
Track
Developing AI Applications
21 hr
Reinforcement fine-tuning (RFT) is a technique for refining the knowledge of large language models through a reward-driven training loop.
Frontier models are remarkable general-purpose language models. The best of them excel at a wide range of tasks, such as translation, assistance, programming, and more. However, a significant area of ongoing research focuses on fine-tuning these models efficiently. The goal is to adapt them to take on specific tones and styles or to specialize in narrow fields, such as providing expert medical advice or performing domain-specific classification tasks.
The challenge lies in achieving this fine-tuning efficiently. Efficiency means consuming less computational power and requiring fewer labeled datasets while still achieving high-quality results. This is where RFT comes into play, offering a promising solution to this problem.
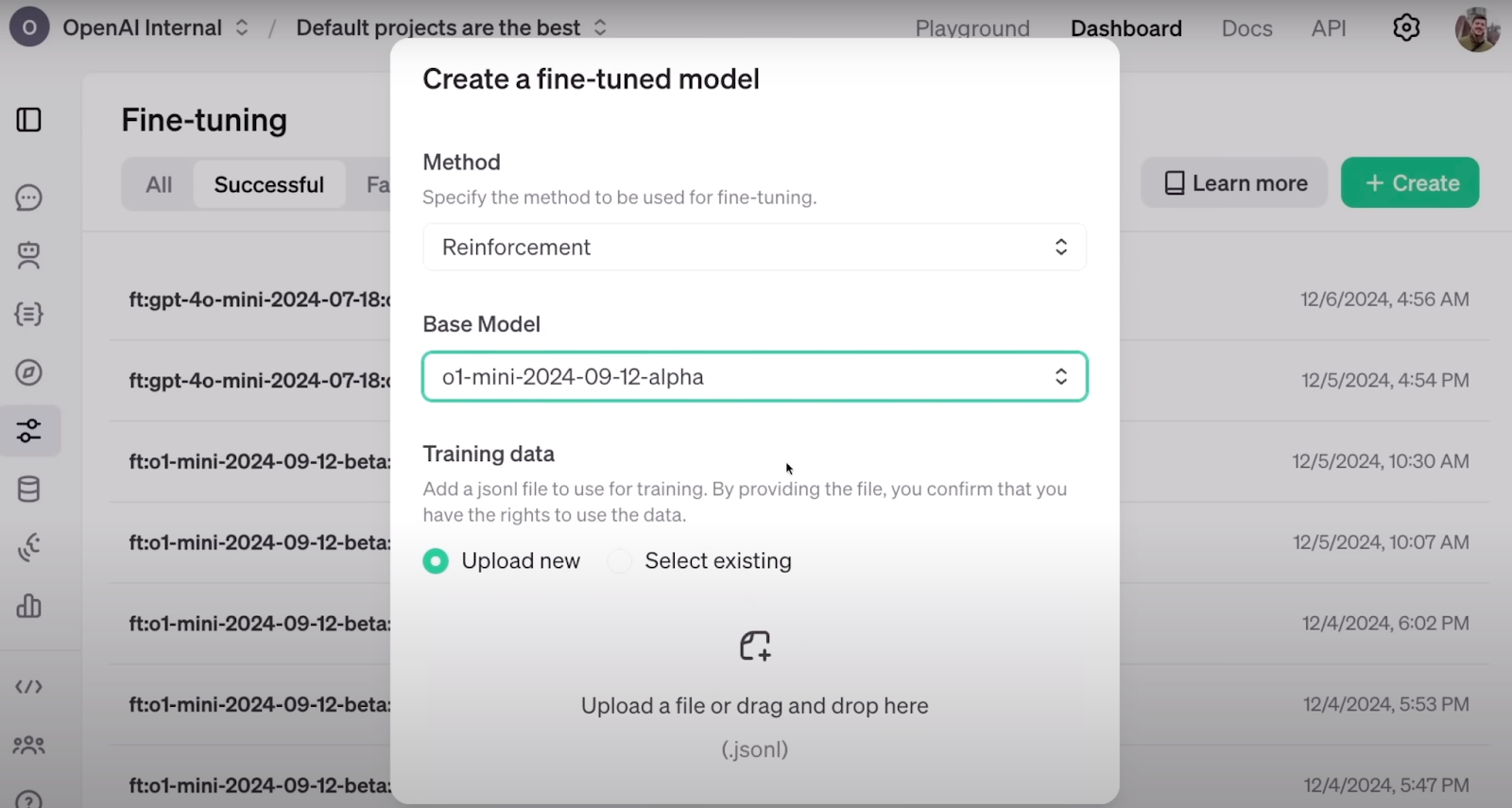
This is how configuring RFT looks like on OpenAI’s dashboard. Source: OpenAI
According to OpenAI’s announcement, RFT can effectively fine-tune a model with just a few dozen examples. In many fields, such as the medical sector, where data is scarce and costly, less data goes a long way.
RFT is built on the backbone of reinforcement learning (RL), where agents are rewarded positively or negatively based on their actions, enabling them to align with the behavior we expect of them. This is achieved by assigning a score to the agent’s output. Through iterative training based on these scores, agents learn without needing to explicitly understand the rules or memorize predefined steps for solving the problem.
When combined with efforts to improve LLMs on specialized tasks, RFT emerges out of RL and fine-tuning techniques. The idea is to perform RFT through a set of steps:
1. Provide a labeled structured dataset that equips the model with the knowledge you want it to learn. Like a typical machine learning task, this dataset should be divided into a training and a validation set.
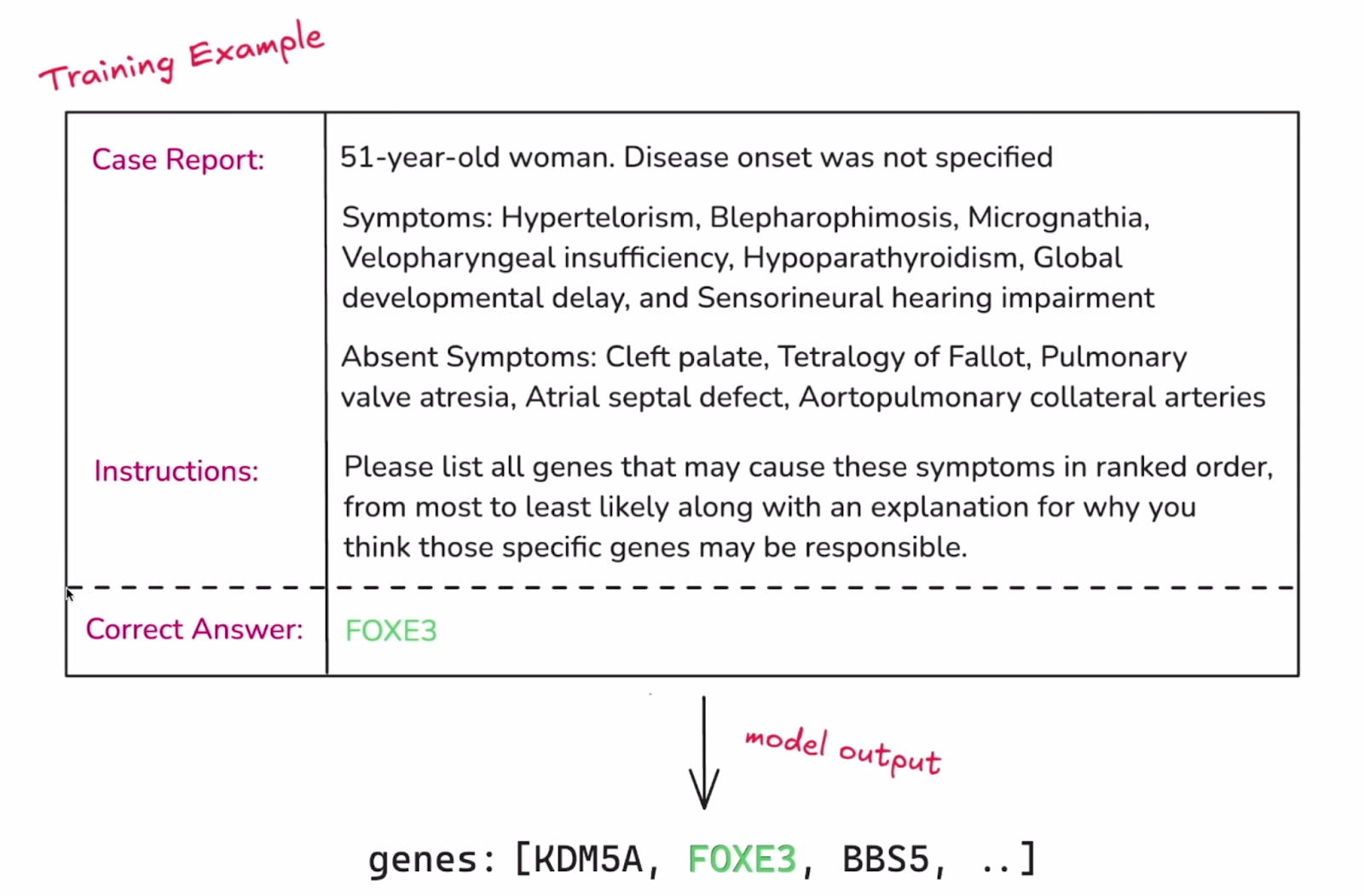
Example of a single instance of the dataset. Source: OpenAI
2. The next critical component of RFT is establishing a way to evaluate the model’s outputs. In a typical fine-tuning process, the model simply tries to reproduce the labeled target answer. In RFT, however, the model should develop a reasoning process that leads to those answers. The grading of the model’s outputs is what guides it during fine-tuning, and it’s done using the “Graders.” The grade can range from 0 to 1 or anywhere in between, and there are many ways to assign a grade to a model’s set of outputs. OpenAI announced plans to roll out more graders and possibly introduce a way for users to implement their own custom graders.
3. Once the model responds to the input from the training set, its output is scored by the grader. This score serves as the “reward” signal. The weights and parameters of the model are then nudged to maximize future rewards.
4. The model is fine-tuned through repeated steps. With each cycle, the model refines its strategy and the validation set (kept separate from training) is used periodically to check how well these improvements generalize to new examples. When the model’s scores improve on the validation data, it’s a good sign that the model is truly learning meaningful strategies and not simply memorizing solutions.
This explanation captures the essence of RFT, but the implementation and technical details may differ.
Looking below at the evaluation results of RFT, which compare a fine-tuned o1-mini model with a standard o1-mini and o1 model, it’s striking that RFT, using a dataset of just 1,100 examples, achieved higher accuracy than the o1 model, despite the latter being larger and more advanced than the o1-mini.
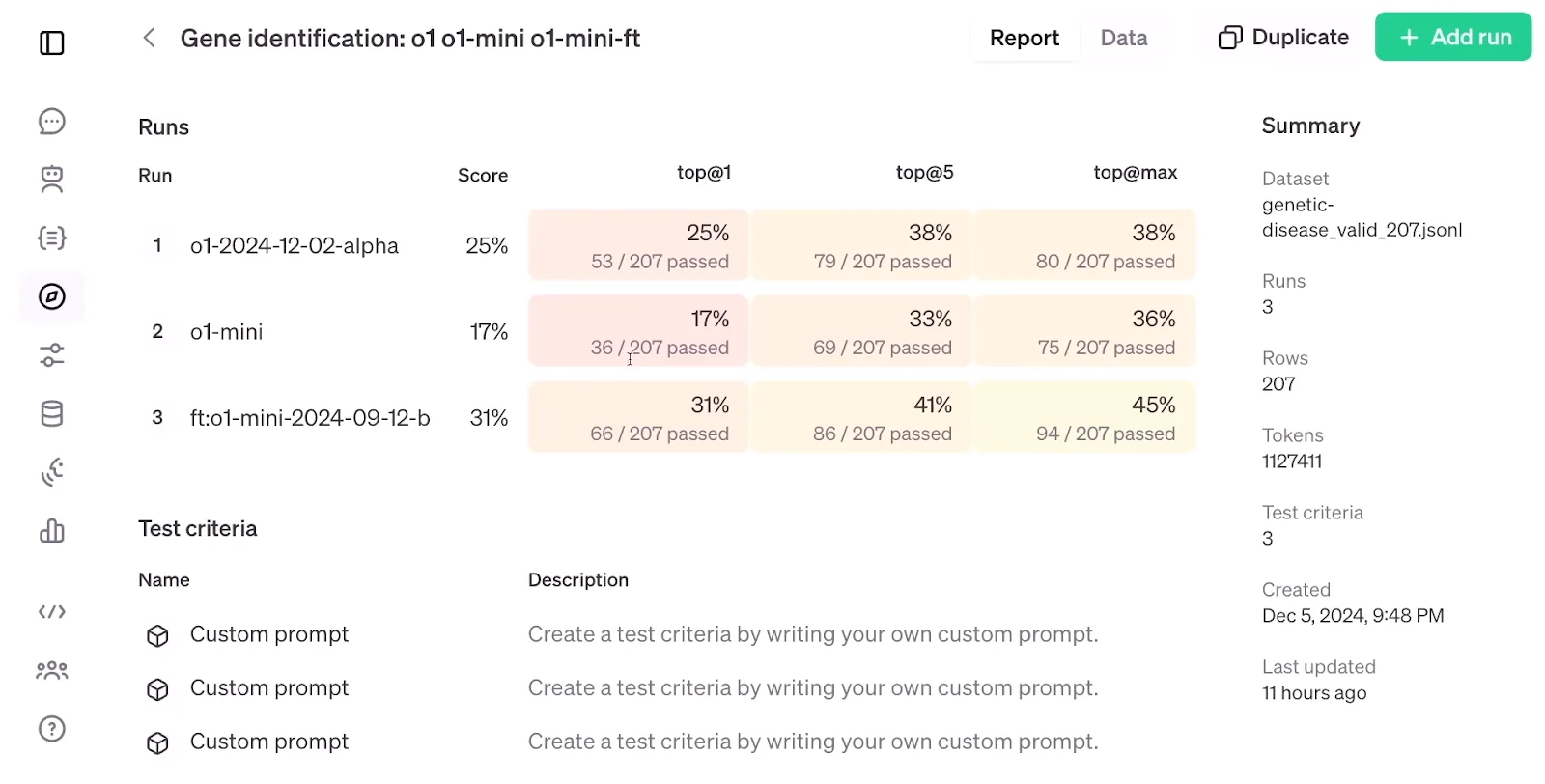
Evaluation of the RFT. Source: OpenAI
Supervised fine-tuning (SFT) involves taking a pre-trained model and adjusting it with additional data using supervised learning techniques. In practice, SFT works best when the goal is to align the model’s output or format to a particular dataset or to make sure the model follows certain instructions.
While supervised fine-tuning and reinforcement fine-tuning both rely on labeled data, they use it differently. In SFT, the labeled data directly drives the model’s updates. The model sees it as the target output and adjusts its parameters to close down the difference between its predicted output and the known correct answer.
In RFT, the model’s exposure to the label is indirect, as it’s mainly used to create the rewards signal rather than a direct target. This is why the model is expected to require fewer labeled data in RFT—the model aims to find patterns to produce the output we want rather than directly aiming to produce our outputs, and this promises more tendency to generalize.
Let’s summarize the differences with this table:
|
Feature |
Supervised Fine-Tuning (SFT) |
Reinforcement Fine-Tuning (RFT) |
|
Core Idea |
Directly train the model on labeled data to match desired output. |
Use a "Grader" to provide rewards to the model for generating desired output. |
|
Label Usage |
Direct target for the model to mimic. |
Indirectly used to create a reward signal for the model. |
|
Data Efficiency |
Requires more labeled data. |
Potentially requires less labeled data due to generalization. |
|
Human Involvement |
Only in initial data labeling. |
Only in designing the "Grader" function. |
|
Generalization |
Can overfit to the training data, limiting generalization. |
Higher potential for generalization due to focus on patterns and rewards. |
|
Alignment with Human Preferences |
Limited, as it relies solely on imitating the labeled data. |
Can be better aligned if the "Grader" accurately reflects human preferences. |
|
Examples |
Fine-tuning a language model to generate specific types of text formats (like poems or code). |
Training a language model to generate creative content that is judged by a "Grader" based on originality and coherence. |
When reading about RFT, I couldn’t help but think of another effective and classic technique called reinforcement learning from human feedback (RLHF). In RLHF, human annotators provide feedback on how to respond to prompts, and a reward model is trained to convert this feedback into numerical reward signals. These signals are then used to fine-tune the parameters of the pre-trained model through proximal policy optimization (PPO).
While RFT takes human feedback out of the loop and relies on the Grader to assign the reward signal to the model’s response, the idea of integrating reinforcement learning into the fine-tuning of the LLM is still consistent with that of RLHF.
Interestingly, RLHF was the method they used previously to better align the model in the ChatGPT training process. According to the announcement video, RFT is the method OpenAI uses internally to train their frontier models like GPT-4o or o1 pro mode.
Reinforcement learning has been integrated into the fine-tuning of the LLMs before, but OpenAI’s reinforcement fine-tuning seems to take that to a higher level.
While the exact mechanics of RFT, its release date, and a scientific evaluation of its effectiveness are yet to be disclosed, we can cross our fingers and hope that RFT will be accessible soon and as powerful as promised.
Learn AI with these courses!
Track
Track
Course
blog
Javier Canales Luna
8 min
blog
Javier Canales Luna
7 min
blog
Ryan Ong
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
code-along
Zoumana Keita



