Programa
Fundamentos da IA
10 h
A Alibaba acaba de lançar o Qwen2.5-Max, seu modelo de IA mais avançado até o momento. Este não é um modelo de raciocínio como o DeepSeek R1 ou o o1 da OpenAI, o que significa que você não pode ver seu processo de raciocínio.
É melhor você pensar no Qwen2.5-Max como um modelo generalista e um concorrente do GPT-4o, do Claude 3.5 Sonnet ou do DeepSeek V3.
Neste blog, falarei sobre o que é o Qwen2.5-Max, como ele foi desenvolvido, como ele se compara à concorrência e como você pode acessá-lo.
O Qwen2.5-Max é o modelo de IA mais avançado da Alibaba até o momento, projetado para competir com modelos de primeira linha como GPT-4o, Claude 3.5 Sonnet e DeepSeek V3.
A Alibaba, uma das maiores empresas de tecnologia da China, é mais conhecida por suas plataformas de comércio eletrônico, mas também construiu uma forte presença em computação em nuvem e inteligência artificial. A série Qwen faz parte de seu ecossistema de IA mais amplo, que varia de modelos menores de peso aberto a sistemas proprietários de grande escala.

Diferentemente de alguns modelos Qwen anteriores, o Qwen2.5-Max não é de código aberto, o que significa que seus pesos não estão disponíveis publicamente.
Treinada em 20 trilhões de tokens, a Qwen2.5-Max tem uma vasta base de conhecimento e fortes recursos gerais de IA. No entanto, ele não é um modelo de raciocínio como o DeepSeek R1 ou o o1 da OpenAI, o que significa que ele não mostra explicitamente seu processo de pensamento. No entanto, dada a expansão contínua da IA da Alibaba, poderemos ver um modelo de raciocínio dedicado no futuro - possivelmente com o Qwen 3.
O Qwen2.5-Max usa um Mistura de Especialistas (MoE) uma técnica também empregada pelo DeepSeek V3. Essa abordagem permite que o modelo seja ampliado, mantendo os custos de computação gerenciáveis. Vamos detalhar seus principais componentes de uma forma que seja fácil de entender.
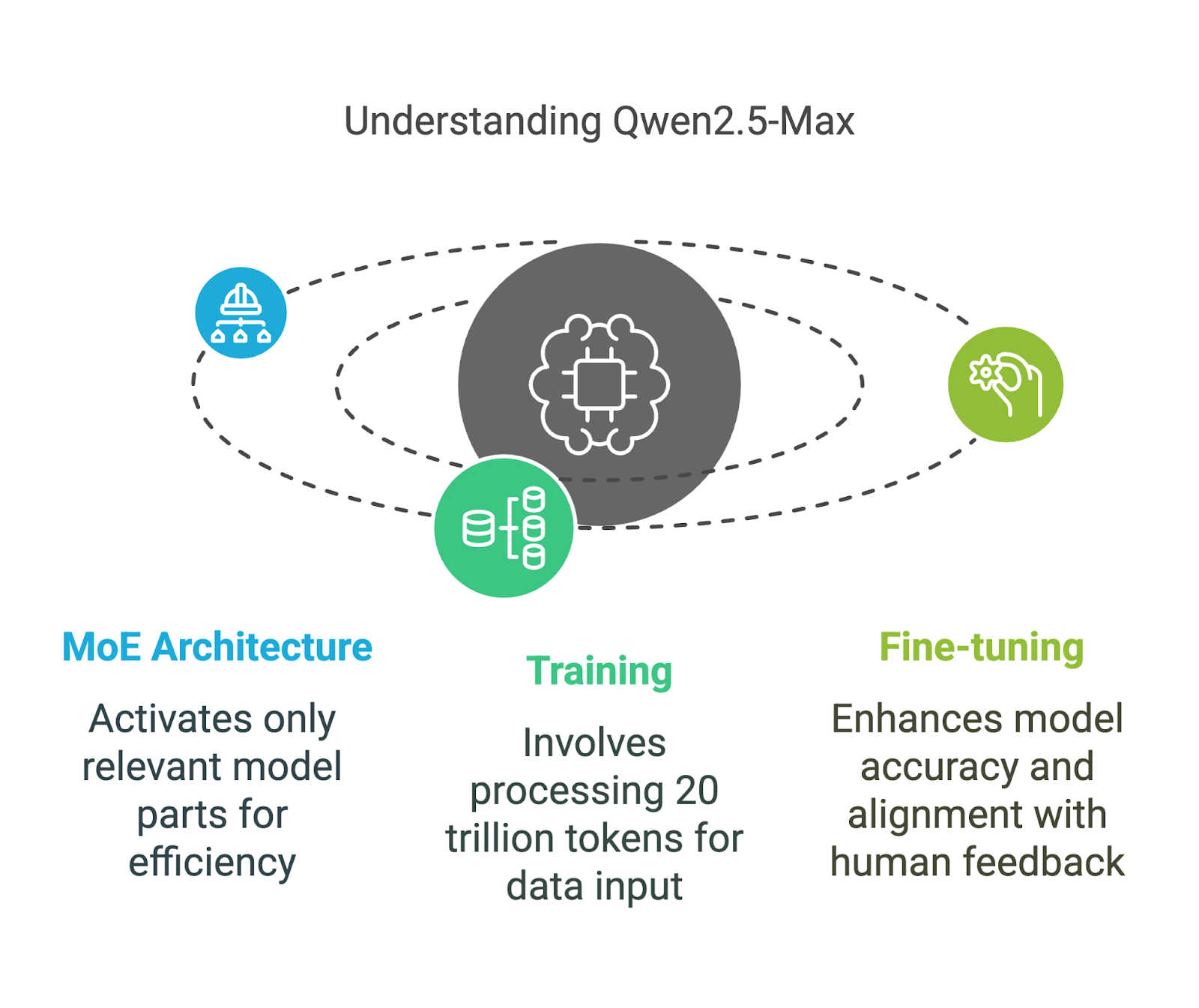
Ao contrário dos modelos tradicionais de IA que usam todos os seus parâmetros para cada tarefa, os modelos MoE, como o Qwen2.5-Max e o DeepSeek V3, ativam apenas as partes mais relevantes do modelo em um determinado momento.
Você pode pensar nisso como uma equipe de especialistas: se você fizer uma pergunta complexa sobre física, somente os especialistas em física responderão, enquanto o restante da equipe permanecerá inativo. Essa ativação seletiva significa que o modelo pode lidar com o processamento em larga escala de forma mais eficiente, sem exigir quantidades extremas de potência de computação.
Esse método torna o Qwen2.5-Max eficiente e dimensionável, permitindo que ele concorra com modelos densos como o GPT-4o e o Claude 3.5 Sonnet e, ao mesmo tempo, seja mais eficiente em termos de recursos - um modelo denso é aquele em que todos os parâmetros são ativados para cada entrada.
O Qwen2.5-Max foi treinado em 20 trilhões de tokens, abrangendo uma grande variedade de tópicos, idiomas e contextos.
Para colocar 20 trilhões de tokens em perspectiva, isso equivale a cerca de 15 trilhões de palavras - uma quantidade tão grande que é difícil de entender. Para fins de comparação, o livro 1984 de George Orwell contém cerca de 89.000 palavras, o que significa que o Qwen2.5-Max foi treinado no equivalente a 168 milhões de cópias de 1984.
No entanto, os dados brutos de treinamento, por si só, não garantem um modelo de IA de alta qualidade, por isso o Alibaba o refinou ainda mais:
O Qwen2.5-Max foi testado contra outros modelos líderes de IA para medir suas capacidades em várias tarefas. Esses benchmarks avaliam tanto os modelos de instrução (que são ajustados para tarefas como bate-papo e codificação) quanto os modelos básicos (que servem como base bruta antes do ajuste fino). Entender essa distinção ajuda a esclarecer o que os números realmente significam.
Os modelos de instrução são ajustados para aplicativos do mundo real, incluindo conversação, codificação e tarefas de conhecimento geral. O Qwen2.5-Max é comparado aqui a modelos como GPT-4o, Claude 3.5 Sonnet, Llama 3.1 405Be DeepSeek V3.
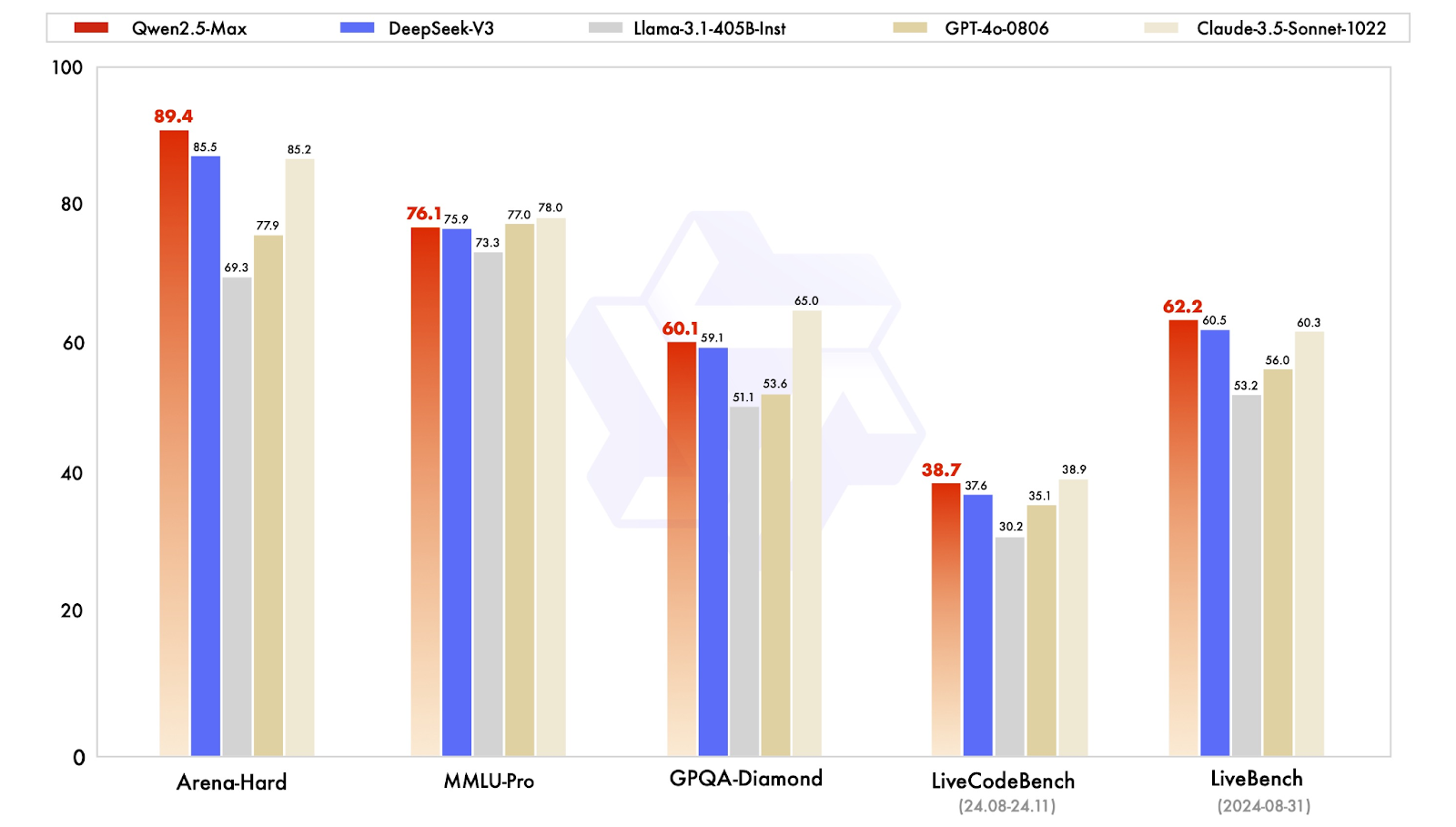
Comparação dos modelos de instrução. Fonte: QwenLM
Vamos analisar rapidamente os resultados:
De modo geral, o Qwen2.5-Max demonstra ser um modelo de IA completo, destacando-se em tarefas baseadas em preferências e recursos gerais de IA, ao mesmo tempo em que mantém conhecimento competitivo e habilidades de codificação.
Desde então GPT-4o e Claude 3.5 Sonnet são modelos proprietários sem versões básicas disponíveis publicamente, a comparação é limitada a modelos de peso aberto como Qwen2.5-Max, DeepSeek V3, LLaMA 3.1-405B e Qwen 2.5-72B. Isso fornece uma imagem mais clara de como o Qwen2.5-Max se posiciona em relação aos principais modelos abertos de grande escala.
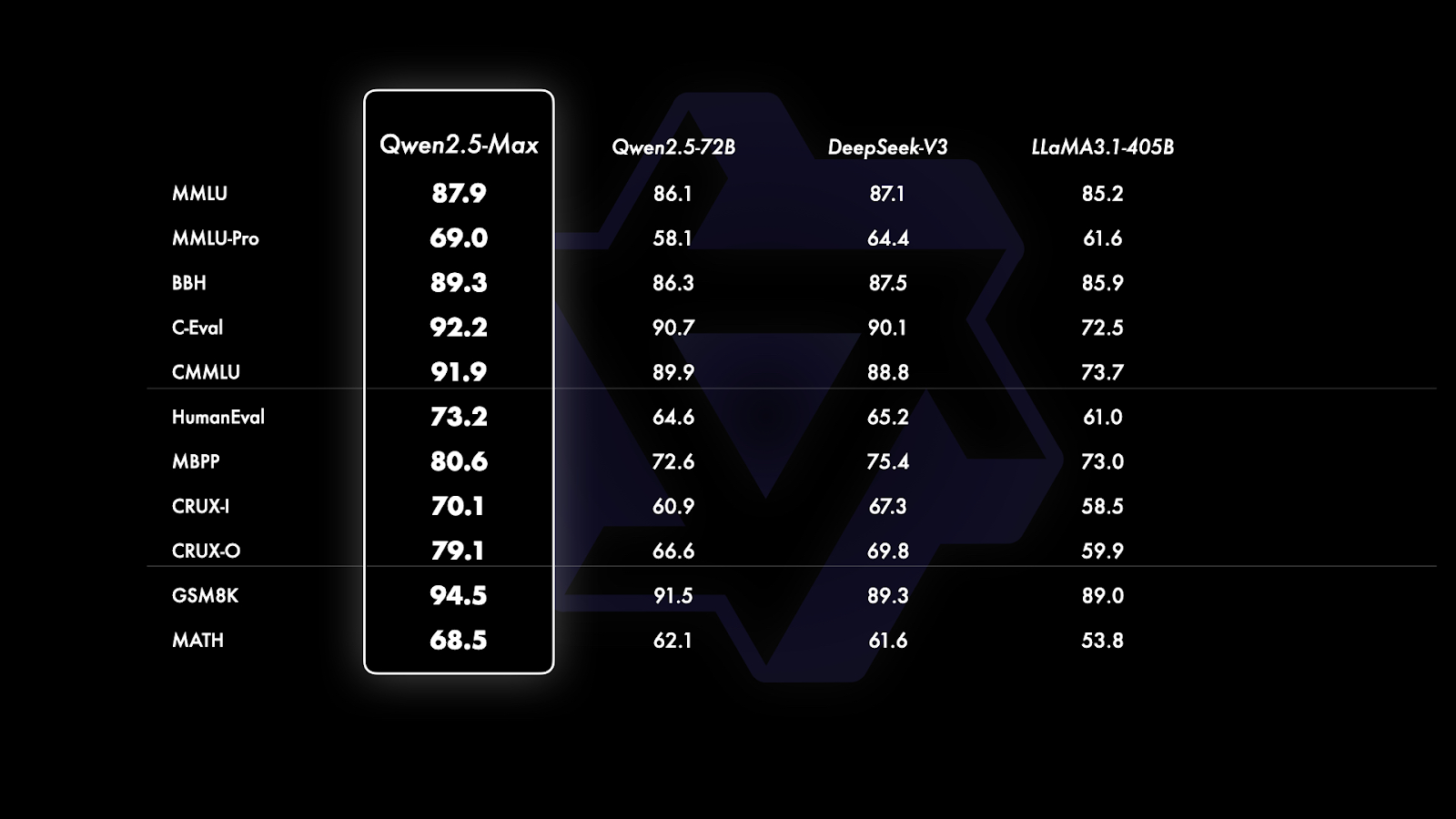
Comparação dos modelos básicos. Fonte: QwenLM
Se você observar atentamente o gráfico acima, ele está dividido em três seções com base no tipo de benchmark que está sendo avaliado:
O acesso ao Qwen2.5-Max é simples e você pode experimentá-lo gratuitamente sem nenhuma configuração complicada.
A maneira mais rápida de você experimentar o Qwen2.5-Max é por meio do Qwen Chat para você. Essa é uma interface baseada na Web que permite que você interaja com o modelo diretamente no navegador, assim como você usaria o ChatGPT no navegador.
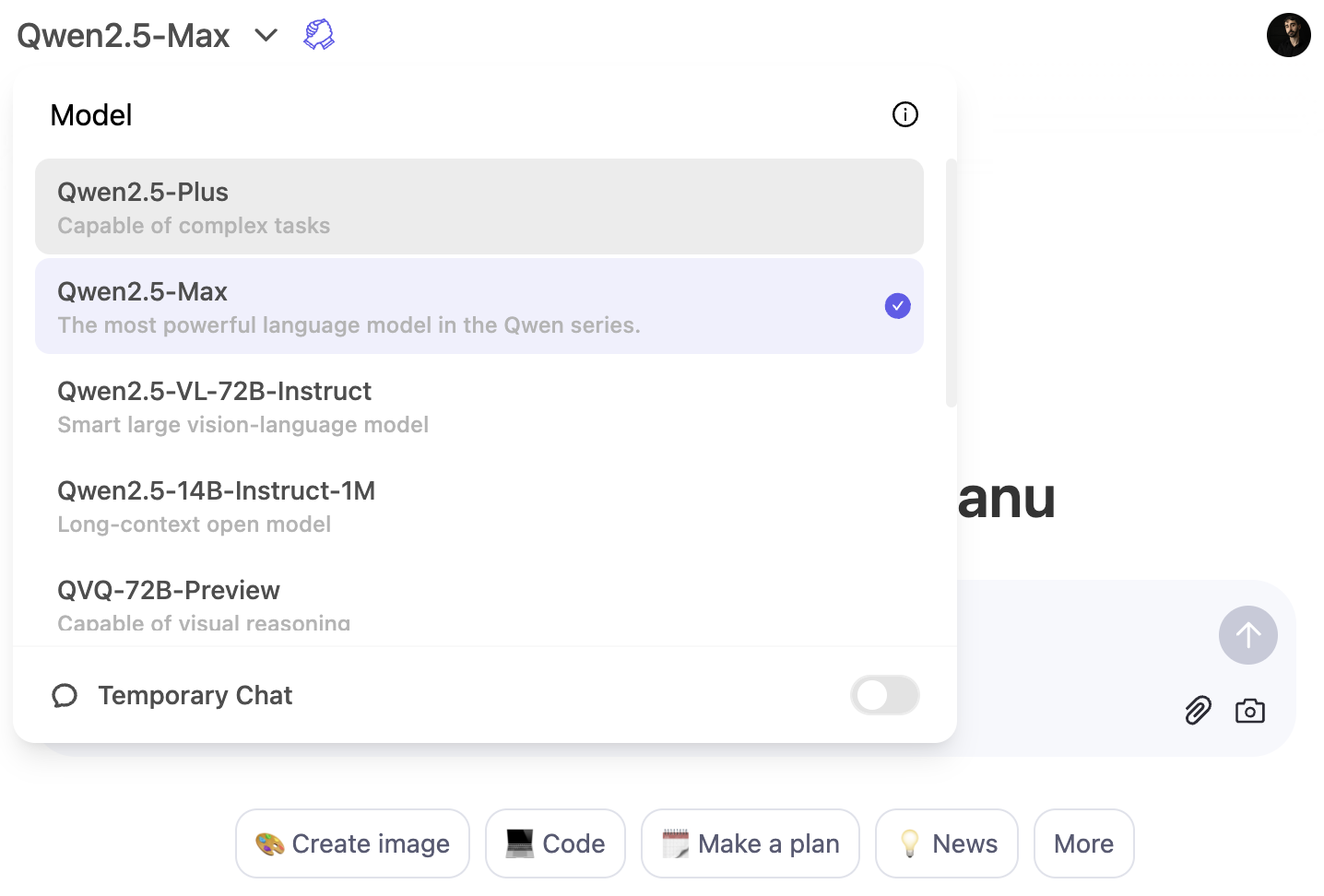
Para usar o modelo Qwen2.5-Max, clique no menu suspenso do modelo e selecione Qwen2.5-Max:
Para os desenvolvedores, o Qwen2.5-Max está disponível por meio da API do Alibaba Cloud Model Studio. Para usá-lo, você precisará se inscrever em uma conta do Alibaba Cloud, ativar o serviço Model Studio e gerar uma chave de API.
Como a API segue o formato da OpenAI, a integração deve ser simples se você já estiver familiarizado com os modelos da OpenAI. Para obter instruções detalhadas de configuração, visite o blog oficial do blog oficial do Qwen2.5-Max.
O Qwen2.5-Max é o modelo de IA mais capaz da Alibaba até o momento, criado para competir com modelos de primeira linha como GPT-4o, Claude 3.5 Sonnet e DeepSeek V3.
Diferentemente de alguns modelos anteriores do Qwen, o Qwen2.5-Max não é de código aberto, mas está disponível para teste por meio do Qwen Chat ou do acesso à API no Alibaba Cloud.
Dado o investimento contínuo do Alibaba em IA, não seria surpreendente ver um modelo focado em raciocínio no futuro - possivelmente com o Qwen 3.
Se você quiser ler mais notícias sobre IA, recomendo estes artigos:
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Richie Cotton
7 min
blog
Ryan Ong
8 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali


