
Cursus
Analyste de données associé en SQL
39 h
Utilisateurs et abonnés, étudiants et cours, clients et produits : notre monde est riche en relations naturelles de type « plusieurs à plusieurs ». Cependant, ces éléments ne sont pas toujours bien pris en compte dans la conception des bases de données. Les relations plusieurs-à-plusieurs mal conçues constituent l'une des causes les plus courantes de duplication des données, d'analyses incorrectes et de difficultés de maintenance à long terme dans les systèmes de production.
Dans cet article, j'aborderai les relations plusieurs-à-plusieurs, depuis les principes fondamentaux jusqu'à leur mise en œuvre dans le monde réel. Nous examinerons également les modèles de conception avancés, la normalisation, les considérations relatives aux performances et la manière dont les relations plusieurs-à-plusieurs sont mises en œuvre dans les systèmes relationnels et nosql.
À la fin, vous devriez être en mesure de concevoir des schémas évolutifs et faciles à maintenir qui modélisent correctement les relations complexes, évitent les anomalies de données et prennent en charge des workflows fiables de reporting et de BI.
Pour les lecteurs qui souhaitent renforcer leurs connaissances fondamentales au fur et à mesure, je recommande de suivre notre cours Introduction aux bases de données relationnelles en SQL .
Une relation plusieurs-à-plusieurs (M:N) est une relation bidirectionnelle entre bases de données dans laquelle chaque enregistrement du tableau A peut être lié à plusieurs enregistrements du tableau B, et chaque enregistrement du tableau B peut être lié à plusieurs enregistrements du tableau A. Contrairement aux types de relations plus simples, la cardinalité existe des deux côtés.
Cette relation est omniprésente dans les systèmes réels :
La relation a une signification et contient souvent ses propres données. Il est essentiel de comprendre cette distinction pour concevoir correctement les schémas et effectuer des requêtes, en particulier lorsque l'on jointure de tableaux à des fins d'analyse.
Pour comprendre pourquoi les relations plusieurs-à-plusieurs nécessitent un traitement particulier, il est utile de les comparer à des cardinalités plus simples.
|
Type de relation |
Description |
Logique |
Exemple |
|
Individuel (1:1) |
Chaque enregistrement du tableau A correspond exactement à un enregistrement du tableau B. |
Accord unique. |
Utilisateur ↔ Profil utilisateur |
|
Un-à-plusieurs (1:N) |
Un enregistrement du tableau A correspond à plusieurs enregistrements du tableau B, mais les enregistrements du tableau B n'ont qu'un seul parent. |
Structure parent/enfant. |
Client → Commandes multiples |
|
Relation multiple (M:N) |
Plusieurs enregistrements du tableau A correspondent à plusieurs enregistrements du tableau B. |
Web bidirectionnel. |
Étudiants ↔ Cours |
Par exemple, dans une conception un-à-plusieurs, une table de commandes contient généralement une clé étrangère customer_id, chaque commande unique ayant un identifiant order_id. Chaque commande est attribuée à un seul client, mais un client peut avoir plusieurs clés d'order_id.
Comparons maintenant cela à l'exemple de l'étudiant et du cours. course_id Si vous essayez de stocker des données directement dans la table des étudiants, chaque étudiant serait lié à plusieurs valeurs d'course_id. À l'inverse, dans le tableau des cours, chaque cours comporterait plusieurs références d'student_id. Au lieu d'une relation unidirectionnelle stricte, les deux directions échangent des informations dans les deux sens.
Un problème courant consiste à tenter de représenter directement des relations plusieurs-à-plusieurs en stockant plusieurs valeurs dans une seule colonne à l'aide d'un tableau (par exemple, course_ids dans une table students ) ou de colonnes répétées comme course_1, course_2, course_3.
Cette approche enfreint la première forme normale (1NF), qui exige que chaque colonne contienne des valeurs atomiques et indivisibles. Veuillez consulter ce blog sur la normalisation en SQL pour rafraîchir vos connaissances.
La violation de la 1NF entraîne des anomalies de mise à jour classiques :
Au-delà de la théorie de la normalisation, il existe une conséquence analytique importante connue sous le nom de problème « plusieurs-à-plusieurs ». Lorsque les tables présentant une relation plusieurs-à-plusieurs ne sont pas jointes avec soin, cela peut facilement entraîner une multiplication des lignes. Cela peut entraîner des problèmes liés au temps de calcul et des erreurs d'agrégation pour l'analyse.
Par exemple, joindre courses à students sur la base de student_id peut entraîner la jonction de chaque cours à plusieurs reprises en raison de la présence de plusieurs entrées d'étudiants. Tenter ensuite de regrouper ces données peut entraîner des divergences analytiques, par exemple au niveau des revenus ou du nombre d'étudiants.
Une conception correcte du schéma influe directement sur la précision des rapports, les calculs financiers et la confiance dans les produits de données. De plus, cela contribue à simplifier les jointures afin de minimiser les erreurs humaines. Pour plus de détails sur les pièges courants liés aux jointures, veuillez consulter ce tutoriel sur les jointures SQL et vous exercer à l'aide de ces 20 questions fréquentes sur les jointures SQL.
La solution standard pour les relations plusieurs-à-plusieurs dans les systèmes relationnels est la table de jonction (également appelée table de liaison, table passerelle ou table associative). Au lieu de tenter de stocker directement les relations, vous introduisez une table intermédiaire qui fait référence aux deux tables parentes.
Conceptuellement, cela transforme A ↔ B en A ← JT→ B.
Désormais, chacune d'entre elles entretient une relation un-à-plusieurs avec la table de jonction, ce qui permet de simplifier le schéma analytique. Je vais vous expliquer comment nous élaborons ces tables de jonction et comment elles sont utilisées.
Une table de jonction de base contient :
Dans la plupart des cas, ces deux clés étrangères forment ensemble une clé primaire composite. Cela garantit qu'une même relation ne peut pas être insérée deux fois et assure l'unicité au niveau de la base de données.
Par exemple, un tableau enrollments pourrait utiliser une concaténation de student_id et course_id comme clé primaire. La base de données dispose désormais d'une clé de référence unique pour la relation et nous pouvons commencer à élaborer des cas d'utilisation métier.
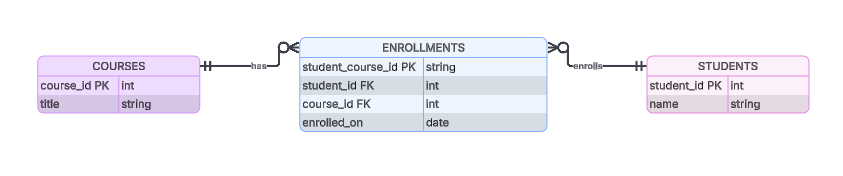
Exemple de ce à quoi pourrait ressembler une table de jonction d'enrollments.
Lorsqu'une table de jonction stocke des attributs supplémentaires, elle se rapproche davantage d'une entité associative que d'un artefact purement structurel. Cela permet à la table de jonction de contenir des informations contextuelles sur la relation. Voici quelques exemples courants :
Date : enrollment_date, creation_date et autres informations similaires liées au temps.
Rôle : par exemple, administrateur ou membre dans un groupe
Mesures : notation de la pertinence dans les systèmes de recommandation
Cela contribue à donner plus de sens à la relation. La complexité des requêtes augmente légèrement, mais le schéma modélise la réalité avec plus de précision. Ce compromis est presque toujours avantageux dans les systèmes où les relations évoluent au fil du temps. Nous pouvons ajouter davantage d'informations et faire les tableaux de jonction un outil analytique utile.
Les tables de jonction dépendent fortement de l'intégrité référentielle. Les contraintes de clé étrangère garantissent que chaque ligne de relation fait référence à des enregistrements parents valides, évitant ainsi les données orphelines.
Les règles de suppression sont importantes :
Le choix dépend de la sémantique métier. Dans certains domaines, le nettoyage automatique est approprié ; dans d'autres, les relations historiques doivent être conservées ou explicitement examinées avant suppression.
Les tables de jonction constituent une application directe de la troisième forme normale (3NF). Ils éliminent les dépendances transitives et suppriment le stockage redondant des données relationnelles. Son objectif principal est d'améliorer la normalisation au sein de la base de données.
Dans de nombreux cas, les tableaux de jonction contribuent également à satisfaire la forme normale de Boyce-Codd (BCNF), car la clé primaire composite détermine entièrement tous les attributs non clés. Ceci est important car cela minimise les anomalies de mise à jour et garantit que la modification d'une relation nécessite la modification d'une seule ligne.
Pour mieux comprendre l'importance de garantir la 3NF dans nos bases de données, veuillez consulter cet article sur la dépendance transitive.
Examinons comment nous pouvons réellement construire nos bases de données pour prendre en charge les relations plusieurs-à-plusieurs. Nous aborderons les bonnes pratiques qui vous faciliteront la vie.
Une dénomination claire des tableaux réduit la charge cognitive et améliore la maintenabilité. Les conventions courantes incluent généralement TableA_TableB ou join_TableATableB, par exemple :
student_course
user_group
join_user_group
Les noms des colonnes doivent refléter les clés primaires de la table parente (par exemple, student_id, course_id) afin de rendre les jointures claires et lisibles. La cohérence devient essentielle à mesure que les schémas se développent et que les équipes s'agrandissent.
Il existe plusieurs méthodes pour créer nos tables de jonction, allant du simple suivi des relations à des relations polymorphes plus complexes.
Les tableaux de jonction simples ne contiennent que des clés étrangères et sont idéaux pour les relations statiques ou à faible contexte. Ils sont très simples à maintenir et nécessitent peu de ressources, car ils servent généralement uniquement à mettre en évidence la relation entre deux tables. Ces tables de jonction ne contiennent aucune donnée temporelle ou contextuelle.
Les relations multiréférences auto-référencées se produisent lorsque les deux clés étrangères font référence à la même table.
Par exemple, si nous suivons une application de réseau social qui inclut le suivi des utilisateurs, de leurs abonnés et des personnes qu'ils suivent, nous pourrions avoir une relation de user_id à follower_id dans les deux sens. Des contraintes supplémentaires peuvent être nécessaires pour éviter les doublons invalides ou symétriques.
Les relations polymorphes plusieurs-à-plusieurs permettent à une table de jonction de relier plusieurs types d'entités à l'aide d'un discriminateur de type. Cela offre une certaine flexibilité, mais transfère l'application des règles d'intégrité vers la logique applicative et complique les requêtes.
Par exemple, un tableau de jonction appelé Tag pour les applications de réseaux sociaux pourrait relier Posts, Comments et Users à une colonne contextuelle supplémentaire permettant d'associer la balise à l'entité appropriée.
Les relations temporelles et pondérées stockent toutes deux des informations sur la relation dans des attributs supplémentaires.
Les relations temporelles plusieurs-à-plusieurs ajoutent des colonnes qui fournissent des informations temporelles, telles que active_from, active_to ou created_on, afin de suivre la validité historique. La clé « enrolled_on » (année d'obtention du diplôme) dans notre base de données précédente sur les étudiants et les cours est un exemple de relation temporelle.
Ces éléments sont essentiels pour les pistes d'audit, les relations qui évoluent lentement et les analyses ponctuelles. Cela ajoute une certaine complexité, car les utilisateurs doivent veiller à filtrer selon l'échelle temporelle appropriée et à prendre en compte les lignes qui peuvent être inactives.
Les relations pondérées, quant à elles, stockent des mesures de classement ou de force. Les moteurs de recommandation, les systèmes de balisage et les scores de pertinence s'appuient généralement sur ce modèle pour suivre des éléments tels que la fiabilité des recommandations.
Alors que la plupart des systèmes OLTP évitent les relations impliquant plus de deux entités, les systèmes analytiques les utilisent fréquemment. Les tables de faits dans les modèles dimensionnels agissent efficacement comme des tables de jonction reliant des tables à différents niveaux de granularité. Ces conceptions sont efficaces, mais nécessitent des requêtes rigoureuses et une documentation claire.
Une conception envisageable consisterait à créer votre table de jonction avec des clés étrangères vers toutes les entités participantes.
Par exemple, si nous nous basons sur notre exemple concernant les étudiants et les cours, un troisième tableau pourrait contenir les numéros des salles de classe. Une table de jonction peut contenir les clés étrangères d'un étudiant dans une classe spécifique dans une salle spécifique. Il est facile de constater que lorsque nous augmentons le nombre de relations, les requêtes et les schémas deviennent exponentiellement plus complexes.
Pour approfondir vos connaissances en matière de création de bases de données, nous vous invitons à suivre notre cours sur la conception de bases de données.
Dans le cadre de toute conception de base de données complexe, il est nécessaire de prendre en compte les considérations relatives aux performances et aux requêtes. Plus nous ajoutons d'éléments, plus nous risquons de rencontrer des problèmes de performances.
Examinons tout d'abord quelques méthodes pour interroger nos tables de jonction. Les modèles d'accès courants comprennent :
Pour optimiser ces requêtes :
Indexer les clés étrangères dans la table de jonction
Veuillez utiliser GROUP BY ou DISTINCT afin d'éviter tout double comptage.
Envisagez d'utiliser des index de couverture pour les charges de travail impliquant de nombreuses lectures.
Soyez précis dans vos instructions d'WHERE s afin de limiter la quantité de données jointes.
Ces techniques sont essentielles pour réaliser des jointures et des agrégations efficaces. Veuillez également noter que si vous envisagez d'utiliser la table de jonction pour relier deux tables, il est judicieux de réfléchir à la manière dont vous pourriez joindre trois tables de manière efficace.
Les tables de jonction enregistrent souvent un volume d'écriture élevé. Les insertions et mises à jour par lots réduisent la charge de travail liée aux transactions.
Cependant, une contention élevée sur les clés étrangères populaires peut entraîner des goulots d'étranglement au niveau du verrouillage. Veuillez surveiller les performances et les tables de partition afin de permettre la parallélisation.
Prenons un instant pour examiner la différence essentielle entre la normalisation et la dénormalisation en tant qu'approche de la conception de notre base de données :
Veuillez réfléchir attentivement aux modèles d'accès, à l'expertise de l'équipe et aux contraintes opérationnelles.
La dénormalisation peut améliorer les performances sur les systèmes à forte activité d'écriture qui ne changent pas fréquemment. Le coût se traduit par une complexité accrue, une charge de maintenance plus importante et un risque de données obsolètes.
Mon humble avis : La dénormalisation ne devrait être qu'une réponse mesurée aux goulots d'étranglement liés à une utilisation intensive de la lecture et devrait toujours être mise en place avec des contrôles de cohérence réguliers.
Les systèmes SQL et nosql ont des approches légèrement différentes pour la mise en œuvre des systèmes plusieurs-à-plusieurs.
Les bases de données relationnelles telles que PostgreSQL, MySQL et SQL Server implémentent explicitement les relations plusieurs-à-plusieurs à l'aide de tables de jonction avec des clés étrangères et des clés primaires composites. De même, les bases de données relationnelles basées sur le cloud, telles que Snowflake, suivent un modèle de conception similaire.
Les systèmes nosql représentent souvent des relations plusieurs-à-plusieurs en intégrant des tableaux d'identifiants associés ou en stockant des références gérées par la logique de l'application. Cela est dû à la priorité accordée aux performances de lecture et à l'évolutivité horizontale dans les bases de données nosql. Cela améliore les performances de lecture et la flexibilité du schéma, mais au détriment de la normalisation.
|
Caractéristique |
Relationnel (SQL) |
NoSQL |
|
Mise en œuvre |
Tableaux de jonction : Utilise un troisième tableau avec des clés étrangères et des clés primaires composites. |
Intégration ou référence : Utilise des tableaux d'identifiants ou des documents imbriqués. |
|
Objectif principal |
Normalisation : Assure la cohérence des données et élimine les redondances. |
Performance : Priorité accordée à la vitesse de lecture et à l'évolutivité horizontale. |
|
Flexibilité |
Schéma rigide : Nécessite des structures prédéfinies et des jointures pour récupérer les données. |
Grande flexibilité : Permet des conceptions sans schéma et divers types de données. |
|
Compromis |
Jointures complexes : Peut devenir plus lent lorsque le volume de données augmente considérablement. |
Normalisation des sacrifices : Peut entraîner une duplication des données ou des données obsolètes. |
|
Exemples |
PostgreSQL, MySQL, SQL Server, Snowflake. |
MongoDB, DynamoDB, Cassandra. |
Les bases de données relationnelles sont privilégiées lorsque vous avez besoin d'une structure de schéma bien définie. Ces bases de données sont plus faciles à manipuler et permettent une meilleure gestion des données. Envisagez d'utiliser une base de données SQL relationnelle dans les cas suivants :
Les bases de données nosql sont adaptées aux situations où la flexibilité et la capacité à traiter des volumes importants sont prioritaires. Par exemple, les bases de données nosql telles que MongoDB permettent l'utilisation d'opérateurs tels que updateMany lorsque nous devons mettre à jour une multitude de documents. Voici quelques principes directeurs pour déterminer quand envisager une implémentation nosql :
Les relations plusieurs-à-plusieurs sont inévitables dans les modèles de données réalistes. Il est essentiel de les concevoir correctement pour garantir l'intégrité des données, l'évolutivité et l'exactitude des analyses. Les tables de jonction, lorsqu'elles sont correctement normalisées et indexées, constituent une base solide qui s'adapte aussi bien aux systèmes transactionnels qu'à l'analyse d'entreprise.
Chaque conception implique des compromis : normalisation ou performance, simplicité ou flexibilité, abstraction ou contrôle. La clé consiste à établir le profil de vos modèles d'accès, à choisir des modèles adaptés à votre charge de travail et à valider les conceptions par le biais d'une révision du schéma et de tests de requêtes.
Pour les professionnels souhaitant approfondir leurs compétences en conception de bases de données, je recommande vivement de s'inscrire à notre cursus professionnel d'analyste de données associé en SQL.
Cours de conception de bases de données
Cursus
Cours
Cours