
programa
Fundamentos del aprendizaje automático en Python
16 h
Tras haber analizado los principios básicos y los usos de la función valor-acción, ahora te mostraré los pasos para implementarla en Python.
Importa los paquetes necesarios, incluyendo Gymnasium y NumPy:
import gymnasium as gym
import numpy as np
import math
import randomInicializa un entorno RL desde Gymnasium. En este artículo, entrenamos a un agente RL para resolver el entorno CartPole.
env = gym.make('CartPole-v1')El espacio de observación del CartPole tiene cuatro estados: posición del carro, velocidad del carro, ángulo del poste y velocidad angular del poste.
En este ejemplo, nos centramos únicamente en las observaciones del ángulo del polo y la velocidad angular del polo. De este modo, creamos la tabla Q discreta de la siguiente manera:
El número de columnas se basa en el tamaño del espacio de acción, en este caso, 2.
NUM_BUCKETS = (1, 1, 6, 3)
NUM_ACTIONS = env.action_space.n
q_table = np.zeros(NUM_BUCKETS + (NUM_ACTIONS,))En el entorno CartPole, el espacio de estados es continuo. El ángulo, la velocidad y la posición del poste del carro pueden variar continuamente. El espacio de acción es discreto: puedes empujar el carro hacia la izquierda o hacia la derecha.
El aprendizaje Q utilizando tablas Q solo se puede utilizar en un espacio discreto, ya que es necesario tabular explícitamente el valor Q para un conjunto de estados y acciones. Por lo tanto, el primer paso es discretizar el espacio de estados continuo.
En primer lugar, consideramos los límites superior e inferior de las variables del espacio de estados. Observamos que la velocidad del carro y la velocidad angular del poste tienen límites infinitos. Por lo tanto, establecemos artificialmente límites superiores e inferiores para estas variables de estado.
STATE_BOUNDS = list(zip(env.observation_space.low, env.observation_space.high))
STATE_BOUNDS[1] = [-0.5, 0.5]
STATE_BOUNDS[3] = [-math.radians(50), math.radians(50)]Creamos una función para discretizar los valores de estado continuos en valores discretos:
def discretize_state(state):
discrete_states = []
for i in range(len(state)):
if state[i] <= STATE_BOUNDS[i][0]:
discrete_state = 0
elif state[i] >= STATE_BOUNDS[i][1]:
discrete_state = NUM_BUCKETS[i] - 1
else:
bound_width = STATE_BOUNDS[i][1] - STATE_BOUNDS[i][0]
offset = (NUM_BUCKETS[i] - 1) * STATE_BOUNDS[i][0] / bound_width
scaling = (NUM_BUCKETS[i] - 1) / bound_width
discrete_state = int(round(scaling * state[i] - offset))
discrete_states.append(discrete_state)
return tuple(discrete_states)Las ecuaciones de Bellman proporcionan la expresión para actualizar los valores Q basándose en la tasa de aprendizaje, la tasa de descuento, la recompensa que se obtiene al pasar al siguiente paso y el valor Q máximo esperado del siguiente estado. Expresa el valor esperado de un estado como la suma de dos partes:
La ecuación de Bellman es recursiva. De este modo, es posible escribir un programa iterativo, partiendo de un estado inicial aleatorio, para encontrar la función óptima de valor de acción.
La ecuación para actualizar la tabla Q es:
![]()
En la expresión anterior:
state_current » en el código.state_next).action).reward. best_q. El código siguiente implementa la función para actualizar la tabla Q.
def update_q(state_current, state_next, action, reward, alpha):
best_q = np.amax(q_table[state_next])
q_table[state_current + (action,)] += alpha * (reward + GAMMA*(best_q) - q_table[state_current + (action,)])
return best_qDeclara los parámetros del entrenamiento:
MAX_EPISODES = 5000
MAX_STEPS = 500
SUCCESS_STEPS = 450
SUCCESS_STREAK = 50Declara los hiperparámetros:
EPSILON_MIN = 0.01
EPSILON_MAX = 1
ALPHA_MIN = 0.1
ALPHA_MAX = 0.5
GAMMA = 0.99
DECAY_COEFF = 25Antes de entrenar al agente, escribimos dos funciones para reducir gradualmente la tasa de aprendizaje y la tasa de exploración. Estos hiperparámetros disminuyen gradualmente en valor a lo largo del entrenamiento.
def decay_epsilon(step):
return max(EPSILON_MIN, min(EPSILON_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))
def decay_alpha(step):
return max(ALPHA_MIN, min(ALPHA_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))También escribimos una función para seleccionar la acción de forma estocástica. Primero generamos un número aleatorio.
def select_action(state, epsilon):
if random.random() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state])
return actionConstruimos un bucle para entrenar al agente siguiendo estos pasos:
select_action() declarada anteriormente. update_q() declarada anteriormente. El código siguiente implementa los pasos del bucle de entrenamiento:
def train():
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
state_current = state_next
if done:
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
print("=============SUCCESS=============")
else:
successful_episodes = 0
print("=============FAIL=============")
break
if successful_episodes > SUCCESS_STREAK:
breakPor último, ejecuta el bucle de entrenamiento, cierra el entorno e imprime el valor final de la tabla Q.
train()
env.close()
print(q_table)Utiliza este cuaderno de trabajo de DataLab como punto de partida para editar y ejecutar el código para Q-Learning.
En la sección anterior, discretizamos el espacio de observación continuo (estado) para utilizar una tabla Q. Una tabla Q grande (para entornos complejos) es ineficiente desde el punto de vista computacional. En tales casos, la función Q puede aproximarse utilizando una red neuronal. Esto se denomina red Q profunda, expresada como Q(s, a; θ), donde el parámetro θ representa los pesos de la red neuronal. Este método se denomina «aprendizaje Q profundo». En términos más generales, el RL que utiliza redes neuronales profundas se denomina aprendizaje por refuerzo profundo.
En lugar de utilizar la tabla Q para elegir la acción para cada estado, la red neuronal DQN toma el estado como entrada y devuelve el valor Q para cada acción posible en ese estado.
La red se entrena mediante métodos tradicionales (como la retropropagación) para minimizar el error de diferencia temporal (TD). El error TD δ es la diferencia entre los valores Q previstos y los valores Q objetivo (calculados como la suma de la recompensa del estado actual y el valor descontado de la recompensa máxima esperada del siguiente estado).
Cuando se implementa como una red neuronal (con parámetros de red θ), el error TD se expresa como:
![]()
Ten en cuenta que tanto los valores Q como los valores Q objetivo se calculan utilizando la misma red neuronal.
En cada iteración, se actualizan los parámetros de la red (θ). La actualización de la red (mediante retropropagación) se basa en el valor objetivo calculado utilizando el θ previo a la actualización. Cálculo de los valores objetivo con los mismos resultados actualizados en un objetivo en movimiento continuo. Esto hace que el entrenamiento sea inestable.
Para evitar el problema anterior, creamos una nueva red para calcular los valores Q objetivo. Esta es la red de destino. Se basa en los mismos parámetros que la red de políticas, pero se actualiza con menos frecuencia. Por lo tanto, el proceso de entrenamiento tiene un objetivo estable con respecto al cual aplica la retropropagación.
Si representamos los pesos de la red objetivo con θ-, la ecuación anterior se reescribe como:
![]()
Las siguientes secciones mostrarán cómo implementar y entrenar un DQN sencillo en el entorno CartPole.
Instala los paquetes necesarios, incluidos Gymnasium y PyTorch.
!pip install gymnasium matplotlib torchImporta los paquetes necesarios en el entorno Python:
import gymnasium as gym
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as FCrea el entorno CartPole:
env = gym.make("CartPole-v1")Inicializa el entorno y declara las constantes de Python con el tamaño de los espacios de estado y acción del entorno.
state, info = env.reset()
NUM_OBSERVATIONS = len(state)
NUM_ACTIONS = env.action_space.nDeclara una clase Python para una red neuronal simple con una sola capa oculta. El número de capas de entrada es el tamaño del espacio de estado (espacio de observación). El número de capas de salida es el número de acciones posibles que puede realizar el agente RL. Esta red simula internamente la tabla Q y predice los valores de acción dados un estado de entrada.
class DQN(nn.Module):
def __init__(self, NUM_OBSERVATIONS, NUM_ACTIONS):
super(DQN, self).__init__()
self.layer1 = nn.Linear(NUM_OBSERVATIONS, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, NUM_ACTIONS)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)Crea una red de políticas y una red de objetivos. Carga la red de destino con los parámetros de la red de políticas utilizando el diccionario de estados. Inicializa un optimizador para entrenar la red neuronal.
policy_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)Los métodos RL sin modelos fuera de política, como el Q-Learning (analizado en la sección anterior) y las DQN, se entrenan utilizando una muestra aleatoria de las interacciones del agente con el entorno. Las acciones del agente y las respuestas del entorno (recompensa y estado siguiente) se recopilan y almacenan. En cada iteración del entrenamiento se selecciona una muestra aleatoria de estas interacciones para formar un lote de entrenamiento.
Declara un objeto tupla para almacenar el estado del entorno (observación) en cada interacción:
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))Crea una clase Python para el búfer de reproducción:
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)Crea un objeto de memoria para almacenar un gran número de interacciones. Estas interacciones se utilizan para entrenar al agente.
memory = ReplayMemory(10000)Antes del entrenamiento, declara los parámetros y los hiperparámetros:
LR)GAMMA)TAU)EPS_START, EPS_END y EPS_DECAY).MAX_EPISODES = 600
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4Escribe una función para seleccionar la acción en función de la tasa de exploración, siguiendo estos pasos:
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
action = policy_net(state).max(1).indices.view(1, 1)
return action
else:
action = torch.tensor([[env.action_space.sample()]], dtype=torch.long)
return actionEscribe la función para optimizar el modelo basándote en estos pasos:
non_final_mask) para identificar aquellos estados que no van seguidos de un estado terminal. non_final_next_states).![]()
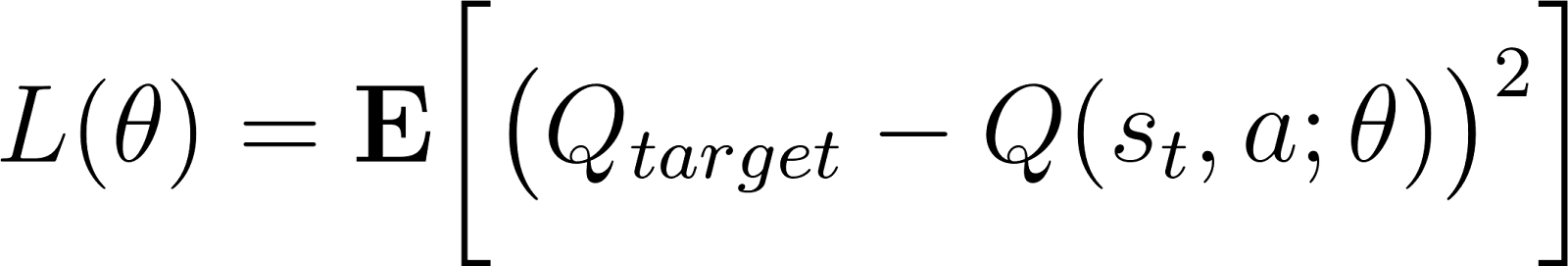
El siguiente código muestra cómo implementar el optimizador:
batch = 0
def optimize_model():
global batch
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE )
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1).values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
loss_func = nn.SmoothL1Loss()
loss = loss_func(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)
optimizer.step()Escribe un bucle de entrenamiento para entrenar al agente:
select_action() » para decidir la acción del agente.El siguiente código implementa estos pasos:
def train():
for episode in range(MAX_EPISODES):
# Initialize the environment and get its state
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
reward = torch.tensor([reward])
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32).unsqueeze(0)
memory.push(state, action, next_state, reward)
state = next_state
optimize_model()
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
print('count -- ', t)
#plot_durations()
breakPuedes ver, editar y ejecutar el programa de entrenamiento DQN utilizando este cuaderno de trabajo de DataLab.
Es útil realizar un seguimiento visual del progreso del proceso de formación. Visualizar los valores de acción ayuda a reconocer dónde está fallando el entrenamiento y qué parámetros o hiperparámetros deben modificarse.
Por ejemplo, si observas visualmente que la mejora en el rendimiento del modelo es demasiado lenta, es posible que desees aumentar la tasa de aprendizaje. Si observas que el modelo está aprendiendo pero aún no se ha entrenado por completo, puede ser útil aumentar el número de episodios de entrenamiento. Si observas que el entrenamiento es inestable, es posible que desees reducir la tasa de aprendizaje o ajustar el coeficiente de exploración o la tasa de actualización de la red objetivo (TAU).
Además de los valores Q, también puede ser útil gráficar el número de pasos exitosos en cada episodio. En el aprendizaje Q utilizando tablas Q, los valores Q se almacenan explícitamente. Sin embargo, cuando se utilizan DQN, los valores Q no se almacenan explícitamente. La red genera la acción en función de sus pesos y del estado. Por lo tanto, realizar un seguimiento del número de pasos correctos en cada episodio puede ser más significativo para el DQN.
Los siguientes pasos describen cómo gráficar los valores Q y el número de pasos exitosos por episodio para entrenar el algoritmo de aprendizaje Q:
q_vals - para almacenar los valores Q en cada paso de cada episodio. success_steps - para almacenar el número de pasos correctos en cada episodio.q_vals ».success_steps » el número de pasos completados con éxito en ese episodio. El código siguiente muestra el bucle de entrenamiento Q-Learning (utilizando tablas Q) (mostrado en la sección anterior) actualizado para realizar un seguimiento de los valores Q y el número de pasos correctos:
q_vals = []
success_steps = []
def train():
global q_vals
global success_steps
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
q_vals.append(best_q)
state_current = state_next
if done:
q_vals.append(best_q)
success_steps.append(step)
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
else:
successful_episodes = 0
break
if successful_episodes > SUCCESS_STREAK:
print("Training successful")
returnEl siguiente fragmento muestra cómo gráficar los valores Q en cada episodio:
def plot_q():
plt.plot(q_vals)
plt.title('Q-values over training steps')
plt.xlabel('Training steps')
plt.ylabel('Q-value')
plt.show()El siguiente fragmento muestra cómo gráficar el número de pasos exitosos en cada episodio:
def plot_steps():
plt.plot(success_steps)
plt.title('Successful steps over training episodes')
plt.xlabel('Training episode')
plt.ylabel('Successful steps')
plt.show()Es necesario especificar los criterios para decidir si el agente ha sido formado con éxito y en qué momento. En el aprendizaje automático tradicional, el objetivo del entrenamiento es minimizar la pérdida: la diferencia entre los valores previstos y los reales. En RL, el objetivo es maximizar la recompensa acumulada. El entrenamiento se considera exitoso cuando el agente obtiene las máximas recompensas del entorno.
Los entornos como CartPole no terminan hasta que alcanzan una condición terminal, como chocar contra los bordes o permitir que el cartpole se incline excesivamente. En tales casos, un agente entrenado puede continuar interactuando con el entorno de forma indefinida. Por lo tanto, el número máximo de pasos correctos se impone de forma artificial. En el caso de CartPole-v1 de Gymnasium, el episodio finaliza cuando alcanza los 500 pasos de tiempo sin terminar.
Evaluamos el rendimiento del agente a lo largo de episodios consecutivos para determinar si el entrenamiento ha sido satisfactorio. Por ejemplo:
SUCCESS_STEPS) de media en los últimos N episodios. En los ejemplos de este artículo, hemos establecido este umbral en 450. SUCCESS_STREAK). En este ejemplo, establecemos N en 50. Como ejemplo práctico, considera este fragmento del bucle de entrenamiento DQN mostrado anteriormente.
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
average_steps = sum(episode_durations[-SUCCESS_STREAK:])/SUCCESS_STREAK
print('average steps over last 50 episodes -- ', average_steps)
if average_steps > SUCCESS_STEPS:
print("training successful.")
return
breakAyuda a evaluar el rendimiento del agente basándose en la ejecución de los siguientes pasos al final (estado terminal) de cada episodio de entrenamiento:
SUCCESS_STREAK) es 50. Así pues, calculamos el promedio de pasos en los últimos 50 episodios. SUCCESS_STEPS), finalizamos el entrenamiento. En este ejemplo, este umbral se establece en 450 pasos. A continuación, se incluyen algunas prácticas recomendadas que puedes seguir para obtener mejores resultados de la implementación de la función de valor de acción.
Dada la función de valor real de la acción, el agente puede maximizar los rendimientos esperados adoptando una estrategia codiciosa, basada en elegir la acción con el valor más alto en cada paso. Esto se denomina explotación de la información disponible. Sin embargo, el uso de una estrategia codiciosa con una función de valor de acción no entrenada (que aún no representa los valores de acción reales) te llevará a quedarte atascado en un óptimo local.
Durante el entrenamiento, es importante tanto explorar el entorno como aprovechar la información disponible.
En las etapas iniciales del proceso de entrenamiento, la información disponible se basa en una función de valor aleatorio. Por lo tanto, esta información no es muy valiosa (para explotar con una estrategia codiciosa). Es más importante explorar el entorno para descubrir las recompensas de las diversas acciones posibles en diferentes estados.
A medida que se actualiza la tabla Q (o se entrena el DQN), resulta viable explotar parcialmente la información disponible para maximizar las recompensas. Hacia las etapas finales del entrenamiento, el agente converge en la función de valor real; una exploración más profunda puede ser perjudicial. Por lo tanto, el agente da prioridad a explotar la función de valor conocida.
Al igual que con cualquier modelo de machine learning, los hiperparámetros son importantes para entrenar con éxito los algoritmos de RL. En el caso del Q-Learning y las DQN, los hiperparámetros son épsilon (tasa de exploración), alfa (tasa de aprendizaje) y gamma (tasa de descuento).
Por último, ten en cuenta que el entrenamiento RL es sensible a los valores aleatorios iniciales. Si el entrenamiento no converge, suele ser útil utilizar una semilla aleatoria diferente o volver a ejecutar el entrenamiento para que comience con un conjunto diferente de valores iniciales aleatorios.
Entrenar agentes RL para entornos complejos es todo un reto. Las funciones Q se utilizan en muchos algoritmos diferentes, por lo que es esencial desarrollar cierta intuición para entrenar agentes RL basados en el aprendizaje Q. La mejor manera de hacerlo es practicando las técnicas en entornos más sencillos, como CartPole, antes de aplicar métodos similares en entornos más complejos.
Además, los entornos complejos son más costosos para la formación, por lo que resulta más económico utilizar entornos más sencillos como herramienta de aprendizaje.
Este artículo ha analizado los principios teóricos fundamentales de la función del valor de la acción y su importancia en el RL. Hemos visto cómo se utilizan las funciones de valor de acción en el aprendizaje Q y el aprendizaje Q profundo, y hemos implementado ambos métodos paso a paso en Python.
Para continuar tu aprendizaje, te recomiendo encarecidamenteel curso Deep Reinforcement Learning in Python.
¡Aprende más sobre la IA con estos cursos!
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Hafeezul Kareem Shaik
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial

