
Programa
Fundamentos da IA
10 h
Acabei de fechar um contrato com uma empresa de inteligência artificial. Entre outras coisas, eles ajudam os pesquisadores a treinar LLMs. Como doutor em matemática, criei problemas matemáticos que deixaram os modelos de IA mais avançados sem saber o que fazer. As dicas não valiam; as dicas tinham que mostrar os erros de raciocínio.
Durante esse trabalho, ouvi várias referências ao “Último Exame da Humanidade”. Descobri que era um benchmark de IA feito pra testar o raciocínio em várias áreas acadêmicas. Minha curiosidade me levou a pesquisar mais sobre o que é HLE e o que isso nos diz sobre os limites atuais do raciocínio da IA.
Se você é novo no mundo da IA e do benchmarking, recomendo fazer o programa de habilidades Fundamentos de IA.
Com o avanço dos LLMs, os pesquisadores usam conjuntos de perguntas de avaliação, conhecidos como benchmarks, para comparar o desempenho e acompanhar o progresso. O Último Exame da Humanidade (HLE ) é um benchmark feito pra medir as habilidades de raciocínio e de correspondência de padrões de um LLM , não só a capacidade dele de fazer a correspondência de padrões. O objetivo é ver como um modelo lida com problemas de nível avançado em várias áreas acadêmicas.
Com tantos benchmarks já existentes, por que criar mais um? Os benchmarks que antes desafiavam os LLMs, como o MMLU, agora estão saturados, com modelos frequentemente obtendo pontuações acima de 90%. Nesse ponto, esses benchmarks deixam de medir diferenças significativas entre os modelos.
O HLE é um padrão de referência de última geração que aumenta o nível de dificuldade ao reunir perguntas elaboradas por especialistas que exigem raciocínio em várias etapas, e não apenas a memorização de padrões superficiais.
No final de 2024, o Centro para a Segurança da IA, uma organização sem fins lucrativos dedicada à segurança da IA, fez uma parceria com a Scale AI, uma empresa de dados, para desenvolver um benchmark de IA mais difícil. Dan Hendrycks comandou o projeto.
A equipe fez um crowdsourcing de perguntas de nível de pós-graduação de várias disciplinas acadêmicas e ofereceu prêmios bem legais: os 50 melhores colaboradores ganharam US$ 5.000 cada, e os 500 seguintes ganharam US$ 500.
O resultado foi um grande conjunto de perguntas de nível especializado em várias disciplinas, como matemática, ciência da computação, literatura, análise musical e história.
O documento da HLE descreve o benchmark como "... o benchmark final fechado para habilidades acadêmicas gerais." As perguntas exigem um raciocínio em várias etapas, o que impede que os modelos adivinhem ou memorizem as respostas.
O HLE tem 2.500 perguntas públicas e mais ou menos 500 perguntas adicionais num conjunto privado.
Cada pergunta precisa ser original, ter só uma resposta certa e não ser fácil de achar numa busca rápida na internet ou num banco de dados. Cerca de 76% das perguntas usam o formato de resposta de correspondência exata e os 24% restantes usam múltipla escolha. Mais ou menos 14% das perguntas são multimodais, envolvendo tanto texto quanto imagens.
A equipe da HLE tinha um processo de verificação bem rigoroso para as perguntas.
Os primeiros resultados mostraram que os modelos pioneiros inicialmente tiveram notas baixas nas perguntas, mas mostraram muita confiança. Essa diferença indica alucinações.
Grupos independentes também mostraram preocupação. A Future House, um laboratório de pesquisa sem fins lucrativos, publicou um blog intitulado “Cerca de 30% das respostas da última prova de química/biologia da humanidade provavelmente estão erradas”.
A análise deles focou no protocolo de revisão. Os autores das perguntas afirmaram que as respostas estavam corretas, mas os revisores foram instruídos a dedicar apenas cinco minutos à revisão da correção das respostas. Eles dizem que esse processo deixa passar respostas muito complicadas, forçadas ou confusas, que muitas vezes não batem com o que a literatura científica diz.
Os responsáveis pela manutenção do HLE responderam à publicação encomendando uma revisão por três especialistas do subconjunto em disputa. A partir de 16 de setembro de 2025, eles planejaram anunciar um processo de revisão contínua para a HLE.
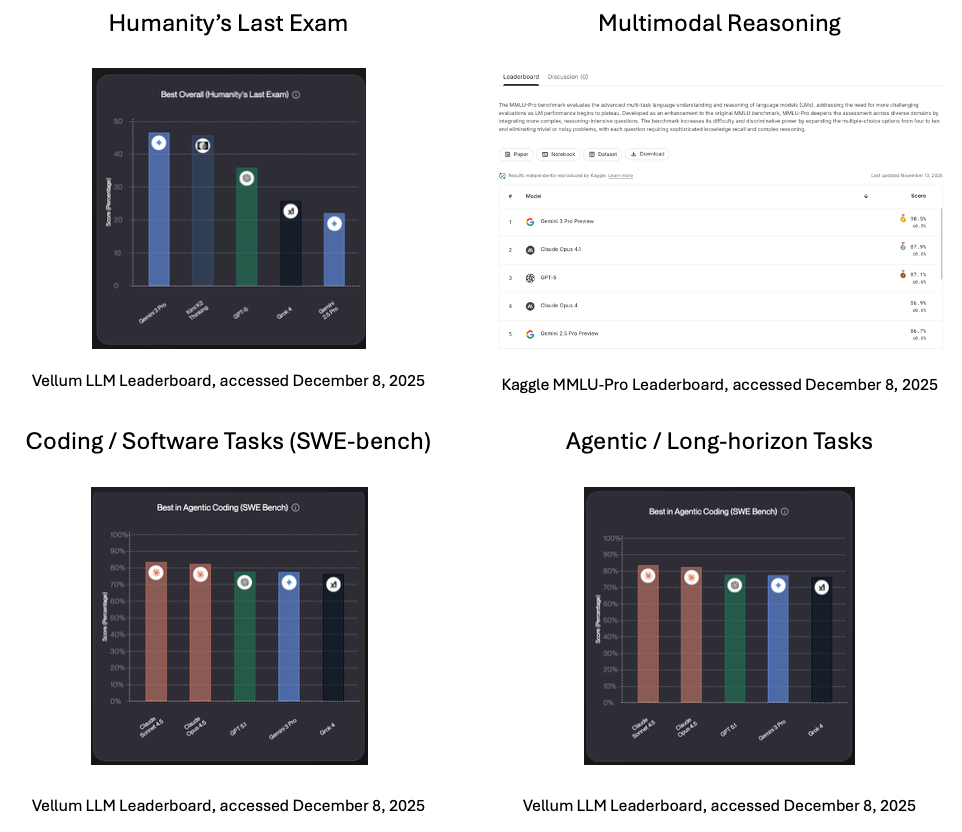
O HLE faz parte de um ecossistema mais amplo de benchmarks que testam diferentes aspectos da capacidade do LLM.
Esses padrões de referência avaliam o conhecimento acadêmico e o raciocínio.
Esses benchmarks medem o raciocínio que envolve tanto texto quanto imagens.
Outros benchmarks ainda se concentram especificamente em engenharia de software e uso de ferramentas.
O Centro de Pesquisa em Modelos Fundamentais (CRFM) da Universidade de Stanford desenvolveu Avaliação Holística de Modelos de Linguagem (HELM) para apoiar a avaliação responsável da IA.
O HELM avalia modelos em uma série de cenários padronizados, como resposta a perguntas, resumos, consultas críticas à segurança e conteúdo social/ético. Esses cenários são avaliados em várias dimensões, não só na precisão, mas também na calibração, robustez e toxicidade.
O HELM virou uma família de frameworks relacionados.
As estruturas de segurança medem o risco, e não a competência intelectual.
Muitos programas públicos acompanham o desempenho do LLM em várias métricas.
Aqui estão algumas pontuações até o momento em que este artigo foi escrito, em dezembro de 2025.
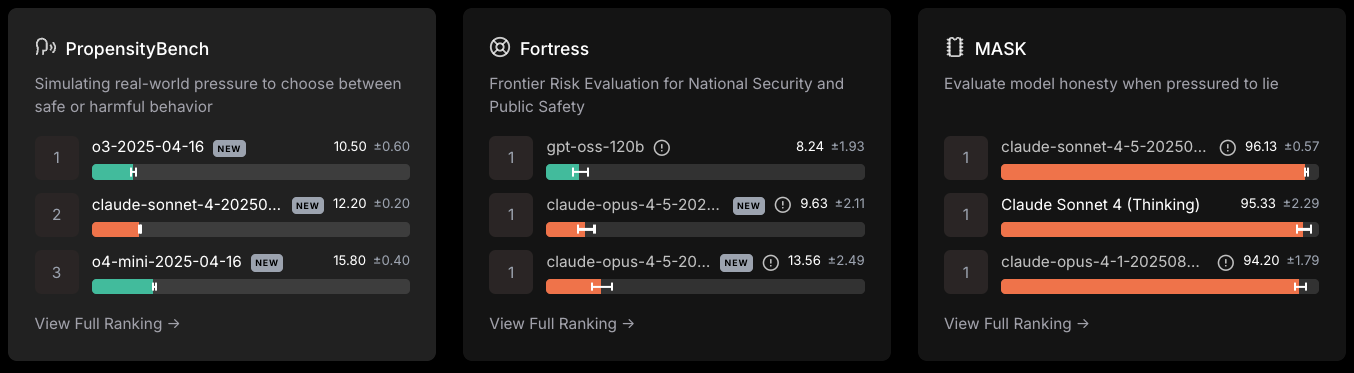
Ranking de segurança da Scale LLM, acessado em 8 de dezembro de 2025
Até agora, eu expliquei o que é HLE e como foi desenvolvido. Vamos agora ver como o teste é usado na prática.
A HLE oferece um método de avaliação padronizado para todos os domínios. Ele mostra os pontos fortes e fracos de um modelo. Isso mostra a diferença entre ele e o desempenho de um especialista humano. As equipes podem usar esses padrões para orientar o desenvolvimento de modelos e o pós-treinamento focado.
A HLE oferece uma métrica pública e global do progresso do raciocínio da IA. Isso cria um ponto de referência comum entre países e órgãos reguladores e pode fundamentar discussões sobre limites, supervisão e governança na realidade, sem exageros.
Os benchmarks de IA moldam a forma como medimos o progresso da IA. Como os benchmarks anteriores ficaram saturados, ficou claro que precisávamos de um novo benchmark, focado no raciocínio, e não só na memorização ou na correspondência de padrões.
O Humanity's Last Exam tenta preencher essa lacuna com perguntas de nível de pós-graduação feitas por especialistas de todo o mundo para mostrar as limitações dos LLMs. Não é a palavra final, mas deixa claro onde a IA está hoje em relação ao raciocínio dos especialistas humanos.
Pra saber mais sobre LLMs e como funcionam, recomendo os seguintes recursos:
Os melhores cursos de IA
Programa
Curso
Curso