
Programa
Fundamentos de machine learning Em Python
16 h
Depois de falar sobre os princípios básicos e os usos da função valor-ação, agora vou mostrar os passos para implementá-la em Python.
Importa os pacotes necessários, incluindo Gymnasium e NumPy:
import gymnasium as gym
import numpy as np
import math
import randomInicialize um ambiente RL a partir do Gymnasium. Neste artigo, a gente treina um agente RL pra resolver o ambiente CartPole.
env = gym.make('CartPole-v1')O espaço de observação do CartPole tem quatro estados: posição do carrinho, velocidade do carrinho, ângulo do poste e velocidade angular do poste.
Neste exemplo, vamos focar só nas observações do ângulo do polo e da velocidade angular do polo. Assim, criamos a tabela Q discreta da seguinte forma:
O número de colunas depende do tamanho do espaço de ação, que aqui é 2.
NUM_BUCKETS = (1, 1, 6, 3)
NUM_ACTIONS = env.action_space.n
q_table = np.zeros(NUM_BUCKETS + (NUM_ACTIONS,))No ambiente CartPole, o espaço de estado é contínuo. O ângulo, a velocidade e a posição do poste do carrinho podem mudar o tempo todo. O espaço de ação é discreto - você pode empurrar o carrinho para a esquerda ou para a direita.
O Q-Learning usando tabelas Q só pode ser usado em um espaço discreto, porque você precisa tabular explicitamente o valor Q para um conjunto de estados e ações. Então, o primeiro passo é discretizar o espaço de estado contínuo.
Primeiro, vamos pensar nos limites superior e inferior das variáveis do espaço de estado. A gente percebe que a velocidade do carrinho e a velocidade angular do poste não têm limites. Então, a gente definiu limites superiores e inferiores artificiais para essas variáveis de estado.
STATE_BOUNDS = list(zip(env.observation_space.low, env.observation_space.high))
STATE_BOUNDS[1] = [-0.5, 0.5]
STATE_BOUNDS[3] = [-math.radians(50), math.radians(50)]Criamos uma função para discretizar os valores contínuos do estado em valores discretos:
def discretize_state(state):
discrete_states = []
for i in range(len(state)):
if state[i] <= STATE_BOUNDS[i][0]:
discrete_state = 0
elif state[i] >= STATE_BOUNDS[i][1]:
discrete_state = NUM_BUCKETS[i] - 1
else:
bound_width = STATE_BOUNDS[i][1] - STATE_BOUNDS[i][0]
offset = (NUM_BUCKETS[i] - 1) * STATE_BOUNDS[i][0] / bound_width
scaling = (NUM_BUCKETS[i] - 1) / bound_width
discrete_state = int(round(scaling * state[i] - offset))
discrete_states.append(discrete_state)
return tuple(discrete_states)As equações de Bellman mostram como atualizar os valores Q com base na taxa de aprendizagem, na taxa de desconto, na recompensa que vai para a próxima etapa e no valor Q máximo esperado do próximo estado. É o valor esperado de um estado como a soma de duas partes:
A equação de Bellman é recursiva. Assim, dá pra escrever um programa iterativo, começando de um estado inicial aleatório, pra achar a função de valor de ação ideal.
A equação para atualizar a tabela Q é:
![]()
Na expressão acima:
state_current ” no código.state_next).action).reward. best_q. O código abaixo implementa a função para atualizar a tabela Q.
def update_q(state_current, state_next, action, reward, alpha):
best_q = np.amax(q_table[state_next])
q_table[state_current + (action,)] += alpha * (reward + GAMMA*(best_q) - q_table[state_current + (action,)])
return best_qDeclara os parâmetros do treinamento:
MAX_EPISODES = 5000
MAX_STEPS = 500
SUCCESS_STEPS = 450
SUCCESS_STREAK = 50Declara os hiperparâmetros:
EPSILON_MIN = 0.01
EPSILON_MAX = 1
ALPHA_MIN = 0.1
ALPHA_MAX = 0.5
GAMMA = 0.99
DECAY_COEFF = 25Antes de treinar o agente, a gente escreve duas funções pra diminuir a taxa de aprendizado e a taxa de exploração aos poucos. Esses hiperparâmetros diminuem de valor gradualmente ao longo do treinamento.
def decay_epsilon(step):
return max(EPSILON_MIN, min(EPSILON_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))
def decay_alpha(step):
return max(ALPHA_MIN, min(ALPHA_MAX, 1.0-math.log10((step+1)/DECAY_COEFF)))Também criamos uma função pra escolher a ação de forma aleatória. Primeiro, a gente gera um número aleatório.
def select_action(state, epsilon):
if random.random() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state])
return actionA gente cria um loop pra treinar o agente seguindo esses passos:
select_action() que falamos antes. update_q() declarada anteriormente. O código abaixo mostra como funciona o loop de treinamento:
def train():
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
state_current = state_next
if done:
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
print("=============SUCCESS=============")
else:
successful_episodes = 0
print("=============FAIL=============")
break
if successful_episodes > SUCCESS_STREAK:
breakPor fim, execute o loop de treinamento, feche o ambiente e imprima o valor final da tabela Q.
train()
env.close()
print(q_table)Use esta pasta de trabalho do DataLab como ponto de partida para editar e executar o código para o Q-Learning.
Na seção anterior, a gente discretizou o espaço de observação contínuo (estado) pra usar uma tabela Q. Uma tabela Q grande (para ambientes complexos) é ineficiente em termos computacionais. Nesses casos, a função Q pode ser aproximada usando uma rede neural. Isso é chamado de Deep Q-Network, que é tipo um Q(s, a; θ), onde o parâmetro θ representa os pesos da rede neural. Esse método é chamado de Deep Q-learning. De um jeito mais geral, RL usando redes neurais profundas é chamado de Aprendizado por Reforço Profundo.
Em vez de usar a Tabela Q para escolher a ação para cada estado, a rede neural DQN pega o estado como entrada e mostra o valor Q para cada ação possível nesse estado.
A rede é treinada usando métodos tradicionais (como retropropagação) para minimizar o erro de diferença temporal (TD). O erro TD δ é a diferença entre os valores Q previstos e os valores Q alvo (calculados como a soma da recompensa do estado atual e o valor descontado da recompensa máxima esperada do próximo estado).
Quando implementado como uma rede neural (com parâmetros de rede θ), o erro TD é expresso como:
![]()
Observe que tanto os valores Q quanto os valores Q alvo são calculados usando a mesma rede neural.
Em cada repetição, os parâmetros da rede (θ) são atualizados. A atualização da rede (via backprop) é baseada no valor alvo calculado usando o θ pré-atualização. Calcular os valores alvo com os mesmos resultados atualizados em um alvo em movimento contínuo. Isso deixa o treino meio instável.
Para evitar o problema acima, criamos uma nova rede para calcular os valores Q desejados. Essa é a rede que a gente quer. É baseada nos mesmos parâmetros da rede de políticas, mas é atualizada com menos frequência. Então, o processo de treinamento tem um objetivo fixo em relação ao qual aplica a retropropagação.
Se representarmos os pesos da rede alvo com θ-, a equação anterior é reescrita como:
![]()
As seções a seguir mostram como implementar e treinar um DQN simples no ambiente CartPole.
Instale os pacotes necessários, incluindo Gymnasium e PyTorch.
!pip install gymnasium matplotlib torchImporta os pacotes necessários no ambiente Python:
import gymnasium as gym
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as FCrie o ambiente CartPole:
env = gym.make("CartPole-v1")Inicialize o ambiente e declare as constantes Python com o tamanho dos espaços de estado e ação do ambiente.
state, info = env.reset()
NUM_OBSERVATIONS = len(state)
NUM_ACTIONS = env.action_space.nDeclare uma classe Python para uma rede neural simples com uma única camada oculta. O número de camadas de entrada é o tamanho do espaço de estado (espaço de observação). O número de camadas de saída é o número de ações possíveis que o agente RL pode realizar. Essa rede simula internamente a tabela Q e prevê os valores de ação para um estado de entrada.
class DQN(nn.Module):
def __init__(self, NUM_OBSERVATIONS, NUM_ACTIONS):
super(DQN, self).__init__()
self.layer1 = nn.Linear(NUM_OBSERVATIONS, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, NUM_ACTIONS)
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)Crie uma rede de políticas e uma rede de metas. Carregue a rede de destino com os parâmetros da rede de políticas usando o dicionário de estados. Inicialize um otimizador para treinar a rede neural.
policy_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net = DQN(NUM_OBSERVATIONS, NUM_ACTIONS)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)Os métodos RL sem modelo fora da política, como Q-Learning (falado na seção anterior) e DQNs, são treinados usando uma amostra aleatória das interações do agente com o ambiente. As ações do agente e as respostas do ambiente (recompensa e próximo estado) são coletadas e armazenadas. Uma amostra aleatória dessas interações é escolhida em cada iteração do treinamento para formar um lote de treinamento.
Declare um objeto tupla para guardar o estado do ambiente (observação) em cada interação:
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))Crie uma classe Python para o buffer de reprodução:
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)Crie um objeto de memória pra guardar um monte de interações. Essas interações são usadas para treinar o agente.
memory = ReplayMemory(10000)Antes de treinar, declare os parâmetros e hiperparâmetros:
LR)GAMMA)TAU)EPS_START, EPS_END e EPS_DECAY)MAX_EPISODES = 600
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4Escreva uma função para escolher a ação com base na taxa de exploração, seguindo esses passos:
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
action = policy_net(state).max(1).indices.view(1, 1)
return action
else:
action = torch.tensor([[env.action_space.sample()]], dtype=torch.long)
return actionEscreva a função para otimizar o modelo com base nessas etapas:
non_final_mask) pra identificar os estados que não são seguidos por um estado terminal. non_final_next_states).![]()
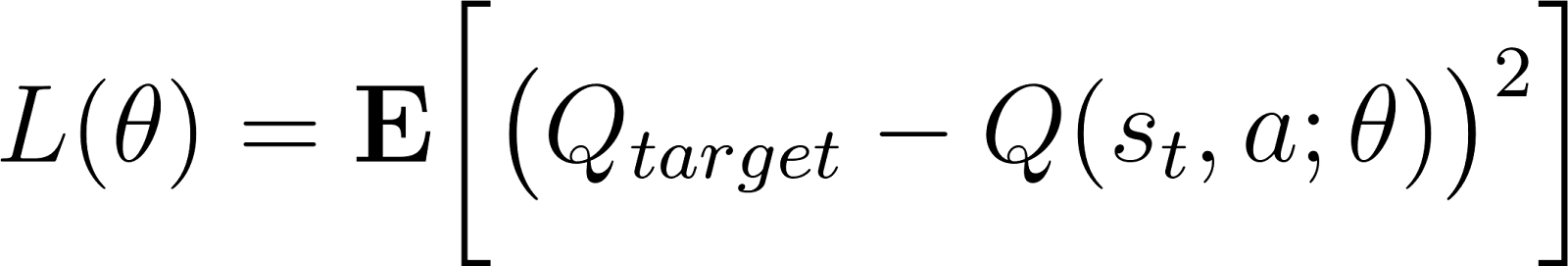
O código abaixo mostra como implementar o otimizador:
batch = 0
def optimize_model():
global batch
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE )
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1).values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
loss_func = nn.SmoothL1Loss()
loss = loss_func(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)
optimizer.step()Escreva um loop de treinamento para treinar o agente:
select_action() para decidir o que o agente vai fazer.O código a seguir implementa essas etapas:
def train():
for episode in range(MAX_EPISODES):
# Initialize the environment and get its state
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
reward = torch.tensor([reward])
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32).unsqueeze(0)
memory.push(state, action, next_state, reward)
state = next_state
optimize_model()
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
print('count -- ', t)
#plot_durations()
breakVocê pode ver, editar e rodar o programa de treinamento DQN usando essa pasta de trabalho do DataLab.
É legal acompanhar visualmente o progresso do treinamento. Visualizar os valores da ação ajuda a ver onde o treinamento está falhando e quais parâmetros ou hiperparâmetros precisam ser alterados.
Por exemplo, se você perceber que o modelo está demorando muito pra melhorar, pode ser uma boa ideia aumentar a taxa de aprendizado. Se você perceber que o modelo está aprendendo, mas ainda não foi totalmente treinado, pode ser uma boa ideia aumentar o número de episódios de treinamento. Se você achar que o treinamento está instável, pode ser uma boa ideia reduzir a taxa de aprendizagem ou ajustar o coeficiente de exploração ou a taxa de atualização da rede de destino (TAU).
Além dos valores Q, também pode ser útil traçar o número de etapas bem-sucedidas em cada episódio. No Q-Learning usando tabelas Q, os valores Q são guardados explicitamente. Mas, quando usamos DQNs, os valores Q não ficam guardados de forma explícita. A rede mostra a ação dependendo dos pesos e do estado. Então, acompanhar o número de etapas bem-sucedidas em cada episódio pode ser mais útil para o DQN.
Os passos a seguir mostram como plotar os valores Q e o número de passos bem-sucedidos por episódio para treinar o algoritmo de aprendizado Q:
q_vals - pra guardar os valores Q em cada etapa de cada episódio. success_steps - pra guardar o número de passos que deram certo em cada episódio.q_vals.success_steps ” o número de etapas bem-sucedidas nesse episódio. O código abaixo mostra o loop de treinamento do Q-Learning (usando tabelas Q) (mostrado na seção anterior) atualizado para acompanhar os valores Q e o número de etapas bem-sucedidas:
q_vals = []
success_steps = []
def train():
global q_vals
global success_steps
successful_episodes = 0
for episode in range(MAX_EPISODES):
epsilon = decay_epsilon(episode)
alpha = decay_alpha(episode)
observation, _ = env.reset()
state_current = discretize_state(observation)
for step in range(MAX_STEPS):
action = select_action(state_current, epsilon)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state_next = discretize_state(observation)
best_q = update_q(state_current, state_next, action, reward, alpha)
q_vals.append(best_q)
state_current = state_next
if done:
q_vals.append(best_q)
success_steps.append(step)
print("Episode %d finished after %d time steps" % (episode, step))
print("best q value: %f" % (float(best_q)))
if (step >= SUCCESS_STEPS):
successful_episodes += 1
else:
successful_episodes = 0
break
if successful_episodes > SUCCESS_STREAK:
print("Training successful")
returnO trecho abaixo mostra como plotar os valores Q em cada episódio:
def plot_q():
plt.plot(q_vals)
plt.title('Q-values over training steps')
plt.xlabel('Training steps')
plt.ylabel('Q-value')
plt.show()O trecho a seguir mostra como plotar o número de etapas bem-sucedidas em cada episódio:
def plot_steps():
plt.plot(success_steps)
plt.title('Successful steps over training episodes')
plt.xlabel('Training episode')
plt.ylabel('Successful steps')
plt.show()É preciso definir os critérios para saber se e quando o agente foi treinado com sucesso. No aprendizado de máquina tradicional, o objetivo do treinamento é minimizar a perda: a diferença entre os valores previstos e os valores reais. Na RL, o objetivo é maximizar a recompensa acumulada. O treinamento é considerado bem-sucedido quando o agente consegue o máximo de recompensas do ambiente.
Ambientes como o CartPole não acabam até chegarem a uma condição final, tipo bater nas bordas ou deixar o cartpole inclinar demais. Nesses casos, um agente treinado pode continuar interagindo com o ambiente por tempo ilimitado. Então, o número máximo de passos que dá certo é meio que imposto de um jeito artificial. No caso do CartPole-v1 do Gymnasium, o episódio termina quando chega a 500 passos de tempo sem terminar.
A gente avalia o desempenho do agente em episódios seguidos pra ver se o treinamento deu certo. Por exemplo:
SUCCESS_STEPS) em média nos últimos N episódios. Nos exemplos deste artigo, definimos esse limite em 450. SUCCESS_STREAK). Neste exemplo, definimos N como 50. Como exemplo prático, dá uma olhada nesse trecho do loop de treinamento DQN que mostramos antes.
if done:
episode_durations.append(t + 1)
print('episode -- ', episode)
average_steps = sum(episode_durations[-SUCCESS_STREAK:])/SUCCESS_STREAK
print('average steps over last 50 episodes -- ', average_steps)
if average_steps > SUCCESS_STEPS:
print("training successful.")
return
breakIsso ajuda a avaliar o desempenho do agente com base na execução das seguintes etapas no final (estado terminal) de cada episódio de treinamento:
SUCCESS_STREAK) é 50. Então, a gente calcula a média de passos nos últimos 50 episódios. SUCCESS_STEPS), a gente encerra o treinamento. Neste exemplo, esse limite está definido em 450 passos. Aqui estão algumas dicas que você pode seguir pra ter melhores resultados com a implementação da função valor-ação.
Com a função de valor de ação real, o agente pode maximizar os retornos esperados usando uma estratégia gananciosa, que é escolher a ação com o maior valor em cada etapa. Isso é chamado de exploração das informações disponíveis. Mas, usar uma estratégia gananciosa com uma função de valor de ação não treinada (que ainda não representa os valores de ação reais) vai fazer com que a gente fique preso em um ótimo local.
Durante o treinamento, é importante tanto explorar o ambiente quanto usar as informações disponíveis.
Nas primeiras etapas do processo de treinamento, as informações disponíveis são baseadas em uma função de valor aleatório. Então, essa informação não é muito valiosa (para usar com uma estratégia gananciosa). É mais importante explorar o ambiente para descobrir as recompensas de várias ações possíveis em diferentes situações.
À medida que a tabela Q é atualizada (ou o DQN é treinado), torna-se possível usar parcialmente as informações disponíveis para maximizar as recompensas. Nas fases finais do treinamento, o agente converge para a função de valor real; explorar mais pode ser ruim. Então, o agente prioriza explorar a função de valor conhecida.
Como em qualquer modelo de machine learning, os hiperparâmetros são importantes para treinar algoritmos de RL com sucesso. No caso do Q-Learning e das DQNs, os hiperparâmetros são epsilon (taxa de exploração), alfa (taxa de aprendizagem) e gama (taxa de desconto).
Por fim, entenda que o treinamento RL é sensível aos valores aleatórios iniciais. Se o treinamento não convergir, muitas vezes é útil usar uma semente aleatória diferente ou refazer o treinamento para que ele comece com um conjunto diferente de valores iniciais aleatórios.
Treinar agentes RL para ambientes complexos é um desafio. As funções Q são usadas em vários algoritmos diferentes, então é essencial ter uma boa intuição pra treinar agentes RL baseados em Q-learning. A melhor maneira de fazer isso é praticando as técnicas em ambientes mais simples, como CartPole, antes de tentar métodos parecidos em ambientes mais complexos.
Além disso, ambientes complexos são mais caros para treinar, então é mais econômico usar ambientes mais simples como ferramenta de aprendizagem.
Esse artigo falou sobre os princípios teóricos básicos da função de valor de ação e sua importância na RL. A gente falou sobre como as funções de valor de ação são usadas no Q-learning e no Deep Q-learning e implementou esses dois métodos passo a passo em Python.
Para continuar aprendendo, recomendo muitoo curso Deep Reinforcement Learning em Python.
Aprenda mais sobre IA com esses cursos!
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Thushan Ganegedara
Tutorial
Moez Ali

