programa
Llama Fundamentals
4 h
En 2017, Google sacudió a la comunidad de la IA con su innovador artículo "La atención es todo lo que necesitas". Este artículo presentó la arquitectura Transformer, que revolucionó el modelado de secuencias utilizando mecanismos de autoatención.
Recientemente, Google ha publicado un nuevo documento titulado "Titanes: Learning to Memorize at Test Time ", en el que proponen una novedosa arquitectura de memoria diseñada para mejorar la forma en que los sistemas de IA almacenan y utilizan la información.
Inspirándose en los entresijos de la memoria humana, esta investigación pretende superar las limitaciones de los sistemas de memoria existentes en los modelos de IA, en particular la ventana de contexto restringida de los Transformers.
La arquitectura Titanes introduce un sofisticado enfoque para integrar diferentes tipos de memoria -a corto plazo, a largo plazo y persistente- en los modelos de IA, permitiéndoles aprender y memorizar dinámicamente durante el tiempo de prueba.
Para ello es fundamental el mecanismo de la "sorpresa", que se basa en la tendencia del cerebro humano a recordar acontecimientos inesperados. Esta arquitectura permite a los modelos gestionar eficazmente la memoria incorporando sorpresas momentáneas y pasadas, garantizando la memorización y recuperación eficaz de los datos.
En este artículo, simplificaré los conceptos y mecanismos introducidos en el documento de los Titanes y exploraré el impacto potencial que esta nueva arquitectura podría tener en el futuro de la IA.
Transformadores son la arquitectura utilizada en la mayoría de los LLM actuales. Son conocidos por su capacidad para procesar secuencias de datos, como las palabras de una frase. Funcionan muy eficazmente utilizando algo llamado "atención"que les ayuda a centrarse en las partes relevantes de los datos. Sin embargo, se enfrentan a un reto clave: el tamaño de su ventana contextual.
La ventana contextual es básicamente la cantidad de información que un Transformer puede considerar a la vez. Piensa en ella como una ventana que recorre una frase, captando un segmento de palabras para comprender su significado en contexto.
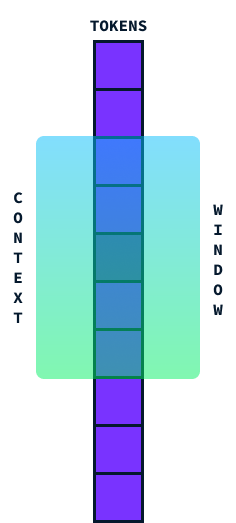
Idealmente, nos gustaría que esta ventana fuera lo más grande posible para procesar grandes secciones de texto a la vez, pero hay un inconveniente. A medida que intentamos hacer más grande esta ventana de contexto, la cantidad de cálculo necesaria aumenta significativamente debido a la complejidad cuadrática de tiempo y espacio de la arquitectura del transformador.
Esto significa que si duplicamos el tamaño de la ventana contextual, el cálculo no sólo se duplica, ¡sino que se vuelve cuatro veces más exigente! Esto ocurre porque cada palabra de la ventana debe compararse con todas las demás, por lo que los cálculos crecen rápidamente.
Los modelos actuales de última generación (SOTA) tienen 2 millones de ventanas de contexto de fichas. Sin embargo, procesarlos es bastante caro, y algunas aplicaciones, como la comprensión de vídeo, requieren ventanas de contexto más amplias. Disponer de una ventana de contexto más larga sin que aumente enormemente el coste computacional permitiría a los LLM manejar secuencias más largas con mayor eficacia, mejorando su rendimiento en tareas que requieran comprender grandes trozos de datos de una sola vez. Por eso, superar el problema del coste cuadrático es uno de los principales objetivos del avance de estos modelos.
Titanes es una nueva arquitectura que mejora la capacidad de los modelos de IA para almacenar y recuperar información con eficacia, especialmente cuando se trata de datos grandes y complejos, inspirándose en las complejidades de la memoria humana.
La memoria desempeña un papel crucial en el aprendizaje y el comportamiento humanos. Nos ayuda a retener información de experiencias pasadas, que utilizamos para tomar decisiones, adaptarnos a nuevas situaciones y resolver problemas. La memoria humana puede clasificarse a grandes rasgos en tres tipos:
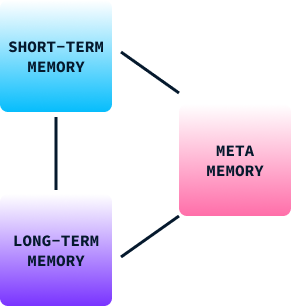
En el comportamiento humano, estos tipos de memoria trabajan juntos para permitirnos aprender de nuestros entornos, adaptar estrategias y mejorar nuestros comportamientos a lo largo del tiempo. Sin ella, estaríamos limitados a reflejos básicos y comportamientos estereotipados.
Al igual que el modelo de memoria humana, la estructura de la memoria de Titán se compone de tres partes:
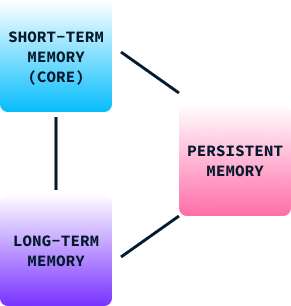
Al integrar estos tres tipos de memoria, la arquitectura de los Titanes permite a los modelos de IA gestionar dinámicamente la información de forma muy parecida a nuestro cerebro, mezclando el procesamiento inmediato con la retención de experiencias y conocimientos pasados.
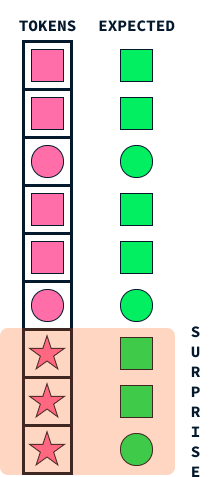
El mecanismo de "sorpresa" de los Titanes imita un aspecto fundamental de la memoria humana: nuestra tendencia a recordar acontecimientos sorprendentes o inesperados de forma más vívida. Este enfoque ayuda a los modelos de IA a decidir qué información almacenar, identificando los datos que sobresalen de lo que el modelo espera.
Imagina que vas caminando por la calle y todo parece ordinario y rutinario. Puede que no recuerdes este paseo cotidiano unas semanas después. Sin embargo, si ocurre algo inesperado, como que pase un colorido desfile o que recibas una llamada telefónica con noticias emocionantes, estos elementos sorprendentes captan tu atención, haciéndolos más memorables.
Del mismo modo, los Titanes emplean esta idea de sorpresa para priorizar qué información memorizar. Cuando el modelo encuentra datos que difieren significativamente de lo que había previsto (muy parecido a nuestro colorido desfile), marca esta información como sorprendente. Entonces, el sistema de memoria de los Titanes da prioridad al almacenamiento de estos sucesos inesperados, asegurándose de que no se pasen por alto datos importantes pero inusuales.
Este mecanismo permite a los Titanes gestionar eficazmente sus recursos de memoria, centrándose en la información significativa y atípica, en lugar de intentar retener cada detalle. Al igual que los humanos son más propensos a recordar lo inesperado, los titanes aplican esta estrategia natural para procesar y retener información vital de forma eficaz, lo que les permite rendir mejor en tareas complejas que implican clasificar grandes cantidades de datos.
Formalmente, el concepto de sorpresa se define como el gradiente de la función de pérdida con respecto a la entrada. Esto mide esencialmente cuánto tendrían que cambiar los parámetros del modelo en respuesta a la nueva entrada para minimizar la pérdida.
La intuición que subyace al uso del gradiente como medida de sorpresa es que un gradiente grande implica que se necesitan cambios significativos en el modelo para acomodar la nueva entrada, lo que indica que la entrada es muy diferente de lo que el modelo ha visto antes o que es inesperada y, por tanto, sorprendente.
El mecanismo de olvido en la arquitectura de los Titanes es un componente crítico diseñado para gestionar eficazmente la memoria neuronal a largo plazo, garantizando que el modelo retenga la información relevante mientras descarta lo que ya no es necesario.
Este mecanismo es vital cuando se manejan grandes cantidades de datos, en los que la memoria podría verse desbordada por información obsoleta o irrelevante. En la práctica, el mecanismo de olvido funciona ajustando la regla de actualización de la memoria para borrar selectivamente la información en función de su factor sorpresa y relevancia, que se evalúa dinámicamente durante la inferencia.
En concreto, un parámetro de compuerta adaptativa determina cuánto del estado anterior de la memoria debe conservarse, lo que permite al modelo borrar o conservar el contenido de la memoria de forma adaptativa. Este mecanismo evita el desbordamiento de la memoria y promueve una utilización eficiente del espacio de memoria, mejorando en última instancia la capacidad del modelo para centrarse en las entradas críticas y novedosas sin verse empantanado por una acumulación de datos innecesarios.
Este enfoque refleja fielmente los procesos cognitivos humanos, en los que los recuerdos sin importancia o anticuados se desvanecen con el tiempo, lo que permite un procesamiento cognitivo y una recuperación de la información más eficientes.
En aprendizaje automático tradicional el aprendizaje se produce durante la fase de entrenamiento. Una vez entrenado el modelo, se despliega para realizar inferencias -hacer predicciones basadas en datos nuevos y no vistos- sin necesidad de modificar sus parámetros aprendidos.
La arquitectura Titanes introduce un cambio innovador en este paradigma al permitir que los modelos aprendan dinámicamente durante la inferencia, también conocida como tiempo de prueba. Esta capacidad permite a los Titanes actualizar su memoria y sus parámetros en función de la sorpresa y la importancia de los datos entrantes mientras los procesan.
La capacidad de aprender en tiempo de inferencia proporciona varias ventajas significativas:
La arquitectura de los Titanes utiliza tres formas distintas de incorporar la memoria, cada una inspirada en diferentes aspectos de la cognición humana. Vamos a desglosar cada modo de memoria utilizando analogías sencillas.
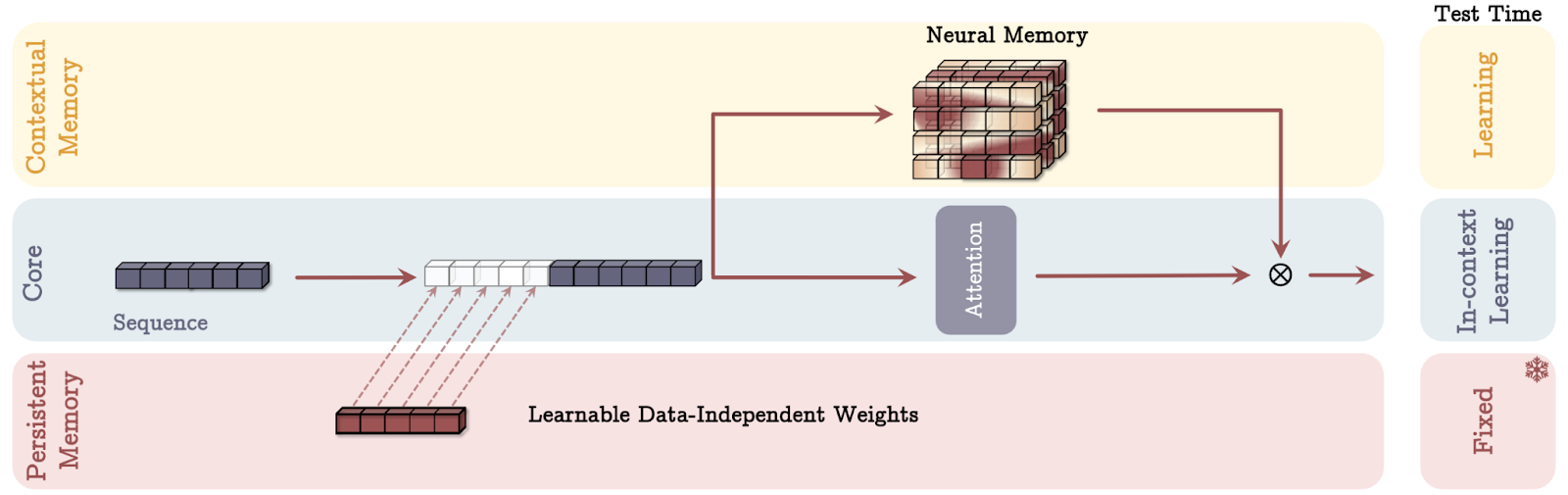
Fuente: Behrouz et. al, 2024
Imagina que tienes un asistente personal durante una reunión. Este asistente toma notas exhaustivas de conversaciones anteriores (memoria a largo plazo) y te susurra al oído fragmentos de información relevantes cuando los necesitas (recuperación).
En el modo MAC, el modelo de IA funciona de forma similar. Conserva un historial detallado de datos pasados y los integra con los datos actuales para tomar decisiones informadas. Al igual que tu asistente te ayuda a mezclar conocimientos pasados con discusiones presentes para mejorar tu toma de decisiones, MAC utiliza la memoria a largo plazo para proporcionar contexto a la información inmediata que se está procesando.
Imagina que tienes dos asesores en tu mente. Una se centra únicamente en lo que está ocurriendo ahora, proporcionando información sobre las tareas inmediatas (atención a corto plazo). La otra se basa en años de experiencia y sabiduría acumuladas (memoria a largo plazo).
El modo MAG actúa como un guardián que decide cuánta atención prestar a cada asesor, ajustando dinámicamente el enfoque en función de las necesidades presentes frente al aprendizaje pasado. Esto garantiza un enfoque equilibrado, que permite a la IA adaptarse tanto si la tarea en cuestión requiere precisión inmediata como conocimientos de experiencias pasadas.
Piensa en este modo como en múltiples capas de comprensión, donde cada capa procesa la información de forma única:
Este procesamiento por capas refleja cómo solemos digerir la información compleja por etapas, construyendo y refinando nuestra comprensión paso a paso. Cada modo ofrece puntos fuertes únicos, lo que permite a los Titanes manejar con eficacia diversas tareas imitando diferentes aspectos de cómo los humanos procesamos y retenemos la información.
Los resultados experimentales ponen de manifiesto la superioridad de la arquitectura de los Titanes sobre los Transformadores tradicionales y los modelos modernos en diversas tareas. He aquí un desglose de los principales resultados:
En general, los Titanes aprovechan un novedoso enfoque de gestión de la memoria que les permite manejar tareas complejas y de contexto largo con mayor eficacia, estableciendo un nuevo estándar para los modelos de IA tanto en escalabilidad como en precisión.
La arquitectura Transformer actual, aunque potente, tiene dificultades para manejar contextos extremadamente largos debido a problemas de escalado. La innovadora arquitectura de Titanes, inspirada en la memoria humana, supera estas limitaciones gestionando dinámicamente la memoria a corto plazo, a largo plazo y persistente.
Creo que la capacidad de los Titanes para aprender en tiempo de inferencia, adaptarse a los nuevos datos y priorizar la memoria basándose en un mecanismo de "sorpresa" tiene el potencial de crear sistemas de IA más parecidos a los humanos en su procesamiento de la información. Esto podría mejorar el rendimiento de los sistemas de IA en entornos complejos y dinámicos, lo que podría cambiar las reglas del juego para agentes de IA como Operador de OpenAI.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Bharath K
Tutorial
Zoumana Keita



