
programa
Analista de datos asociado en SQL
39 h
Usuarios y seguidores, estudiantes y cursos, clientes y productos: nuestro mundo está lleno de relaciones naturales de muchos a muchos. Sin embargo, esto no siempre se traduce bien en los diseños de bases de datos. Las relaciones muchos a muchos mal diseñadas son una de las causas más comunes de duplicación de datos, análisis incorrectos y problemas de mantenimiento a largo plazo en los sistemas de producción.
En este artículo, repasaré las relaciones muchos a muchos desde los principios básicos hasta su implementación en el mundo real. También exploraremos patrones de diseño avanzados, normalización, consideraciones de rendimiento y cómo se implementan las relaciones muchos a muchos en los sistemas relacionales y nosql.
Al finalizar, deberías ser capaz de diseñar esquemas escalables y fáciles de mantener que modelen correctamente relaciones complejas, eviten anomalías en los datos y admitan flujos de trabajo fiables de generación de informes y BI.
Para los lectores que deseen reforzar los conceptos básicos a lo largo del curso, recomiendo realizar nuestro curso Introducción a las bases de datos relacionales en SQL .
Una relación muchos a muchos (M:N) es una relación bidireccional entre bases de datos en la que cada registro de la tabla A puede relacionarse con muchos registros de la tabla B, y cada registro de la tabla B puede relacionarse con muchos registros de la tabla A. A diferencia de los tipos de relación más simples, la cardinalidad existe en ambos lados.
Esta relación es omnipresente en los sistemas reales:
La relación tiene significado y, a menudo, datos propios. Comprender esta distinción es fundamental para diseñar esquemas y realizar consultas correctamente, especialmente cuando unir tablas para realizar análisis.
Para entender por qué las relaciones muchos a muchos requieren un tratamiento especial, resulta útil compararlas con cardinalidades más simples.
|
Tipo de relación |
Descripción |
Lógica |
Ejemplo |
|
Uno a uno (1:1) |
Cada registro de la tabla A se corresponde exactamente con uno de la tabla B. |
Maridaje único. |
Usuario ↔ Perfil de usuario |
|
Uno a muchos (1:N) |
Un registro de la tabla A se relaciona con muchos de la tabla B, pero los registros de la tabla B solo tienen un padre. |
Estructura padre/hijo. |
Cliente → Pedidos múltiples |
|
Muchos a muchos (M:N) |
Varios registros de la tabla A se relacionan con varios registros de la tabla B. |
Web bidireccional. |
Estudiantes ↔ Cursos |
Por ejemplo,e, en un diseño uno a muchos, una tabla de pedidos suele contener una clave externa customer_id, y cada pedido único tiene un order_id. Cada pedido pertenece exactamente a un cliente, pero un cliente puede tener muchas claves order_id.
Ahora compara esto con el ejemplo del estudiante y el curso. Si intentas almacenar course_id directamente en la tabla de estudiantes, cada estudiante estaría vinculado a múltiples valores course_id. Por el contrario, dentro de la tabla de cursos, cada curso tendría múltiples referencias student_id. En lugar de una relación unidireccional clara, ambas direcciones comparten información en ambos sentidos.
Un problema habitual es intentar representar relaciones muchos a muchos directamente almacenando varios valores en una sola columna utilizando un arreglo (por ejemplo, course_ids en una tabla students ) o columnas repetidas como course_1, course_2, course_3.
Este enfoque viola la primera forma normal (1NF), que exige que cada columna contenga valores atómicos e indivisibles. Lee este blog sobre normalización en SQL para refrescar tus conocimientos.
Violar la 1NF conduce a anomalías de actualización clásicas:
Más allá de la teoría de la normalización, existe una grave consecuencia analítica conocida como el problema «muchos a muchos». Cuando las tablas con una relación muchos a muchos no se unen con cuidado, se puede producir fácilmente una multiplicación de filas. Esto puede causar problemas con el tiempo de cálculo y errores de agregación para el análisis.
Por ejemplo, unir courses con students basándose en student_id puede provocar que cada curso se una varias veces debido a las múltiples entradas de los estudiantes. Entonces, intentar la agregación puede dar lugar a discrepancias analíticas, como en los ingresos o el número de estudiantes.
El diseño correcto del esquema afecta directamente a la precisión de los informes, los cálculos financieros y la confianza en los productos de datos. Además, ayuda a simplificar las uniones para minimizar los errores humanos. Para obtener más información sobre los errores más comunes al realizar uniones, consulta este tutorial sobre uniones SQL y practica con estas 20 preguntas más frecuentes sobre uniones SQL.
La solución estándar para las relaciones muchos a muchos en los sistemas relacionales es la tabla de unión (también llamada tabla de enlace, tabla puente o tabla asociativa). En lugar de intentar almacenar las relaciones directamente, introduces una tabla intermedia que hace referencia a ambas tablas principales.
Conceptualmente, esto transforma A ↔ B en A ← JT→ B.
Ahora, cada uno tiene una relación uno a muchos con la tabla de unión, lo que permite un esquema analítico simplificado. Repasaré cómo creamos estas tablas de unión y cómo se utilizan.
Una tabla de unión básica contiene:
En la mayoría de los casos, estas dos claves externas juntas forman una clave primaria compuesta. Esto garantiza que la misma relación no se pueda insertar dos veces y garantiza la unicidad a nivel de la base de datos.
Por ejemplo, una tabla enrollments podría utilizar una concatenación de student_id y course_id como clave principal. La base de datos ahora tiene una clave de referencia única para la relación y podemos empezar a crear casos de uso empresarial.
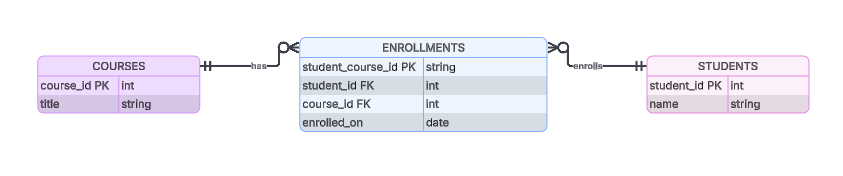
Ejemplo de cómo podría ser una tabla de unión enrollments.
Cuando una tabla de unión almacena atributos adicionales, se acerca más a una entidad asociativa que a un artefacto puramente estructural. Esto permite que la tabla de unión contenga información contextual sobre la relación. Algunos ejemplos comunes son:
Fecha: enrollment_date, creation_date y otra información similar basada en el tiempo.
Función: por ejemplo, administrador frente a miembro en un grupo.
Métricas: puntuación de relevancia en los sistemas de recomendación
Esto ayuda a que la relación tenga más significado. La complejidad de las consultas aumenta ligeramente, pero el esquema modela la realidad con mayor precisión. Esta compensación casi siempre vale la pena en sistemas donde las relaciones evolucionan con el tiempo. Podemos añadir más información y convertir las tablas de unión en una herramienta analítica útil.
Las tablas de unión dependen en gran medida de la integridad referencial. Las restricciones de clave externa garantizan que cada fila de relación haga referencia a registros principales válidos, lo que evita los datos huérfanos.
Las reglas de eliminación son importantes:
La elección depende de la semántica empresarial. En algunos ámbitos, la limpieza automática es adecuada; en otros, las relaciones históricas deben conservarse o revisarse explícitamente antes de eliminarlas.
Las tablas de unión son una aplicación directa de la tercera forma normal (3NF). Eliminan las dependencias transitivas y eliminan el almacenamiento redundante de datos de relaciones. Tu objetivo principal es mejorar la normalización dentro de la base de datos.
En muchos casos, las tablas de unión también ayudan a satisfacer la forma normal de Boyce-Codd (BCNF), ya que la clave primaria compuesta determina completamente todos los atributos que no son clave. Esto es importante porque minimiza las anomalías en las actualizaciones y garantiza que, para modificar una relación, solo sea necesario cambiar una fila.
Para comprender mejor la importancia de garantizar la 3NF en nuestras bases de datos, consulta este artículo sobre dependencia transitiva.
Analicemos cómo podemos crear nuestras bases de datos para que admitan relaciones muchos a muchos. Te explicaremos las buenas prácticas que te facilitarán la vida.
Una nomenclatura clara de las tablas reduce la carga cognitiva y mejora la facilidad de mantenimiento. Las convenciones comunes suelen incluir TableA_TableB o join_TableATableB, por ejemplo:
student_course
user_group
join_user_group
Los nombres de las columnas deben reflejar las claves primarias de la tabla principal (por ejemplo, student_id, course_id) para que las uniones sean claras y legibles. La coherencia se vuelve fundamental a medida que los esquemas crecen y los equipos se amplían.
Hay varias formas de crear tablas de unión, desde el seguimiento de relaciones muy sencillas hasta relaciones polimórficas más complejas.
Las tablas de unión simples contienen solo claves externas y son ideales para relaciones estáticas o con poco contexto. Son muy fáciles de mantener y requieren un esfuerzo mínimo, ya que normalmente solo se ocupan de mostrar cómo se relacionan dos tablas. Estas tablas de unión no contienen datos temporales ni contextuales.
Las relaciones muchos a muchos autorreferenciales se producen cuando ambas claves externas hacen referencia a la misma tabla.
Por ejemplo, si estamos realizando un seguimiento de una aplicación de redes sociales que incluye el seguimiento de los usuarios, sus seguidores y a quiénes siguen, podríamos tener una relación de user_id a follower_id en ambas direcciones. Es posible que se requieran restricciones adicionales para evitar duplicados inválidos o simétricos.
Las relaciones polimórficas muchos a muchos permiten que una tabla de unión conecte varios tipos de entidades mediante un discriminador de tipos. Esto proporciona flexibilidad, pero traslada la aplicación de la integridad a la lógica de la aplicación y complica las consultas.
Por ejemplo, una tabla de unión llamada Tag para aplicaciones de redes sociales podría relacionar Posts, Comments y Users con una columna contextual adicional para asociar la etiqueta con la entidad adecuada.
Las relaciones temporales y ponderadas almacenan información sobre la relación en atributos adicionales.
Las relaciones temporales muchos a muchos añaden columnas que proporcionan información temporal, como active_from, active_to o created_on, para realizar un seguimiento de la validez histórica. La clave « enrolled_on » (Estudiante-Curso) de nuestra base de datos anterior es un ejemplo de relación temporal.
Son esenciales para las pistas de auditoría, las relaciones que cambian lentamente y el análisis puntual. Esto añade un poco de complejidad, ya que los usuarios deben tener cuidado de filtrar en la escala temporal adecuada y tener en cuenta las filas que pueden estar inactivas.
Las relaciones ponderadas, por otro lado, almacenan métricas de clasificación o fuerza. Los motores de recomendación, los sistemas de etiquetado y la puntuación de relevancia suelen basarse en este patrón para realizar un seguimiento de aspectos como la confianza en las recomendaciones.
Mientras que la mayoría de los sistemas OLTP evitan las relaciones que involucran a más de dos entidades, los sistemas analíticos las utilizan con frecuencia. Las tablas de hechos en los modelos dimensionales actúan eficazmente como tablas de unión que conectan tablas con distintos niveles de granularidad. Estos diseños son potentes, pero requieren consultas disciplinadas y una documentación clara.
Un posible diseño sería crear una tabla de unión con claves externas para todas las entidades participantes.
Por ejemplo, si partimos de nuestro ejemplo de alumnos y cursos, una tercera tabla podría ser la de números de aulas. Una tabla de unión puede contener las claves externas de un estudiante en una clase concreta en una sala concreta. Es fácil ver que, a medida que aumentamos el número de relaciones, las consultas y los esquemas se vuelven exponencialmente más complejos.
Para profundizar en la creación de bases de datos, no te pierdas nuestro curso sobre diseño de bases de datos.
Con cualquier diseño de base de datos complicado, hay que tener en cuenta el rendimiento y las consideraciones relativas a las consultas. Cuantas más piezas añadamos, más probable será que nos encontremos con cuellos de botella en el rendimiento.
Veamos primero algunas formas en las que podríamos consultar nuestras tablas de unión. Los patrones de acceso comunes incluyen:
Para optimizar estas consultas:
Indexa las claves externas en la tabla de unión.
Utiliza GROUP BY o DISTINCT para evitar el recuento excesivo.
Considera la posibilidad de cubrir los índices para cargas de trabajo con gran volumen de lecturas.
Sé específico con las instrucciones « WHERE » para limitar la cantidad de datos que se unen.
Estas técnicas son fundamentales para realizar uniones y agregaciones eficientes. Recuerda también que, si intentas utilizar la tabla de unión para conectar dos tablas, es conveniente pensar en cómo se podrían unir tres tablas de manera eficiente.
Las tablas de unión suelen tener un alto volumen de escritura. Las inserciones y actualizaciones por lotes reducen la sobrecarga de las transacciones.
Sin embargo, una alta contienda por claves externas populares puede crear cuellos de botella en el bloqueo. Asegúrate de supervisar el rendimiento y las tablas de particiones para permitir la paralelización.
Dediquemos un momento a analizar la diferencia clave entre la normalización y la desnormalización como enfoque para el diseño de tu base de datos:
Piensa detenidamente en los patrones de acceso, la experiencia del equipo y las limitaciones operativas.
La desnormalización puede mejorar el rendimiento en sistemas con gran volumen de escritura que no cambian con frecuencia. El costo es una mayor complejidad, una mayor carga de mantenimiento y el riesgo de que los datos queden obsoletos.
Mi humilde opinión: La desnormalización solo debe ser una respuesta mesurada a los cuellos de botella con gran volumen de lectura y siempre debe construirse con comprobaciones de coherencia periódicas.
Los sistemas SQL y nosql tienen enfoques ligeramente diferentes para la implementación de sistemas muchos a muchos.
Las bases de datos relacionales como PostgreSQL, MySQL y SQL Server implementan relaciones muchos a muchos de forma explícita utilizando tablas de unión con claves externas y claves primarias compuestas. Del mismo modo, las bases de datos relacionales basadas en la nube, como Snowflake, siguen un patrón de diseño similar.
Los sistemas nosql suelen representar relaciones muchos a muchos mediante la incorporación de arreglos de ID relacionados o el almacenamiento de referencias gestionadas por la lógica de la aplicación. Esto se debe a la prioridad del rendimiento de lectura y la escalabilidad horizontal en las bases de datos nosql. Esto mejora el rendimiento de lectura y la flexibilidad del esquema, pero sacrifica la normalización.
|
Característica |
Relacional (SQL) |
NoSQL |
|
Implementación |
Tablas de unión: Utiliza una tercera tabla con claves externas y claves primarias compuestas. |
Incrustar o hacer referencia: Utiliza arreglos de ID o documentos anidados. |
|
Objetivo principal |
Normalización: Garantiza la coherencia de los datos y elimina la redundancia. |
Rendimiento: Da prioridad a la velocidad de lectura y a la escalabilidad horizontal. |
|
Flexibilidad |
Esquema rígido: Requiere estructuras predefinidas y uniones para recuperar datos. |
Alta flexibilidad: Permite diseños sin esquema y tipos de datos variados. |
|
Compensación |
Uniones complejas: Puede volverse más lento a medida que el conjunto de datos crece significativamente. |
Sacrificios Normalización: Puede provocar la duplicación de datos o datos «obsoletos». |
|
Ejemplos |
PostgreSQL, MySQL, SQL Server, Snowflake. |
MongoDB, DynamoDB, Cassandra. |
Las bases de datos relacionales son las preferidas cuando necesitas una estructura de esquema bien definida. Estas bases de datos son más fáciles de manejar y permiten una mejor gestión de los datos. Considera la posibilidad de utilizar una base de datos SQL relacional cuando:
Las bases de datos nosql son adecuadas para situaciones en las que la flexibilidad y la operatividad masiva son prioridades. Por ejemplo, las bases de datos nosql como MongoDB permiten el uso de operadores como updateMany cuando necesitamos actualizar una gran cantidad de documentos. A continuación, se incluyen algunos principios básicos que deben tenerse en cuenta a la hora de plantearse la implementación de nosql:
Las relaciones muchos a muchos son inevitables en los modelos de datos realistas. Diseñarlos correctamente es fundamental para la integridad de los datos, la escalabilidad y la precisión analítica. Las tablas de unión, cuando están correctamente normalizadas e indexadas, proporcionan una base sólida que se adapta desde los sistemas transaccionales hasta el análisis empresarial.
Todo diseño implica concesiones: normalización frente a rendimiento, simplicidad frente a flexibilidad y abstracción frente a control. La clave está en perfilar tus patrones de acceso, elegir patrones que se ajusten a tu carga de trabajo y validar los diseños mediante la revisión del esquema y las pruebas de consultas.
Para los profesionales que deseen profundizar sus conocimientos en diseño de bases de datos, recomiendo encarecidamente inscribirse en nuestro programa de formación profesional de Analista de Datos Asociado en SQL.
Cursos de diseño de bases de datos
programa
Curso
Curso
blog
Kurtis Pykes
11 min
Tutorial
Nic Raboy
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
Oluseye Jeremiah

