
Programa
Analista de dados associado em SQL
39 h
Usuários e seguidores, alunos e cursos, clientes e produtos: nosso mundo está cheio de relações naturais de muitos para muitos. Mas, nem sempre isso é bem traduzido nos projetos de bancos de dados. Relacionamentos muitos-para-muitos mal projetados são uma das causas mais comuns de duplicação de dados, análises incorretas e dificuldades de manutenção a longo prazo em sistemas de produção.
Neste artigo, vou falar sobre relações muitos-para-muitos, desde os princípios básicos até a implementação no mundo real. Também vamos ver padrões de design avançados, normalização, considerações de desempenho e como as relações muitos-para-muitos são implementadas em sistemas relacionais e nosql.
No final, você deve ser capaz de projetar esquemas escaláveis e sustentáveis que modelem corretamente relações complexas, evitem anomalias de dados e ofereçam suporte a relatórios confiáveis e fluxos de trabalho de BI.
Para quem quer reforçar os fundamentos ao longo do caminho, recomendo fazer nosso Introdução a bancos de dados relacionais em SQL .
Uma relação muitos-para-muitos (M:N) é uma relação bidirecional de banco de dados em que cada registro na Tabela A pode se relacionar com muitos registros na Tabela B, e cada registro na Tabela B pode se relacionar com muitos registros na Tabela A. Diferente de tipos de relação mais simples, a cardinalidade existe nos dois lados.
Essa relação é super comum em sistemas reais:
A relação tem um significado e, muitas vezes, dados próprios. Entender essa diferença é essencial para o design correto do esquema e para as consultas, especialmente quando unir tabelas para análise.
Para entender por que as relações muitos-para-muitos precisam de um tratamento especial, é bom compará-las com cardinalidades mais simples.
|
Tipo de relacionamento |
Descrição |
Lógica |
Exemplo |
|
Um para um (1:1) |
Cada registro na Tabela A corresponde exatamente a um na Tabela B. |
Combinação única. |
Usuário ↔ Perfil do usuário |
|
Um para muitos (1:N) |
Um registro na Tabela A está ligado a vários na Tabela B, mas os registros da Tabela B só têm um pai. |
Estrutura pai/filho. |
Cliente → Vários pedidos |
|
Muitos para muitos (M:N) |
Vários registros na Tabela A estão ligados a vários registros na Tabela B. |
Web bidirecional. |
Alunos ↔ Cursos |
Por exemplo,e, em um design um-para-muitos, uma tabela de pedidos normalmente contém uma chave estrangeira customer_id, com cada pedido exclusivo tendo um order_id. Cada pedido é de um cliente só, mas um cliente pode ter várias chaves order_id.
Agora, compare isso com o exemplo do aluno e do curso. Se você tentar guardar course_id diretamente na tabela dos alunos, cada aluno ficaria ligado a vários valores de course_id. Por outro lado, dentro da tabela de cursos, cada curso teria várias referências student_id. Em vez de uma relação unidirecional bem definida, as duas direções trocam informações entre si.
Um problema comum é tentar representar relações muitos-para-muitos diretamente, armazenando vários valores em uma única coluna usando uma matriz (por exemplo, course_ids em uma tabela students ) ou colunas repetidas como course_1, course_2, course_3.
Essa abordagem não segue a Primeira Forma Normal (1NF), que exige que cada coluna tenha valores atômicos e indivisíveis. Dá uma olhada nesse blog sobre normalização em SQL pra refrescar a memória.
Violar a 1NF leva a anomalias clássicas de atualização:
Além da teoria da normalização, existe uma consequência analítica grave conhecida como problema muitos-para-muitos. Quando tabelas com uma relação muitos-para-muitos não são unidas com cuidado, isso pode facilmente levar à multiplicação de linhas. Isso pode causar problemas com o tempo de computação e erros de agregação para análise.
Por exemplo, juntar courses com students com base em student_id pode fazer com que cada curso seja juntado várias vezes por causa de várias entradas de alunos. Então, tentar agregar pode levar a discrepâncias analíticas, como receitas ou contagens de alunos.
O design correto do esquema afeta diretamente a precisão dos relatórios, os cálculos financeiros e a confiança nos produtos de dados. Além disso, ajuda a simplificar as junções para minimizar erros humanos. Pra saber mais sobre as armadilhas comuns das junções, dá uma olhada nesse tutorial de junções SQL e treina com essas 20 perguntas mais frequentes sobre junções SQL.
A solução padrão para relações muitos-para-muitos em sistemas relacionais é a tabela de junção (também chamada de tabela de união, tabela ponte ou tabela associativa). Em vez de tentar armazenar relações diretamente, você introduz uma tabela intermediária que faz referência às duas tabelas principais.
Em termos de conceito, isso transforma A ↔ B em A ← JT→ B.
Agora, cada um tem uma relação um-para-muitos com a tabela de junção, o que permite um esquema analítico mais simples. Vou explicar como criamos essas tabelas de junção e como elas são usadas.
Uma tabela de junção básica tem:
Na maioria dos casos, essas duas chaves estrangeiras juntas formam uma chave primária composta. Isso garante que a mesma relação não possa ser inserida duas vezes e impõe a exclusividade no nível do banco de dados.
Por exemplo, uma tabela enrollments pode usar uma concatenação de student_id e course_id como sua chave primária. Agora, o banco de dados tem uma chave de referência única para a relação e podemos começar a criar casos de uso comerciais.
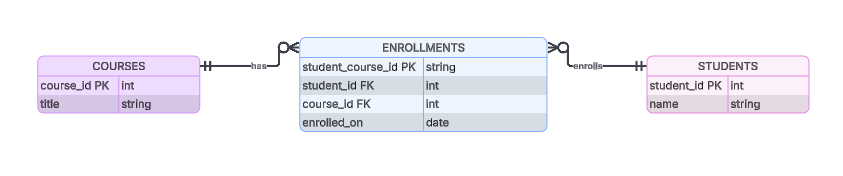
Exemplo de como poderia ser uma tabela de junção enrollments.
Quando uma tabela de junção guarda atributos adicionais, ela fica mais parecida com uma entidade associativa do que com um artefato puramente estrutural. Isso permite que a tabela de junção tenha informações contextuais sobre a relação. Exemplos comuns incluem:
Data: enrollment_date, creation_date e informações semelhantes baseadas no tempo
Função: tipo, administrador versus membro em um grupo
Métricas: pontuação de relevância em sistemas de recomendação
Isso ajuda a relação a ter mais significado. A complexidade da consulta aumenta um pouco, mas o esquema modela a realidade com mais precisão. Essa troca quase sempre vale a pena em sistemas onde as relações evoluem com o tempo. Podemos adicionar mais informações e tornar as tabelas de junção uma ferramenta analítica útil.
As tabelas de junção dependem muito da integridade referencial. As restrições de chave estrangeira garantem que cada linha de relacionamento faça referência a registros pai válidos, evitando dados órfãos.
As regras de exclusão são importantes:
A escolha depende da semântica do negócio. Em alguns casos, a limpeza automática é uma boa ideia; em outros, as relações históricas precisam ser mantidas ou revisadas antes de serem removidas.
As tabelas de junção são uma aplicação direta da Terceira Forma Normal (3NF). Elas eliminam dependências transitivas e removem o armazenamento redundante de dados de relacionamento. O objetivo é melhorar a normalização dentro do banco de dados.
Em muitos casos, as tabelas de junção também ajudam a satisfazer a Forma Normal de Boyce-Codd (BCNF), porque a chave primária composta determina totalmente todos os atributos que não são chaves. Isso é importante porque minimiza anomalias de atualização e garante que a modificação de um relacionamento exija a alteração de exatamente uma linha.
Para entender melhor a importância de garantir a 3NF em nossos bancos de dados, confira este artigo sobre dependência transitiva.
Vamos ver como podemos criar nossos bancos de dados pra dar suporte a relações muitos-para-muitos. Vamos falar sobre boas práticas para facilitar a sua vida.
Nomes claros nas tabelas diminuem a carga cognitiva e melhoram a manutenção. As convenções comuns geralmente incluem TableA_TableB ou join_TableATableB, por exemplo:
student_course
user_group
join_user_group
Os nomes das colunas devem refletir as chaves primárias das tabelas pai (por exemplo, student_id, course_id) para tornar as junções óbvias e legíveis. A consistência se torna essencial à medida que os esquemas crescem e as equipes se expandem.
Tem várias maneiras de montar nossas tabelas de junção, desde o rastreamento de relações bem simples até relações polimórficas mais complexas.
Tabelas de junção simples têm só chaves estrangeiras e são perfeitas pra relações estáticas ou com pouco contexto. São muito fáceis de manter, com um custo mínimo, porque geralmente só mostram como duas tabelas estão relacionadas. Essas tabelas de junção não têm dados temporais ou contextuais.
As relações muitos-para-muitos autorreferenciadas acontecem quando as duas chaves estrangeiras apontam para a mesma tabela.
Por exemplo, se a gente estiver monitorando um aplicativo de mídia social que inclui o rastreamento de usuários, seus seguidores e quem eles seguem, podemos ter uma relação de user_id para follower_id em ambas as direções. Podem ser necessárias restrições adicionais para evitar duplicatas inválidas ou simétricas.
Relacionamentos polimórficos muitos-para-muitos permitem que uma tabela de junção conecte vários tipos de entidades usando um discriminador de tipos. Isso dá flexibilidade, mas muda a aplicação da integridade para a lógica da aplicação e complica as consultas.
Por exemplo, uma tabela de junção chamada Tag para aplicativos de mídia social poderia relacionar Posts, Comments e Users com uma coluna contextual adicional para associar a tag à entidade correta.
As relações temporais e ponderadas armazenam informações sobre a relação em atributos adicionais.
As relações temporais muitos-para-muitos adicionam colunas que fornecem informações temporais, como active_from, active_to ou created_on, para rastrear a validade histórica. A chave “ enrolled_on ” (aluno-curso) em nosso banco de dados anterior de alunos e cursos é um exemplo de relação temporal.
Isso é essencial para trilhas de auditoria, relações que mudam lentamente e análises pontuais. Isso adiciona um pouco de complexidade, pois os usuários devem ter cuidado para filtrar na escala temporal adequada e considerar as linhas que podem estar inativas.
Já as relações ponderadas guardam métricas de classificação ou força. Os mecanismos de recomendação, os sistemas de marcação e a pontuação de relevância geralmente usam esse padrão para acompanhar coisas como a confiança da recomendação.
Embora a maioria dos sistemas OLTP evite relações envolvendo mais de duas entidades, os sistemas analíticos costumam usá-las. As tabelas de fatos em modelos dimensionais funcionam como tabelas de junção, conectando tabelas em diferentes níveis de granularidade. Esses projetos são poderosos, mas exigem consultas disciplinadas e documentação clara.
Um projeto possível seria criar sua tabela de junção com chaves estrangeiras para todas as entidades participantes.
Por exemplo, se a gente continuar com o exemplo dos alunos e cursos, uma terceira tabela poderia ser os números das salas de aula. Uma tabela de junção pode ter as chaves estrangeiras de um aluno em uma turma específica em uma sala específica. É fácil perceber que, à medida que aumentamos o número de relações, as consultas e o esquema ficam exponencialmente mais complexos.
Para saber mais sobre como criar bancos de dados, não deixe de fazer nosso curso sobre design de bancos de dados.
Com qualquer projeto de banco de dados complicado, a gente precisa pensar no desempenho e nas questões relacionadas às consultas. Quanto mais peças a gente adiciona, mais provável que a gente vá ter problemas de desempenho!
Vamos primeiro dar uma olhada em algumas maneiras de consultar nossas tabelas de junção. Os padrões de acesso comuns incluem:
Para otimizar essas consultas:
Indexar chaves estrangeiras na tabela de junção
Use GROUP BY ou DISTINCT para evitar contagem excessiva.
Pense em usar índices de cobertura para cargas de trabalho com muitas leituras.
Seja específico nas instruções ` WHERE ` para limitar a quantidade de dados que estão sendo unidos.
Essas técnicas são essenciais para junções e agregações eficientes. Lembre-se também de que, se você estiver tentando usar a tabela de junção para conectar duas tabelas, é bom pensar em como você poderia unir três tabelas de maneira eficiente.
As tabelas de junção costumam ter um grande volume de gravações. As inserções e atualizações em lote diminuem a sobrecarga das transações.
Mas, muita disputa por chaves estrangeiras populares pode criar gargalos de bloqueio. Fica de olho no desempenho e nas tabelas de partição pra permitir a paralelização.
Vamos dar uma olhada na principal diferença entre normalização e desnormalização como abordagem para o nosso projeto de banco de dados:
Pense bem nos padrões de acesso, na experiência da equipe e nas limitações operacionais.
A desnormalização pode melhorar o desempenho em sistemas com muitas gravações que não mudam com frequência. O custo é mais complexidade, mais trabalho de manutenção e o risco de ter dados desatualizados.
Minha opinião: A desnormalização só deve ser uma resposta moderada a gargalos de leitura pesada e deve sempre ser feita com verificações regulares de consistência.
Os sistemas SQL e nosql têm abordagens um pouco diferentes para a implementação de sistemas muitos-para-muitos.
Bancos de dados relacionais como PostgreSQL, MySQL e SQL Server implementam relações muitos-para-muitos explicitamente usando tabelas de junção com chaves estrangeiras e chaves primárias compostas. Da mesma forma, bancos de dados relacionais baseados em nuvem, como o Snowflake, seguem um padrão de design parecido.
Os sistemas nosql geralmente mostram relações muitos-para-muitos colocando matrizes de IDs relacionados ou guardando referências gerenciadas pela lógica da aplicação. Isso é porque o foco é a velocidade de leitura e a escalabilidade horizontal nos bancos de dados nosql. Isso melhora o desempenho de leitura e a flexibilidade do esquema, mas sacrifica a normalização.
|
Recurso |
Relacional (SQL) |
NoSQL |
|
Implementação |
Tabelas de junção: Usa uma terceira tabela com chaves estrangeiras e chaves primárias compostas. |
Incorporar ou referenciar: Usa matrizes de IDs ou documentos aninhados. |
|
Objetivo principal |
Normalização: Garantir a consistência dos dados e eliminar a redundância. |
Desempenho: Prioriza a velocidade de leitura e a escalabilidade horizontal. |
|
Flexibilidade |
Esquema rígido: Precisa de estruturas e junções pré-definidas para pegar os dados. |
Alta flexibilidade: Permite designs sem esquema e vários tipos de dados. |
|
Compromisso |
Junções complexas: Pode ficar mais lento conforme o conjunto de dados cresce bastante. |
Sacrifícios Normalização: Pode levar à duplicação de dados ou a dados “obsoletos”. |
|
Exemplos |
PostgreSQL, MySQL, SQL Server, Snowflake. |
MongoDB, DynamoDB, Cassandra. |
Os bancos de dados relacionais são os preferidos quando você precisa de uma estrutura de esquema bem definida. Esses bancos de dados são mais fáceis de mexer e permitem um gerenciamento melhor dos dados. Pense em usar um banco de dados SQL relacional quando:
Os bancos de dados nosql são bons pra situações em que flexibilidade e capacidade de operar em massa são prioridades. Por exemplo, bancos de dados nosql como o MongoDB permitem o uso de operadores como updateMany quando precisamos atualizar vários documentos. Aqui estão alguns princípios básicos para saber quando você deve pensar em usar nosql:
Relacionamentos muitos-para-muitos são inevitáveis em modelos de dados realistas. Projetá-los corretamente é essencial para a integridade dos dados, escalabilidade e precisão analítica. Como tabelas de junção, quando bem normalizadas e indexadas, oferecem uma base robusta que vai desde sistemas transacionais até análises empresariais.
Todo projeto envolve escolhas: normalização versus desempenho, simplicidade versus flexibilidade e abstração versus controle. O segredo é criar um perfil dos seus padrões de acesso, escolher padrões que combinem com a sua carga de trabalho e validar os projetos por meio da revisão do esquema e do teste de consultas.
Pra quem quer melhorar suas habilidades em design de banco de dados, recomendo muito se inscrever no nosso curso de programa de carreira de Analista de Dados Associado em SQL.
Cursos de Design de Bancos de Dados
Programa
Curso
Curso
blog
Kurtis Pykes
11 min
blog
Summer Worsley
13 min
Tutorial
DataCamp Team
Tutorial
Javier Canales Luna
Tutorial
DataCamp Team
Tutorial
Oluseye Jeremiah


