
Cursus
Principes fondamentaux de l'IA
10 h
J'ai récemment conclu un contrat avec une entreprise spécialisée dans l'intelligence artificielle. Entre autres, ils assistent les chercheurs dans le post-entraînement des LLM. En tant que docteur en mathématiques, j'ai élaboré des problèmes mathématiques qui ont posé des difficultés aux modèles d'IA de pointe. Les astuces ne comptaient pas ; les questions devaient mettre en évidence les erreurs de raisonnement.
Au cours de ce travail, j'ai entendu à plusieurs reprises des références au « dernier examen de l'humanité ». J'ai appris qu'il s'agissait d'un test de référence en matière d'intelligence artificielle conçu pour évaluer le raisonnement dans de nombreux domaines universitaires. Ma curiosité m'a incité à approfondir mes recherches sur ce qu'est le HLE et ce qu'il nous apprend sur les limites actuelles du raisonnement de l'IA.
Si vous débutez dans le domaine de l'IA et du benchmarking, je vous recommande de suivre le cursus de compétences « Principes fondamentaux de l'IA ».
À mesure que les LLM ont évolué, les chercheurs se sont appuyés sur des collections de questions d'évaluation, appelées benchmarks, pour comparer les performances et suivre le cursus. Le dernier examen de l'humanité (HLE) est un test de référence conçu pour mesurer les capacités d' sraisonnement d'un LLM , et pas seulement sa capacité à reconnaître des modèles. Il vise à évaluer la capacité d'un modèle à traiter des problèmes de niveau expert dans de nombreux domaines académiques.
Étant donné le nombre important de benchmarks déjà disponibles, pourquoi en créer un nouveau ? Les benchmarks qui représentaient autrefois un défi pour les LLM, tels que le MMLU, sont désormais saturés, les modèles obtenant souvent des scores supérieurs à 90 %. À ce stade, ces tests de performance cessent de mesurer des différences significatives entre les modèles.
HLE est un test de référence de nouvelle génération qui augmente le niveau de difficulté en rassemblant des questions élaborées par des experts qui nécessitent un raisonnement en plusieurs étapes, et non pas simplement la mémorisation de correspondances superficielles.
À la fin de l'année 2024, le Centre for AI Safety, une organisation à but non lucratif dédiée à la sécurité de l'IA, s'est associé à Scale AI, une entreprise spécialisée dans les données, afin de développer un benchmark plus exigeant pour l'IA. Monsieur Dan Hendrycks a dirigé le projet.
L'équipe a recueilli des questions de niveau universitaire dans plusieurs disciplines académiques et a offert des prix importants : les 50 meilleurs contributeurs ont chacun gagné 5 000 dollars, et les 500 suivants ont reçu 500 dollars.
Le résultat a été un vaste ensemble de questions de niveau expert couvrant de nombreux sujets, tels que les mathématiques, l'informatique, la littérature, l'analyse musicale et l'histoire.
Le document HLE décrit le benchmark comme « ...le benchmark définitif et fermé pour les compétences académiques générales ». Ses questions nécessitent un raisonnement en plusieurs étapes, ce qui empêche les modèles de deviner ou de mémoriser les réponses.
HLE comprend 2 500 questions publiques et environ 500 questions supplémentaires dans un ensemble privé.
Chaque question doit être originale, avoir une seule réponse correcte et ne pas pouvoir être trouvée facilement par une simple recherche sur Internet ou dans une base de données. Environ 76 % des questions utilisent le format de réponse à correspondance exacte et les 24 % restants utilisent le format à choix multiples. Environ 14 % des questions sont multimodales, impliquant à la fois du texte et des images.
L'équipe HLE a appliqué un processus de vérification rigoureux pour les questions.
Les premiers résultats ont montré que les modèles pionniers ont initialement obtenu de faibles scores aux questions, tout en exprimant un niveau de confiance élevé. Cet écart indique la présence d'hallucinations.
Des groupes indépendants ont également exprimé leurs préoccupations. Future House, un laboratoire de recherche à but non lucratif, a publié un article de blog intitulé « Environ 30 % des réponses aux examens finaux de chimie/biologie de l'humanité sont probablement erronées ».
Leur analyse s'est concentrée sur le protocole d'examen. Les auteurs des questions ont affirmé que les réponses étaient correctes, mais les évaluateurs ont reçu pour instruction de ne consacrer que cinq minutes à la vérification de l'exactitude des réponses. Ils affirment que ce processus permet à des réponses trop complexes, artificielles ou ambiguës de passer entre les mailles du filet, ce qui est souvent en contradiction avec la littérature scientifique.
Les responsables de HLE ont répondu à cette publication en commandant une expertise menée par trois experts sur le sous-ensemble litigieux. Le 16 septembre 2025, ils prévoyaient d'annoncer un processus de révision continue à HLE.
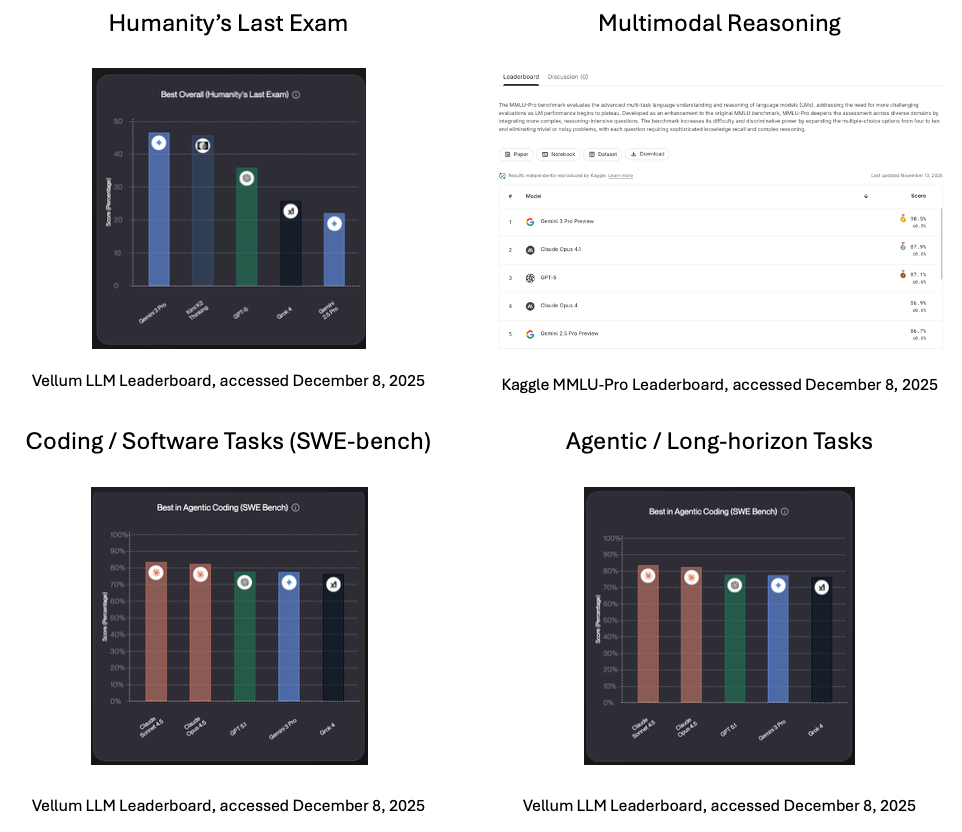
HLE s'inscrit dans un écosystème plus large de benchmarks qui évaluent différents aspects des capacités des LLM.
Ces critères d'évaluation évaluent les connaissances académiques et le raisonnement.
Ces critères évaluent le raisonnement impliquant à la fois du texte et des images.
D'autres critères se concentrent spécifiquement sur l'ingénierie logicielle et l'utilisation d'outils.
Le Centre de recherche sur les modèles fondamentaux (CRFM) de Stanford a développé une évaluation holistique des modèles linguistiques. Évaluation holistique des modèles linguistiques (HELM) afin de favoriser une évaluation responsable de l'IA.
HELM évalue les modèles à l'aide d'une série de scénarios standardisés, tels que la réponse à des questions, la synthèse, les requêtes critiques en matière de sécurité et le contenu social/éthique. Ces scénarios sont évalués selon plusieurs critères, non seulement la précision, mais également l'étalonnage, la robustesse et la toxicité.
HELM s'est développé pour devenir une famille de cadres connexes.
Les cadres de sécurité évaluent le risque plutôt que les compétences intellectuelles.
De nombreux classements publics évaluent les performances des LLM à l'aide de divers indicateurs.
Voici quelques résultats au moment de la rédaction de cet article, en décembre 2025.
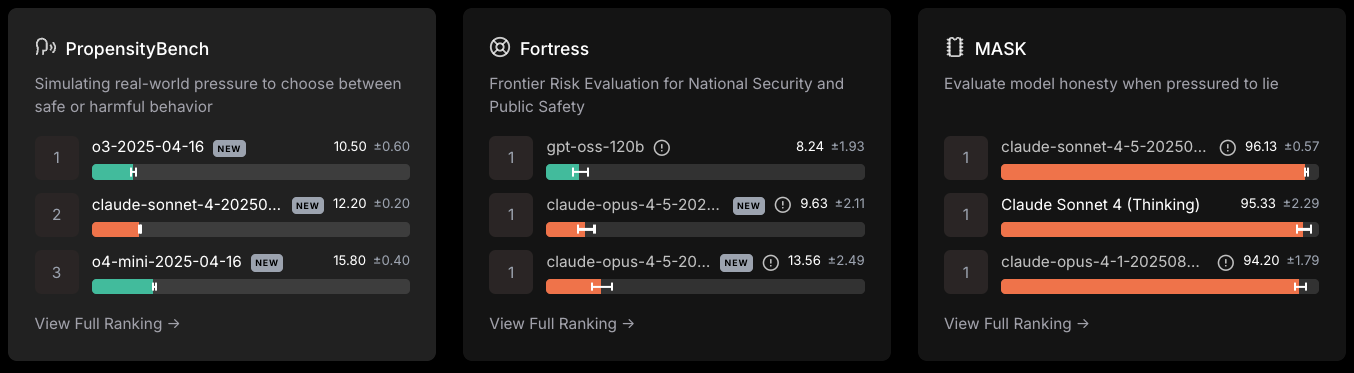
Classement des leaders en matière de sécurité LLM, consulté le 8 décembre 2025
Jusqu'à présent, j'ai présenté ce qu'est le HLE et comment il a été développé. Examinons maintenant comment le test est utilisé dans la pratique.
HLE fournit une méthode d'évaluation standardisée dans tous les domaines. Il met en évidence les points forts et les points faibles d'un modèle. Il met en évidence l'écart entre ses performances et celles d'un expert humain. Les équipes peuvent utiliser ces modèles pour orienter le développement de modèles et cibler la formation post-formation.
HLE fournit un indicateur public et mondial des progrès réalisés en matière de raisonnement artificiel. Il établit un point de référence commun à tous les pays et organismes de réglementation et permet d'ancrer les discussions sur les seuils, la surveillance et la gouvernance dans la réalité, et non dans le battage médiatique.
Les critères de référence en matière d'IA déterminent la manière dont nous évaluons les progrès réalisés dans ce domaine. Les benchmarks précédents ayant atteint leur limite, le besoin d'un nouveau benchmark, axé sur le raisonnement et non plus uniquement sur la mémorisation ou la reconnaissance de formes, est devenu évident.
Humanity's Last Exam tente de combler cette lacune en recueillant des questions de niveau universitaire auprès d'experts du monde entier afin de mettre en évidence les limites des modèles linguistiques à grande échelle (LLM). Ce n'est pas le dernier mot, mais cela clarifie la position actuelle de l'IA par rapport au raisonnement des experts humains.
Pour plus d'informations sur les LLM et leur fonctionnement, je vous recommande les ressources suivantes :
Meilleurs cours sur l'IA
Cursus
Cours
Cours