Curso
Introducción a los LLMs en Python
3 h
33.8K
El campo de la Inteligencia Artificial (IA) está siendo testigo de una explosión de las capacidades de los Grandes Modelos Lingüísticos (LLM), que son cada vez más hábiles en tareas que requieren una comprensión y generación sofisticadas del lenguaje humano. A medida que estos modelos se hacen más potentes, se hace necesario disponer de métodos de evaluación sólidos.
Aquí es donde interviene el punto de referencia MMLU (Massive Multitask Language Understanding). Es una prueba exhaustiva y desafiante para los sistemas de IA más avanzados de hoy en día. La puntuación MMLU se ha convertido en un indicador clave del progreso de un modelo y en una fuerza impulsora en la búsqueda continua para construir máquinas más inteligentes.
Comprender el significado del MMLU y su función es importante para cualquiera que se dedique a la ciencia de datos o a la IA, ya que proporciona una forma estandarizada de medir el conocimiento general y las capacidades de razonamiento de estos modelos en un amplio arreglo de temas. Estas capacidades son fundamentales para el desarrollo de grandes modelos lingüísticos.
En este artículo analizaremos qué es la MMLU, qué implica el proceso de evaluación de la MMLU, cómo está estructurado el extenso conjunto de datos de la MMLU y por qué este punto de referencia es tan importante para el avance de la IA.
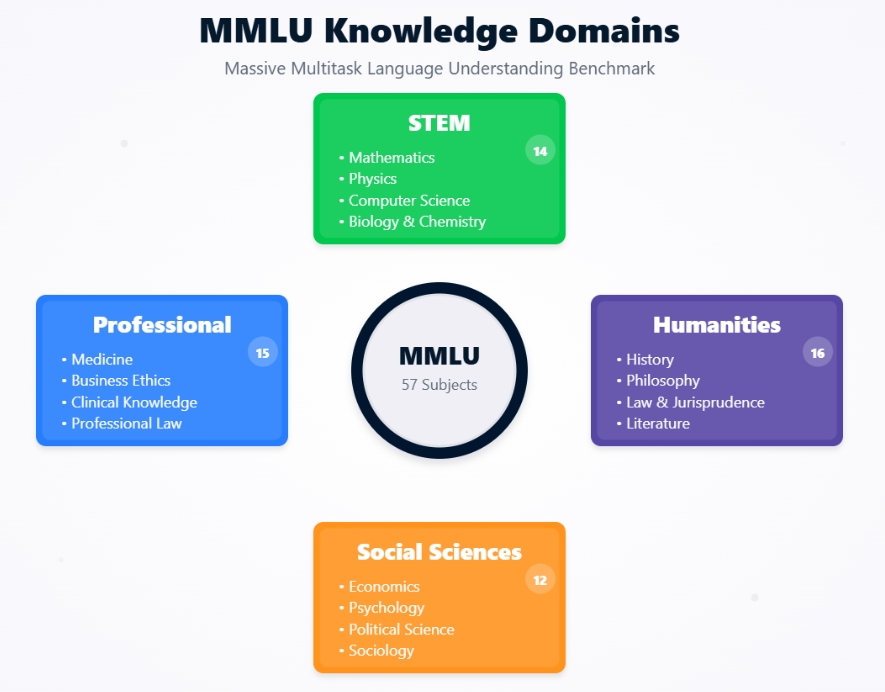
Massive Multitask Language Understanding (MMLU) es una prueba comparativa exhaustiva diseñada para evaluar los conocimientos y la capacidad de resolución de problemas de los grandes modelos lingüísticos (LLM) en una amplia y diversa gama de temas. Consta de preguntas de opción múltiple que abarcan 57 tareas diferentes, como matemáticas elementales, historia de EE.UU., informática, derecho y más.
La idea central de la prueba MMLU es poner a prueba los conocimientos adquiridos y las habilidades de razonamiento de un modelo en un entorno de cero o pocos disparos, lo que significa que el modelo debe responder a preguntas con pocos o ningún ejemplo específico de la tarea.
Este enfoque pretende medir lo bien que los modelos pueden comprender y aplicar los conocimientos de su fase de preentrenamiento a tareas para las que no han sido explícitamente afinados, lo que refleja una forma de inteligencia más general y robusta. El rendimiento de un modelo suele resumirse en su puntuación MMLU, que indica su precisión en estos dominios variados.
El marco de evaluación MMLU es profundamente significativo para la investigación y el desarrollo de la IA por varias razones clave, como:
Dominios de conocimiento MMLU
La aparición del MMLU se entiende mejor si se observa la evolución de la evaluación de modelos lingüísticos y las motivaciones que impulsaron su creación.
La MMLU fue introducida por Dan Hendrycks y un equipo de investigadores en su artículo de 2020, "Medición de la comprensión lingüística multitarea masiva". La principal motivación fue la observación de que los puntos de referencia existentes se estaban saturando por la rápida mejora de los LLM.
Los modelos alcanzaban un rendimiento casi humano o incluso sobrehumano en pruebas de referencia como GLUE y SuperGLUE, pero no siempre estaba claro si esto se traducía en una comprensión del mundo amplia y similar a la humana.
Los creadores del MMLU trataron de desarrollar un test más exigente y completo que pudiera:
El objetivo era crear una evaluación que pudiera diferenciar mejor las capacidades de los LLM cada vez más potentes y proporcionar un camino más claro hacia sistemas más inteligentes en general.
MMLU representa un paso importante en la evolución de los puntos de referencia para la comprensión del lenguaje natural (NLU).
Las primeras evaluaciones de NLU solían centrarse en tareas individuales como el análisis de sentimientos, el reconocimiento de entidades con nombre o la traducción automática, cada una con su propio conjunto de datos y métricas.
Introducido en 2018, GLUE (Evaluación General de la Comprensión del Lenguaje) era una colección de nueve tareas NLU diversas, diseñadas para proporcionar una métrica de un solo número para el rendimiento general del modelo. Se convirtió en un estándar durante un tiempo, pero pronto fue superado por otros modelos.
Desarrollado en 2019 como sucesor más desafiante de GLUE, SuperGLUE presentaba tareas más difíciles y una base humana más completa. Sin embargo, incluso SuperGLUE vio modelos que se acercaban rápidamente al rendimiento humano.
MMLU mejoró estos puntos de referencia anteriores en varios aspectos críticos. Con 57 tareas, el conjunto de datos MMLU es mucho más extenso y abarca una gama mucho más amplia de temas académicos y profesionales que GLUE (9 tareas) o SuperGLUE (8 tareas + un conjunto de datos de diagnóstico). Esta amplitud dificulta la especialización de los modelos y fomenta un conocimiento más general.
Mientras que GLUE/SuperGLUE evaluaban diversos fenómenos lingüísticos, MMLU evalúa directamente los conocimientos en ámbitos específicos como el derecho, la medicina y la ética, lo que requiere algo más que el mero procesamiento del lenguaje.
MMLU prioriza la evaluación de modelos con un mínimo de ejemplos específicos de la tarea. Esto contrasta con muchas tareas de GLUE/SuperGLUE, en las que los modelos a menudo se afinaban en conjuntos de entrenamiento específicos para cada tarea. Esto hace que la evaluación MMLU sea una mejor prueba de la capacidad de generalización de un modelo a partir de su preentrenamiento.
Las preguntas de la MMLU suelen estar diseñadas para que supongan un reto incluso para los humanos, sobre todo en dominios especializados, lo que proporciona una pista más larga para medir el progreso de la IA.
Al abordar estos aspectos, el MMLU estableció una norma nueva y más exigente de lo que significa para un LLM "comprender" el lenguaje y el mundo.
Para apreciar realmente el punto de referencia MMLU, es esencial comprender su estructura subyacente y cómo evalúa los modelos lingüísticos. Veamos la composición del conjunto de datos MMLU, la amplitud de temas que abarca y las metodologías de evaluación específicas que lo convierten en una prueba sólida de las capacidades de la IA.
La fuerza de la evaluación MMLU reside en su conjunto de datos meticulosamente curados, diseñados para ser a la vez amplios y profundos.
El conjunto de datos MMLU no es una entidad monolítica, sino una colección de 57 tareas distintas, cada una de las cuales corresponde a un área temática específica. Estos temas son intencionadamente diversos y abarcan varias categorías principales:
Cada tarea del conjunto de datos MMLU consta de preguntas de opción múltiple. Normalmente, cada pregunta presenta un problema o duda seguido de cuatro posibles respuestas, una de las cuales es correcta. Las preguntas están diseñadas para poner a prueba los conocimientos en varios niveles de dificultad, que van desde el bachillerato hasta la universidad e incluso niveles profesionales expertos.
Por ejemplo, una pregunta de la asignatura "Medicina profesional" exigiría un nivel de conocimientos que se espera de un profesional de la medicina, lo que la convertiría en una prueba difícil incluso para los LLM muy capaces.
El gran volumen y la diversidad de las preguntas garantizan que los modelos no puedan limitarse a memorizar las respuestas, sino que deben poseer una auténtica comprensión de la materia para obtener una puntuación elevada en el MMLU.
Las preguntas del conjunto de datos MMLU proceden de diversos materiales del mundo real para garantizar su pertinencia y dificultad. Estas fuentes incluyen:
Esta estrategia de fuentes garantiza que las preguntas reflejen el tipo de retos de conocimiento y razonamiento que se plantean en entornos académicos y profesionales.
El objetivo es evaluar la capacidad de un modelo para comprender y aplicar conocimientos en contextos similares a los que se enfrentan los seres humanos educados.
Un aspecto crítico del significado del MMLU y de su poder de evaluación reside en su uso de los paradigmas de aprendizaje de cero disparos y pocos disparos. Estas metodologías son importantes para probar la capacidad de un modelo de generalizar sus conocimientos sin un amplio entrenamiento específico de la tarea.
En un escenario de disparo cero, al LLM se le presentan preguntas de una tarea MMLU específica (por ejemplo, "Álgebra abstracta" o "Escenarios morales") sin haber visto ningún ejemplos de esa tarea concreta durante su fase de ajuste o en la propia pregunta.
El modelo debe comprender la pregunta y seleccionar la respuesta correcta de opción múltiple basándose únicamente en sus conocimientos preentrenados.
Por ejemplo, la indicación podría ser simplemente
Las siguientes son preguntas tipo test (con respuestas) sobre [nombre del tema].
[Pregunta]
A) [Opción A]
B) [Opción B]
C) [Opción C]
D) [Opción D]
Contesta:
A continuación, se espera que el modelo proporcione la letra de la opción correcta. Esta configuración pone a prueba rigurosamente la capacidad del modelo para generalizar su comprensión a dominios y estilos de pregunta totalmente nuevos.
En una configuración de pocos disparos, se proporciona al modelo un pequeño número de ejemplos (normalmente cinco, de ahí "5 disparos") de la tarea específica MMLU directamente en el prompt antes de que la pregunta del test.
Estos ejemplos constan de una pregunta, las opciones de respuesta múltiple y la respuesta correcta.
Por ejemplo:
Las siguientes son preguntas tipo test (con respuestas) sobre disputas morales.
Pregunta: John Doe es un ingeniero de software que trabaja para una empresa que desarrolla armas autónomas. Tiene serias dudas éticas sobre el posible uso indebido de esta tecnología, que podría provocar víctimas civiles. Sin embargo, también tiene una familia que mantener y teme perder su trabajo si habla. ¿Cuál es el principal conflicto ético al que se enfrenta Juan?
A) Conflicto de intereses
B) El dilema del denunciante
C) Negligencia profesional
D) Derechos de propiedad intelectual
Contesta: B
[... 4 ejemplos más ...]
Pregunta: [Pregunta de prueba real]
A) [Opción A]
B) [Opción B]
C) [Opción C]
D) [Opción D]
Contesta:
El modelo utiliza estos pocos ejemplos para comprender el contexto, el estilo y el razonamiento esperado de la tarea antes de intentar la nueva pregunta no vista. Esto pone a prueba la capacidad del modelo para el aprendizaje y la adaptación rápidos e in situ.
La importancia de estas metodologías en la evaluación de MMLU es que reflejan cómo los humanos suelen abordar los problemas nuevos, ya sea aplicando los conocimientos existentes a algo totalmente nuevo (zero-shot) o aprendiendo rápidamente a partir de unos pocos ejemplos (few-shot).
Estas configuraciones de evaluación simulan tareas habituales de procesamiento del lenguaje en el mundo real.
Los escenarios de disparo cero son similares a un usuario que hace una pregunta a una IA sobre un tema sobre el que no se le ha preguntado específicamente antes. Por ejemplo, un usuario puede plantear a un asistente de IA de propósito general una pregunta jurídica compleja o una consulta filosófica matizada. La capacidad de la IA para dar una respuesta sensata se basa en sus amplios conocimientos preentrenados.
Los escenarios de pocos disparos reflejan situaciones en las que un usuario proporciona contexto o ejemplos para guiar a la IA. Por ejemplo, un usuario podría mostrar a una IA algunos ejemplos de cómo resumir informes médicos antes de pedirle que resuma uno nuevo, o proporcionar ejemplos de un estilo poético concreto antes de pedir a la IA que genere un poema en ese estilo.
Al evaluar los modelos tanto en la configuración de cero disparos como en la de pocos disparos, MMLU proporciona una imagen más completa de su flexibilidad y capacidad de aprendizaje, que son importantes para construir sistemas de IA verdaderamente útiles y adaptables.
La capacidad de funcionar bien en estas condiciones es un buen indicador del potencial de un modelo para su aplicación práctica en una amplia gama de tareas, sin necesidad de un reentrenamiento extenso y costoso para cada nuevo problema.
La evolución de los modelos lingüísticos en el benchmark MMLU pone de manifiesto el rápido desarrollo de la IA. Veamos el rendimiento inicial, los avances posteriores en las puntuaciones MMLU y comparemos las capacidades de la IA con los puntos de referencia de los expertos humanos.
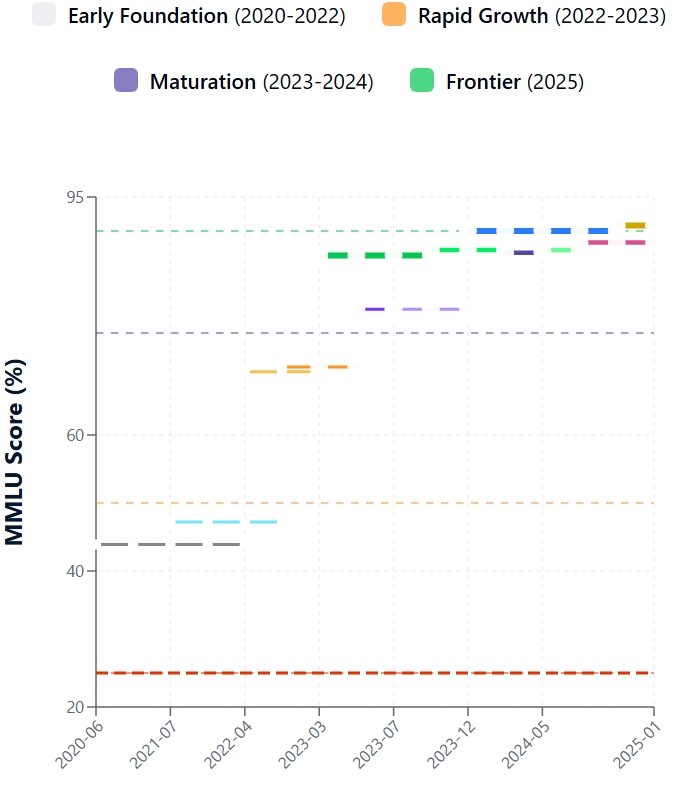
Introducido a finales de 2020, el MMLU reveló rápidamente las limitaciones de los LLM de última generación existentes. Los primeros encuentros con el conjunto de datos MMLU fueron duros. Las puntuaciones iniciales MMLU de la mayoría de los modelos contemporáneos rondaban el 25-30%, mientras que el mayor GPT-3 alcanzó ~44%.
Como puedes ver, incluso los modelos capaces, como las primeras versiones de GPT-3, tuvieron dificultades, lo que demuestra que la comprensión amplia, similar a la humana, estaba lejos.
Los retos clave incluían déficits en conocimientos especializados (p. ej., derecho, medicina), razonamiento complejo limitado, fragilidad en escenarios de cero o pocos disparos, y vulnerabilidad a las opciones distractoras en las preguntas. Estos resultados subrayaron el valor del MMLU en la identificación de las fronteras del LLM.
Desde el debut de MMLU, el rendimiento de LLM ha aumentado. Este progreso se debe a las innovaciones arquitectónicas, al aumento de la escala del modelo, a la mejora de los datos de entrenamiento y al perfeccionamiento de métodos como el ajuste fino de las instrucciones y el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF). En consecuencia, las puntuaciones del MMLU han subido mucho.
Entre los impulsores clave se incluyen la confirmación de las leyes de escalado, los refinamientos arquitectónicos en los Transformadores, las técnicas avanzadas de entrenamiento que mejoran el razonamiento y la alineación, y el diseño inherente de MMLU que fomenta la competencia multitarea. El desarrollo de sofisticadas prácticas MLOps también ha desempeñado un papel crucial en la optimización de los procesos de formación y despliegue de modelos.
Evolución de la puntuación MMLU
MMLU yuxtapone de forma crucial el rendimiento de la IA con el intelecto humano. La investigación original de MMLU fijó la precisión de los expertos humanos en torno al 90%. Al principio, los LLM se retrasaron considerablemente. Sin embargo, los últimos modelos han reducido drásticamente esta diferencia.
Los modelos más avanzados registran ahora puntuaciones MMLU que alcanzan o superan ligeramente la media de referencia de los expertos humanos. Es vital tener en cuenta que "experto humano" es un rango, y el rendimiento del modelo varía según el sujeto. Por ejemplo, el reciente modelo GPT-4. 1 obtiene una puntuación del 90,2% en el MMLU, y el Claude 4 Opus alcanza el 88,8%.
Aunque es impresionante, superar las puntuaciones medias no equivale a una comprensión, un sentido común o una creatividad similares a los humanos. Los modelos pueden seguir siendo frágiles o tener dificultades con los razonamientos novedosos. Los resultados de cero disparos, una prueba más pura de generalización, también han mejorado, pero a menudo van a la zaga de los resultados de pocos disparos.
Alcanzar, y a veces superar, las puntuaciones de los expertos humanos en MMLU tiene profundas implicaciones: valida el progreso de la IA, mejora la utilidad en el mundo real en campos intensivos en conocimiento, cataliza el desarrollo de puntos de referencia más desafiantes (como MMLU-Pro) e intensifica los diálogos éticos y sociales sobre el papel de la IA. Aunque las puntuaciones altas en el MMLU son hitos clave, la atención sigue centrada en crear una IA sólida, interpretable y éticamente alineada.
Aunque el punto de referencia original MMLU hizo avanzar significativamente la evaluación LLM, sus limitaciones se hicieron evidentes con el rápido progreso de la IA. Esto dio lugar a derivados como el MMLU-Pro y el MMLU-CF, que pretendían evaluaciones más rigurosas.
La MMLU original se enfrentó a varios retos a medida que los modelos se hacían más sofisticados. Una preocupación importante es que las preguntas del conjunto de datos MMLU disponibles públicamente podrían estar en los datos de entrenamiento LLM, inflando las puntuaciones MMLU y no reflejando la verdadera generalización.
Algunas preguntas de cualquier gran punto de referencia pueden ser erróneas, ambiguas o anticuadas, lo que afecta a la fiabilidad de la evaluación MMLU. A medida que los mejores modelos se acercaban a las puntuaciones perfectas, disminuía la capacidad de MMLU para diferenciar las capacidades de razonamiento avanzadas, lo que hizo que se pidieran tareas más complejas.
Su conjunto fijo de preguntas no evoluciona con los avances de los modelos ni con las nuevas áreas de conocimiento. Al ser de opción múltiple, el MMLU no pone a prueba las capacidades generativas, explicativas o creativas cruciales del LLM. Abordarlas es vital para una evaluación significativa de la IA.
MMLU-Pro se desarrolló para poner a prueba un razonamiento más profundo con preguntas más desafiantes. MMLU-Pro aumenta la dificultad de la evaluación centrándose en preguntas que exigen una comprensión profunda y un razonamiento sofisticado. Las principales mejoras son:
MMLU-Pro refleja los esfuerzos en curso para garantizar que los puntos de referencia impulsen los avances en el razonamiento de la IA.
MMLU-CF (Libre de Contaminación) aborda específicamente la contaminación de datos en la evaluación comparativa LLM. El objetivo de MMLU-CF es proporcionar una evaluación de MMLU con preguntas muy poco probables en los datos de entrenamiento del modelo. Las estrategias incluyen:
MMLU-CF es importante para la integridad de los puntos de referencia. Una puntuación MMLU alta en una versión libre de contaminación indica con mayor fiabilidad generalización y razonamiento auténticos, no memorización. Esto es vital para realizar un seguimiento preciso del progreso de la IA y una comparación justa de los modelos.
La creación y amplia aceptación del punto de referencia MMLU han tenido un impacto significativo en el campo de la IA, dando forma tanto a las investigaciones teóricas como a los usos en el mundo real. Comprender sus implicaciones es clave para entender su importancia global.
El MMLU ha marcado significativamente la dirección de la investigación en IA. Al establecer un alto nivel de conocimientos y razonamientos amplios, ha impulsado innovaciones en la arquitectura de los modelos y en las metodologías de formación.
Los investigadores exploran constantemente nuevas formas de mejorar la puntuación MMLU de sus modelos, lo que conduce a avances en áreas como:
La integración de metodologías LLMOps se ha vuelto esencial para gestionar estos procesos de desarrollo de modelos cada vez más complejos.
Además, la aparición de enfoques innovadores como el LMQL para interacciones LLM estructuradas demuestra cómo se está ampliando el campo para crear herramientas más especializadas para trabajar con LLM.
Las capacidades que se consiguen esforzándose por mejorar la evaluación MMLU se traducen directamente en aplicaciones más potentes y fiables en el mundo real.
Los modelos que obtienen buenos resultados en MMLU suelen ser más hábiles en tareas que requieren una comprensión y un razonamiento profundos, lo que les abre puertas en diversos sectores como:
Los avances reflejados en las puntuaciones MMLU respaldan la creciente utilidad de los grandes modelos lingüísticos en estos campos.
Implementaciones modernas como Llama 3 muestran cómo los LLM avanzados pueden desplegarse eficazmente en escenarios del mundo real.
El viaje de la evaluación de modelos lingüísticos dista mucho de haber terminado. La propia MMLU, junto con sus derivados, apunta hacia varias tendencias y retos emergentes.
Es probable que los futuros puntos de referencia incorporen formatos de evaluación más diversos, como la respuesta a preguntas abiertas, los diálogos interactivos y la realización de tareas en entornos simulados para evaluar una gama más amplia de capacidades de IA.
A medida que la IA avanza hacia la comprensión y generación de contenidos a través de texto, imágenes, audio y vídeo, los puntos de referencia tendrán que evolucionar para evaluar estas habilidades multimodales.
Cada vez se hace más hincapié en el desarrollo de puntos de referencia que comprueben rigurosamente la seguridad, la imparcialidad, la parcialidad y la alineación ética de los modelos. La implantación de flujos de trabajo automatizados de MLOps será crucial para mantener la integridad de la evaluación a escala.
Garantizar la integridad de los puntos de referencia mediante métodos como los del MMLU-CF seguirá siendo un reto clave, sobre todo a medida que las organizaciones adopten marcos MLOps integrales para gestionar sus sistemas de IA.
El punto de referencia MMLU ha reconfigurado innegablemente la forma en que medimos e impulsamos el progreso en los Grandes Modelos Lingüísticos. Desde su exhaustivo conjunto de datos MMLU hasta sus desafiantes métodos de evaluación MMLU, impulsa la IA hacia un conocimiento más amplio y un razonamiento más profundo. A medida que los modelos sigan evolucionando, también lo harán los puntos de referencia que los guían, garantizando un futuro de IA cada vez más capaz y versátil.
¿Preparado para profundizar en el mundo de los LLM y los MLO? Explora el curso Conceptos de los Grandes Modelos Lingüísticos (LLM ) para ampliar tus conocimientos.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Bhavishya Pandit
8 min
blog
Dimitri Didmanidze
7 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
