
Track
Machine Learning Scientist in Python
85 hr
As someone who regularly uses advanced models like OpenAI’s ChatGPT and Anthropic's Claude, I’ve observed firsthand how their performance degrades as input prompt lengths increase, leading to issues in maintaining coherence and relevance over extended texts.
To address these limitations, researchers at Microsoft and the University of Illinois introduce SAMBA—a novel hybrid architecture that combines state space models (SSMs) with sliding window attention (SWA).
Their approach leverages the strengths of both SSMs, which are excellent at managing long-term dependencies, and SWA, which handles context windows and maintains computational tractability. By merging these techniques, SAMBA achieves efficient language modeling with practically unlimited context length.
In this article, we’ll explore SAMBA's architecture and its unique ability to handle long text spans without losing context. We also highlight its potential to significantly enhance the capabilities of language models in processing and generating extended sequences, setting a new standard in language modeling.
To understand why SAMBA is so innovative, we first need to understand the challenges traditional language models face when dealing with long text sequences.
Traditional Transformer-based models, while immensely powerful, face significant challenges when dealing with long text sequences due to their quadratic complexity concerning context length. This quadratic complexity arises from the self-attention mechanism, which requires each token to attend to every other token in the sequence.
As a result, the computational and memory costs grow rapidly with increasing sequence length, making these models impractical for tasks requiring the processing of very long texts.
This limitation often forces us to truncate inputs or use other suboptimal strategies to fit the constraints of available hardware. Ultimately, this compromise reduces the model's ability to maintain performance over extended sequences, a challenge I encountered when developing an application that needs to process lengthy documents.
State Space Models (SSMs) offer an alternative with linear complexity, making them more computationally efficient for handling long sequences. SSMs maintain an evolving state, allowing them to handle extended dependencies without the prohibitive cost of transformers.
However, SSMs have their limitations. Due to their Markovian nature, where the current state is dependent only on the previous state, they often struggle with memory recall over long sequences. This limited memory recall reduces their effectiveness in comprehensive context modeling, particularly in applications that require the retention and reference of information from much earlier in the sequence.
Given the strengths and weaknesses of both Transformers and SSMs, there’s a compelling need for hybrid approaches that can leverage the advantages of each while mitigating their limitations. Combining SSMs with attention mechanisms presents a promising solution.
This hybrid approach utilizes the efficiency and long-range dependency properties of SSMs alongside the dynamic and focused attention mechanism of Transformers. By integrating these two methods, we can create a model that smoothly processes long sequences with enhanced memory recall and contextual understanding.
SAMBA offers an elegant solution to this context bottleneck, combining the strengths of two distinct approaches.
The core idea behind SAMBA is to interleave Mamba, an SSM, with SwiGLU and sliding window attention (SWA) layers. This hybrid structure captures both recurrent structures and precise memory retrieval.
SAMBA exemplifies this approach by combining the strengths of SSMs and attention mechanisms to manage long contexts while retaining detailed information.
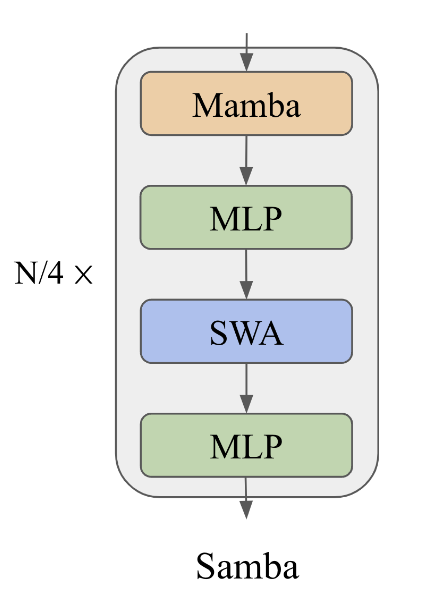
A diagram illustrating the SAMBA architecture. Source: Ren et. al (2024)
Mamba layers in SAMBA are adept at capturing time-dependent semantics, providing a robust framework for handling sequential data. These layers operate by maintaining and updating a state that reflects the temporal dependencies within the data.
Mamba achieves this by utilizing selective state spaces that allow the model to focus on relevant inputs and maintain important information over long sequences. This selective gating mechanism is crucial for fast decoding and ensures that the model can interpret and predict sequential patterns with high accuracy and minimal computational overhead.
Sliding window attention layers complement the Mamba layers by addressing complex, non-Markovian dependencies within a limited context window. SWA operates on a window size that slides over the input sequence, ensuring linear computational complexity.
This allows the model to retrieve high-definition signals from the middle to short-term history that cannot be captured by the recurrent states of Mamba. By dynamically adjusting its focus, SWA layers enable the model to maintain coherence and context, particularly for tasks requiring contextually relevant responses over long inputs.
SwiGLU layers in SAMBA facilitate non-linear transformation and enhance knowledge recall. These layers introduce non-linearity into the model, enabling it to capture more complex patterns and interactions within the data.
Furthermore, SwiGLU layers ensure the model can process and recall information, contributing to its robustness and versatility. This non-linear transformation is essential for the model's ability to generalize from training data to real-world applications.
Having explored the architecture of SAMBA, let's now examine its performance and efficiency compared to other models.
SAMBA demonstrates good performance across a variety of language understanding and reasoning benchmarks, outperforming both pure attention-based and SSM-based models. In particular, SAMBA has been evaluated on tasks such as MMLU, GSM8K, and HumanEval, achieving a 71.2 score for MMLU, 69.6 for GSM8K, and 54.9 for HumanEval.
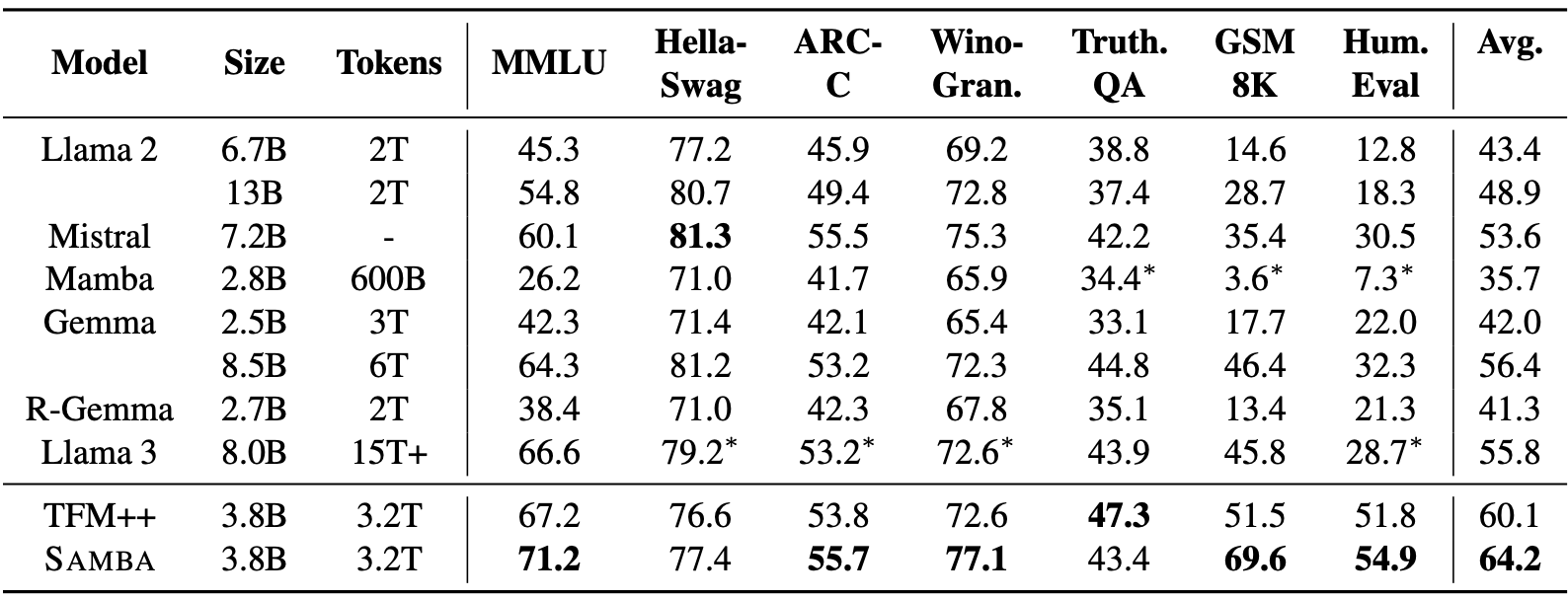
Source: Ren et. al (2024)
These results significantly surpass those of other state-of-the-art models, including TFM++ and Llama-3, showcasing SAMBA's ability to handle diverse language comprehension tasks. For instance, SAMBA achieved an 18.1% higher accuracy in GSM8K compared to TFM++, highlighting the proficiency of its hybrid architecture that combines SSM with attention mechanisms.
One of SAMBA's most notable features is its ability to handle significantly longer context lengths while maintaining efficiency. Despite being pre-trained on sequences of 4K length, SAMBA can extrapolate up to 1M tokens with improved perplexity and still maintain linear decoding time complexity.
This is achieved through the layer-wise combination of Mamba's selective state spaces with SWA, enabling the model to maintain high performance without quadratic computation complexity.
In practical terms, SAMBA achieves a 3.64X faster decoding throughput compared to the Llama-3 architecture, particularly for sequences up to 128K tokens in length, demonstrating its scalability and capability in processing long contexts.
SAMBA's hybrid architecture significantly amplifies its memory recall abilities compared to pure SSMs. In tests such as Passkey Retrieval, SAMBA showed nearly perfect memory recall up to 256K context length after fine-tuning with only 500 steps, while SWA-based models struggled beyond 4K lengths.
This exceptional performance is attributed to the combined strengths of Mamba's recurrent structures for time-dependent semantics and SWA's memory retrieval capabilities. Consequently, SAMBA excels in short-term and long-term memory recall tasks, making it a robust solution for applications that require extensive context understanding.
Let's take a closer look at the specific design choices and strategies that contribute to SAMBA's impressive performance.
SAMBA employs a sophisticated hybridization strategy that combines Mamba, SWA, and Multi-Layer Perceptron (MLP) layers. This approach optimizes performance for long-context language modeling by leveraging the unique properties of each component:
The SAMBA paper explores various linear recurrent models and attention mechanisms to identify the most optimal combination. Alternatives such as Multi-Scale Retention and GLA were considered potential substitutes for Mamba. You can find more information on the Mamba architecture in this introduction to the Mamba LLM architecture guide.
These explorations aimed to balance computational efficiency and performance in language modeling tasks. The comparison revealed that while these alternatives offered some benefits, the combination of Mamba with SWA and MLP layers achieved the best overall performance and scalability.
Analyzing the entropy of attention distributions led to valuable insights into the performance of SAMBA and comparable models like Mistral. The attention entropy analysis revealed that SAMBA maintains a more stable and reliable memory recall over extended contexts.
For instance, in the Passkey Retrieval task, SAMBA demonstrated near-perfect retrieval up to 256K context lengths, significantly outperforming Mistral. The heatmap analysis indicated that SAMBA's hybrid architecture allows it to maintain high retrieval accuracy across various pass-key positions, underscoring its exceptional long-range retrieval capabilities.
Given its ability to effectively process long sequences, SAMBA opens up a wide range of potential applications.
SAMBA's ability to handle unlimited context length opens up significant possibilities for various long-context tasks. It's able to maintain coherence and relevance over extensive sequences, which makes it particularly suitable for applications such as:
SAMBA’s architecture is designed with efficiency in mind, addressing the typical limitations of both pure attention-based and SSM-based models. Some key benefits include:
Looking ahead, several exciting avenues for future work can further develop SAMBA's capabilities:
SAMBA represents a significant advancement in language modeling, offering a novel hybrid architecture that combines SSMs with Sliding SWA and MLP layers. The key innovations and advantages of the SAMBA architecture include the hybridization of SSM and attention mechanisms, efficiency in handling long contexts, and enhanced memory recall.
While this wraps up our exploration of the SAMBA architecture, a great way to gain a deeper understanding of the SAMBA architecture and its innovations is by experimenting with the implementation available on GitHub.
If you want to learn more about the latest AI innovations, I recommend these blog posts:
Learn AI with these courses!
Track
Course
Course
blog
Zoumana Keita
13 min
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Ryan Ong
code-along
Rishit Dholakia

