
Course
Building AI Agents with Google ADK
1 hr
6.5K
Corrective retrieval-augmented generation (CRAG) is an improved version of RAG that aims to make language models more accurate.
While traditional RAG simply uses retrieved documents to help generate text, CRAG takes it a step further by actively checking and refining these documents to ensure they are relevant and accurate. This helps reduce errors or hallucinations where the model might produce incorrect or misleading information.
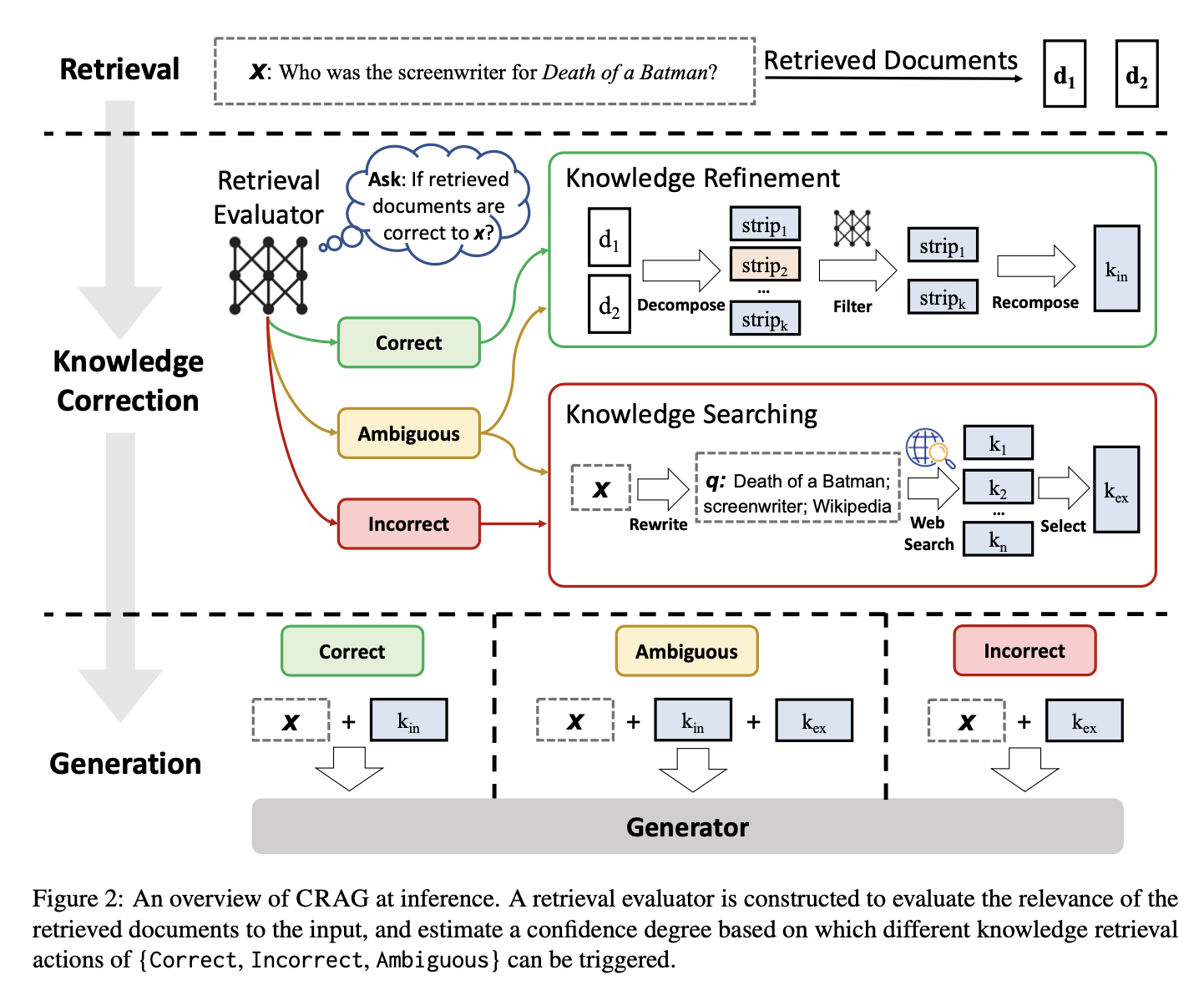
Source: Shi-Qi Yan et al., 2024
The CRAG framework operates through a few key steps, which involve a retrieval evaluator and specific corrective actions.
For any given input query, a standard retriever first pulls a set of documents from a knowledge base. These documents are then reviewed by a retrieval evaluator to determine each document's relevance to the query.
In CRAG, the retrieval evaluator is a fine-tuned T5-large model. The evaluator assigns a confidence score to each document, categorizing them into three levels of confidence:
After one of these actions is taken, the refined knowledge is used to generate the final response.
CRAG makes several key improvements over traditional RAG. One of its biggest advantages is its ability to fix errors in the information it retrieves. The retrieval evaluator in CRAG helps spot when information is wrong or irrelevant, so it can be corrected before it affects the final output. This means CRAG provides more accurate and reliable information, cutting down on errors and misinformation.
CRAG also excels in making sure the information is both relevant and accurate. While traditional RAG might only check relevance scores, CRAG goes further by refining the documents to ensure they are not just relevant but also precise. It filters out irrelevant details and focuses on the most important points, so the generated text is based on accurate information.
In this section, we will go through a step-by-step guide on how to implement CRAG using LangGraph. You'll learn how to set up your environment, create a basic knowledge vector store, and configure the key components needed for CRAG, like the retrieval evaluator, question rewriter, and web search tool.
We'll also learn how to build a LangGraph workflow that brings all these parts together, demonstrating how CRAG can manage various types of queries for more accurate and reliable results.
First, install the required packages. This step sets up the environment to run the CRAG pipeline.
pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-pythonNext, configure your API keys for Tavily and OpenAI:
import os
os.environ["TAVILY_API_KEY"] = "YOUR_TAVILY_API_KEY"
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"To perform RAG, we first need a knowledge base filled with documents. In this step, we'll scrape some sample documents from a Substack newsletter to create a vector store, which acts as our proxy knowledge base. This vector store helps us find relevant documents based on user queries.
We start by loading documents from the provided URLs and splitting them into smaller sections using a text splitter. These sections are then embedded using OpenAIEmbeddings and stored in a vector database (Chroma) for efficient document retrieval.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>",
"<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>",
"<https://ryanocm.substack.com/p/098-i-have-read-100-productivity>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()In this step, we set up a basic RAG chain that takes a user's question and a set of documents to generate an answer.
The RAG chain uses a predefined prompt and a language model (GPT 4-o mini) to create responses based on the retrieved documents. An output parser then formats the generated text to make it easier to read.
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
rag_prompt = hub.pull("rlm/rag-prompt")
# LLM
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# Post-processing
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = rag_prompt | rag_llm | StrOutputParser()
print(rag_prompt.messages[0].prompt.template)You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:generation = rag_chain.invoke({"context": docs, "question": question})
print("Question: %s" % question)
print("----")
print("Documents:\\n")
print('\\n\\n'.join(['- %s' % x.page_content for x in docs]))
print("----")
print("Final answer: %s" % generation)Question: what is the bagel method
----
Documents:
- the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯
- #105 | The Bagel Method in Relationships 🥯
- The Limitless Playbook 🧬SubscribeSign inShare this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOther#105 | The Bagel Method in Relationships 🥯A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��Ryan Ong �Feb 25, 2024Share this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOtherShareHello curious minds 🧠I recently finished the book Fight Right: How Successful Couples Turn Conflict into Connection and oh my days, I love every chapter of it!There were many repeating concepts but this time, it was applied in the context of conflicts in relationships. As usual with the Gottman’s books, I highlighted the hell out of the entire book 😄One of the cool exercises in
- The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals
----
Final answer: The Bagel Method is a relationship strategy that helps partners identify their core needs and areas where they can be flexible. It involves mapping out non-negotiables in the inner circle and compromise areas in the outer circle, facilitating open communication about each partner's priorities. This method aims to foster understanding and collaboration in resolving differences.To improve the accuracy of the generated content, we set up a retrieval evaluator. This tool checks how relevant each retrieved document is to make sure only the most useful information is used.
The retrieval evaluator is configured with a prompt and a language model. It determines whether documents are relevant or not, filtering out any irrelevant content before a response is generated.
### Retrieval Evaluator
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RetrievalEvaluator(BaseModel):
"""Classify retrieved documents based on how relevant it is to the user's question."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
retrieval_evaluator_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_evaluator = retrieval_evaluator_llm.with_structured_output(RetrievalEvaluator)
# Prompt
system = """You are a document retrieval evaluator that's responsible for checking the relevancy of a retrieved document to the user's question. \\n
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n
Output a binary score 'yes' or 'no' to indicate whether the document is relevant to the question."""
retrieval_evaluator_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \\n\\n {document} \\n\\n User question: {question}"),
]
)
retrieval_grader = retrieval_evaluator_prompt | structured_llm_evaluatorWe’ll add a question rewriter to make user queries clearer and more specific, which helps improve the search process.
The rewriter refines the original query to make the search more focused, leading to better and more relevant results.
### Question Re-writer
# LLM
question_rewriter_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Prompt
system = """You are a question re-writer that converts an input question to a better version that is optimized \\n
for web search. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | question_rewriter_llm | StrOutputParser()If the knowledge base doesn’t have enough information, CRAG turns to web search to fill in the gaps. This broadens the range of possible information sources. In this step, we use the Tavily API to search the web and find additional documents.
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)To build the CRAG workflow with LangGraph, follow these three main steps:
Create a shared state to store data as it moves between nodes during the workflow. This state will hold all the variables, such as the user's question, retrieved documents, and generated answers.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]In the LangGraph workflow, each function node handles a specific task in the CRAG pipeline, such as retrieving documents, generating answers, evaluating relevance, transforming queries, and searching the web. Here's a breakdown of each function:
The retrieve function finds documents from the knowledge base that are relevant to the user's question. It uses a retriever object, which is usually a vector store created from pre-processed documents. This function takes the current state, including the user's question, and uses the retriever to get relevant documents. It then adds these documents to the state.
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}The generate function creates a response to the user's question using the retrieved documents. It works with the RAG chain, which combines a prompt with a language model. This function takes the retrieved documents and the user’s question, processes them through the RAG chain, and then adds the answer to the state.
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}The evaluate_documents function checks how relevant each retrieved document is to the user's question using the retrieval evaluator. This helps make sure only useful information is used for the final answer. This function rates each document's relevance and filters out those that aren't useful. It also updates the state with a flag web_search to show if a web search is needed when most documents aren't relevant.
def evaluate_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
if len(filtered_docs) / len(documents) <= 0.7:
web_search = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search}The transform_query function improves the user’s question to get better search results, especially if the original query doesn’t find relevant documents. It uses a question rewriter to make the question clearer and more specific. A better question increases the chances of finding useful documents from both the knowledge base and web searches.
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}The web_search function looks up additional information online using the refined query. It’s used when the knowledge base doesn't have enough information, helping to gather more content. This function uses the Tavily web search tool to find extra documents on the web, which are then added to the existing documents to improve the knowledge base.
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}The decide_to_generate function decides what to do next: either generate an answer with the current documents or refine the query and search again. It makes this choice based on how relevant the documents are (as assessed earlier).
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"Once all the function nodes have been defined, we can now link all the function nodes together in the LangGraph workflow to build the CRAG pipeline. This means connecting the nodes with edges to manage the flow of information and decisions, making sure the workflow runs correctly based on each step's results.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", evaluate_documents) # evaluate documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass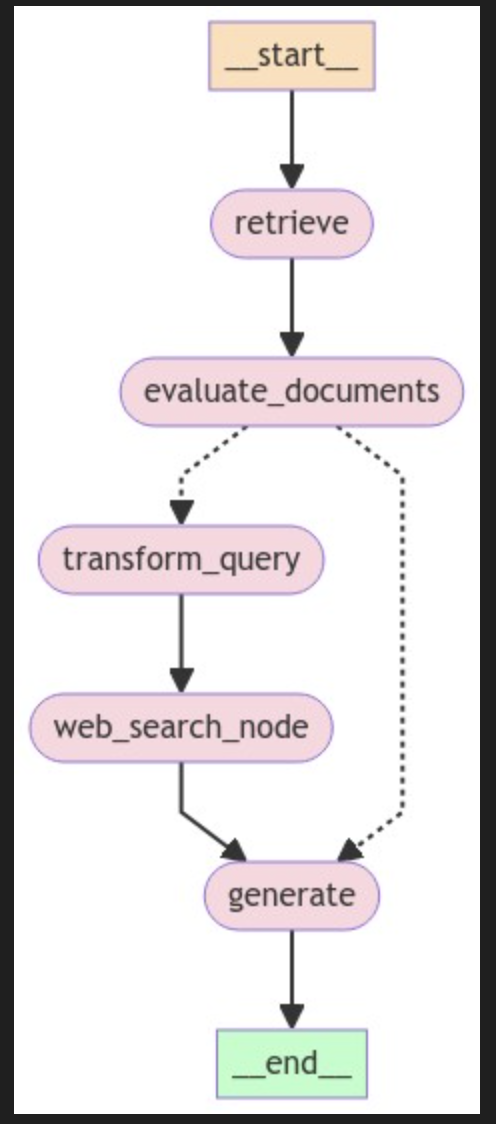
To test our setup, we run the workflow with sample queries to check how it retrieves information, evaluates document relevance, and generates responses.
The first query checks how well CRAG finds answers within its knowledge base.
from pprint import pprint
# Run
inputs = {"question": "What's the bagel method?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint(value, indent=2, width=80, depth=None)
pprint("\\n---\\n")
# Final generation
pprint(value["generation"])---RETRIEVE---
"Node 'retrieve':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='The Limitless Playbook 🧬SubscribeSign inShare this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOther#105 | The Bagel Method in Relationships 🥯A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life â�¤ï¸�Ryan Ong ğŸ�®Feb 25, 2024Share this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOtherShareHello curious minds ğŸ§\\xa0I recently finished the book Fight Right: How Successful Couples Turn Conflict into Connection and oh my days, I love every chapter of it!There were many repeating concepts but this time, it was applied in the context of conflicts in relationships. As usual with the Gottman’s books, I highlighted the hell out of the entire book 😄One of the cool exercises in', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life â�¤ï¸�', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': "What's the bagel method?"}
'\\n---\\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'evaluate_documents':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': "What's the bagel method?",
'web_search': 'No'}
'\\n---\\n'
---GENERATE---
"Node 'generate':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'generation': 'The Bagel Method is a framework designed to help partners '
'navigate differences and find compromises by mapping out '
'their core needs and areas of flexibility. It involves '
'creating two circles: the inner circle for non-negotiable '
'needs and the outer circle for aspects where compromise is '
'possible. This method encourages open communication about '
"each partner's priorities and shared goals.",
'question': "What's the bagel method?"}
'\\n---\\n'
('The Bagel Method is a framework designed to help partners navigate '
'differences and find compromises by mapping out their core needs and areas '
'of flexibility. It involves creating two circles: the inner circle for '
'non-negotiable needs and the outer circle for aspects where compromise is '
"possible. This method encourages open communication about each partner's "
'priorities and shared goals.')And the second query tests CRAG's ability to search the web for additional information when the knowledge base doesn’t have the relevant documents.
from pprint import pprint
# Run
inputs = {"question": "What is prompt engineering?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint(value, indent=2, width=80, depth=None)
pprint("\\n---\\n")
# Final generation
pprint(value["generation"])---RETRIEVE---
"Node 'retrieve':"
{ 'documents': [ Document(page_content='Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries ��", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='ğŸ�¦Â\\xa0Twitter, 👨ğŸ�»â€�💻Â\\xa0LinkedIn, ğŸŒ�Â\\xa0Personal Website, and 📸Â\\xa0InstagramShare this postMystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)ryanocm.substack.comCopy linkFacebookEmailNoteOtherSharePreviousNextCommentsTopLatestDiscussionsNo postsReady for more?Subscribe© 2024 Ryan Ong ğŸ�®Privacy ∙ Terms ∙ Collection notice Start WritingGet the appSubstack is the home for great cultureShareCopy linkFacebookEmailNoteOther', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries â�¤ï¸�", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='skills are the foundation of which you build your life and career and it’s truly yours to own; you can lose your network, resources, and reputation but you will never lose your knowledge and skills.Never try to skip the first two buckets. If you try to jump straight to network, resources, and / or reputation bucket, you might “succeed� in the short-run but in the long run, your lack of knowledge and skill will catch on to you.There is no skipping the first two buckets of knowledge and skills if you’re playing long-term sustainable results. Any attempt to do so is equivalent to building your house on sand.💥 Key takeawayFocus on using your knowledge and skills to create lots of values in the world and the world will reward you with growing network (people will come to you), resources (people will pay for your services), and reputation (people will know what you are capable of).⛰ 4-4-4 Exploration ProjectEach month, I would explore one new thing; a skill, a subject, or an experience.January 2023: Writing and Storytelling (Subject)', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries ��", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='This site requires JavaScript to run correctly. Please turn on JavaScript or unblock scripts', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': 'What is prompt engineering?'}
'\\n---\\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
"Node 'evaluate_documents':"
{ 'documents': [],
'question': 'What is prompt engineering?',
'web_search': 'Yes'}
'\\n---\\n'
---TRANSFORM QUERY---
"Node 'transform_query':"
{ 'documents': [],
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
---WEB SEARCH---
"Node 'web_search_node':"
{ 'documents': [ Document(page_content="Prompt engineering is the method to ask generative AI to produce what the individual needs. There are two main principles of building a successful prompt for any AI, specificity and iteration. The box below includes one example of a framework that can be applied when prompting any generative AI.\\nPrompt Engineering is the process of designing and refining text inputs (prompts) to achieve specific application objectives with AI models. Think of it as a two-step journey: Designing the Initial Prompt: Creating the initial input for the model to achieve the desired result. Refining the Prompt: Continuously adjusting the prompt to enhance ...\\nPrompt engineering is the process of designing and refining the inputs given to language models, like those in AI, to achieve desired outputs more effectively. It involves creatively crafting prompts that guide the model in generating responses that are accurate, relevant, and aligned with the user's intentions.. For students and researchers in higher education, mastering prompt engineering is ...\\nJune 25, 2024. Prompt engineering means writing precise instructions for AI models. These instructions are different from coding because they use natural language. And today, everybody does it—from software developers to artists and content creators. Prompt engineering can help you improve productivity and save time by automating repetitive ...\\nMaster Prompt Engineering - The (AI) Prompt\\nAI Takes Wall Street by Storm: C3.ai's Strong Forecast Sparks a Surge in AI Stocks\\nAsk Me Anything (AMA) Prompting\\nHow Self-Critique Improves Logic and Reasoning in LLMs Like ChatGPT\\nOptimizing Large Language Models to Maximize Performance\\nThe Black Box Problem: Opaque Inner Workings of Large Language Models\\nHow to Evaluate Large Language Models for Business Tasks\\nIntroduction to the AI Prompt Development Process\\nSubscribe to new posts\\nThe Official Source For Everything Prompt Engineering & Generative AI Defining Prompt Engineering\\nGiven that the prompt is the singular input channel to large language models, prompt engineering can be defined as:\\nPrompt Engineering can be thought of as any process that contributes to the development of a well-crafted prompt to generate quality, useful outputs from an AI system.\\n A Simplified Approach to Defining Prompt Engineering\\nThe Prompt is the Sole Input\\nWhen interacting with Generative AI Models such as large language models (LLMs), the prompt is the only thing that gets input into the AI system. Its applications cut across diverse sectors, from healthcare and education to business, securing its place as a cornerstone of our interactions with AI.\\nExploration of Essential Prompt Engineering Techniques and Concepts\\nIn the rapidly evolving landscape of Artificial Intelligence (AI), mastering key techniques of Prompt Engineering has become increasingly vital. The key concepts of Prompt Engineering include prompts and prompting the AI, training the AI, developing and maintaining a prompt library, and testing, evaluation, and categorization.\\n")],
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
---GENERATE---
"Node 'generate':"
{ 'documents': [ Document(page_content="Prompt engineering is the method to ask generative AI to produce what the individual needs. There are two main principles of building a successful prompt for any AI, specificity and iteration. The box below includes one example of a framework that can be applied when prompting any generative AI.\\nPrompt Engineering is the process of designing and refining text inputs (prompts) to achieve specific application objectives with AI models. Think of it as a two-step journey: Designing the Initial Prompt: Creating the initial input for the model to achieve the desired result. Refining the Prompt: Continuously adjusting the prompt to enhance ...\\nPrompt engineering is the process of designing and refining the inputs given to language models, like those in AI, to achieve desired outputs more effectively. It involves creatively crafting prompts that guide the model in generating responses that are accurate, relevant, and aligned with the user's intentions.. For students and researchers in higher education, mastering prompt engineering is ...\\nJune 25, 2024. Prompt engineering means writing precise instructions for AI models. These instructions are different from coding because they use natural language. And today, everybody does it—from software developers to artists and content creators. Prompt engineering can help you improve productivity and save time by automating repetitive ...\\nMaster Prompt Engineering - The (AI) Prompt\\nAI Takes Wall Street by Storm: C3.ai's Strong Forecast Sparks a Surge in AI Stocks\\nAsk Me Anything (AMA) Prompting\\nHow Self-Critique Improves Logic and Reasoning in LLMs Like ChatGPT\\nOptimizing Large Language Models to Maximize Performance\\nThe Black Box Problem: Opaque Inner Workings of Large Language Models\\nHow to Evaluate Large Language Models for Business Tasks\\nIntroduction to the AI Prompt Development Process\\nSubscribe to new posts\\nThe Official Source For Everything Prompt Engineering & Generative AI Defining Prompt Engineering\\nGiven that the prompt is the singular input channel to large language models, prompt engineering can be defined as:\\nPrompt Engineering can be thought of as any process that contributes to the development of a well-crafted prompt to generate quality, useful outputs from an AI system.\\n A Simplified Approach to Defining Prompt Engineering\\nThe Prompt is the Sole Input\\nWhen interacting with Generative AI Models such as large language models (LLMs), the prompt is the only thing that gets input into the AI system. Its applications cut across diverse sectors, from healthcare and education to business, securing its place as a cornerstone of our interactions with AI.\\nExploration of Essential Prompt Engineering Techniques and Concepts\\nIn the rapidly evolving landscape of Artificial Intelligence (AI), mastering key techniques of Prompt Engineering has become increasingly vital. The key concepts of Prompt Engineering include prompts and prompting the AI, training the AI, developing and maintaining a prompt library, and testing, evaluation, and categorization.\\n")],
'generation': 'Prompt engineering is the process of designing and refining '
'text inputs to guide AI models in generating desired outputs. '
'It focuses on specificity and iteration to create effective '
'prompts that align with user intentions. This technique is '
'widely applicable across various sectors, enhancing '
'productivity and automating tasks.',
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
('Prompt engineering is the process of designing and refining text inputs to '
'guide AI models in generating desired outputs. It focuses on specificity and '
'iteration to create effective prompts that align with user intentions. This '
'technique is widely applicable across various sectors, enhancing '
'productivity and automating tasks.')Even though CRAG improves on traditional RAG, it has some limitations that need attention.
One major issue is its dependence on the quality of the retrieval evaluator. This evaluator is essential for judging whether the retrieved documents are relevant and accurate. However, training and fine-tuning the evaluator can be demanding, requiring a lot of high-quality data and computational power. Keeping the evaluator up-to-date with new types of queries and data sources adds to the complexity and cost.
Another limitation is CRAG's use of web searches to find or replace documents that are incorrect or ambiguous. While this approach can provide more recent and diverse information, it also risks introducing biased or unreliable data. The quality of web content varies widely, and sorting through it to find the most accurate information can be challenging. This means even a well-trained evaluator can’t completely prevent the inclusion of poor-quality or biased information.
These challenges highlight the need for ongoing research and development.
Overall, CRAG improves on traditional RAG systems by adding features that check and refine the information retrieved, making language models more accurate and reliable. This makes CRAG a useful tool for many different applications.
To learn more about CRAG, check out the original paper here.
If you’re looking for more learning resources on RAG, I recommend these blogs:
Build AI agents with these courses!
Course
Course
Course
blog
Natassha Selvaraj
10 min
blog
Stanislav Karzhev
12 min
Tutorial
Bhavishya Pandit
Tutorial
Iván Palomares Carrascosa
Tutorial
Ryan Ong
Tutorial
Eugenia Anello

