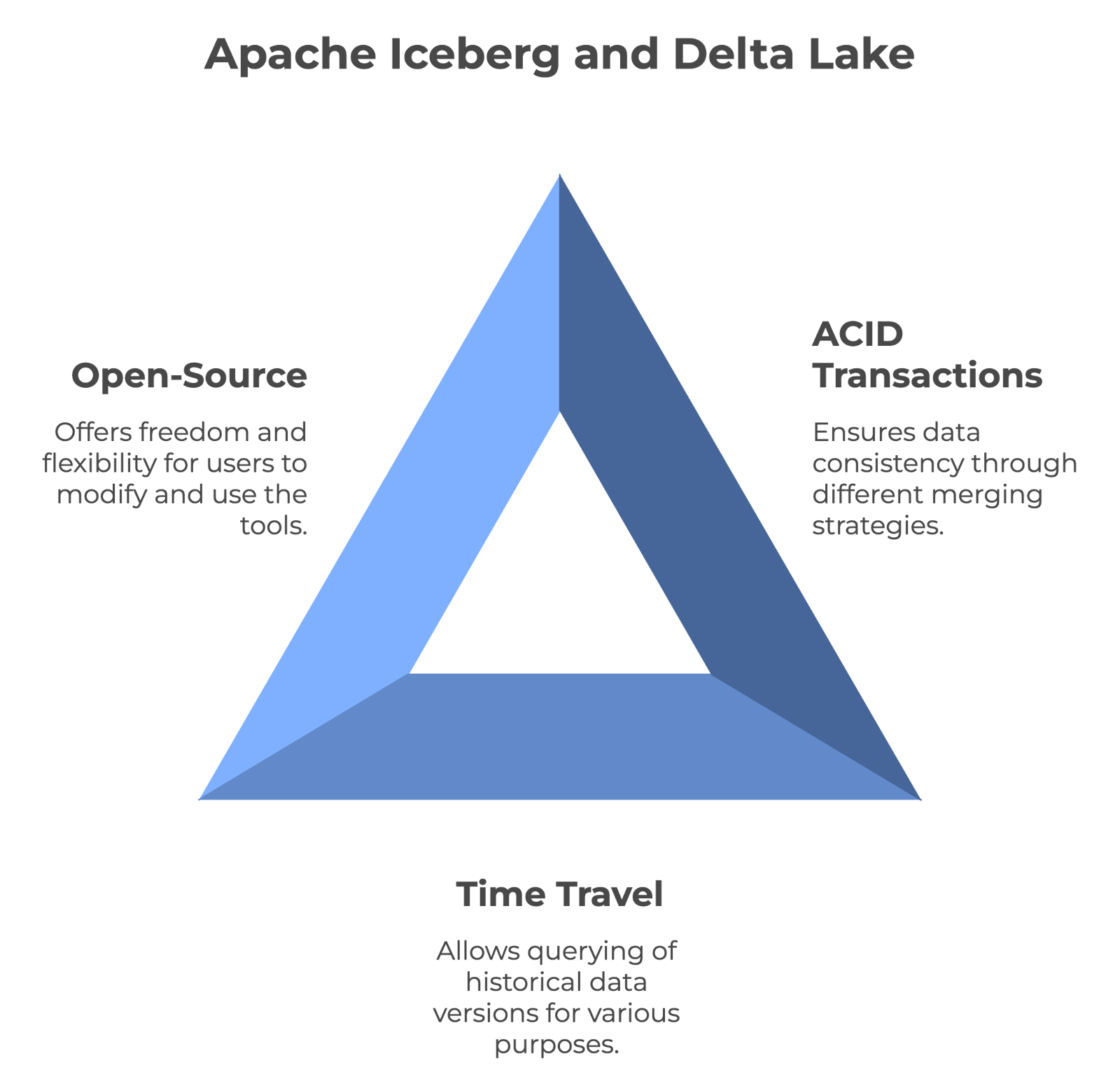
Die wichtigsten Merkmale haben Apache Iceberg und Delta Lake gemeinsam. Bild vom Autor erstellt mit napkin.ai.
Iceberg und Delta Lake haben zwar Gemeinsamkeiten, aber sie unterscheiden sich in ihrer Architektur. Lass uns sehen, wie:
Iceberg und Delta Lake gewährleisten die Zuverlässigkeit der Daten in Data Lakes, aber sie erreichen dies durch unterschiedliche Mechanismen. Iceberg verwendet Snapshots für atomare Transaktionen, um sicherzustellen, dass Änderungen vollständig übertragen oder rückgängig gemacht werden. Aber Delta Lake verwendet Transaktionsprotokolle, um sicherzustellen, dass nur validierte Änderungen in die Tabelle übertragen werden, und sorgt für eine zuverlässige Datenaktualisierung.
Apache Iceberg verwendet eine hierarchische Metadatenstruktur, die Manifestdateien, Manifestlisten und Metadatendateien umfasst. Dieses Design rationalisiert die Abfrageverarbeitung, da kostspielige Operationen wie das Auflisten und Umbenennen von Dateien entfallen.
Delta Lake verwendet jedoch einen transaktionsbasierten Ansatz, um jede Transaktion in einem Protokoll aufzuzeichnen. Um die Abfrageeffizienz zu verbessern und die Protokollverwaltung zu vereinfachen, werden diese Protokolle regelmäßig in Parquet Checkpoint-Dateien konsolidiert, die den kompletten Tabellenstatus erfassen.
Iceberg ist flexibel mit Dateiformaten und kann nativ mit Parquet-, ORC- und Avro-Dateien arbeiten. Das ist hilfreich, wenn du Daten in verschiedenen Formaten hast oder wenn du in Zukunft die Formate wechseln willst, ohne dein ganzes System zu ändern.
Delta Lake speichert Daten hauptsächlich im Parquet-Format, weil Parquet effizient ist, insbesondere für analytische Abfragen. Sie konzentriert sich nur auf ein Format, um die bestmögliche Leistung für diesen speziellen Dateityp zu erzielen.
Iceberg und Delta Lake skalieren Data Lakes, verwenden aber unterschiedliche Strategien. Iceberg legt den Schwerpunkt auf fortschrittliche Datenorganisation mit Funktionen wie Partitionierung und Verdichtung, während Delta Lake mit seiner Delta Engine, der automatischen Verdichtung und den Indizierungsfunktionen auf hohe Leistung setzt.
Apache Iceberg und Delta Lake Kernunterschiede. Bild vom Autor erstellt mit napkin.ai.
Aufgrund seiner einzigartigen Funktionen hat sich Apache Iceberg schnell zu einer Standardlösung für modernes Data Lake Management entwickelt. Schauen wir uns einige seiner wichtigsten Anwendungsfälle an, um seine Stärken zu verstehen.
Hier erfährst du, warum Iceberg eine beliebte Wahl für Unternehmen ist, die Data Lakes in der Cloud betreiben:
Teams, die mit komplexen Datenmodellen arbeiten, finden Iceberg aus folgenden Gründen besonders nützlich:
Iceberg ist mit verschiedenen Tools kompatibel, was es zu einer vielseitigen Wahl für das Datenökosystem macht. Werfen wir einen Blick auf einige der wichtigsten Integrationen:
Iceberg funktioniert nahtlos mit den folgenden Produkten:
Die folgenden großen Cloud-Anbieter bieten native Unterstützung für Iceberg:
Iceberg bietet auch Client-Bibliotheken für verschiedene Programmiersprachen, wie z.B.:
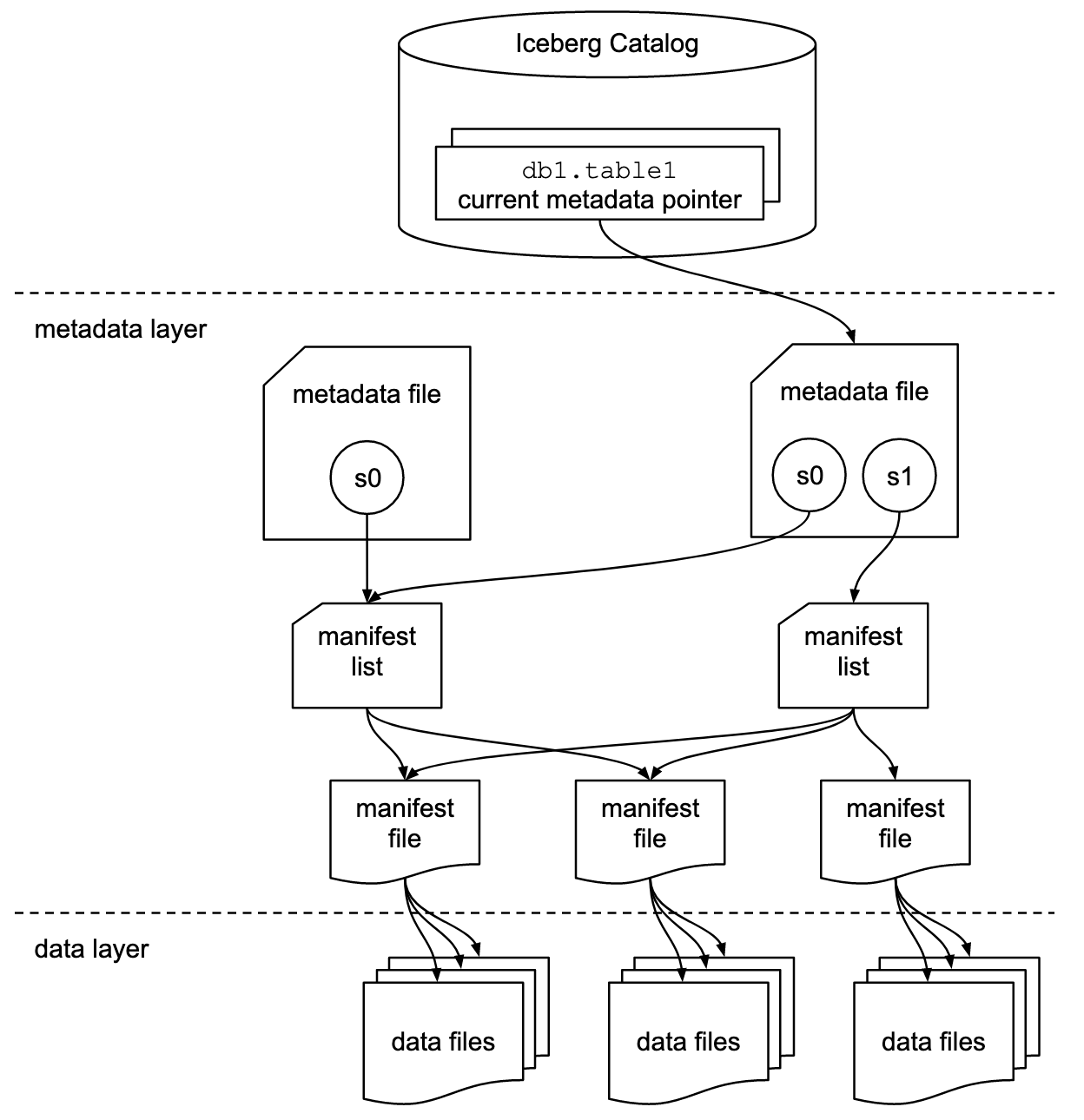
Apache Iceberg Tabellenformat Spezifikation. Bildquelle: Eisberg Dokumentation.
Delta Lake kann gängige Herausforderungen lösen und die Datenverwaltung vereinfachen. Schauen wir uns einige Schlüsselsituationen an, in denen es wirklich hilft.
Mit Delta Lake brauchst du keine separaten Systeme für verschiedene Datentypen. Stattdessen kannst du ein System haben, das alles regelt. Du kannst neue Daten in Echtzeit zu deinen Tabellen hinzufügen und sie sind sofort für die Analyse bereit. Das bedeutet, dass deine Daten immer aktuell sind.
Du kannst einen einzigen Arbeitsablauf erstellen, der alte und neue Daten verarbeitet, damit dein ganzes System weniger komplex und einfacher zu verwalten ist. Dieser einheitliche Ansatz wird deine Datenpipelines vereinfachen.
Delta Lake bringt durch ACID-Transaktionen eine hohe Datensicherheit in Data Lakes. Zum Beispiel:
Delta Lake erreicht diese Zuverlässigkeit, indem es sicherstellt, dass alle Änderungen entweder vollständig oder gar nicht übernommen werden. Außerdem stellt es sicher, dass die Daten immer von einem gültigen Zustand in einen anderen übergehen und dass sich die verschiedenen Vorgänge nicht gegenseitig stören.
Delta Lake arbeitet auch nahtlos mit Apache Spark zusammen, ein großer Vorteil für viele Unternehmen. Wenn du bereits Spark verwendest, ist das Hinzufügen von Delta Lake ganz einfach und erfordert keine großen Änderungen an deinem bestehenden System. Dein Team kann die gleichen Spark-Tools und SQL-Befehle verwenden, mit denen es vertraut ist.
Dadurch werden deine Spark-Jobs schneller ausgeführt, vor allem wenn du mit großen Datenmengen arbeitest. Dies geschieht durch eine effizientere Organisation der Daten und intelligente Indexierungstechniken.
Im Folgenden fassen wir die wichtigsten Unterschiede zwischen Apache Iceberg und Delta Lake zusammen, damit du die Stärken und wichtigsten Funktionen der beiden Formate schnell verstehst.
|
Eigenschaften |
Apache Iceberg |
Deltasee |
|
ACID-Transaktion |
Ja |
Ja |
|
Zeitreise |
Ja |
Ja |
|
Datenversionierung |
Ja |
Ja |
|
Dateiformat |
Parquet, ORC, Avro |
Parquet |
|
Schema-Entwicklung |
Vollständig |
Partial |
|
Integration mit anderen Engines |
Apache Spark, Trino, Flink |
Vor allem Apache Spark |
|
Cloud-Kompatibilität |
AWS, GCP, Azure |
AWS, GCP |
|
Query Engines |
Spark, Trino, Flink |
Funke |
|
Programmiersprache |
SQL, Python, Java |
SQL, Python |
Hinweis: Die beste Wahl hängt von deinen Bedürfnissen, deinen Anforderungen an die Skalierbarkeit und deiner langfristigen Datenstrategie ab.
Wenn du dich zwischen Apache Iceberg und Delta Lake entscheidest, solltest du deinen spezifischen Anwendungsfall und deinen bestehenden Technologie-Stack berücksichtigen. Icebergs Flexibilität bei Dateiformaten und Abfrage-Engines macht es ideal für Cloud-native Umgebungen. Die enge Integration von Delta Lake mit Apache Spark ist jedoch eine gute Option für Unternehmen, die stark in das Spark-Ökosystem investiert haben.
Du kannst dir auch einige relevante DataCamp-Ressourcen ansehen, um dein bestehendes Datenverständnis zu stärken:
Viel Spaß beim Lernen!
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
