
Lernpfad
Grundlagen der KI
10 Std.
Ich hab gerade einen Auftrag für eine KI-Firma gemacht. Unter anderem helfen sie Forschern dabei, LLMs nachzutrainieren. Als promovierter Mathematiker habe ich Matheaufgaben entwickelt, die selbst die modernsten KI-Modelle überfordert haben. Trickfragen zählten nicht; die Fragen mussten Denkfehler aufdecken.
Während dieser Arbeit hab ich immer wieder von der „letzten Prüfung der Menschheit“ gehört. Ich hab erfahren, dass es sich um einen KI-Benchmark handelt, der entwickelt wurde, um das logische Denken in vielen akademischen Bereichen zu testen. Meine Neugier hat mich dazu gebracht, genauer zu schauen, was HLE ist und was es uns über die aktuellen Grenzen des KI-Denkens verrät.
Wenn du dich noch nicht so gut mit KI und Benchmarking auskennst, empfehle ich dir den Lernpfad „Grundlagen der KI”.
Da sich LLMs weiterentwickelt haben, nutzen Forscher Sammlungen von Bewertungsfragen, die als Benchmarksbekannt sind , um die Leistung zu vergleichen und den Fortschritt zu verfolgen. Die letzte Prüfung der Menschheit (HLE ) ist ein Test, der entwickelt wurde, um die Fähigkeiten eines LLM zum logischen Denken und zur Schlussfolgerung zu messen , nicht nur seine Fähigkeit zum Musterabgleich. Es geht darum, zu checken, wie gut ein Modell mit kniffligen Problemen aus vielen akademischen Bereichen klarkommt.
Warum noch ein weiterer Benchmark, wenn es doch schon so viele gibt? Benchmarks, die früher für LLMs echt eine Herausforderung waren, wie zum Beispiel MMLU, sind jetzt voll ausgereizt, und die Modelle erreichen oft über 90 Prozent. An diesem Punkt messen diese Benchmarks keine sinnvollen Unterschiede zwischen den Modellen mehr.
HLE ist ein Benchmark der nächsten Generation, der den Schwierigkeitsgrad erhöht, indem er von Experten entwickelte Fragen zusammenstellt, die mehrstufiges logisches Denken erfordern und nicht nur das Abrufen oberflächlicher Muster.
Ende 2024 hat sich das Centre for AI Safety, eine gemeinnützige Organisation, die sich mit KI-Sicherheit beschäftigt, mit Scale AI, einem Datenunternehmen, zusammengetan, um einen anspruchsvolleren KI-Benchmark zu entwickeln. Dan Hendrycks hat das Projekt geleitet.
Das Team hat Fragen auf Hochschulniveau aus verschiedenen akademischen Fachbereichen gesammelt und coole Preise angeboten: Die besten 50 Mitwirkenden haben jeweils 5000 Dollar gewonnen, und die nächsten 500 haben 500 Dollar bekommen.
Das Ergebnis war ein riesiger Pool an Fragen auf Expertenniveau zu vielen Themen, wie Mathe, Informatik, Literatur, Musikanalyse und Geschichte.
Das HLE-Papier beschreibt den Benchmark als „...den endgültigen geschlossenen Benchmark für allgemeine akademische Fähigkeiten.“ Die Fragen erfordern mehrstufiges Denken, was verhindert, dass Modelle Antworten raten oder auswendig lernen.
HLE hat 2.500 öffentliche Fragen und etwa 500 weitere Fragen in einem privaten Holdout-Set.
Jede Frage muss originell sein, eine einzige richtige Antwort haben und darf nicht einfach durch eine Websuche oder Datenbankabfrage gefunden werden können. Ungefähr 76 % der Fragen haben das Antwortformat „genaue Übereinstimmung” und die restlichen 24 % sind Multiple-Choice-Fragen. Ungefähr 14 % der Fragen sind multimodal, also mit Text und Bildern.
Das HLE-Team hat die Fragen echt streng geprüft.
Die ersten Ergebnisse zeigten, dass die Pioniermodelle bei den Fragen anfangs schlecht abschnitten, aber trotzdem viel Zuversicht zeigten. Diese Lücke deutet auf Halluzinationen hin.
Auch unabhängige Gruppen haben Bedenken geäußert. Future House, ein gemeinnütziges Forschungslabor, hat einen Blogbeitrag mit dem Titel „Etwa 30 % der Antworten in den Abschlussprüfungen der Menschheit in Chemie/Biologie sind wahrscheinlich falsch” veröffentlicht.
Ihre Analyse hat sich auf das Überprüfungsprotokoll konzentriert. Die Leute, die die Fragen geschrieben haben, haben die richtigen Antworten angegeben, aber die Prüfer sollten nur fünf Minuten damit verbringen, die Richtigkeit der Antworten zu checken. Sie sagen, dass dieser Prozess zu komplizierte, gekünstelte oder unklare Antworten durchlässt, die oft nicht mit der wissenschaftlichen Literatur übereinstimmen.
Die Leute von HLE haben auf den Beitrag reagiert, indem sie drei Experten gebeten haben, den umstrittenen Teil zu überprüfen. Am 16. September 2025 wollten sie einen fortlaufenden Überprüfungsprozess für HLE ankündigen.
HLE ist Teil eines größeren Ökosystems von Benchmarks, die verschiedene Aspekte der LLM-Fähigkeiten testen.
Diese Benchmarks checken akademisches Wissen und logisches Denken.
Diese Benchmarks messen das logische Denken, das sowohl Texte als auch Bilder umfasst.
Andere Benchmarks konzentrieren sich speziell auf Softwareentwicklung und den Einsatz von Tools.
Das Center for Research on Foundation Models (CRFM) der Stanford University hat ganzheitliche Bewertung von Sprachmodellen (HELM) entwickelt, um eine verantwortungsvolle Bewertung von KI zu unterstützen.
HELM testet Modelle anhand einer Reihe von standardisierten Szenarien, wie zum Beispiel Fragen beantworten, Zusammenfassen, sicherheitskritische Abfragen und soziale/ethische Inhalte. Diese Szenarien werden in mehreren Bereichen bewertet, nicht nur in Bezug auf Genauigkeit, sondern auch in Bezug auf Kalibrierung, Robustheit und Toxizität.
HELM hat sich zu einer ganzen Familie von verwandten Frameworks entwickelt.
Sicherheitsrahmen messen eher das Risiko als die intellektuelle Kompetenz.
Viele öffentliche Ranglisten verfolgen die Leistung von LLM anhand verschiedener Kennzahlen.
Hier sind ein paar Ergebnisse, wie sie zum Zeitpunkt des Verfassens dieses Artikels im Dezember 2025 vorlagen.
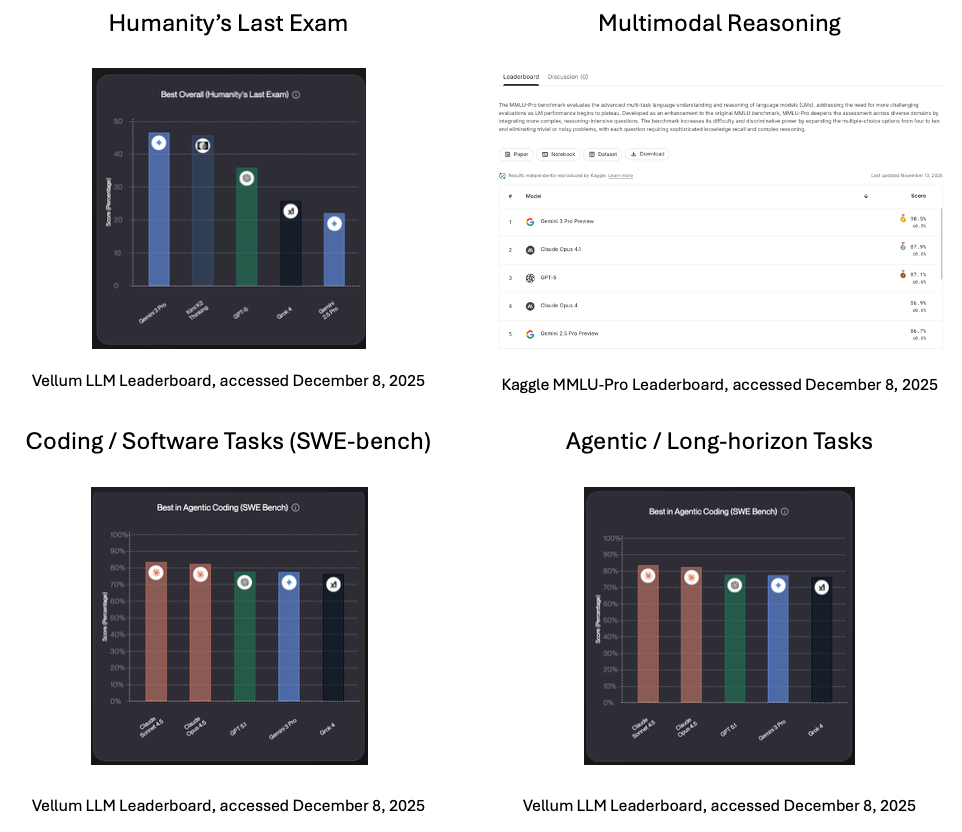
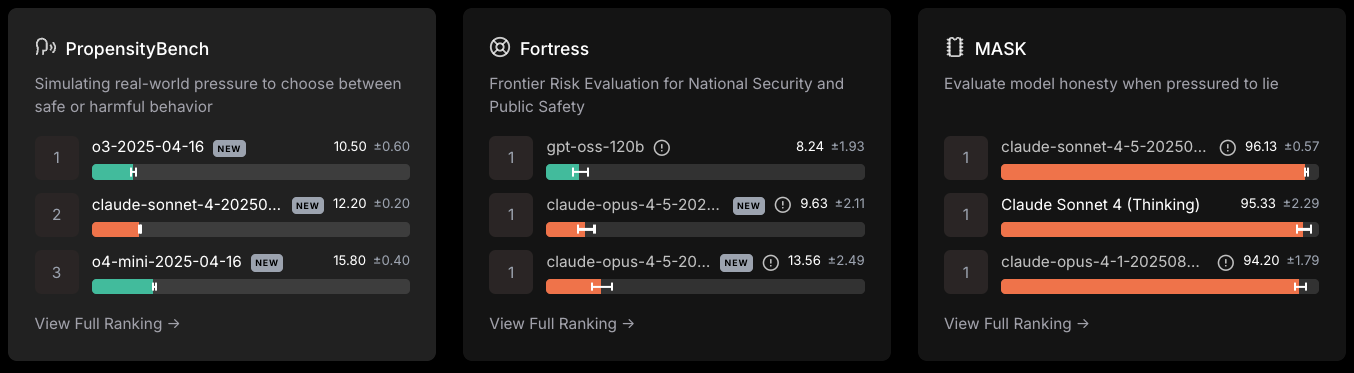
Skala LLM-Sicherheitsrangliste, abgerufen am 8. Dezember 2025
Bis jetzt habe ich erklärt, was HLE ist und wie es entstanden ist. Schauen wir uns jetzt mal an, wie der Test in der Praxis genutzt wird.
HLE bietet eine einheitliche Bewertungsmethode für alle Bereiche. Es zeigt die Stärken und Schwächen eines Modells auf. Es zeigt, wie weit es noch von der Leistung menschlicher Experten entfernt ist. Teams können diese Muster nutzen, um die Modellentwicklung und das gezielte Training nach dem Training zu steuern.
HLE bietet eine öffentliche, globale Messgröße für den Fortschritt beim KI-Schlussfolgern. Es schafft einen gemeinsamen Bezugspunkt für alle Länder und Regulierungsbehörden und kann Diskussionen über Schwellenwerte, Aufsicht und Governance in der Realität verankern, ohne dass es zu einem Hype kommt.
KI-Benchmarks bestimmen, wie wir den Fortschritt der KI messen. Da frühere Benchmarks nicht mehr weiterentwickelt werden, wurde klar, dass wir einen neuen Benchmark brauchen, der sich auf logisches Denken konzentriert und nicht nur auf das Abrufen von Informationen oder das Erkennen von Mustern.
Humanity's Last Exam versucht, diese Lücke zu schließen, indem es Fragen auf Hochschulniveau von Experten aus der ganzen Welt sammelt, um die Grenzen von LLMs aufzuzeigen. Das ist zwar nicht das letzte Wort, aber es zeigt, wo KI heute im Vergleich zum Denken menschlicher Experten steht.
Für mehr Infos über LLMs und wie sie funktionieren, schau dir mal diese Quellen an:
Die besten KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
