
Lernpfad
Grundlagen des maschinellen Lernens in Python
16 Std.
Nachdem wir die Grundlagen und die Verwendung der Aktionswertfunktion besprochen haben, zeige ich dir jetzt, wie du sie in Python umsetzt.
Importiere die benötigten Pakete, einschließlich Gymnasium und NumPy:
import gymnasium as gym
import numpy as np
import math
import randomInitialisiere eine RL-Umgebung aus Gymnasium. In diesem Artikel trainieren wir einen RL-Agenten, um die CartPole-Umgebung zu meistern.
env = gym.make('CartPole-v1')Der Beobachtungsraum von CartPole hat vier Zustände: Wagenposition, Wagengeschwindigkeit, Stangenwinkel und Stangenwinkelgeschwindigkeit.
In diesem Beispiel konzentrieren wir uns nur auf die Beobachtungen des Polwinkels und der Polwinkelgeschwindigkeit. So erstellen wir die diskrete Q-Tabelle wie folgt:
Die Anzahl der Spalten hängt von der Größe des Aktionsraums ab, in diesem Fall 2.
NUM_BUCKETS = (1, 1, 6, 3)
NUM_ACTIONS = env.action_space.n
q_table = np.zeros(NUM_BUCKETS + (NUM_ACTIONS,))In der CartPole-Umgebung ist der Zustandsraum kontinuierlich. Der Winkel, die Geschwindigkeit und die Position der Wagenstange können sich ständig ändern. Der Aktionsraum ist klar – du kannst den Wagen nach links oder rechts schieben.
Q-Learning mit Q-Tabellen kann nur in einem diskreten Raum verwendet werden, weil man den Q-Wert für eine Reihe von Zuständen und Aktionen explizit tabellarisch auflisten muss. Also, der erste Schritt ist, den kontinuierlichen Zustandsraum in diskrete Zustände zu zerlegen.
Zuerst schauen wir uns die oberen und unteren Grenzen der Zustandsraumvariablen an. Wir sehen, dass die Geschwindigkeit des Wagens und die Winkelgeschwindigkeit der Stange unendlich sind. Also haben wir künstlich obere und untere Grenzen für diese Zustandsvariablen festgelegt.
STATE_BOUNDS = list(zip(env.observation_space.low, env.observation_space.high))
STATE_BOUNDS[1] = [-0.5, 0.5]
STATE_BOUNDS[3] = [-math.radians(50), math.radians(50)]Wir machen eine Funktion, um die durchgehenden Zustandswerte in diskrete Werte zu zerlegen:
def discretize_state(state):
discrete_states = []
for i in range(len(state)):
if state[i] <= STATE_BOUNDS[i][0]:
discrete_state = 0
elif state[i] >= STATE_BOUNDS[i][1]:
discrete_state = NUM_BUCKETS[i] - 1
else:
bound_width = STATE_BOUNDS[i][1] - STATE_BOUNDS[i][0]
offset = (NUM_BUCKETS[i] - 1) * STATE_BOUNDS[i][0] / bound_width
scaling = (NUM_BUCKETS[i] - 1) / bound_width
discrete_state = int(round(scaling * state[i] - offset))
discrete_states.append(discrete_state)
return tuple(discrete_states)Die Bellman-Gleichungen zeigen, wie man die Q-Werte anhand der Lernrate, des Diskontsatzes, der Belohnung für den nächsten Schritt und des erwarteten maximalen Q-Werts des nächsten Zustands aktualisiert. Es drückt den erwarteten Wert eines Zustands als Summe zweier Teile aus:
Die Bellman-Gleichung ist rekursiv. So kann man ein Programm schreiben, das immer wieder von einem zufälligen Anfangszustand startet, um die beste Aktionswertfunktion zu finden.
Die Formel zum Aktualisieren der Q-Tabelle lautet:
![]()
In dem obigen Ausdruck:
state_current “ (Aktiv) bezeichnet.state_next).action).reward “. best_q. Der Code unten macht die Funktion zum Aktualisieren der Q-Tabelle klar.
def update_q(state_current, state_next, action, reward, alpha):
best_q = np.amax(q_table[state_next])
q_table[state_current + (action,)] += alpha * (reward + GAMMA*(best_q) - q_table[state_current + (action,)])
return best_qErkläre die Parameter des Trainings:
MAX_EPISODES = 5000
MAX_STEPS = 500
SUCCESS_STEPS = 450
SUCCESS_STREAK = 50Die Hyperparameter angeben:
EPSILON_MIN = 0.01
EPSILON_MAX = 1
ALPHA_MIN = 0.1
ALPHA_MAX = 0.5
GAMMA = 0.99
DECAY_COEFF = 25Bevor wir den Agenten trainieren, schreiben wir zwei Funktionen, um die Lernrate und die Erkundungsrate nach und nach zu verringern. Diese Hyperparameter werden im Laufe des Trainings immer kleiner.
def decay_epsilon(step):
return max(EPSILON_MIN, min(EPSILON_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))
def decay_alpha(step):
return max(ALPHA_MIN, min(ALPHA_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))Wir schreiben auch eine Funktion, um die Aktion zufällig auszuwählen. Zuerst machen wir eine Zufallszahl.
def select_action(state, epsilon):
if random.random() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state])
return actionWir bauen eine Schleife auf, um den Agenten anhand der folgenden Schritte zu trainieren:
select_action() “ aus. update_q() “. Der Code unten zeigt, wie die Trainingsschleife funktioniert:
def train():
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
state_current = state_next
if done:
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
print("=============SUCCESS=============")
else:
successful_episodes = 0
print("=============FAIL=============")
break
if successful_episodes > SUCCESS_STREAK:
breakZum Schluss startest du die Trainingsschleife, schließt die Umgebung und druckst den letzten Wert der Q-Tabelle aus.
train()
env.close()
print(q_table)Nutze diese DataLab-Arbeitsmappe als Ausgangspunkt, um den Code für Q-Learning zu bearbeiten und auszuführen.
Im vorherigen Abschnitt haben wir den kontinuierlichen (Zustands-)Beobachtungsraum diskretisiert, um eine Q-Tabelle zu verwenden. Eine große Q-Tabelle (für komplexe Umgebungen) ist rechnerisch ziemlich ineffizient. In solchen Fällen kann die Q-Funktion mit einem neuronalen Netzwerk angenähert werden. Das nennt man ein Deep Q-Netzwerk, ausgedrückt als Q(s, a; θ), wobei der Parameter θ die Gewichte des neuronalen Netzwerks darstellt. Diese Methode heißt Deep Q-Learning. Allgemeiner wird RL mit tiefen neuronalen Netzen als Deep Reinforcement Learning bezeichnet.
Anstatt die Q-Tabelle zu benutzen, um die Aktion für jeden Zustand zu wählen, nimmt das DQN-neuronale Netzwerk den Zustand als Input und gibt den Q-Wert für jede mögliche Aktion in diesem Zustand zurück.
Das Netzwerk wird mit klassischen Methoden (wie Backpropagation) trainiert, um den zeitlichen Differenzfehler (TD-Fehler) zu minimieren. Der TD-Fehler δ ist die Differenz zwischen den vorhergesagten Q-Werten und den Ziel-Q-Werten (berechnet als Summe der Belohnung aus dem aktuellen Zustand und dem diskontierten Wert der erwarteten maximalen Belohnung aus dem nächsten Zustand).
Wenn man das als neuronales Netzwerk (mit Netzwerkparametern θ) macht, sieht der TD-Fehler so aus:
![]()
Beachte, dass sowohl die Q-Werte als auch die Ziel-Q-Werte mit demselben neuronalen Netzwerk berechnet werden.
Bei jeder Wiederholung werden die Netzwerkparameter (θ) aktualisiert. Das Netzwerk-Update (über Backprop) basiert auf dem Zielwert, der mit dem vor dem Update berechneten θ ermittelt wurde. Berechnung der Zielwerte mit denselben aktualisierten Ergebnissen bei einem sich ständig bewegenden Ziel. Das macht das Training unsicher.
Um das oben genannte Problem zu vermeiden, erstellen wir ein neues Netzwerk, um die Ziel-Q-Werte zu berechnen. Das ist das Zielnetzwerk. Es basiert auf denselben Parametern wie das Politiknetzwerk, wird aber nicht so oft aktualisiert. So hat der Trainingsprozess ein klares Ziel, auf das die Rückwärtsausbreitung angewendet wird.
Wenn wir die Gewichte des Zielnetzwerks mit θ- darstellen, sieht die obige Gleichung so aus:
![]()
In den nächsten Abschnitten zeigen wir dir, wie du ein einfaches DQN in der CartPole-Umgebung umsetzt und trainierst.
Installier die benötigten Pakete, wie Gymnasium und PyTorch.
!pip install gymnasium matplotlib torchImportiere die benötigten Pakete in die Python-Umgebung:
import gymnasium as gym
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as FErstell die CartPole-Umgebung:
env = gym.make("CartPole-v1")Initialisiere die Umgebung und erkläre Python-Konstanten mit der Größe der Zustands- und Aktionsräume der Umgebung.
state, info = env.reset()
NUM_OBSERVATIONS = len(state)
NUM_ACTIONS = env.action_space.nDeklarier eine Python-Klasse für ein einfaches neuronales Netzwerk mit einer einzigen versteckten Schicht. Die Anzahl der Eingabeschichten ist die Größe des Zustandsraums (Beobachtungsraums). Die Anzahl der Ausgabeschichten ist die Anzahl der möglichen Aktionen, die der RL-Agent ausführen kann. Dieses Netzwerk simuliert intern die Q-Tabelle und sagt die Aktionswerte für einen bestimmten Eingabestatus voraus.
class DQN(nn.Module):
def __init__(self, NUM_OBSERVATIONS, NUM_ACTIONS):
super(DQN, self).__init__()
self.layer1 = nn.Linear(NUM_OBSERVATIONS, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, NUM_ACTIONS)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)Mach dir ein Netzwerk für deine Richtlinien und ein Zielnetzwerk. Lade das Zielnetzwerk mit den Parametern des Richtliniennetzwerks über das Statuswörterbuch. Starte einen Optimierer, um das neuronale Netzwerk zu trainieren.
policy_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)Off-Policy-Modellfreie RL-Methoden wie Q-Learning (im vorherigen Abschnitt besprochen) und DQNs werden mit einer zufälligen Auswahl der Interaktionen des Agenten mit der Umgebung trainiert. Die Aktionen des Agenten und die Reaktionen der Umgebung (Belohnung und nächster Zustand) werden gesammelt und gespeichert. In jeder Trainingsrunde wird eine zufällige Auswahl dieser Interaktionen genommen, um einen Trainingsstapel zu bilden.
Deklarier ein Tupel-Objekt, um den Zustand der Umgebung (Beobachtung) bei jeder Interaktion zu speichern:
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))Erstell eine Python-Klasse für den Wiedergabepuffer:
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)Erstell ein Speicherobjekt, um viele Interaktionen zu speichern. Diese Interaktionen werden benutzt, um den Agenten zu trainieren.
memory = ReplayMemory(10000)Vor dem Training musst du die Parameter und Hyperparameter angeben:
LR)GAMMA)TAU)EPS_START, EPS_END und EPS_DECAY)MAX_EPISODES = 600
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4Schreib eine Funktion, die die Aktion anhand der Erkundungsrate auswählt, und zwar so:
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
action = policy_net(state).max(1).indices.view(1, 1)
return action
else:
action = torch.tensor([[env.action_space.sample()]], dtype=torch.long)
return actionSchreib die Funktion, um das Modell anhand dieser Schritte zu optimieren:
non_final_mask), um die Zustände zu erkennen, auf die kein Endzustand folgt. non_final_next_states).![]()
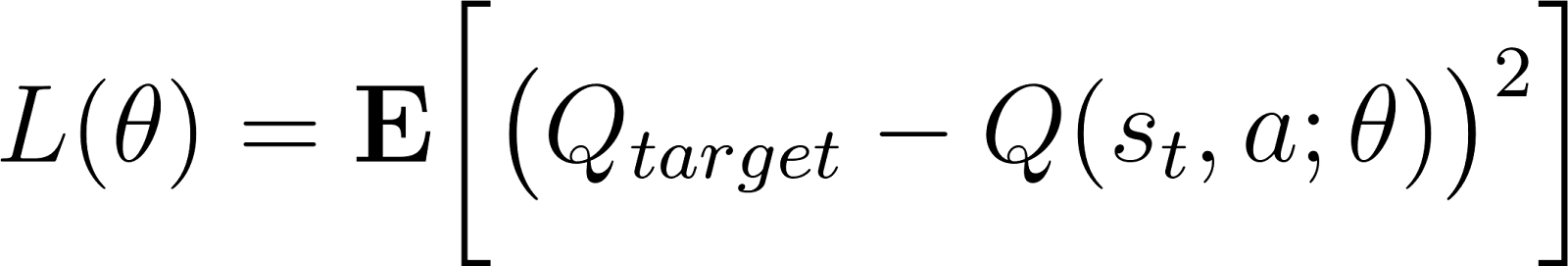
Der Code unten zeigt, wie man den Optimierer einsetzt:
batch = 0
def optimize_model():
global batch
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE )
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1).values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
loss_func = nn.SmoothL1Loss()
loss = loss_func(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)
optimizer.step()Schreib eine Trainingsschleife, um den Agenten zu trainieren:
select_action() “, um zu entscheiden, was der Agent machen soll.Der folgende Code macht das klar:
def train():
for episode in range(MAX_EPISODES):
# Initialize the environment and get its state
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
reward = torch.tensor([reward])
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32).unsqueeze(0)
memory.push(state, action, next_state, reward)
state = next_state
optimize_model()
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
print('count -- ', t)
#plot_durations()
breakMit dieser DataLab-Arbeitsmappe kannst du das DQN-Trainingsprogramm anzeigen, bearbeiten und ausführen.
Es ist hilfreich, den Fortschritt des Trainingsprozesses visuell auf einem Lernpfad zu verfolgen. Die Werte der Aktionen zu sehen, hilft dabei, zu erkennen, wo das Training nicht so gut läuft und welche Parameter oder Hyperparameter angepasst werden müssen.
Wenn du zum Beispiel siehst, dass das Modell nicht schnell genug besser wird, solltest du vielleicht die Lernrate erhöhen. Wenn du merkst, dass das Modell zwar lernt, aber noch nicht ganz fertig trainiert ist, kann es helfen, die Anzahl der Trainingseinheiten zu erhöhen. Wenn du merkst, dass das Training nicht so läuft, wie es soll, solltest du vielleicht die Lernrate runterdrehen oder den Erkundungskoeffizienten oder die Aktualisierungsrate des Zielnetzwerks anpassen (TAU).
Zusätzlich zu den Q-Werten kann es auch hilfreich sein, die Anzahl der erfolgreichen Schritte in jeder Episode aufzuzeichnen. Beim Q-Learning mit Q-Tabellen werden die Q-Werte explizit gespeichert. Bei der Verwendung von DQNs werden die Q-Werte aber nicht explizit gespeichert. Das Netzwerk gibt die Aktion je nach ihren Gewichten und dem Status aus. Deshalb kann es für DQN sinnvoller sein, die Anzahl der erfolgreichen Schritte in jeder Episode zu verfolgen.
Die folgenden Schritte zeigen, wie du die Q-Werte und die Anzahl der erfolgreichen Schritte pro Episode für das Training des Q-Learning-Algorithmus zeichnest:
q_vals - zum Speichern der Q-Werte in jedem Schritt jeder Episode. success_steps - zum Speichern der Anzahl der erfolgreichen Schritte in jeder Episode.q_vals “ hinzu.success_steps “ die Anzahl der erfolgreichen Schritte in dieser Episode hinzu. Der Code unten zeigt die Q-Learning-Trainingsschleife (mit Q-Tabellen) (siehe vorheriger Abschnitt), die aktualisiert wurde, um die Q-Werte und die Anzahl der erfolgreichen Schritte zu verfolgen:
q_vals = []
success_steps = []
def train():
global q_vals
global success_steps
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
q_vals.append(best_q)
state_current = state_next
if done:
q_vals.append(best_q)
success_steps.append(step)
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
else:
successful_episodes = 0
break
if successful_episodes > SUCCESS_STREAK:
print("Training successful")
returnDer folgende Ausschnitt zeigt, wie man die Q-Werte in jeder Episode darstellt:
def plot_q():
plt.plot(q_vals)
plt.title('Q-values over training steps')
plt.xlabel('Training steps')
plt.ylabel('Q-value')
plt.show()Der folgende Ausschnitt zeigt, wie du die Anzahl der erfolgreichen Schritte in jeder Episode zeichnest:
def plot_steps():
plt.plot(success_steps)
plt.title('Successful steps over training episodes')
plt.xlabel('Training episode')
plt.ylabel('Successful steps')
plt.show()Man muss festlegen, wann der Agent gut trainiert ist. Beim klassischen ML geht's beim Training darum, den Verlust zu minimieren, also den Unterschied zwischen den vorhergesagten und den echten Werten. In RL geht's darum, die Gesamtbelohnung so hoch wie möglich zu machen. Das Training gilt als erfolgreich, wenn der Agent die maximale Belohnung aus der Umgebung bekommt.
Umgebungen wie CartPole enden erst, wenn sie einen Endzustand erreichen, z. B. wenn sie an die Ränder stoßen oder sich der Cartpole zu stark neigt. In solchen Fällen kann ein geschulter Agent unbegrenzt mit der Umgebung interagieren. So wird die maximale Anzahl erfolgreicher Schritte künstlich begrenzt. Bei CartPole-v1 von Gymnasium wird die Episode beendet, wenn 500 Zeitschritte ohne Abbruch erreicht sind.
Wir checken, wie gut der Agent in aufeinanderfolgenden Episoden abschneidet, um zu sehen, ob das Training funktioniert. Zum Beispiel:
SUCCESS_STEPS) zu absolvieren. In den Beispielen in diesem Artikel haben wir diesen Schwellenwert auf 450 gesetzt. SUCCESS_STREAK). In diesem Beispiel setzen wir N auf 50. Schau dir als praktisches Beispiel diesen Ausschnitt aus der zuvor gezeigten DQN-Trainingsschleife an.
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
average_steps = sum(episode_durations[-SUCCESS_STREAK:])/SUCCESS_STREAK
print('average steps over last 50 episodes -- ', average_steps)
if average_steps > SUCCESS_STEPS:
print("training successful.")
return
breakEs ist hilfreich, die Leistung des Agenten anhand der folgenden Schritte am Ende (Endzustand) jeder Trainingseinheit zu bewerten:
SUCCESS_STREAK) gleich 50. Also, wir rechnen die durchschnittlichen Schritte der letzten 50 Folgen aus. SUCCESS_STEPS) liegt, beenden wir das Training. In diesem Beispiel ist der Schwellenwert auf 450 Schritte gesetzt. Hier sind ein paar Tipps, die du befolgen kannst, um mit deiner Action-Value-Funktion bessere Ergebnisse zu erzielen.
Mit der richtigen Aktionswertfunktion kann der Agent die erwarteten Erträge maximieren, indem er eine gierige Strategie verfolgt, bei der er in jedem Schritt die Aktion mit dem höchsten Wert wählt. Das nennt man Ausnutzung der verfügbaren Infos. Wenn man aber eine gierige Strategie mit einer ungetraineden Aktionswertfunktion (die noch nicht die echten Aktionswerte zeigt) benutzt, bleibt man in einem lokalen Optimum hängen.
Während des Trainings ist es wichtig, sowohl die Umgebung zu erkunden als auch die verfügbaren Infos zu nutzen.
In den ersten Phasen des Trainingsprozesses basieren die verfügbaren Infos auf einer Zufallswertfunktion. Daher sind diese Infos nicht besonders wertvoll (um sie mit einer gierigen Strategie zu nutzen). Es ist wichtiger, die Umgebung zu erkunden, um herauszufinden, was man mit verschiedenen Aktionen in unterschiedlichen Situationen erreichen kann.
Wenn die Q-Tabelle aktualisiert wird (oder das DQN trainiert wird), kann man die verfügbaren Infos teilweise nutzen, um die Belohnungen zu maximieren. Gegen Ende des Trainings nähert sich der Agent der echten Wertfunktion an; mehr zu suchen könnte schaden. Deshalb konzentriert sich der Agent darauf, die bekannte Wertfunktion zu nutzen.
Wie bei jedem maschinellen Lernmodell sind Hyperparameter wichtig, um RL-Algorithmen erfolgreich zu trainieren. Bei Q-Learning und DQNs sind die Hyperparameter Epsilon (Erkundungsrate), Alpha (Lernrate) und Gamma (Diskontierungsrate).
Zu guter Letzt solltest du wissen, dass RL-Training empfindlich auf anfängliche Zufallswerte reagiert. Wenn das Training nicht konvergiert, hilft es oft, einen anderen Zufallsstartwert zu verwenden oder das Training neu zu starten, damit es mit anderen zufälligen Anfangswerten beginnt.
Das Training von RL-Agenten für komplexe Umgebungen ist echt eine Herausforderung. Q-Funktionen werden in vielen verschiedenen Algorithmen verwendet, daher ist es wichtig, ein Gefühl dafür zu entwickeln, wie man Q-Learning-basierte RL-Agenten trainiert. Das geht am besten, indem du die Techniken erst mal in einfacheren Umgebungen wie CartPole ausprobierst, bevor du ähnliche Methoden in komplexeren Umgebungen anwendest.
Außerdem ist das Training in komplizierten Umgebungen teurer, sodass es günstiger ist, einfachere Umgebungen als Lernwerkzeug zu nutzen.
In diesem Artikel haben wir die grundlegenden theoretischen Prinzipien der Aktionswertfunktion und ihre Bedeutung in RL besprochen. Wir haben uns angesehen, wie Aktionswertfunktionen beim Q-Learning und Deep Q-Learning verwendet werden, und beide Methoden Schritt für Schritt in Python umgesetzt.
Um weiterzulernen, empfehle ich dirden Kurs „Deep Reinforcement Learning in Python ”.
Lerne mit diesen Kursen mehr über KI!
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
