
Course
Foundations of PySpark
4 hr
157.5K
Big data processing often involves working with unstructured data, which can be challenging to manage and analyze. Accidental deletions or other errors may occur at any point — posing a major risk to data integrity.
Apache Iceberg and Delta Lake are open-source table formats primarily used for managing large-scale data lakes and lakehouses. Both platforms provide features like schema evolution, time travel, and ACID transactions to address the challenges of handling massive datasets. While each has unique advantages, they share a common goal: maintaining data consistency across datasets.
In this article, I’ll explain the key features, similarities, and architectural differences between Apache Iceberg and Delta Lake to help you choose the right tool for your needs.

Developed by Netflix and later donated to the Apache Software Foundation, Iceberg aims to solve the challenges of managing large-scale data lakes. It’s a high-performance format for large analytic tables that efficiently manages and queries massive datasets. Its features address many of the limitations of traditional data lake storage approaches.
Let’s understand Apache Iceberg in more detail.
Here are some of Apache Iceberg's most prominent features, which are very helpful for data engineers when working with datasets.
loyalty_points field, you can do it without affecting existing data or breaking current queries. This flexibility is especially useful for long-term data projects that need to adapt over time.These features make Iceberg particularly good for large-scale data analytics, especially if you deal with data that changes frequently or needs to be accessed in various ways over long periods.
Check out the Apache Iceberg Explained blog post for a deep dive into this exciting technology.

Developed by Databricks, Delta Lake seamlessly works with Spark, making it a popular choice for organizations already invested in the Spark ecosystem. It’s an open-source storage layer that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to Apache Spark and big data workloads.
Delta Lake-based data lakehouses streamline data warehousing and machine learning to maintain data quality through scalable metadata, versioning, and schema enforcement.
Here are the key features that make Delta Lake a good solution for modern data processing:
The course Big Data Fundamentals with PySpark goes deep into modern data processing with Spark. It is a great refresher on this powerful technology.
Since Apache Iceberg and Delta Lake both manage large amounts of data, let's examine their fundamental similarities.
Both tools can provide full data consistency using ACID transactions and versioning. However, Iceberg uses the merge-on-read approach, whereas Delta Lake uses the merge-on-write strategy.
As a result, each handles performance and data management differently. Iceberg can provide full schema evolution support, while Delta Lake enforces schema compliance.
Time travel functionality allows users to query historical versions of data. This makes it invaluable for auditing, debugging, and even reproducing experiments. Both Iceberg and Delta Lake support time travel, which means you can access previous states of data without worrying.
Apache Iceberg and Delta Lake are open-source technologies. This means anyone can use them for free and even help improve them. In addition, being open-source means you're not tied to one company's product — you have more freedom to switch or combine tools as needed. And since their code is public, you can even optimize it for your specific needs.
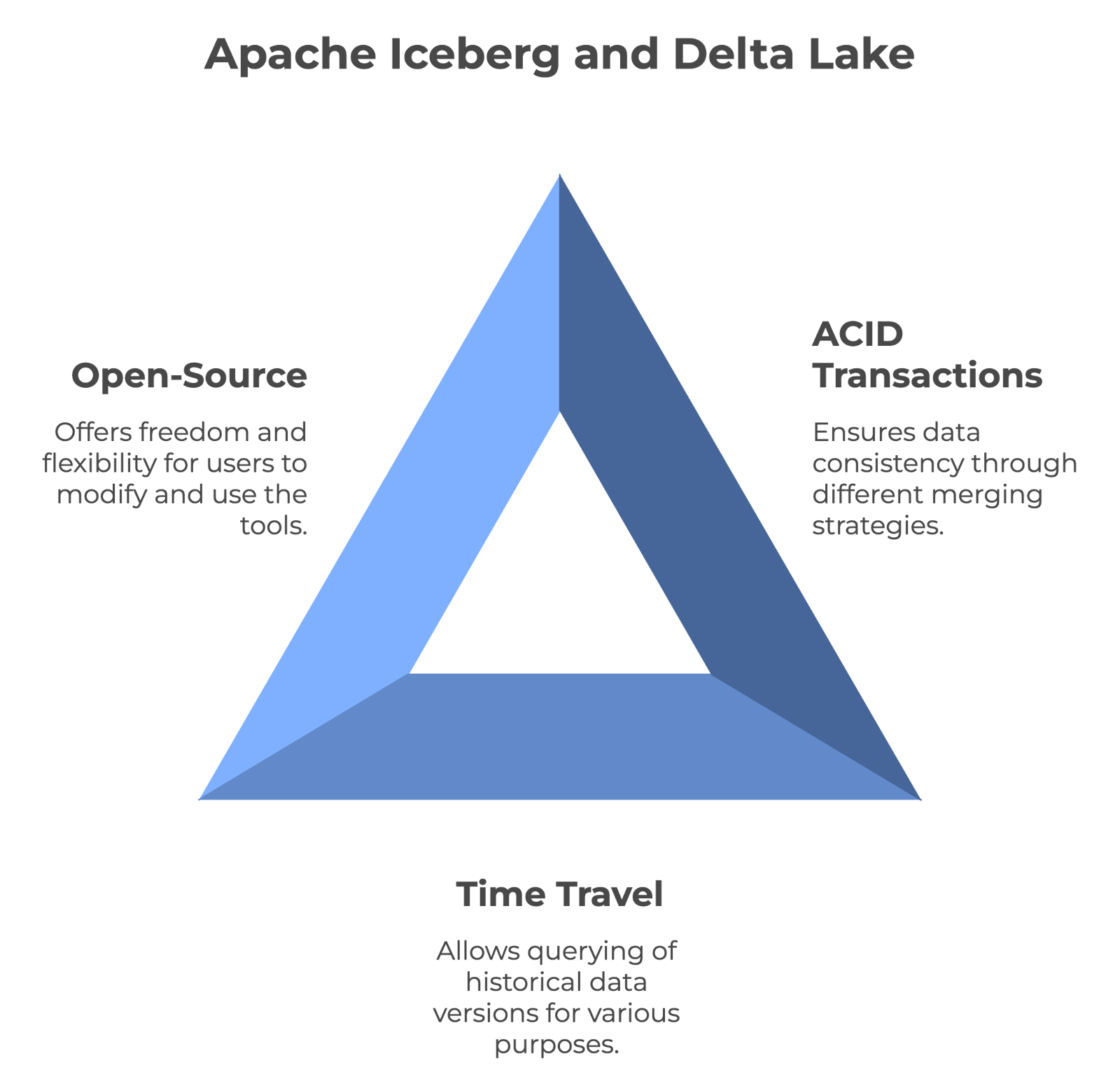
The main features shared by Apache Iceberg and Delta Lake. Image by Author created with napkin.ai.
While Iceberg and Delta Lake share similarities, they differ in architecture. Let's see how:
Iceberg and Delta Lake ensure data reliability in data lakes, but they achieve this through different mechanisms. Iceberg uses snapshots for atomic transactions to ensure changes are fully committed or rolled back. But Delta Lake uses transaction logs to ensure that only validated changes are committed to the table and provides reliability in data updates.
Apache Iceberg employs a hierarchical metadata structure, which includes manifest files, manifest lists, and metadata files. This design streamlines query processing by eliminating costly operations like file listing and renaming.
However, Delta Lake adopts a transaction-based approach to record each transaction in a log. To enhance query efficiency and simplify log management, it periodically consolidates these logs into Parquet checkpoint files, which capture the complete table state.
Iceberg is flexible with file formats and can work natively with Parquet, ORC, and Avro files. This is helpful if you have data in different formats or if you want to switch formats in the future without changing your entire system.
Delta Lake primarily stores data in the Parquet format because Parquet is efficient, especially for analytical queries. It only focuses on one format to give the best possible performance for that specific file type.
Iceberg and Delta Lake scale data lakes but employ different strategies. Iceberg prioritizes advanced data organization with features like partitioning and compaction, while Delta Lake emphasizes high performance through its Delta Engine, auto compaction, and indexing capabilities.
Apache Iceberg and Delta Lake core differences. Image by Author created with napkin.ai.
Due to its unique features, Apache Iceberg has quickly become a go-to solution for modern data lake management. Let’s examine some of its primary use cases to understand its strengths.
Here's why Iceberg is a popular choice for organizations building data lakes that operate at a cloud scale:
Teams dealing with complex data models find Iceberg particularly useful because of the following:
Iceberg is compatible with diversified tools, making it a versatile choice for the data ecosystem. Let’s take a look at some of its key integrations:
Iceberg works seamlessly with the following:
The following major cloud providers offer native support for Iceberg:
Iceberg also provides client libraries for different programming languages, such as:
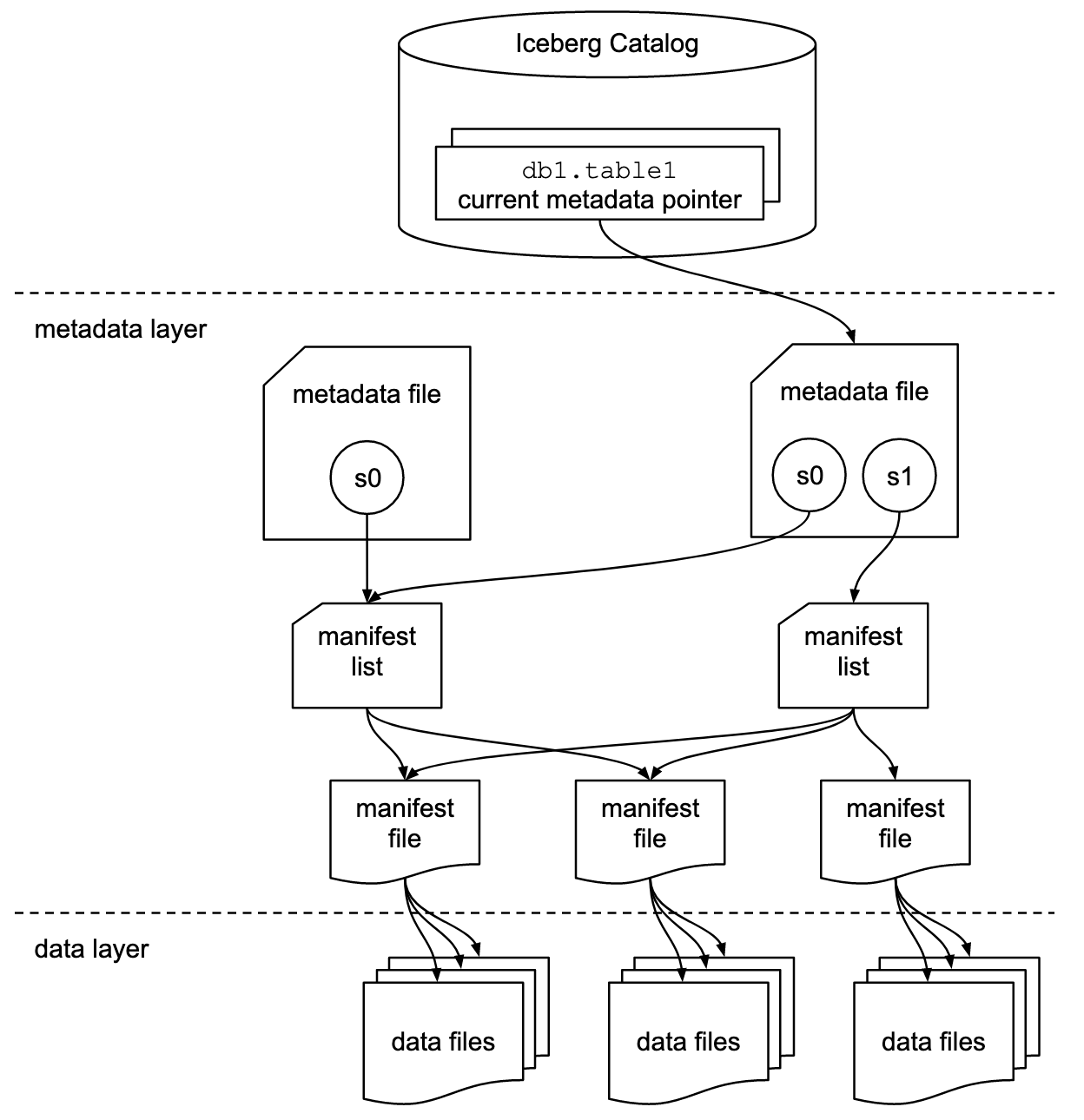
Apache Iceberg table format specification. Image source: Iceberg documentation.
Delta Lake can solve common challenges and make data management easier. Let's examine some key situations where it really helps.
With Delta Lake, you don't need separate systems for different data types. Instead, you can have one system that handles everything. You can add new data to your tables in real time, and it's immediately ready for analysis. This means your data is always up-to-date.
You can build a single workflow that handles old and new data to make your whole system less complex and easier to manage. This unified approach will simplify your data pipelines.
Delta Lake brings strong data reliability to data lakes through ACID transactions. For example:
Delta Lake achieves this reliability by ensuring that all changes are either completely applied or not at all. In addition, it ensures that data always moves from one valid state to another and that different operations don't interfere with each other.
Delta Lake also works seamlessly with Apache Spark, a big advantage for many organizations. If you're already using Spark, adding Delta Lake would be simple and won’t require major changes to your existing setup. Your team can use the same Spark tools and SQL commands they're familiar with.
As a result, it will make your Spark jobs run faster, especially when dealing with large amounts of data. It does this by organizing data more efficiently and using smart indexing techniques.
Let's summarize the key differences between Apache Iceberg and Delta Lake to help you quickly understand their format strengths and key features.
|
Features |
Apache Iceberg |
Delta Lake |
|
ACID transaction |
Yes |
Yes |
|
Time travel |
Yes |
Yes |
|
Data versioning |
Yes |
Yes |
|
File format |
Parquet, ORC, Avro |
Parquet |
|
Schema evolution |
Full |
Partial |
|
Integration with other engines |
Apache Spark, Trino, Flink |
Primarily Apache Spark |
|
Cloud Compatibility |
AWS, GCP, Azure |
AWS, GCP |
|
Query Engines |
Spark, Trino, Flink |
Spark |
|
Programming Language |
SQL, Python, Java |
SQL, Python |
Note: The best choice depends on your needs, scalability requirements, and long-term data strategy.
When choosing between Apache Iceberg and Delta Lake, consider your specific use case and existing technology stack. Iceberg's flexibility with file formats and query engines makes it ideal for cloud-native environments. However, Delta Lake's tight integration with Apache Spark is a good option for organizations heavily invested in the Spark ecosystem.
You can check out some relevant DataCamp resources too to strengthen your existing data understanding:
Happy learning!
Learn more about data engineering with these courses!
Course
Course
Course
blog
Austin Chia
10 min
blog
DataCamp Team
4 min
blog
Laiba Siddiqui
9 min
blog
Gus Frazer
12 min
blog
Gus Frazer
14 min
Tutorial
Gus Frazer
