programa
Científico especializado en machine learning en Python
85 h
Como usuario habitual de modelos avanzados como el ChatGPT de OpenAI y el Claude de Anthropic, he observado de primera mano cómo su rendimiento disminuye a medida que aumenta la longitud de las entradas, lo que provoca problemas para mantener la coherencia y la relevancia en textos extensos.
Para hacer frente a estas limitaciones, investigadores de Microsoft y de la Universidad de Illinois introducen SAMBA-una novedosa arquitectura híbrida que combina los modelos de espacio de estados (SSM) con la atención de ventana deslizante (SWA).
Su enfoque aprovecha los puntos fuertes tanto de los SSM, que son excelentes para gestionar las dependencias a largo plazo, como de los SWA, que manejan las ventanas de contexto y mantienen la tractabilidad computacional. Al fusionar estas técnicas, SAMBA consigue un modelado lingüístico eficaz con unalongitud de contexto prácticamente ilimitada.
En este artículo, exploraremos la arquitectura de SAMBA y su capacidad única para manejar grandes extensiones de texto sin perder el contexto. También destacamos su potencial para mejorar significativamente las capacidades de los modelos lingüísticos en el procesamiento y la generación de secuencias ampliadas, estableciendo un nuevo estándar en el modelado lingüístico.
Para entender por qué SAMBA es tan innovador, primero tenemos que comprender los retos a los que se enfrentan los modelos lingüísticos tradicionales cuando tratan secuencias de texto largas.
Tradicional Modelos basados en transformadoresaunque son inmensamente potentes, se enfrentan a importantes retos cuando tratan secuencias de texto largas, debido a su complejidad cuadrática en relación con la longitud del contexto. Esta complejidad cuadrática surge del mecanismo de autoatenciónque requiere que cada ficha atienda a todas las demás fichas de la secuencia.
Como resultado, los costes computacionales y de memoria crecen rápidamente al aumentar la longitud de la secuencia, lo que hace que estos modelos sean poco prácticos para tareas que requieran el procesamiento de textos muy largos.
Esta limitación nos obliga a menudo a truncar las entradas o a utilizar otras estrategias subóptimas para ajustarnos a las restricciones del hardware disponible. En última instancia, este compromiso reduce la capacidad del modelo para mantener el rendimiento en secuencias largas, un reto que me encontré al desarrollar una aplicación que necesita procesar documentos largos.
Los Modelos de Espacio de Estados (MES) ofrecen una alternativa con complejidad lineal, lo que los hace más eficientes computacionalmente para manejar secuencias largas. Los SSM mantienen un estado evolutivo, lo que les permite manejar dependencias ampliadas sin el coste prohibitivo de los transformadores.
Sin embargo, los SSM tienen sus limitaciones. Debido a su naturaleza markoviana, en la que el estado actual sólo depende del estado anterior, suelen tener dificultades para recordar secuencias largas. Esta memoria limitada reduce su eficacia en el modelado contextual exhaustivo, sobre todo en aplicaciones que requieren la retención y referencia de información de fases muy anteriores de la secuencia.
Dados los puntos fuertes y débiles tanto de los Transformadores como de los SSM, existe una necesidad imperiosa de enfoques híbridos que puedan aprovechar las ventajas de cada uno y, al mismo tiempo, mitigar sus limitaciones. Combinar los SSM con mecanismos de atención presenta una solución prometedora.
Este enfoque híbrido utiliza las propiedades de eficacia y dependencia de largo alcance de los SSM junto con el mecanismo de atención dinámica y focalizada de los Transformadores. Integrando estos dos métodos, podemos crear un modelo que procese suavemente las secuencias largas con un recuerdo y una comprensión contextual mejorados.
SAMBA ofrece una solución elegante a este cuello de botella contextual, combinando los puntos fuertes de dos enfoques distintos.
La idea central de SAMBA es intercalar Mambaun SSM, con SwiGLU y capas de atención de ventana deslizante (SWA). Esta estructura híbrida capta tanto las estructuras recurrentes como la recuperación precisa de la memoria.
SAMBA ejemplifica este enfoque combinando los puntos fuertes de los SSM y los mecanismos de atención para gestionar contextos largos conservando información detallada.
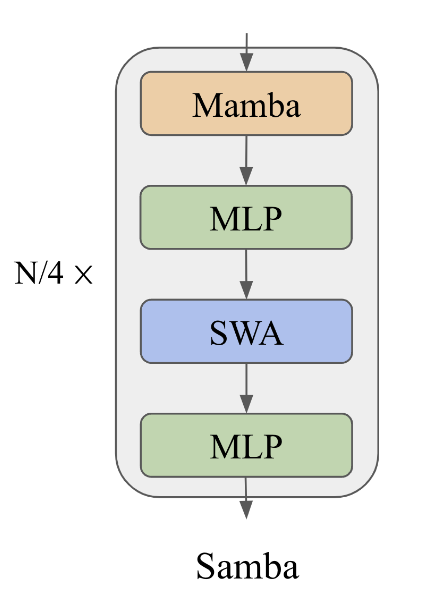
Un diagrama que ilustra la arquitectura SAMBA. Fuente: Ren et. al (2024)
Las capas Mamba de SAMBA son expertas en captar la semántica dependiente del tiempo, proporcionando un marco robusto para manejar datos secuenciales. Estas capas funcionan manteniendo y actualizando un estado que refleja las dependencias temporales de los datos.
Mamba lo consigue utilizando espacios de estado selectivos que permiten al modelo centrarse en las entradas relevantes y mantener la información importante durante secuencias largas. Este mecanismo de compuerta selectiva es crucial para una descodificación rápida y garantiza que el modelo pueda interpretar y predecir patrones secuenciales con gran precisión y una sobrecarga computacional mínima.
Las capas de atención de ventana deslizante complementan a las capas Mamba abordando las dependencias complejas no markovianas dentro de una ventana de contexto limitada. SWA funciona con un tamaño de ventana que se desliza sobre la secuencia de entrada, garantizando una complejidad computacional lineal.
Esto permite al modelo recuperar señales de alta definición de la historia a medio y corto plazo que no pueden ser captadas por los estados recurrentes de Mamba. Al ajustar dinámicamente su enfoque, las capas SWA permiten al modelo mantener la coherencia y el contexto, sobre todo en tareas que requieren respuestas contextualmente relevantes a lo largo de entradas largas.
Las capas SwiGLU de SAMBA facilitan la transformación no lineal y mejoran la recuperación de conocimientos. Estas capas introducen la no linealidad en el modelo, permitiéndole captar pautas e interacciones más complejas dentro de los datos.
Además, las capas SwiGLU garantizan que el modelo pueda procesar y recuperar información, lo que contribuye a su robustez y versatilidad. Esta transformación no lineal es esencial para que el modelo pueda generalizar de los datos de entrenamiento a las aplicaciones del mundo real.
Una vez explorada la arquitectura de SAMBA, examinemos ahora su rendimiento y eficacia en comparación con otros modelos.
SAMBA demuestra un buen rendimiento en una serie de pruebas de comprensión y razonamiento lingüísticos, superando tanto a los modelos basados en la atención pura como a los basados en SSM. En concreto, SAMBA ha sido evaluado en tareas como MMLU, GSM8K y HumanEval, obteniendo una puntuación de 71,2 en MMLU, 69,6 en GSM8K y 54,9 en HumanEval.
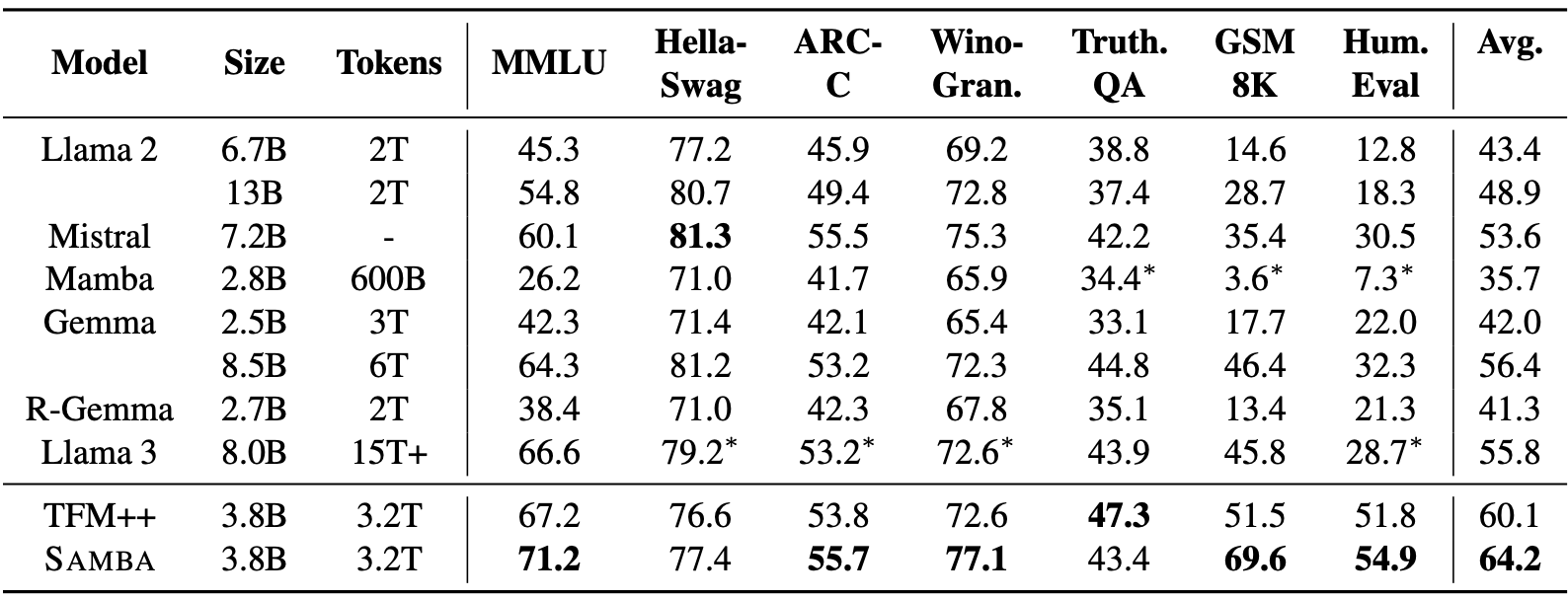
Fuente: Ren et. al (2024)
Estos resultados superan significativamente los de otros modelos del estado de la técnica, como TFM++ y Llama-3, lo que demuestra la capacidad de SAMBA para manejar diversas tareas de comprensión lingüística. Por ejemplo, SAMBA consiguió un 18,1% más de precisión en GSM8K en comparación con TFM++, lo que pone de relieve la competencia de su arquitectura híbrida que combina SSM con mecanismos de atención.
Una de las características más notables de SAMBA es su capacidad para manejar longitudes de contexto significativamente mayores, manteniendo la eficiencia. A pesar de estar preentrenado en secuencias de 4K de longitud, SAMBA puede extrapolar hasta 1M de tokens con una perplejidad mejorada y seguir manteniendo una complejidad de tiempo de descodificación lineal.
Esto se consigue mediante la combinación por capas de los espacios de estado selectivos de Mamba con SWA, lo que permite al modelo mantener un alto rendimiento sin una complejidad de cálculo cuadrática.
En la práctica, SAMBA consigue un rendimiento de descodificación 3,64 veces más rápido que la arquitectura Llama-3, en particular para secuencias de hasta 128K tokens de longitud, lo que demuestra su escalabilidad y capacidad para procesar contextos largos..
La arquitectura híbrida de SAMBA amplía significativamente su capacidad de recuperación de memoria en comparación con los SSM puros. En pruebas como la Recuperación de Claves de Acceso, SAMBA mostró una recuperación de memoria casi perfecta hasta una longitud de contexto de 256K tras un ajuste fino con sólo 500 pasos, mientras que los modelos basados en SWA tuvieron problemas más allá de longitudes de 4K.
Este rendimiento excepcional se atribuye a la fuerza combinada de las estructuras recurrentes de Mamba para la semántica dependiente del tiempo y la capacidad de recuperación de memoria de SWA. En consecuencia, SAMBA destaca en tareas de recuerdo a corto y largo plazo, lo que lo convierte en una solución sólida para aplicaciones que requieren una amplia comprensión del contexto.
Echemos un vistazo más de cerca a las opciones y estrategias de diseño específicas que contribuyen al impresionante rendimiento de SAMBA.
SAMBA emplea una sofisticada estrategia de hibridación que combina capas Mamba, SWA y Perceptrón Multicapa (MLP). Este enfoque optimiza el rendimiento del modelado lingüístico de contexto largo aprovechando las propiedades únicas de cada componente:
El documento SAMBA explora varios modelos recurrentes lineales y mecanismos de atención para identificar la combinación más óptima. Alternativas como la Retención Multiescala y la GLA se consideraron posibles sustitutos de la Mamba. Puedes encontrar más información sobre la arquitectura Mamba en esta introducción a la guía de arquitectura Mamba LLM.
Estas exploraciones pretendían equilibrar la eficiencia computacional y el rendimiento en las tareas de modelado lingüístico. La comparación reveló que, aunque estas alternativas ofrecían algunas ventajas, la combinación de Mamba con capas SWA y MLP conseguía el mejor rendimiento global y escalabilidad.
El análisis de la entropía de las distribuciones de la atención permitió obtener valiosos conocimientos sobre el rendimiento de SAMBA y de modelos comparables como Mistral. El análisis de la entropía de la atención reveló que SAMBA mantiene un recuerdo más estable y fiable en contextos prolongados.
Por ejemplo, en la tarea de recuperación de claves de acceso, SAMBA demostró una recuperación casi perfecta hasta longitudes de contexto de 256K, superando significativamente a Mistral. El análisis del mapa de calor indicó que la arquitectura híbrida de SAMBA le permite mantener una alta precisión de recuperación en varias posiciones de clave de paso, lo que subraya su excepcional capacidad de recuperación de largo alcance.
Dada su capacidad para procesar eficazmente secuencias largas, SAMBA abre un amplio abanico de aplicaciones potenciales.
La capacidad de SAMBA para manejar una longitud de contexto ilimitada abre importantes posibilidades para diversas tareas de contexto largo. Es capaz de mantener la coherencia y la relevancia a lo largo de extensas secuencias, lo que la hace especialmente adecuada para aplicaciones como:
La arquitectura de SAMBA se ha diseñado pensando en la eficiencia, abordando las limitaciones típicas de los modelos basados en la atención pura y los basados en SSM. Algunas ventajas clave son:
De cara al futuro, hay varias vías de trabajo interesantes que pueden desarrollar aún más las capacidades de SAMBA:
SAMBA representa un avance significativo en el modelado del lenguaje, ya que ofrece una novedosa arquitectura híbrida que combina SSM con SWA deslizante y capas MLP. Las innovaciones y ventajas clave de la arquitectura SAMBA incluyen la hibridación de los mecanismos SSM y de atención, la eficacia en el manejo de contextos largos y la mejora de la recuperación de la memoria.
Aunque con esto hemos concluido nuestra exploración de la arquitectura SAMBA, una buena forma de profundizar en la arquitectura SAMBA y sus innovaciones es experimentar con la aplicación disponible en GitHub.
Si quieres saber más sobre las últimas innovaciones en IA, te recomiendo estas entradas de blog:
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan


