
Cursus
Principes fondamentaux de l'apprentissage automatique en Python
16 h
Après avoir abordé les principes fondamentaux et les utilisations de la fonction action-valeur, je vais maintenant vous présenter les étapes nécessaires à sa mise en œuvre en Python.
Veuillez importer les paquets requis, y compris Gymnasium et NumPy :
import gymnasium as gym
import numpy as np
import math
import randomInitialisez un environnement RL à partir de Gymnasium. Dans cet article, nous entraînons un agent RL à résoudre l'environnement CartPole.
env = gym.make('CartPole-v1')L'espace d'observation CartPole comporte quatre états : la position du chariot, la vitesse du chariot, l'angle du poteau et la vitesse angulaire du poteau.
Dans cet exemple, nous nous concentrons uniquement sur les observations de l'angle polaire et de la vitesse angulaire polaire. Nous créons ainsi le tableau Q discret comme suit :
Le nombre de colonnes dépend de la taille de l'espace d'action, dans ce cas, 2.
NUM_BUCKETS = (1, 1, 6, 3)
NUM_ACTIONS = env.action_space.n
q_table = np.zeros(NUM_BUCKETS + (NUM_ACTIONS,))Dans l'environnement CartPole, l'espace d'état est continu. L'angle, la vitesse et la position du poteau du chariot peuvent varier en continu. L'espace d'action est discret : vous pouvez pousser le chariot vers la gauche ou vers la droite.
L'apprentissage par Q-tables ne peut être utilisé que dans un espace discret, car il est nécessaire de tabuler explicitement la valeur Q pour un ensemble d'états et d'actions. La première étape consiste donc à discrétiser l'espace d'états continus.
Nous examinons tout d'abord les limites supérieures et inférieures des variables de l'espace d'état. Nous remarquons que la vitesse du chariot et la vitesse angulaire du poteau ont des limites infinies. Nous avons donc fixé artificiellement des limites supérieures et inférieures pour ces variables d'état.
STATE_BOUNDS = list(zip(env.observation_space.low, env.observation_space.high))
STATE_BOUNDS[1] = [-0.5, 0.5]
STATE_BOUNDS[3] = [-math.radians(50), math.radians(50)]Nous créons une fonction pour discrétiser les valeurs d'état continues en valeurs discrètes :
def discretize_state(state):
discrete_states = []
for i in range(len(state)):
if state[i] <= STATE_BOUNDS[i][0]:
discrete_state = 0
elif state[i] >= STATE_BOUNDS[i][1]:
discrete_state = NUM_BUCKETS[i] - 1
else:
bound_width = STATE_BOUNDS[i][1] - STATE_BOUNDS[i][0]
offset = (NUM_BUCKETS[i] - 1) * STATE_BOUNDS[i][0] / bound_width
scaling = (NUM_BUCKETS[i] - 1) / bound_width
discrete_state = int(round(scaling * state[i] - offset))
discrete_states.append(discrete_state)
return tuple(discrete_states)Les équations de Bellman fournissent l'expression permettant de mettre à jour les valeurs Q en fonction du taux d'apprentissage, du taux d'actualisation, de la récompense obtenue à l'étape suivante et de la valeur Q maximale attendue de l'état suivant. Elle exprime la valeur attendue d'un état comme la somme de deux parties :
L'équation de Bellman est récursive. Il est donc possible d'écrire un programme itératif, à partir d'un état initial aléatoire, afin de trouver la fonction de valeur d'action optimale.
L'équation permettant de mettre à jour le tableau Q est la suivante :
![]()
Dans l'expression ci-dessus :
state_current e dans le code.state_next).action).reward. best_q. Le code ci-dessous implémente la fonction permettant de mettre à jour le tableau Q.
def update_q(state_current, state_next, action, reward, alpha):
best_q = np.amax(q_table[state_next])
q_table[state_current + (action,)] += alpha * (reward + GAMMA*(best_q) - q_table[state_current + (action,)])
return best_qDéclarez les paramètres de l'entraînement :
MAX_EPISODES = 5000
MAX_STEPS = 500
SUCCESS_STEPS = 450
SUCCESS_STREAK = 50Déclarez les hyperparamètres :
EPSILON_MIN = 0.01
EPSILON_MAX = 1
ALPHA_MIN = 0.1
ALPHA_MAX = 0.5
GAMMA = 0.99
DECAY_COEFF = 25Avant de former l'agent, nous écrivons deux fonctions pour réduire progressivement le taux d'apprentissage et le taux d'exploration. Ces hyperparamètres diminuent progressivement en valeur tout au long de l'entraînement.
def decay_epsilon(step):
return max(EPSILON_MIN, min(EPSILON_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))
def decay_alpha(step):
return max(ALPHA_MIN, min(ALPHA_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))Nous écrivons également une fonction pour sélectionner l'action de manière aléatoire. Nous générons tout d'abord un nombre aléatoire.
def select_action(state, epsilon):
if random.random() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state])
return actionNous construisons une boucle pour former l'agent en suivant les étapes suivantes :
select_action() déclarée précédemment. update_q() déclarée précédemment. Le code ci-dessous implémente les étapes de la boucle d'entraînement :
def train():
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
state_current = state_next
if done:
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
print("=============SUCCESS=============")
else:
successful_episodes = 0
print("=============FAIL=============")
break
if successful_episodes > SUCCESS_STREAK:
breakEnfin, exécutez la boucle d'apprentissage, fermez l'environnement et affichez la valeur finale du tableau Q.
train()
env.close()
print(q_table)Veuillez utiliser ce classeur DataLab comme point de départ pour modifier et exécuter le code pour l'apprentissage par Q.
Dans la section précédente, nous avons discrétisé l'espace d'observation continu (état) afin d'utiliser un tableau Q. Un grand tableau Q (pour les environnements complexes) est inefficace sur le plan informatique. Dans de tels cas, la fonction Q peut être approximée à l'aide d'un réseau neuronal. Ceci est appelé un réseau Q profond, exprimé sous la forme Q(s, a ; θ), où le paramètre θ représente les poids du réseau neuronal. Cette méthode est appelée apprentissage profond par Q. De manière plus générale, l'apprentissage par renforcement utilisant des réseaux neuronaux profonds est appelé apprentissage par renforcement profond.
Au lieu d'utiliser le tableau Q pour choisir l'action pour chaque état, le réseau neuronal DQN prend l'état comme entrée et renvoie la valeur Q pour chaque action possible dans cet état.
Le réseau est formé à l'aide de méthodes traditionnelles (telles que la rétropropagation) afin de minimiser l'erreur de différence temporelle (TD). L'erreur TD δ correspond à la différence entre les valeurs Q prédites et les valeurs Q cibles (calculée comme la somme de la récompense de l'état actuel et de la valeur actualisée de la récompense maximale attendue de l'état suivant).
Lorsqu'elle est mise en œuvre sous forme de réseau neuronal (avec des paramètres de réseau θ), l'erreur TD s'exprime comme suit :
![]()
Veuillez noter que les valeurs Q et les valeurs Q cibles sont calculées à l'aide du même réseau neuronal.
À chaque itération, les paramètres du réseau (θ) sont mis à jour. La mise à jour du réseau (via rétropropagation) est basée sur la valeur cible calculée à l'aide du θ pré-mise à jour. Calcul des valeurs cibles avec les mêmes résultats actualisés dans une cible en mouvement continu. Cela rend l'entraînement instable.
Pour éviter ce problème, nous créons un nouveau réseau afin de calculer les valeurs Q cibles. Il s'agit du réseau cible. Il repose sur les mêmes paramètres que le réseau de politiques, mais il est mis à jour moins fréquemment. Ainsi, le processus d'apprentissage dispose d'un objectif stable par rapport auquel il applique la rétropropagation.
Si nous représentons les poids du réseau cible par θ-, l'équation précédente peut être reformulée comme suit :
![]()
Les sections suivantes montrent comment implémenter et entraîner un DQN simple dans l'environnement CartPole.
Veuillez installer les paquets requis, y compris Gymnasium et PyTorch.
!pip install gymnasium matplotlib torchImportez les paquets nécessaires dans l'environnement Python :
import gymnasium as gym
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as FVeuillez créer l'environnement CartPole :
env = gym.make("CartPole-v1")Initialisez l'environnement et déclarez les constantes Python avec la taille des espaces d'état et d'action de l'environnement.
state, info = env.reset()
NUM_OBSERVATIONS = len(state)
NUM_ACTIONS = env.action_space.nDéclarez une classe Python pour un réseau neuronal simple avec une seule couche cachée. Le nombre de couches d'entrée correspond à la taille de l'espace d'état (espace d'observation). Le nombre de couches de sortie correspond au nombre d'actions possibles que l'agent RL peut effectuer. Ce réseau simule en interne le tableau Q et prédit les valeurs d'action données pour un état d'entrée.
class DQN(nn.Module):
def __init__(self, NUM_OBSERVATIONS, NUM_ACTIONS):
super(DQN, self).__init__()
self.layer1 = nn.Linear(NUM_OBSERVATIONS, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, NUM_ACTIONS)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)Élaborez un réseau de politiques et un réseau cible. Chargez le réseau cible avec les paramètres du réseau de politiques à l'aide du dictionnaire d'états. Initialisez un optimiseur pour entraîner le réseau neuronal.
policy_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)Les méthodes d'apprentissage par renforcement sans modèle hors politique, telles que l'apprentissage par Q (abordé dans la section précédente) et les DQN, sont entraînées à l'aide d'un échantillon aléatoire des interactions de l'agent avec l'environnement. Les actions de l'agent et les réponses de l'environnement (récompense et état suivant) sont collectées et stockées. Un échantillon aléatoire de ces interactions est sélectionné à chaque itération de l'entraînement afin de former un lot d'entraînement.
Déclarez un objet tuple pour stocker l'état de l'environnement (observation) dans chaque interaction :
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))Créez une classe Python pour le tampon de relecture :
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)Créez un objet mémoire pour stocker un grand nombre d'interactions. Ces interactions sont utilisées pour former l'agent.
memory = ReplayMemory(10000)Avant l'entraînement, veuillez déclarer les paramètres et les hyperparamètres :
LR)GAMMA)TAU)EPS_START, EPS_END et EPS_DECAY)MAX_EPISODES = 600
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4Écrivez une fonction permettant de sélectionner l'action en fonction du taux d'exploration, en suivant les étapes suivantes :
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
action = policy_net(state).max(1).indices.view(1, 1)
return action
else:
action = torch.tensor([[env.action_space.sample()]], dtype=torch.long)
return actionÉcrivez la fonction permettant d'optimiser le modèle en suivant ces étapes :
non_final_mask) pour identifier les états qui ne sont pas suivis d'un état terminal. non_final_next_states).![]()
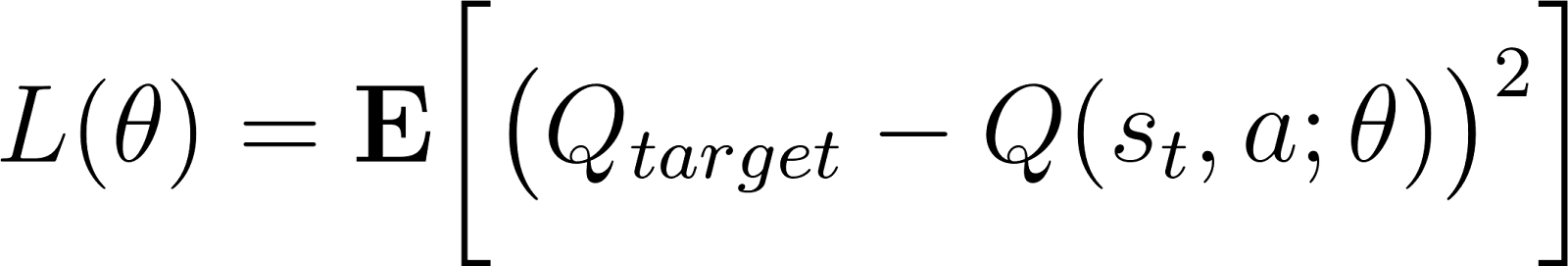
Le code ci-dessous montre comment implémenter l'optimiseur :
batch = 0
def optimize_model():
global batch
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE )
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1).values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
loss_func = nn.SmoothL1Loss()
loss = loss_func(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)
optimizer.step()Écrivez une boucle d'entraînement pour former l'agent :
select_action() » pour déterminer l'action de l'agent.Le code suivant met en œuvre ces étapes :
def train():
for episode in range(MAX_EPISODES):
# Initialize the environment and get its state
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
reward = torch.tensor([reward])
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32).unsqueeze(0)
memory.push(state, action, next_state, reward)
state = next_state
optimize_model()
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
print('count -- ', t)
#plot_durations()
breakVous pouvez afficher, modifier et exécuter le programme de formation DQN à l'aide de ce classeur DataLab.
Il est utile de suivre visuellement la progression du processus de formation. La visualisation des valeurs d'action permet d'identifier les lacunes de la formation et les paramètres ou hyperparamètres à modifier.
Par exemple, si vous constatez visuellement que l'amélioration des performances du modèle est trop lente, vous pouvez augmenter le taux d'apprentissage. Si vous remarquez que le modèle apprend mais n'est pas encore entièrement formé, il peut être utile d'augmenter le nombre d'épisodes d'entraînement. Si vous constatez que l'entraînement est instable, vous pouvez réduire le taux d'apprentissage ou ajuster le coefficient d'exploration ou le taux de mise à jour du réseau cible (TAU).
En plus des valeurs Q, il peut également être utile de représenter graphiquement le nombre d'étapes réussies dans chaque épisode. Dans l'apprentissage par Q utilisant des tables Q, les valeurs Q sont explicitement stockées. Cependant, lors de l'utilisation des DQN, les valeurs Q ne sont pas explicitement enregistrées. Le réseau génère l'action en fonction de ses poids et de l'état. Ainsi, le suivi du nombre d'étapes réussies dans chaque épisode peut être plus significatif pour le DQN.
Les étapes suivantes décrivent comment représenter graphiquement les valeurs Q et le nombre d'étapes réussies par épisode pour l'entraînement de l'algorithme d'apprentissage Q :
q_vals - pour stocker les valeurs Q à chaque étape de chaque épisode. success_steps - pour enregistrer le nombre d'étapes réussies dans chaque épisode.q_vals.success_steps s le nombre d'étapes réussies dans cet épisode. Le code ci-dessous montre la boucle d'apprentissage Q-Learning (utilisant des tableaux Q) (illustrée dans la section précédente) mise à jour pour suivre les valeurs Q et le nombre d'étapes réussies :
q_vals = []
success_steps = []
def train():
global q_vals
global success_steps
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
q_vals.append(best_q)
state_current = state_next
if done:
q_vals.append(best_q)
success_steps.append(step)
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
else:
successful_episodes = 0
break
if successful_episodes > SUCCESS_STREAK:
print("Training successful")
returnL'extrait ci-dessous montre comment représenter graphiquement les valeurs Q dans chaque épisode :
def plot_q():
plt.plot(q_vals)
plt.title('Q-values over training steps')
plt.xlabel('Training steps')
plt.ylabel('Q-value')
plt.show()L'extrait suivant montre comment représenter graphiquement le nombre d'étapes réussies dans chaque épisode :
def plot_steps():
plt.plot(success_steps)
plt.title('Successful steps over training episodes')
plt.xlabel('Training episode')
plt.ylabel('Successful steps')
plt.show()Il est nécessaire de préciser les critères permettant de déterminer si et quand l'agent a été formé avec succès. Dans le ML traditionnel, l'objectif de l'entraînement est de minimiser la perte : la différence entre les valeurs prédites et les valeurs réelles. Dans RL, l'objectif est de maximiser la récompense cumulative. La formation est considérée comme réussie lorsque l'agent obtient le maximum de récompenses de l'environnement.
Les environnements tels que CartPole ne se terminent pas avant d'atteindre une condition terminale, comme heurter les bords ou permettre au chariot de s'incliner excessivement. Dans de tels cas, un agent qualifié peut continuer à interagir avec l'environnement indéfiniment. Ainsi, le nombre maximal de pas réussis est imposé artificiellement. Dans le cas du CartPole-v1 de Gymnasium, l'épisode se termine lorsqu'il atteint 500 étapes sans s'arrêter.
Nous évaluons les performances de l'agent au cours d'épisodes consécutifs afin de déterminer si la formation est efficace. Par exemple :
SUCCESS_STEPS) au cours des N derniers épisodes. Dans les exemples présentés dans cet article, nous avons défini ce seuil à 450. SUCCESS_STREAK). Dans cet exemple, nous avons défini N à 50. À titre d'exemple pratique, considérons cet extrait de la boucle d'entraînement DQN présentée précédemment.
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
average_steps = sum(episode_durations[-SUCCESS_STREAK:])/SUCCESS_STREAK
print('average steps over last 50 episodes -- ', average_steps)
if average_steps > SUCCESS_STEPS:
print("training successful.")
return
breakIl est utile d'évaluer les performances de l'agent en fonction de l'exécution des étapes suivantes à la fin (état terminal) de chaque épisode d'entraînement :
SUCCESS_STREAK) est égal à 50. Nous calculons donc la moyenne des étapes parcourues au cours des 50 derniers épisodes. SUCCESS_STEPS), nous mettons fin à l'entraînement. Dans cet exemple, ce seuil est fixé à 450 pas. Voici quelques bonnes pratiques que vous pouvez suivre pour obtenir de meilleurs résultats lors de la mise en œuvre de votre fonction de valeur d'action.
Compte tenu de la fonction de valeur d'action réelle, l'agent peut maximiser les rendements attendus en adoptant une stratégie avide, basée sur le choix de l'action ayant la valeur la plus élevée à chaque étape. Ceci est appelé « exploitation des informations disponibles ». Cependant, l'utilisation d'une stratégie avide avec une fonction de valeur d'action non entraînée (qui ne représente pas encore les valeurs d'action réelles) conduira à rester bloqué dans un optimum local.
Au cours de la formation, il est important d'explorer l'environnement et d'exploiter les informations disponibles.
Au début du processus de formation, les informations disponibles sont basées sur une fonction de valeur aléatoire. Par conséquent, ces informations ne sont pas très utiles (à exploiter avec une stratégie avide). Il est plus important d'explorer l'environnement afin de découvrir les avantages de différentes actions possibles dans différents états.
Au fur et à mesure que le tableau Q est mis à jour (ou que le DQN est entraîné), il devient possible d'exploiter partiellement les informations disponibles afin de maximiser les récompenses. Vers la fin de la formation, l'agent converge vers la fonction de valeur réelle ; toute exploration supplémentaire peut être préjudiciable. Par conséquent, l'agent privilégie l'exploitation de la fonction de valeur connue.
Comme pour tout modèle d'apprentissage automatique, les hyperparamètres sont essentiels à la réussite de l'entraînement des algorithmes RL. Dans le cas du Q-Learning et des DQN, les hyperparamètres sont epsilon (taux d'exploration), alpha (taux d'apprentissage) et gamma (taux d'actualisation).
Enfin, il est important de comprendre que l'entraînement RL est sensible aux valeurs aléatoires initiales. Si l'entraînement ne converge pas, il est souvent utile d'utiliser une graine aléatoire différente ou de relancer l'entraînement afin qu'il commence avec un ensemble différent de valeurs initiales aléatoires.
La formation d'agents RL pour des environnements complexes représente un défi. Les fonctions Q sont utilisées dans de nombreux algorithmes différents. Il est donc essentiel de développer une certaine intuition pour former des agents RL basés sur l'apprentissage Q. Il est préférable de s'exercer à ces techniques dans des environnements plus simples, tels que CartPole, avant d'appliquer des méthodes similaires à des environnements plus complexes.
De plus, les environnements complexes sont plus coûteux à former, il est donc plus économique d'utiliser des environnements plus simples comme outil d'apprentissage.
Cet article a abordé les principes théoriques fondamentaux de la fonction de valeur d'action et son importance dans l'apprentissage par renforcement. Nous avons abordé l'utilisation des fonctions de valeur d'action dans l'apprentissage Q et l'apprentissage Q profond, et avons implémenté ces deux méthodes étape par étape en Python.
Pour approfondir vos connaissances, je vous recommande vivementle cours Deep Reinforcement Learning in Python.
Apprenez-en davantage sur l'IA grâce à ces cours !
Cursus
Cours
Cours