Programa
Fundamentos do Negócio de IA
12 h
O QwQ-32B não é apenas um modelo de IA do tipo chatbot comum, ele pertence a uma categoria diferente: modelos de raciocínio.
Embora a maioria dos modelos de IA de uso geral, como o GPT-4.5 ou DeepSeek-V3são projetados para gerar textos fluidos e de conversação sobre uma ampla gama de tópicos, os modelos de raciocínio se concentram em decompor os problemas logicamente, trabalhando em etapas e chegando a respostas estruturadas.
No exemplo abaixo, podemos ver diretamente o processo de pensamento do QwQ-32B:
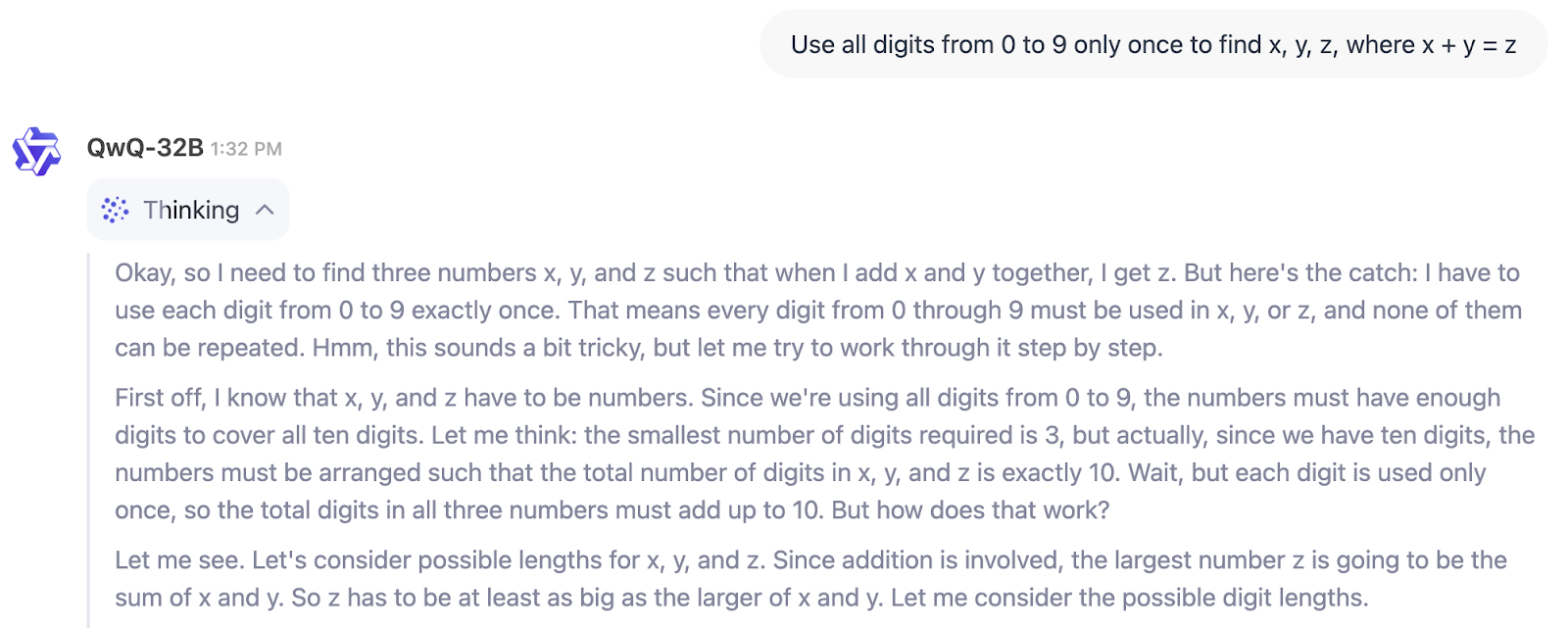
Então, para quem é o QwQ-32B? Se você está procurando um modelo para ajudar a escrever, fazer brainstorming ou resumir, não é esse o caso.
Mas se você precisar de algo para resolver problemas técnicos, verificar soluções de várias etapas ou auxiliar em domínios como pesquisa científica, finanças ou desenvolvimento de software, o QwQ-32B foi criado para esse tipo de raciocínio estruturado. Ele é particularmente útil para engenheiros, pesquisadores e desenvolvedores que precisam de uma IA capaz de lidar com fluxos de trabalho lógicos em vez de apenas gerar texto.
Há também uma tendência mais ampla do setor a ser considerada. Semelhante ao surgimento de modelos de linguagem pequenos (SLMs)podemos estar testemunhando com o QwQ-32B o surgimento de "pequenos modelos de raciocínio" (inventei totalmente esse termo). Por que estou dizendo isso? Bem, há uma diferença de 20 vezes entre os parâmetros 671B do DeepSeek-R1 e os 32B do QwQ-32B, mas o QwQ-32B ainda se aproxima em termos de desempenho (como veremos abaixo na seção sobre benchmarks).
O QwQ-32B foi desenvolvido para raciocinar sobre problemas complexos, e grande parte disso se deve à forma como ele foi treinado. Ao contrário dos modelos tradicionais de IA que dependem apenas de pré-treinamento e ajuste finoo QwQ-32B incorpora aprendizado por reforço (RL)um método que permite que o modelo refine seu raciocínio aprendendo por tentativa e erro.
Essa abordagem de treinamento vem ganhando força no espaço da IA, com modelos como o DeepSeek-R1 usando treinamento de RL em vários estágios para obter recursos de raciocínio mais fortes.
A maioria dos modelos de linguagem aprende prevendo a próxima palavra em uma frase com base em grandes quantidades de dados de texto. Embora isso funcione bem para a fluência, não necessariamente os torna bons na solução de problemas.
O aprendizado por reforço muda isso ao introduzir um sistema de feedback: em vez de apenas gerar texto, o modelo é recompensado por encontrar a resposta certa ou seguir um caminho de raciocínio correto. Com o tempo, isso ajuda a IA a desenvolver um melhor julgamento ao lidar com problemas complexos, como matemática, codificação e raciocínio lógico .
O QwQ-32B leva isso adiante ao integrar recursos relacionados a agentes, permitindo que ele adapte seu raciocínio com base no feedback ambiental. Isso significa que, em vez de apenas memorizar padrões, o modelo pode usar ferramentas, verificar os resultados e refinar suas respostas dinamicamente. Esses aprimoramentos o tornam mais confiável para tarefas de raciocínio estruturado, em que a simples previsão de palavras não é suficiente.
Um dos aspectos mais impressionantes do desenvolvimento do QwQ-32B é sua eficiência. Apesar de ter apenas 32 bilhões de parâmetros, ele atinge um desempenho comparável ao do DeepSeek-R1, que tem 671 bilhões de parâmetros (com 37 bilhões ativados). Isso sugere que o aumento da escala do aprendizado por reforço pode ser tão impactante quanto o aumento do tamanho do modelo.
Outro aspecto importante de seu design é a janela de contexto de 131.072 tokens, que permite processar e reter informações em longas passagens de texto.
O QwQ-32B foi projetado para competir com modelos de raciocínio de última geração, e seus resultados de benchmark mostram que ele se aproxima surpreendentemente do DeepSeek-R1, apesar de ser muito menor em tamanho. O modelo foi testado em uma série de benchmarks que avaliaram matemática, codificação e raciocínio estruturado, nos quais o desempenho foi frequentemente igual ou próximo aos níveis do DeepSeek-R1.
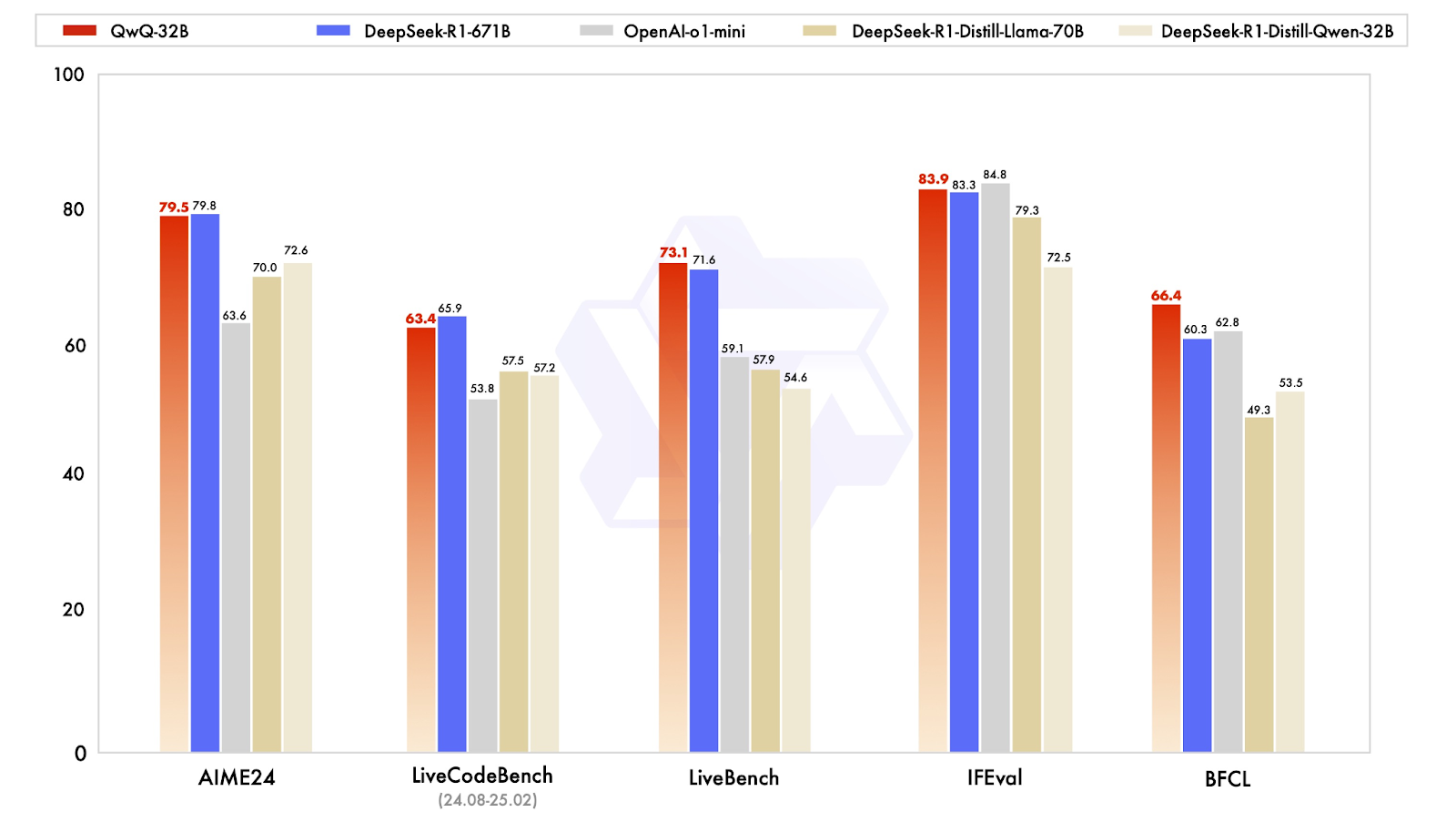
Fonte: Qwen
Um dos resultados mais reveladores vem do AIME24, um benchmark de matemática criado para testar a resolução de problemas matemáticos. O QwQ-32B obteve 79,5 pontos, logo atrás do DeepSeek-R1 com 79,8 e bem à frente do o1-mini da OpenAI (63,6) e dos modelos destilados do DeepSeek modelos destilados (70.0-72.6). Isso é particularmente impressionante, pois o QwQ-32B tem apenas 32 bilhões de parâmetros, em comparação com os 671 bilhões do DeepSeek-R1.
Outro benchmark importante, o IFEval, que testa o raciocínio funcional e simbólico, também apresentou um desempenho competitivo do QwQ-32B, com pontuação de 83,9, um pouco acima do DeepSeek-R1! Ele está apenas um pouco atrás do o1-mini da OpenAI, que lidera essa categoria com uma pontuação de 84,8.
Para modelos de IA destinados a auxiliar no desenvolvimento de software, os benchmarks de codificação são essenciais. No LiveCodeBench, que mede a capacidade de gerar e refinar códigos, o QwQ-32B obteve 63,4 pontos, um pouco atrás do DeepSeek-R1, com 65,9, mas significativamente à frente do o1-mini da OpenAI, com 53,8 . Isso sugere que a aprendizagem por reforço desempenhou um papel significativo no aprimoramento da capacidade do QwQ-32B de raciocinar iterativamente por meio de problemas de codificação, em vez de apenas gerar soluções únicas.
O QwQ-32B obteve 73,1 pontos no LiveBench, uma avaliação das habilidades gerais de resolução de problemas, superando ligeiramente a pontuação de 71,6 do DeepSeek-R1. Ambos os modelos obtiveram uma pontuação significativamente mais alta do que o o1-mini da OpenAI, que alcançou uma pontuação de 59,1. Isso corrobora a ideia de que modelos pequenos e bem otimizados podem diminuir a diferença em relação a sistemas proprietários de grande porte, pelo menos em tarefas estruturadas.
Talvez o resultado mais interessante esteja no BFCL, um benchmark que avalia o raciocínio funcional amplo. Aqui, o QwQ-32B atingiu 66,4, superando o DeepSeek-R1 (60,3) e o o1-mini da OpenAI (62,8) . Isso sugere que a abordagem de treinamento do QwQ-32B, especialmente seus recursos agênticos e estratégias de aprendizagem por reforço, oferece uma vantagem em áreas em que a solução de problemas exige flexibilidade e adaptação, em vez de apenas padrões memorizados.
O QwQ-32B é totalmente de código aberto, o que o torna um dos poucos modelos de raciocínio de alto desempenho disponíveis para que qualquer pessoa possa fazer experiências com ele. Se você quiser testá-lo interativamente, integrá-lo a um aplicativo ou executá-lo em seu próprio hardware, há várias maneiras de acessar o modelo.
Para aqueles que desejam apenas experimentar o modelo sem configurar nada, o Qwen Chat oferece uma maneira fácil de interagir com o QwQ-32B. A interface do chatbot baseada na Web permite que você teste diretamente os recursos de raciocínio, matemática e codificação do modelo. Embora não seja tão flexível quanto executar o modelo localmente, ele oferece uma maneira direta de ver seus pontos fortes em ação.
Para experimentá-lo, você precisa acessar https://chat.qwen.ai/ e criar uma conta. Quando você entrar, comece selecionando o modelo QwQ-32B no menu de seleção de modelos:
O modoThinking (QwQ) é ativado por padrão e não pode ser desativado com esse modelo. Você pode começar a solicitar na interface baseada em bate-papo:
Os desenvolvedores que desejam integrar o QwQ-32B em seus próprios fluxos de trabalho podem baixá-lo em Hugging Face ou do ModelScope. Essas plataformas fornecem acesso aos pesos do modelo, às configurações e às ferramentas de inferência, facilitando a implantação do modelo para uso em pesquisa ou produção.
O QwQ-32B desafia a ideia de que somente modelos massivos podem ter um bom desempenho no raciocínio estruturado. Apesar de ter muito menos parâmetros do que o DeepSeek-R1, ele oferece resultados sólidos em matemática, codificação e solução de problemas em várias etapas, mostrando que técnicas de treinamento como aprendizado por reforço e otimização de contexto longo podem ter um impacto significativo.
O que mais se destaca para mim é sua disponibilidade de código aberto. Enquanto muitos modelos de raciocínio de alto desempenho permanecem trancados atrás de APIs proprietárias, o QwQ-32B pode ser acessado no Hugging Face, ModelScope e Qwen Chat, facilitando o teste e a criação para pesquisadores e desenvolvedores.
Aprenda IA com estes cursos!
Programa
Programa
Programa
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
blog
Abid Ali Awan
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita



