
Lernpfad
Assoziierter Datenanalyst in SQL
39 Std.
Nutzer und Follower, Studenten und Kurse, Kunden und Produkte: Unsere Welt ist voll von natürlichen Mehr-zu-Mehr-Beziehungen. Allerdings lassen sich diese nicht immer gut in Datenbankdesigns umsetzen. Schlecht gemachte viele-zu-viele-Beziehungen sind oft der Grund für doppelte Daten, falsche Analysen und langfristige Probleme bei der Wartung in Produktionssystemen.
In diesem Artikel werde ich Many-to-Many-Beziehungen von den Grundlagen bis zur praktischen Umsetzung durchgehen. Wir schauen uns auch fortgeschrittene Designmuster, Normalisierung, Performance-Überlegungen und die Implementierung von Many-to-Many-Beziehungen in relationalen und nosql-Systemen an.
Am Ende solltest du in der Lage sein, skalierbare, wartungsfreundliche Schemata zu entwerfen, die komplexe Beziehungen korrekt abbilden, Datenanomalien vermeiden und zuverlässige Berichts- und BI-Workflows unterstützen.
Für alle, die ihre Grundlagenkenntnisse auffrischen wollen, empfehle ich unseren Kurs Einführung in relationale Datenbanken in SQL zu machen.
Eine Viele-zu-Viele-Beziehung (M:N) ist eine bidirektionale Datenbankbeziehung, bei der jeder Datensatz in Tabelle A mit vielen Datensätzen in Tabelle B in Verbindung stehen kann und jeder Datensatz in Tabelle B mit vielen Datensätzen in Tabelle A in Verbindung stehen kann. Anders als bei einfacheren Beziehungstypen gibt es hier Kardinalität auf beiden Seiten.
Diese Beziehung ist in echten Systemen überall zu finden:
Die Beziehung hat eine Bedeutung und oft auch eigene Daten. Dieses Unterschied zu verstehen ist wichtig für die richtige Schema-Gestaltung und Abfrage, vor allem wenn Tabellen für Analysen zusammengeführt werden.
Um zu verstehen, warum viele-zu-viele-Beziehungen eine spezielle Behandlung brauchen, hilft es, sie mit einfacheren Kardinalitäten zu vergleichen.
|
Beziehungstyp |
Beschreibung |
Logik |
Beispiel |
|
Eins-zu-eins (1:1) |
Jeder Eintrag in Tabelle A passt genau zu einem in Tabelle B. |
Einzigartige Kombination. |
Benutzer ↔ Benutzerprofil |
|
Eins-zu-Viele (1:N) |
Ein Datensatz in Tabelle A ist mit mehreren Datensätzen in Tabelle B verbunden, aber die Datensätze in Tabelle B haben nur einen übergeordneten Datensatz. |
Eltern-Kind-Struktur. |
Kunde → Mehrere Bestellungen |
|
Viele-zu-Viele (M:N) |
Mehrere Datensätze in Tabelle A hängen mit mehreren Datensätzen in Tabelle B zusammen. |
Bidirektionales Web. |
Studierende ↔ Kurse |
Zum Beispiele, in einem Eins-zu-Viele-Design hat eine Tabelle für Aufträge normalerweise einen Fremdschlüssel customer_id, wobei jeder einzelne Auftrag einen order_id hat. Jede Bestellung gehört genau zu einem Kunden, aber ein Kunde kann mehrere „ order_id “-Schlüssel haben.
Vergleich das mal mit dem Beispiel „Student–Kurs“. Wenn du versuchst, „ course_id ” direkt in der Tabelle „students” zu speichern, würde jeder Student mit mehreren „ course_id ”-Werten verknüpft werden. Andersrum, in der Kurstabelle hätte jeder Kurs mehrere Verweise auf student_id. Statt einer klaren Einbahnstraße tauschen beide Seiten Informationen hin und her aus.
Ein häufiges Problem ist der Versuch, viele-zu-viele-Beziehungen direkt darzustellen, indem mehrere Werte in einer einzigen Spalte gespeichert werden, entweder mithilfe eines Arrays (z. B. course_ids in einer Tabelle students ) oder wiederholter Spalten wie course_1, course_2, course_3.
Dieser Ansatz verstößt gegen die erste Normalform (1NF), die verlangt, dass jede Spalte atomare, unteilbare Werte enthält. Schau dir diesen Blog über Normalisierung in SQL an, um dein Wissen aufzufrischen.
Das Verstoßen gegen 1NF führt zu klassischen Aktualisierungsanomalien:
Abgesehen von der Normalisierungstheorie gibt es ein echtes analytisches Problem, das als Many-to-Many-Problem bekannt ist. Wenn Tabellen mit einer Viele-zu-Viele-Beziehung nicht sorgfältig verknüpft werden, kann das leicht zu einer Vervielfachung der Zeilen führen. Das kann zu Problemen mit der Rechenzeit und zu Aggregationsfehlern bei der Analyse führen.
Wenn du zum Beispiel „ courses “ mit „ students “ verbindest, basierend auf „ student_id “, kann das dazu führen, dass jeder Kurs wegen mehrerer Studieneinträge mehrfach verbunden wird. Dann kann der Versuch einer Aggregation zu Abweichungen bei der Analyse führen, wie zum Beispiel bei den Einnahmen oder der Anzahl der Schüler.
Ein richtiges Schema-Design beeinflusst direkt die Genauigkeit von Berichten, Finanzberechnungen und das Vertrauen in Datenprodukte. Außerdem hilft es dabei, Verknüpfungen zu vereinfachen, um menschliche Fehler zu minimieren. Mehr Infos zu den typischen Fallstricken bei Joins findest du in diesem SQL-Join-Tutorial und kannst dein Wissen mit den Top 20 SQL-Join-Fragen testen.
Die Standardlösung für viele-zu-viele-Beziehungen in relationalen Systemen ist die Verknüpfungstabelle (auch als Join-Tabelle, Brückentabelle oder assoziative Tabelle bezeichnet). Anstatt zu versuchen, Beziehungen direkt zu speichern, fügst du eine Zwischentabelle ein, die auf beide übergeordneten Tabellen verweist.
Im Grunde genommen verwandelt das A ↔ B in A ← JT→ B.
Jetzt hat jede eine Eins-zu-Viele-Beziehung zur Verknüpfungstabelle, was ein vereinfachtes Analyseschema ermöglicht. Ich erkläre dir, wie wir diese Verknüpfungstabellen erstellen und wie sie genutzt werden.
Eine einfache Verbindungstabelle hat:
Meistens bilden diese beiden Fremdschlüssel zusammen einen zusammengesetzten Primärschlüssel. Das stellt sicher, dass dieselbe Beziehung nicht zweimal eingefügt werden kann, und sorgt für Eindeutigkeit auf Datenbankebene.
Zum Beispiel könnte eine Tabelle „ enrollments “ eine Verkettung von „ student_id “ und „ course_id “ als Primärschlüssel verwenden. Die Datenbank hat jetzt einen eindeutigen Referenzschlüssel für die Beziehung, und wir können mit der Erstellung von Anwendungsfällen für Unternehmen anfangen.
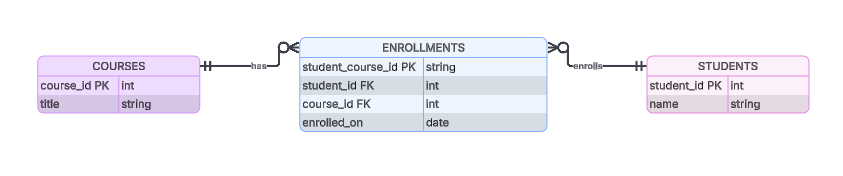
So könnte eine Verbindungstabelle für „ enrollments “ aussehen.
Wenn eine Verknüpfungstabelle zusätzliche Attribute speichert, ist sie eher eine assoziative Entität als ein reines strukturelles Ding. Dadurch kann die Verknüpfungstabelle Kontextinfos über die Beziehung enthalten. Häufige Beispiele sind:
Datum: enrollment_date, creation_date und ähnliche zeitbasierte Infos
Rolle: z. B. Admin vs. Mitglied in einer Gruppe
Metriken: Relevanzbewertung in Empfehlungssystemen
Das macht die Beziehung noch bedeutungsvoller. Die Komplexität der Abfrage steigt ein bisschen, aber das Schema spiegelt die Realität genauer wider. Dieser Kompromiss lohnt sich fast immer in Systemen, in denen sich Beziehungen mit der Zeit entwickeln. Wir können mehr Infos hinzufügen und Verknüpfungstabellen zu einem nützlichen Analysewerkzeug machen.
Verbindungstabellen hängen stark von der referenziellen Integrität ab. Fremdschlüsselbeschränkungen sorgen dafür, dass jede Beziehungszeile auf gültige übergeordnete Datensätze verweist, und verhindern so verwaiste Daten.
Löschregeln sind wichtig:
Die Entscheidung hängt von der Geschäftssemantik ab. In manchen Bereichen ist eine automatische Bereinigung okay; in anderen muss man alte Beziehungen behalten oder vor dem Löschen genau checken.
Verbindungstabellen sind eine direkte Anwendung der dritten Normalform (3NF). Sie machen Schluss mit transitiven Abhängigkeiten und beseitigen die unnötige Speicherung von Beziehungsdaten. Das ganze Ziel ist, die Normalisierung innerhalb der Datenbank zu verbessern.
In vielen Fällen helfen Verknüpfungstabellen auch dabei, die Boyce-Codd-Normalform (BCNF) zu erfüllen, weil der zusammengesetzte Primärschlüssel alle Nicht-Schlüsselattribute komplett bestimmt. Das ist wichtig, weil es Probleme bei der Aktualisierung minimiert und sicherstellt, dass beim Ändern einer Beziehung genau eine Zeile geändert werden muss.
Wenn du mehr darüber wissen willst, warum es so wichtig ist, die 3NF in unseren Datenbanken sicherzustellen, schau dir diesen Artikel über transitive Abhängigkeiten an.
Lass uns mal darüber reden, wie wir unsere Datenbanken so aufbauen können, dass sie viele-zu-viele-Beziehungen unterstützen. Wir zeigen dir ein paar coole Tricks, die dir das Leben leichter machen.
Eine klare Benennung der Tabellen macht es einfacher, sich zurechtzufinden, und verbessert die Wartbarkeit. Übliche Konventionen sind zum Beispiel TableA_TableB oder join_TableATableB, zum Beispiel:
student_course
user_group
join_user_group
Die Spaltennamen sollten die Primärschlüssel der übergeordneten Tabelle widerspiegeln (z. B. „ student_id “, „ course_id “), damit Verknüpfungen klar und lesbar sind. Konsistenz wird echt wichtig, wenn Schemata wachsen und Teams größer werden.
Es gibt ein paar verschiedene Möglichkeiten, wie wir unsere Verknüpfungstabellen erstellen können, von ganz einfachen Beziehungsnachverfolgungen bis hin zu komplexeren polymorphen Beziehungen.
Einfache Verknüpfungstabellen haben nur Fremdschlüssel und sind super für statische oder kontextarme Beziehungen. Die sind echt einfach zu pflegen und machen kaum Aufwand, weil sie meistens nur zeigen, wie zwei Tabellen zusammenhängen. Diese Verbindungstabellen haben keine Zeit- oder Kontextdaten.
Selbstreferenzierende Viele-zu-Viele-Beziehungen treten auf, wenn beide Fremdschlüssel auf dieselbe Tabelle verweisen.
Wenn wir zum Beispiel eine Social-Media-App tracken, die Nutzer, ihre Follower und die Leute, denen sie folgen, erfasst, könnten wir eine Beziehung von user_id zu follower_id in beide Richtungen haben. Es könnten noch mehr Einschränkungen nötig sein, um ungültige oder symmetrische Duplikate zu vermeiden.
Polymorphe Viele-zu-Viele-Beziehungen machen es möglich, dass eine Verbindungstabelle mehrere Entitätstypen mithilfe eines Typunterscheiders miteinander verbindet. Das sorgt für Flexibilität, verlagert aber die Integritätsdurchsetzung in die Anwendungslogik und macht Abfragen komplizierter.
Zum Beispiel könnte eine Verbindungstabelle namens „ Tag ” für Social-Media-Apps die Daten Posts, Comments und Users mit einer zusätzlichen kontextbezogenen Spalte verknüpfen, um das Tag mit der richtigen Entität zu verbinden.
Sowohl zeitliche als auch gewichtete Beziehungen speichern Infos über die Beziehung in zusätzlichen Attributen.
Zeitliche Viele-zu-Viele-Beziehungen fügen Spalten hinzu, die Zeitinfos liefern, wie zum Beispiel „ active_from “, „ active_to “ oder „ created_on “, um die historische Gültigkeit zu verfolgen. Der Schlüssel „ enrolled_on ” in unserer früheren Datenbank für Studenten und Kurse ist ein Beispiel für eine zeitliche Beziehung.
Die sind echt wichtig für Prüfpfade, sich langsam verändernde Beziehungen und Punkt-in-Zeit-Analysen. Das macht die Sache ein bisschen komplizierter, weil die Benutzer darauf achten müssen, nach der richtigen Zeitachse zu filtern und auch Zeilen zu berücksichtigen, die vielleicht inaktiv sind.
Gewichtete Beziehungen speichern dagegen Ranglisten oder Stärke-Metriken. Empfehlungsmaschinen, Tagging-Systeme und Relevanzbewertungen nutzen dieses Muster oft, um Sachen wie die Zuverlässigkeit von Empfehlungen zu verfolgen.
Während die meisten OLTP-Systeme Beziehungen zwischen mehr als zwei Entitäten meiden, werden sie in Analysesystemen oft genutzt. Faktentabellen in Dimensionsmodellen sind wie Verbindungstabellen, die Tabellen mit unterschiedlichen Detailstufen zusammenbringen. Diese Designs sind echt stark, brauchen aber eine disziplinierte Abfrage und klare Dokumentation.
Ein mögliches Design wäre, deine Verknüpfungstabelle mit Fremdschlüsseln zu allen beteiligten Entitäten zu erstellen.
Wenn wir zum Beispiel unser Beispiel mit den Studenten und Kursen weiterdenken, könnte eine dritte Tabelle die Klassenzimmernummern enthalten. Eine Verknüpfungstabelle kann die Fremdschlüssel für einen Schüler in einer bestimmten Klasse in einem bestimmten Raum haben. Es ist leicht zu erkennen, dass mit zunehmender Anzahl von Beziehungen die Abfragen und Schemata exponentiell komplexer werden.
Wenn du dich näher mit dem Aufbau von Datenbanken beschäftigen willst, solltest du unbedingt unseren Kurs zum Thema Datenbankdesign besuchen.
Bei jedem komplizierten Datenbankdesign müssen wir uns Gedanken über die Leistung und die Abfrage machen. Je mehr Teile wir hinzufügen, desto eher haben wir Probleme mit der Leistung!
Schauen wir uns erst mal ein paar Möglichkeiten an, wie wir unsere Verknüpfungstabellen abfragen können. Häufige Zugriffsmuster sind:
Um diese Abfragen zu optimieren:
Fremdschlüssel in der Verknüpfungstabelle indizieren
Benutz GROUP BY oder DISTINCT, um Doppelzählungen zu vermeiden.
Denk mal drüber nach, Indizes für Workloads mit vielen Lesevorgängen abzudecken.
Sei bei den Anweisungen „ WHERE “ genau, um die Menge der zu verknüpfenden Daten zu begrenzen.
Diese Techniken sind echt wichtig für effiziente Verknüpfungen und Aggregationen. Denk auch daran: Wenn du versuchst, mit der Verknüpfungstabelle zwei Tabellen zu verbinden, solltest du dir überlegen, wie du drei Tabellen effizient verbinden kannst.
Verbindungstabellen haben oft ein hohes Schreibvolumen. Batch-Einfügungen und -Aktualisierungen sparen Transaktionsaufwand.
Aber wenn viele Leute auf beliebte Fremdschlüssel zugreifen, kann das zu Problemen beim Sperren führen. Achte darauf, die Leistung und die Partitionstabellen im Auge zu behalten, um Parallelisierung zu ermöglichen.
Schauen wir uns mal kurz den Hauptunterschied zwischen Normalisierung und Denormalisierung als Ansatz für unser Datenbankdesign an:
Denk mal richtig über Zugriffsmuster, Team-Know-how und betriebliche Einschränkungen nach.
Denormalisierung kann die Leistung bei Systemen mit vielen Schreibvorgängen verbessern, die sich nicht oft ändern. Die Kosten sind mehr Komplexität, ein höherer Wartungsaufwand und das Risiko, dass Daten veralten.
Meine Meinung dazu: Denormalisierung sollte nur als angemessene Reaktion auf leseintensive Engpässe eingesetzt werden und immer mit regelmäßigen Konsistenzprüfungen einhergehen.
SQL- und nosql-Systeme haben ein bisschen unterschiedliche Ansätze bei der Umsetzung von Many-to-Many-Systemen.
Relationale Datenbanken wie PostgreSQL, MySQL und SQL Server machen viele-zu-viele-Beziehungen explizit mit Hilfe von Verknüpfungstabellen mit Fremdschlüsseln und zusammengesetzten Primärschlüsseln. Ähnlich funktionieren auch Cloud-basierte relationale Datenbanken wie Snowflake.
Nosql-Systeme zeigen oft viele-zu-viele-Beziehungen, indem sie Arrays mit zugehörigen IDs einbetten oder Referenzen speichern, die von der Anwendungslogik verwaltet werden. Das liegt daran, dass bei nosql-Datenbanken die Leseleistung und die horizontale Skalierbarkeit im Vordergrund stehen. Das macht das Lesen schneller und das Schema flexibler, aber die Normalisierung leidet darunter.
|
Feature |
Relational (SQL) |
NoSQL |
|
Umsetzung |
Verbindungstabellen: Verwendet eine dritte Tabelle mit Fremdschlüsseln und zusammengesetzten Primärschlüsseln. |
Einbetten oder Verweisen: Verwendet Arrays von IDs oder verschachtelte Dokumente. |
|
Hauptziel |
Normalisierung: Sorgt dafür, dass die Daten konsistent bleiben und Doppelte Daten wegfallen. |
Leistung: Priorisiert Lesegeschwindigkeit und horizontale Skalierbarkeit. |
|
Flexibilität |
Rigid Schema: Braucht vordefinierte Strukturen und Verknüpfungen, um Daten abzurufen. |
Hohe Flexibilität: Ermöglicht schemalose Designs und verschiedene Datentypen. |
|
Kompromiss |
Komplexe Verknüpfungen: Kann langsamer werden, wenn der Datensatz ziemlich groß wird. |
Opfer Normalisierung: Kann zu doppelten oder veralteten Daten führen. |
|
Beispiele |
PostgreSQL, MySQL, SQL Server, Snowflake. |
MongoDB, DynamoDB, Cassandra. |
Relationale Datenbanken sind die erste Wahl, wenn du eine klar definierte Schemastruktur brauchst. Diese Datenbanken sind einfacher zu handhaben und ermöglichen eine bessere Datenverwaltung. Überleg dir, eine relationale SQL-Datenbank zu nutzen, wenn:
Nosql-Datenbanken sind super für Situationen, in denen Flexibilität und die Möglichkeit, viele Daten auf einmal zu bearbeiten, wichtig sind. Zum Beispiel kannst du mit nosql-Datenbanken wie MongoDB Operatoren wie updateMany, wenn wir mehrere Dokumente gleichzeitig aktualisieren müssen. Hier sind ein paar Tipps, wann du eine nosql-Implementierung in Betracht ziehen solltest:
Viele-zu-viele-Beziehungen sind in echten Datenmodellen einfach nicht zu vermeiden. Die richtige Gestaltung ist super wichtig für die Datenintegrität, Skalierbarkeit und analytische Korrektheit. Wenn Junction-Tabellen richtig normalisiert und indiziert sind, bieten sie eine solide Basis, die von Transaktionssystemen bis hin zu Unternehmensanalysen reicht.
Jedes Design hat seine Vor- und Nachteile: Normalisierung oder Leistung, Einfachheit oder Flexibilität, Abstraktion oder Kontrolle. Der Schlüssel liegt darin, deine Zugriffsmuster zu analysieren, Muster auszuwählen, die zu deiner Arbeitslast passen, und Designs durch Schemaüberprüfung und Abfragetests zu validieren.
Für Leute, die ihre Fähigkeiten im Datenbankdesign verbessern wollen, empfehle ich echt, sich für unseren Lernpfad zum Associate Data Analyst in SQL.
Kurse zum Thema Datenbankdesign
Lernpfad
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
Javier Canales Luna
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Matt Crabtree

