
Track
AI Business Fundamentals
12 hr
QwQ-32B is not just a regular chatbot-style AI model—it belongs to a different category: reasoning models.
While most general-purpose AI models, like GPT-4.5 or DeepSeek-V3, are designed to generate fluid, conversational text on a wide range of topics, reasoning models focus on breaking down problems logically, working through steps, and arriving at structured answers.
In the example below, we can see directly the thinking process of QwQ-32B:
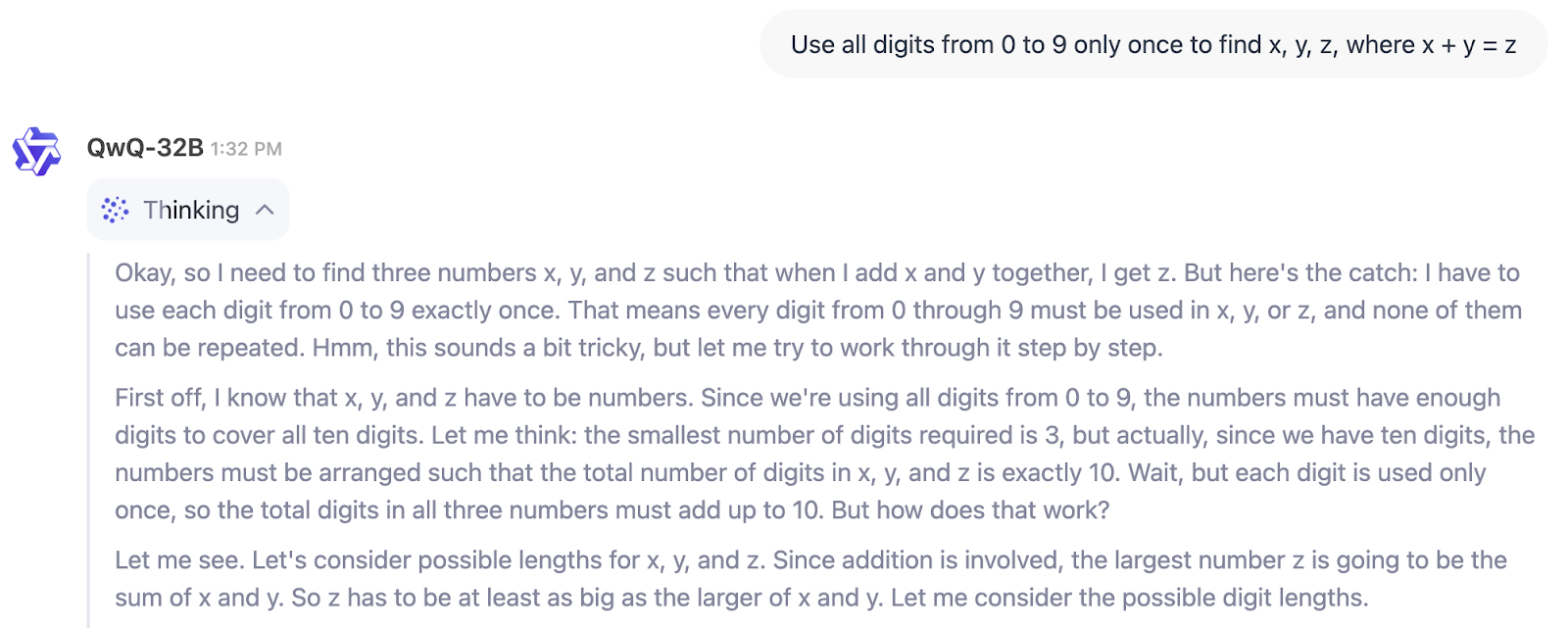
So, who is QwQ-32B for? If you’re looking for a model to help with writing, brainstorming, or summarizing, this isn’t it.
But if you need something to tackle technical problems, verify multi-step solutions, or assist in domains like scientific research, finance, or software development, QwQ-32B is built for that kind of structured reasoning. It’s particularly useful for engineers, researchers, and developers who require AI that can handle logical workflows rather than just generating text.
There’s also a broader industry trend to consider. Similar to the rise of small language models (SLMs), we may be witnessing with QwQ-32B the emergence of “small reasoning models” (I totally made this term up). Why am I saying this? Well, there’s a 20-fold difference between the 671B parameters of DeepSeek-R1 and the 32B of QwQ-32B, yet QwQ-32B still gets close in performance (as we’ll see below in the section on benchmarks).
QwQ-32B is built to reason through complex problems, and a big part of that comes from how it was trained. Unlike traditional AI models that rely only on pretraining and fine-tuning, QwQ-32B incorporates reinforcement learning (RL), a method that allows the model to refine its reasoning by learning from trial and error.
This training approach has been gaining traction in the AI space, with models like DeepSeek-R1 using multi-stage RL training to achieve stronger reasoning capabilities.
Most language models learn by predicting the next word in a sentence based on vast amounts of text data. While this works well for fluency, it doesn’t necessarily make them good at problem-solving.
Reinforcement learning changes this by introducing a feedback system: instead of just generating text, the model gets rewarded for finding the right answer or following a correct reasoning path. Over time, this helps the AI develop better judgment when tackling complex problems like math, coding, and logical reasoning .
QwQ-32B takes this further by integrating agent-related capabilities, allowing it to adapt its reasoning based on environmental feedback. This means that instead of just memorizing patterns, the model can use tools, verify outputs, and refine its responses dynamically. These improvements make it more reliable for structured reasoning tasks, where simply predicting words isn’t enough.
One of the most impressive aspects of QwQ-32B’s development is its efficiency. Despite having only 32 billion parameters, it achieves performance comparable to DeepSeek-R1, which has 671 billion parameters (with 37 billion activated). This suggests that scaling up reinforcement learning can be just as impactful as increasing model size.
Another key aspect of its design is its 131,072-token context window, which allows it to process and retain information over long passages of text.
QwQ-32B is designed to compete with state-of-the-art reasoning models, and its benchmark results show that it gets surprisingly close to DeepSeek-R1, despite being much smaller in size. The model was tested on a range of benchmarks evaluating math, coding, and structured reasoning, where it often performed at or near DeepSeek-R1 levels.
Source: Qwen
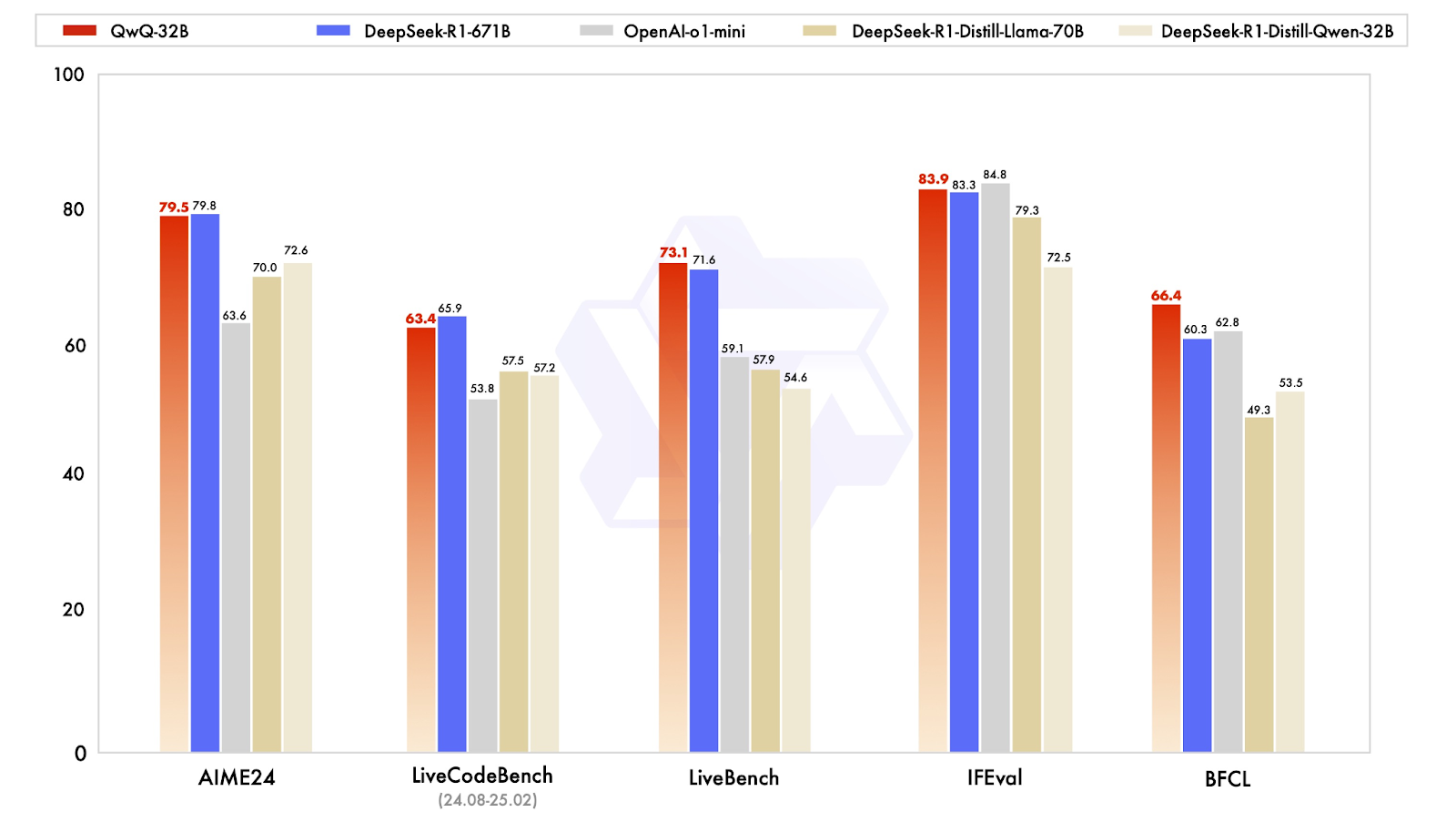
One of the most telling results comes from AIME24, a math benchmark designed to test math problem-solving. QwQ-32B scored 79.5, just behind DeepSeek-R1 at 79.8 and well ahead of OpenAI’s o1-mini (63.6) and DeepSeek’s distilled models (70.0–72.6). This is particularly impressive given that QwQ-32B has just 32 billion parameters compared to DeepSeek-R1’s 671 billion.
Another key benchmark, IFEval, which tests functional and symbolic reasoning, also saw QwQ-32B perform at a competitive level, scoring 83.9—slightly above DeepSeek-R1! It’s only narrowly behind OpenAI’s o1-mini, which leads this category with a score of 84.8.
For AI models meant to assist with software development, coding benchmarks are essential. In LiveCodeBench, which measures the ability to generate and refine code, QwQ-32B scored 63.4, slightly behind DeepSeek-R1 at 65.9 but significantly ahead of OpenAI’s o1-mini at 53.8 . This suggests that reinforcement learning played a significant role in improving QwQ-32B’s ability to iteratively reason through coding problems rather than just generating one-off solutions.
QwQ-32B scored 73.1 on LiveBench, an evaluation of general problem-solving skills, slightly outperforming DeepSeek-R1's score of 71.6. Both models scored significantly higher than OpenAI's o1-mini, which achieved a score of 59.1.This supports the idea that small, well-optimized models can close the gap with massive proprietary systems, at least in structured tasks.
Perhaps the most interesting result is on BFCL, a benchmark assessing broad functional reasoning. Here, QwQ-32B achieved 66.4, surpassing DeepSeek-R1 (60.3) and OpenAI’s o1-mini (62.8) . This suggests that QwQ-32B’s training approach, particularly its agentic capabilities and reinforcement learning strategies, gives it an edge in areas where problem-solving requires flexibility and adaptation rather than just memorized patterns.
QwQ-32B is fully open-source, making it one of the few high-performing reasoning models available for anyone to experiment with. Whether you want to test it interactively, integrate it into an application, or run it on your own hardware, there are multiple ways to access the model.
For those who just want to try the model without setting anything up, Qwen Chat offers an easy way to interact with QwQ-32B. The web-based chatbot interface lets you test the model’s reasoning, math, and coding capabilities directly. While it’s not as flexible as running the model locally, it provides a straightforward way to see its strengths in action.
To try it, you need to access https://chat.qwen.ai/ and make an account. Once you’re in, start by selecting the QwQ-32B model in the model picker menu:
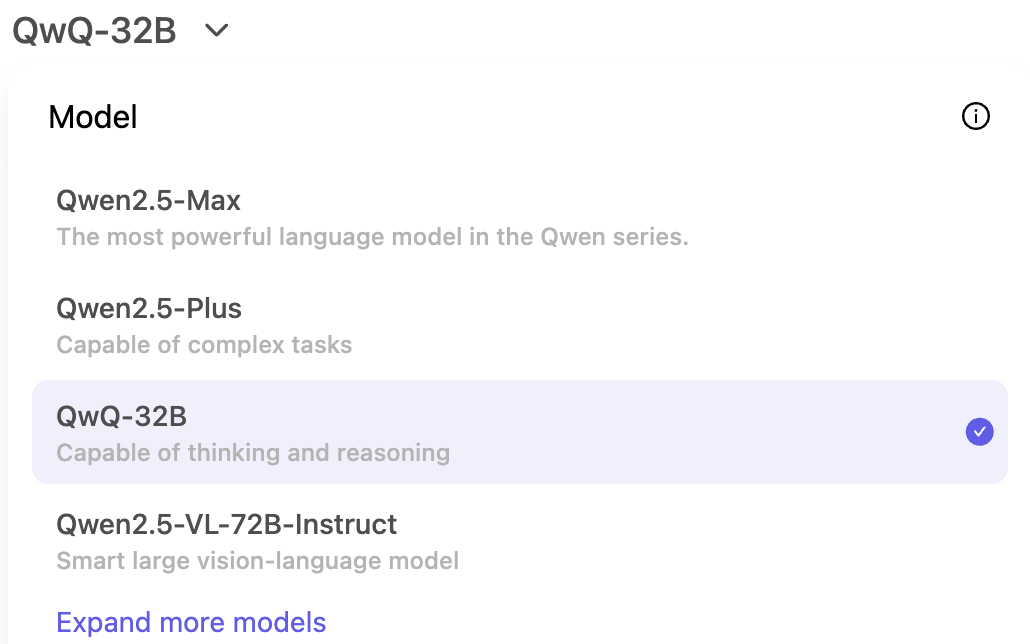
The Thinking (QwQ) mode is activated by default and can’t be turned off with this model. You can start prompting in the chat-based interface:
Developers looking to integrate QwQ-32B into their own workflows can download it from Hugging Face or ModelScope. These platforms provide access to the model weights, configurations, and inference tools, making it easier to deploy the model for research or production use.
QwQ-32B challenges the idea that only massive models can perform well in structured reasoning. Despite having far fewer parameters than DeepSeek-R1, it delivers strong results in math, coding, and multi-step problem-solving, showing that training techniques like reinforcement learning and long-context optimization can make a significant impact.
What stands out the most to me is its open-source availability. While many high-performing reasoning models remain locked behind proprietary APIs, QwQ-32B is accessible on Hugging Face, ModelScope, and Qwen Chat, making it easier for researchers and developers to test and build with.
Learn AI with these courses!
Track
Track
Track
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Vinod Chugani
7 min
blog
François Aubry
8 min
Tutorial
Dr Ana Rojo-Echeburúa


