
Cursus
Développer des applications d'IA
21 h
Le réglage fin par renforcement (RFT) est une technique permettant d'affiner les connaissances de grands modèles de langage par le biais d'une boucle d'apprentissage axée sur la récompense.
Les modèles frontières sont de remarquables modèles linguistiques à usage général. Les meilleurs d'entre eux excellent dans un large éventail de tâches, telles que la traduction, l'assistance, la programmation, etc. Cependant, un domaine important de la recherche en cours se concentre sur l'affinement ces modèles de manière efficace. L'objectif est de les adapter pour qu'ils adoptent des tons et des styles spécifiques ou qu'ils se spécialisent dans des domaines précis, comme la fourniture d'avis médicaux spécialisés ou l'exécution de tâches de classification spécifiques à un domaine.
Le défi consiste à réaliser ce réglage fin de manière efficace. L'efficacité consiste à consommer moins de puissance de calcul et à nécessiter moins d'ensembles de données étiquetées, tout en obtenant des résultats de haute qualité. C'est là que la RFT entre en jeu, offrant une solution prometteuse à ce problème.
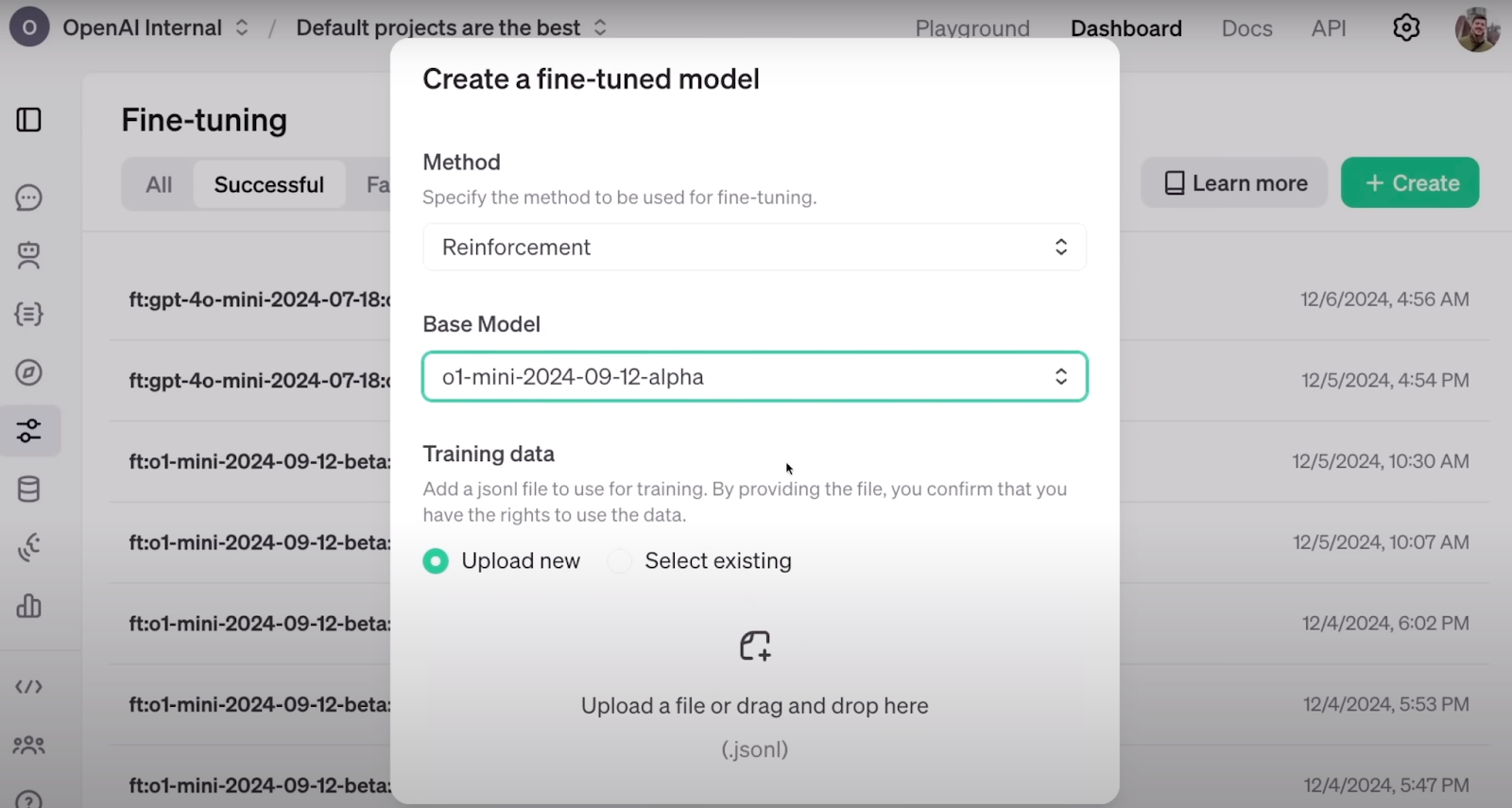
Voici à quoi ressemble la configuration de RFT sur le tableau de bord d'OpenAI. Source : OpenAI
Selon l'annonce d'OpenAI d'OpenAIla RFT permet d'affiner efficacement un modèle avec seulement quelques dizaines d'exemples. Dans de nombreux domaines, tels que le secteur médical, où les données sont rares et coûteuses, la réduction du nombre de données permet d'aller plus loin.
Le RFT s'appuie sur l'épine dorsale de l'apprentissage par renforcement. l'apprentissage par renforcement (RL), où les agents sont récompensés positivement ou négativement en fonction de leurs actions, ce qui leur permet de s'aligner sur le comportement que nous attendons d'eux. Pour ce faire, une note est attribuée à la production de l'agent. Grâce à une formation itérative basée sur ces scores, les agents apprennent sans avoir besoin de comprendre explicitement les règles ou de mémoriser des étapes prédéfinies pour résoudre le problème.
Combiné aux efforts d'amélioration des LLM sur des tâches spécialisées, le RFT émerge des techniques de RL et de réglage fin. L'idée est de réaliser la RFT en suivant une série d'étapes :
1. Fournissez un ensemble de données structuré et étiqueté qui fournit au modèle les connaissances que vous souhaitez qu'il apprenne. Comme pour une tâche typique d'apprentissage automatique, cet ensemble de données doit être divisé en un ensemble de formation et un ensemble de validation.
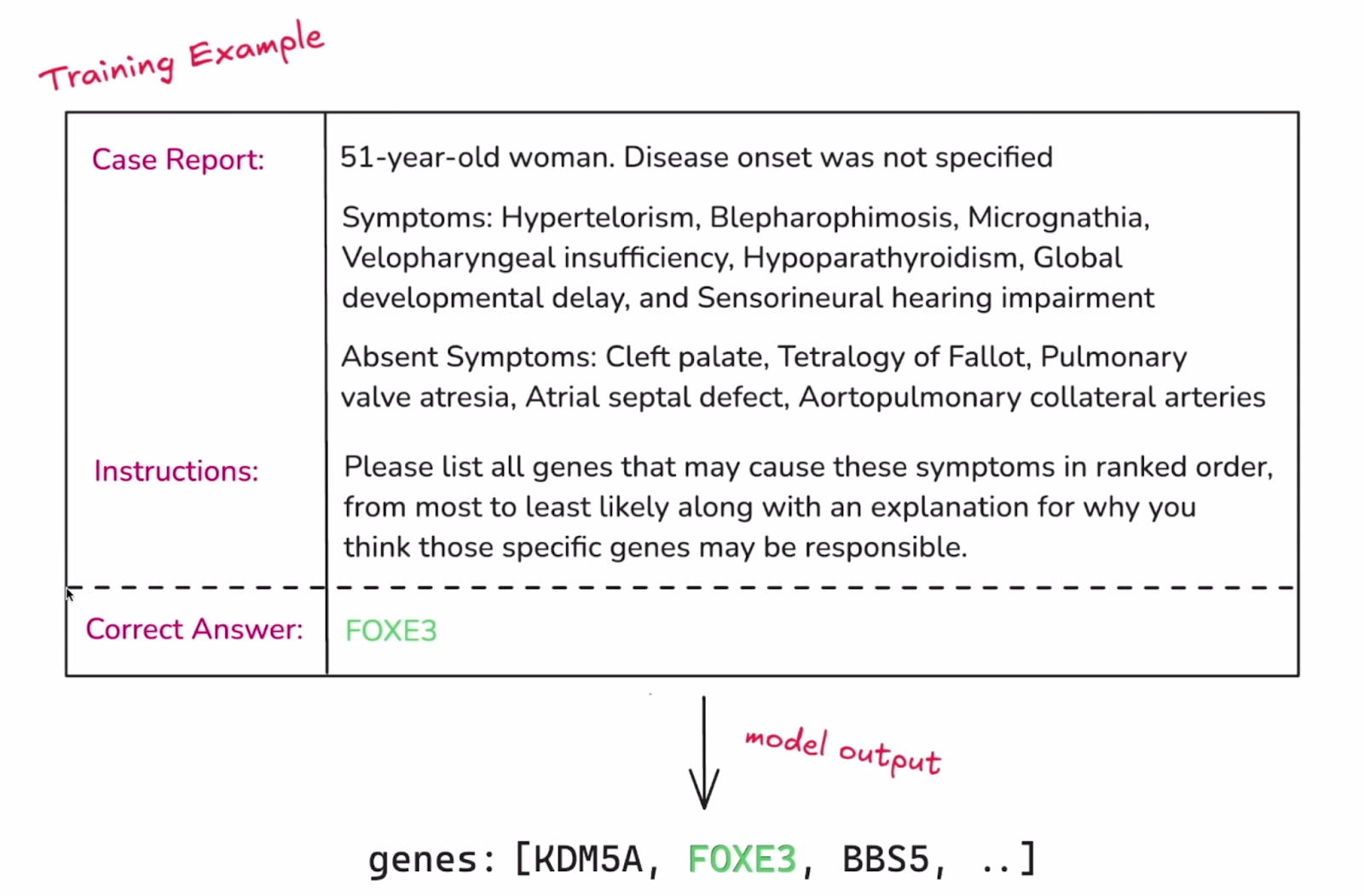
Exemple d'une instance unique de l'ensemble de données. Source : OpenAI
2. L'élément critique suivant de la RFT est la mise en place d'une méthode d'évaluation des résultats du modèle. Dans un processus de réglage fin typique, le modèle tente simplement de reproduire la réponse cible étiquetée. En revanche, dans le cadre de la RFT, le modèle doit développer un processus de raisonnement qui conduit à ces réponses. Le classement des résultats du modèle est ce qui le guide lors de l'affinage, et il est effectué à l'aide du site "Graders". La note peut aller de 0 à 1 ou se situer entre les deux, et il existe de nombreuses façons d'attribuer une note à l'ensemble des résultats d'un modèle. OpenAI a annoncé son intention de déployer d'autres évaluateurs et d'introduire éventuellement un moyen pour les utilisateurs de mettre en œuvre leurs propres évaluateurs personnalisés.
3. Une fois que le modèle a répondu aux données de l'ensemble d'apprentissage, sa sortie est notée par le correcteur. Ce score sert de signal de "récompense". Les poids et les paramètres du modèle sont ensuite modifiés pour maximiser les récompenses futures.
4. Le modèle est affiné par des étapes répétées. À chaque cycle, le modèle affine sa stratégie et l'ensemble de validation (séparé de l'apprentissage) est utilisé périodiquement pour vérifier si ces améliorations se généralisent à de nouveaux exemples. Lorsque les résultats du modèle s'améliorent sur les données de validation, c'est le signe que le modèle apprend réellement des stratégies significatives et ne se contente pas de mémoriser des solutions.
L'explication présentée ici reflète l'essence de la RFT, mais la mise en œuvre et les détails techniques peuvent différer.
Si l'on examine ci-dessous les résultats de l'évaluation de RFT, qui comparent un modèle o1-mini affiné à un modèle o1-mini et o1 standard, il est frappant de constater que RFT, en utilisant un ensemble de données de seulement 1 100 exemples, a obtenu une précision supérieure à celle du modèle o1-mini. modèle o1bien que ce dernier soit plus grand et plus avancé que le modèle o1-mini.
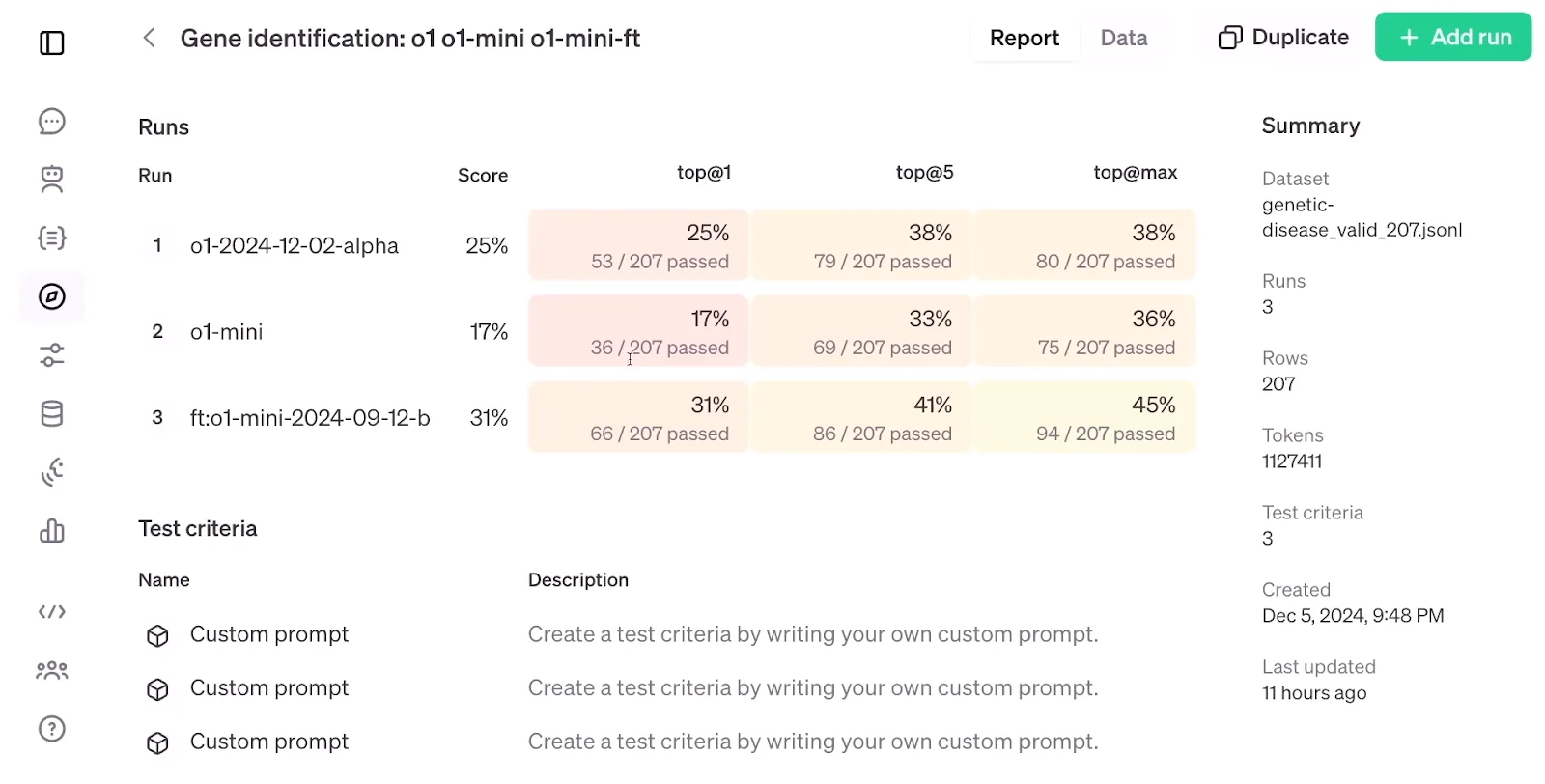
Évaluation de la RFT. Source : OpenAI
Le réglage fin supervisé (SFT) consiste à prendre un modèle pré-entraîné et à l'ajuster avec des données supplémentaires à l'aide de techniques d'apprentissage supervisé. Dans la pratique, SFT fonctionne mieux lorsque l'objectif est d'aligner la sortie ou le format du modèle sur un ensemble de données particulier ou de s'assurer que le modèle suit certaines instructions.
Si le réglage fin supervisé et le réglage fin par renforcement s'appuient tous deux sur des données étiquetées, ils les utilisent différemment. Dans le cadre du SFT, les données étiquetées déterminent directement les mises à jour du modèle. Le modèle considère qu'il s'agit de la sortie cible et ajuste ses paramètres pour réduire la différence entre sa sortie prédite et la réponse correcte connue.
Dans le cadre de la RFT, l'exposition du modèle à l'étiquette est indirecte, puisqu'elle est principalement utilisée pour créer le signal de récompense plutôt qu'une cible directe. C'est la raison pour laquelle le modèle devrait nécessiter moins de données étiquetées dans le cadre de la RFT - le modèle vise à trouver des modèles pour produire les résultats que nous souhaitons plutôt que de viser directement à produire nos résultats, ce qui promet une plus grande tendance à lagénéralisation à l'adresse .
Résumons les différences àl'aide de ce tableau :
|
Fonctionnalité |
Réglage fin supervisé (SFT) |
Mise au point du renforcement (RFT) |
|
Idée maîtresse |
Entraînez directement le modèle sur des données étiquetées afin qu'il corresponde au résultat souhaité. |
Utilisez un "grader" pour récompenser le modèle lorsqu'il produit les résultats souhaités. |
|
Utilisation de l'étiquette |
Cible directe que le modèle doit imiter. |
Utilisé indirectement pour créer un signal de récompense pour le modèle. |
|
Efficacité des données |
Nécessite plus de données étiquetées. |
Requiert potentiellement moins de données étiquetées en raison de la généralisation. |
|
L'implication de l'homme |
Uniquement lors de l'étiquetage des données initiales. |
Uniquement lors de la conception de la fonction "Grader". |
|
Généralisation |
Peut s'adapter de manière excessive aux données d'apprentissage, ce qui limite la généralisation. |
Potentiel de généralisation plus élevé en raison de l'accent mis sur les modèles et les récompenses. |
|
Alignement sur les préférences humaines |
Limitée, car elle repose uniquement sur l'imitation des données étiquetées. |
L'alignement peut être amélioré si le "grader" reflète fidèlement les préférences humaines. |
|
Exemples |
Affiner un modèle linguistique pour générer des types spécifiques de formats de texte (comme des poèmes ou du code). |
Entraînement d'un modèle linguistique pour générer un contenu créatif jugé par un "grader" sur la base de l'originalité et de la cohérence. |
En lisant sur la RFT, je n'ai pas pu m'empêcher de penser à une autre technique efficace et classique appelée l'apprentissage par renforcement à partir du feedback humain (RLHF). Dans le cadre de la RLHF, des annotateurs humains fournissent un retour d'information sur la manière de répondre aux invites, et un modèle de récompense est formé pour convertir ce retour d'information en signaux de récompense numériques. Ces signaux sont ensuite utilisés pour affiner les paramètres du modèle pré-entraîné par le biais d'une l'optimisation proximale de la politique (PPO).
Alors que la RFT retire le feedback humain de la boucle et s'appuie sur le Grader pour attribuer le signal de récompense à la réponse du modèle, l'idée d'intégrer l'apprentissage par renforcement dans le réglage fin du LLM est toujours cohérente avec celle de la RLHF.
Il est intéressant de noter que la méthode RLHF a été utilisée précédemment pour mieux aligner le modèle dans le processus de formation du ChatGPT. Selon la vidéo d'annonce, RFT est la méthode qu'OpenAI utilise en interne pour entraîner ses modèles de frontière tels que GPT-4o ou o1 pro mode.
L'apprentissage par renforcement a déjà été intégré dans le réglage fin des LLM, mais le réglage fin par renforcement de l'OpenAI semble aller plus loin.
Bien que les mécanismes exacts de la RFT, sa date de lancement et l'évaluation scientifique de son efficacité n'aient pas encore été divulgués, nous pouvons croiser les doigts et espérer que la RFT sera bientôt accessible et qu'elle sera aussi puissante que promis.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours