
programa
Desarrollo de aplicaciones de IA
21 h
El ajuste fino por refuerzo (RFT) es una técnica para refinar el conocimiento de grandes modelos lingüísticos mediante un bucle de entrenamiento basado en recompensas.
Los modelos de frontera son notables modelos lingüísticos de uso general. Los mejores destacan en una amplia gama de tareas, como traducción, asistencia, programación, etc. Sin embargo, un área importante de la investigación en curso se centra en afinar eficientemente estos modelos. El objetivo es adaptarlos para que adopten tonos y estilos específicos o se especialicen en campos reducidos, como proporcionar asesoramiento médico experto o realizar tareas de clasificación específicas de un dominio.
El reto consiste en lograr este ajuste de forma eficaz. Eficiencia significa consumir menos potencia de cálculo y requerir menos conjuntos de datos etiquetados sin dejar de obtener resultados de alta calidad. Aquí es donde entra en juego la RFT, que ofrece una solución prometedora a este problema.
Así es como se ve la configuración de RFT en el panel de control de OpenAI. Fuente: OpenAI
Según el anuncio de OpenAI de OpenAIla RFT puede afinar eficazmente un modelo con sólo unas docenas de ejemplos. En muchos campos, como el sector médico, donde los datos son escasos y costosos, con menos datos se llega muy lejos.
La RFT se basa en la columna vertebral del aprendizaje por refuerzo (RL), donde los agentes son recompensados positiva o negativamente en función de sus acciones, lo que les permite alinearse con el comportamiento que esperamos de ellos. Esto se consigue asignando una puntuación a la producción del agente. Mediante un entrenamiento iterativo basado en estas puntuaciones, los agentes aprenden sin necesidad de comprender explícitamente las reglas ni de memorizar pasos predefinidos para resolver el problema.
Cuando se combina con los esfuerzos para mejorar los LLM en tareas especializadas, la RFT surge de la RL y de las técnicas de ajuste fino. La idea es realizar la RFT mediante una serie de pasos:
1. Proporciona un conjunto de datos estructurado y etiquetado que dote al modelo de los conocimientos que quieres que aprenda. Como en una tarea típica de aprendizaje automático, este conjunto de datos debe dividirse en un conjunto de entrenamiento y otro de validación.
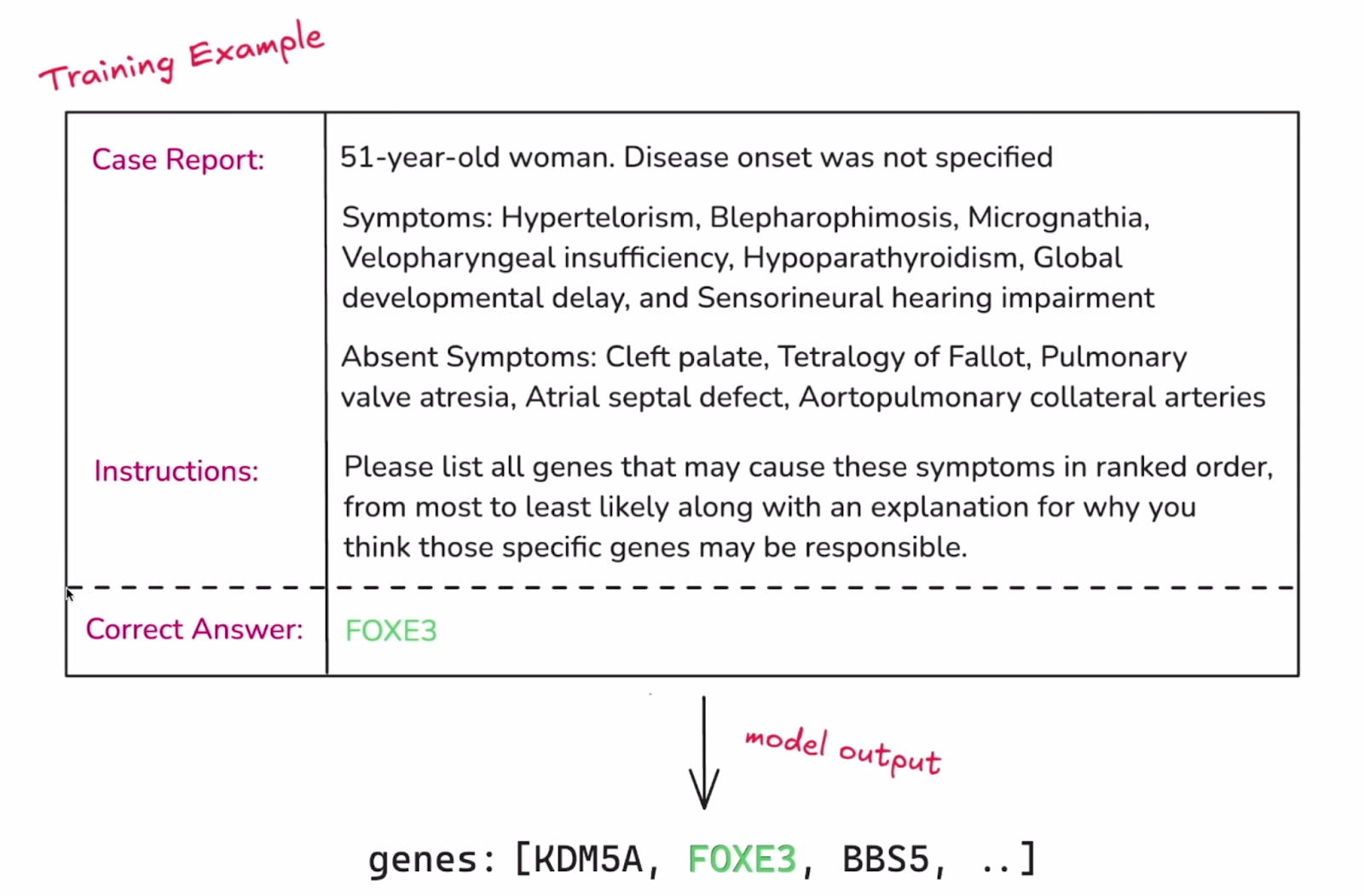
Ejemplo de una sola instancia del conjunto de datos. Fuente: OpenAI
2. El siguiente componente crítico del RFT es establecer una forma de evaluar los resultados del modelo. En un proceso típico de ajuste fino, el modelo simplemente intenta reproducir la respuesta objetivo etiquetada. Sin embargo, en la RFT, el modelo debe desarrollar un proceso de razonamiento que conduzca a esas respuestas. La graduación de las salidas del modelo es lo que lo guía durante el ajuste fino, y se hace utilizandolos "Graders" de . La calificación puede oscilar entre 0 y 1 o en cualquier punto intermedio, y hay muchas formas de asignar una calificación al conjunto de resultados de un modelo. OpenAI ha anunciado planes para desplegar más calificadores y posiblemente introducir una forma de que los usuarios implementen sus propios calificadores personalizados.
3. Una vez que el modelo responde a la entrada del conjunto de entrenamiento, su salida es puntuada por el calificador. Esta puntuación sirve como señal de "recompensa". Los pesos y parámetros del modelo se modifican para maximizar las recompensas futuras.
4. El modelo se afina mediante pasos repetidos. Con cada ciclo, el modelo refina su estrategia y el conjunto de validación (que se mantiene separado del entrenamiento) se utiliza periódicamente para comprobar lo bien que estas mejoras se generalizan a nuevos ejemplos. Cuando las puntuaciones del modelo mejoran con los datos de validación, es una buena señal de que el modelo está aprendiendo realmente estrategias significativas y no simplemente memorizando soluciones.
Esta explicación capta la esencia de la RFT, pero la aplicación y los detalles técnicos pueden diferir.
Si observamos a continuación los resultados de la evaluación de RFT, que comparan un modelo o1-mini afinado con un modelo o1-mini y o1 estándar, resulta sorprendente que RFT, utilizando un conjunto de datos de sólo 1.100 ejemplos, consiguiera una precisión mayor que el modelo modelo o1a pesar de que este último es mayor y más avanzado que el o1-mini.
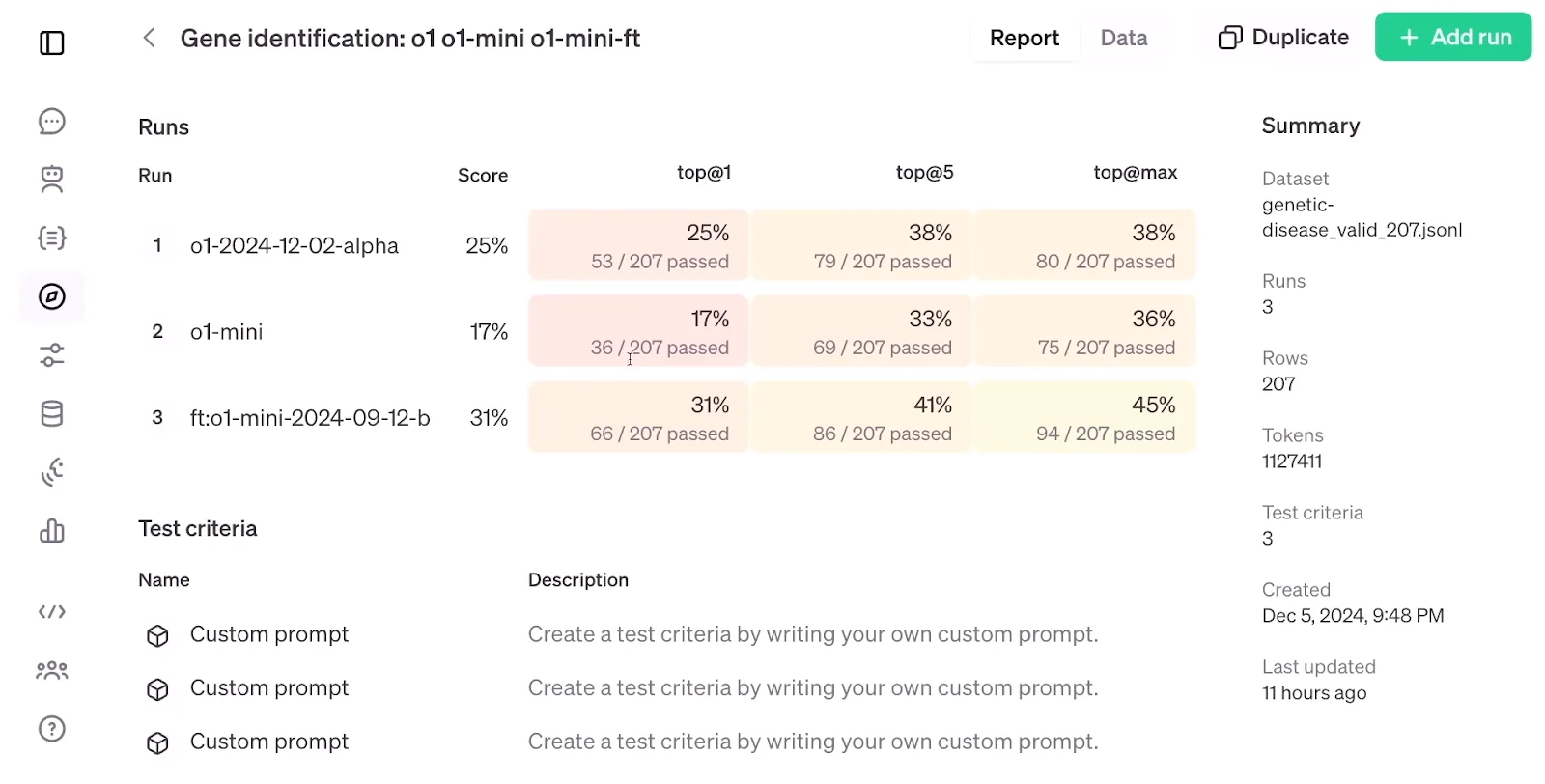
Evaluación del RFT. Fuente: OpenAI
El ajuste fino supervisado (SFT) consiste en tomar un modelo preentrenado y ajustarlo con datos adicionales mediante técnicas de aprendizaje supervisado. En la práctica, la SFT funciona mejor cuando el objetivo es alinear la salida o el formato del modelo con un conjunto de datos concreto o asegurarse de que el modelo sigue determinadas instrucciones.
Aunque tanto el ajuste fino supervisado como el ajuste fino por refuerzo se basan en datos etiquetados, los utilizan de forma diferente. En la SFT, los datos etiquetados dirigen directamente las actualizaciones del modelo. El modelo lo ve como la salida objetivo y ajusta sus parámetros para cerrar la diferencia entre su salida prevista y la respuesta correcta conocida.
En la RFT, la exposición del modelo a la etiqueta es indirecta, ya que se utiliza principalmente para crear la señal de recompensa y no como objetivo directo. Por eso se espera que el modelo requiera menos datos etiquetados en RFT: el modelo pretende encontrar patrones para producir el resultado que deseamos, en lugar de aspirar directamente a producir nuestros resultados, y esto promete más tendencia a generalizar.
Resumamos las diferenciascon esta tabla:
|
Función |
Ajuste fino supervisado (SFT) |
Ajuste fino del refuerzo (RFT) |
|
Idea central |
Entrena directamente el modelo con datos etiquetados para que coincida con el resultado deseado. |
Utiliza un "Grader" para recompensar al modelo por generar los resultados deseados. |
|
Uso de la etiqueta |
Objetivo directo a imitar por el modelo. |
Se utiliza indirectamente para crear una señal de recompensa para el modelo. |
|
Eficacia de los datos |
Requiere más datos etiquetados. |
Potencialmente requiere menos datos etiquetados debido a la generalización. |
|
Implicación humana |
Sólo en el etiquetado inicial de datos. |
Sólo en el diseño de la función "Grader". |
|
Generalización |
Puede sobreajustarse a los datos de entrenamiento, limitando la generalización. |
Mayor potencial de generalización debido a la concentración en patrones y recompensas. |
|
Alineación con las preferencias humanas |
Limitada, ya que se basa únicamente en imitar los datos etiquetados. |
Puede alinearse mejor si el "Calificador" refleja con precisión las preferencias humanas. |
|
Ejemplos |
Afinar un modelo lingüístico para generar tipos específicos de formatos de texto (como poemas o código). |
Entrenar un modelo lingüístico para generar contenidos creativos que sean juzgados por un "Calificador" en función de su originalidad y coherencia. |
Al leer sobre el RFT, no pude evitar pensar en otra técnica clásica y eficaz llamada aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). En RLHF, los anotadores humanos proporcionan información sobre cómo responder a las instrucciones, y se entrena un modelo de recompensa para convertir esta información en señales numéricas de recompensa. A continuación, estas señales se utilizan para afinar los parámetros del modelo preentrenado mediante optimización de la política proximal (OPP).
Aunque el RFT saca la retroalimentación humana del bucle y confía en el Grader para asignar la señal de recompensa a la respuesta del modelo, la idea de integrar el aprendizaje por refuerzo en el ajuste fino del LLM sigue siendo coherente con la del RLHF.
Curiosamente, RLHF fue el método que utilizaron anteriormente para alinear mejor el modelo en el proceso de entrenamiento ChatGPT. Según el vídeo de anuncio, RFT es el método que OpenAI utiliza internamente para entrenar sus modelos de frontera como GPT-4o o o1 modo pro.
El aprendizaje por refuerzo ya se ha integrado antes en el ajuste fino de los LLM, pero el ajuste fino por refuerzo de OpenAI parece llevarlo a un nivel superior.
Aunque aún no se ha revelado la mecánica exacta de la RFT, ni su fecha de lanzamiento, ni una evaluación científica de su eficacia, podemos cruzar los dedos y esperar que la RFT sea accesible pronto y tan potente como promete.
Aprende IA con estos cursos
programa
programa
Curso
Tutorial
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan


