
Course
Databricks Concepts
4 hr
22K
Databricks APIs enable programmatic interaction with Databricks, allowing users to automate workflows, manage clusters, execute jobs, and access data. These APIs support authentication via personal access tokens, OAuth, or Azure Active Directory.
In this article, I will walk you through an in-depth, hands-on journey through the Databricks REST API. Whether you're new to Databricks or looking to optimize your existing workflows, this guide will help you master key operations, including authentication, job management, and integration with external systems.
By the end of this article, you will have a clear blueprint for:
If you are totally new to Databricks and want to pick it up quickly, read out blog post, How to Learn Databricks: A Beginner’s Guide to the Unified Data Platform, which will help you understand the core features and applications of Databricks, and also provide you a structured path to start your learning.
The Databricks REST API unlocks powerful capabilities for developers and data engineers, enabling them to manage resources programmatically and streamline workflows. Here’s how the Databricks API can make a big difference:
The Databricks API allows users to automate tasks such as job scheduling and cluster management. This reduces the manual effort required to manage these processes, freeing up time for more strategic activities. By automating repetitive tasks, organizations can improve efficiency and reduce the likelihood of human error, which can lead to costly mistakes or downtime.
The Databricks API is designed for flexibility, enabling integration with external platforms such as orchestration tools like Apache Airflow or Azure Data Factory.
You can also use Databricks API for monitoring and alerting systems such as Prometheus or Datadog. Databricks API is also used in data ingestion pipelines from tools like Kafka or RESTful data services. These integrations help build end-to-end workflows that bridge data engineering and analytics across multiple systems.
The Databricks API supports the creation and management of thousands of automated pipelines. It effortlessly scales to manage thousands of jobs running in parallel and dynamic cluster scaling based on workload demand. This scalability ensures that your infrastructure adapts seamlessly to business needs, even at enterprise scale.
The Databricks REST API offers a wide array of operations for managing jobs, clusters, files, and access permissions. Below, I will explore key API operations with practical examples to help you build and automate robust workflows.
Jobs are the backbone of automated workflows in Databricks. The API allows you to create, manage, and monitor jobs seamlessly.
Use the POST /API/2.1/jobs/create endpoint to define a new job. For example, the following JSON payload creates a new Databricks job named My Job and runs a notebook located at /path/to/notebook. The payload then uses an existing cluster with the ID cluster-id, avoiding the need to create a new one. If the job fails, the payload will send an email notification to user@example.com.
{
"name": "My Job",
"existing_cluster_id": "cluster-id",
"notebook_task": {
"notebook_path": "/path/to/notebook"
},
"email_notifications": {
"on_failure": ["user@example.com"]
}
}You can use the endpoint GET /api/2.1/jobs/list to retrieve a list of all jobs in your workspace. For example, the following sample command will list all the jobs:
curl -n -X GET \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/listUse the endpoint POST /api/2.1/jobs/run-now to trigger an immediate run of a job.
curl -n -X POST \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/run-now?job_id=123456789While the latest API version does not have a direct endpoint for deleting jobs, you can manage job runs and their lifecycle through other endpoints. Use the Delete a Job: POST /api/2.1/jobs/delete endpoint to delete a job and POST /api/2.1/jobs/runs/cancel to cancel a run.
Use GET /api/2.1/jobs/runs/get to monitor a job’s status. Retrieve logs or handle errors using the run_state field.
Clusters provide the computing resources for running jobs. The API simplifies cluster lifecycle management.
Create a cluster with POST /api/2.1/clusters/create. For example, you can have the following in the request body.
{
"cluster_name": "Example Cluster",
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 4
}Then, run the sample command below to create this cluster.
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"cluster_name": "My Cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "i3.xlarge", "num_workers": 2}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/clusters/createUse the following APIs to:
Start Cluster: POST /api/2.1/clusters/start
Restart Cluster: POST /api/2.1/clusters/restart
Resize Cluster: PATCH /api/2.1/clusters/edit
Terminate Cluster: POST /api/2.1/clusters/delete
Consider the following best practices for:
DBFS enables file storage and retrieval in Databricks.
You can use the API POST /api/2.1/dbfs/upload to upload files to DBFS in chunks (multipart) or when handling large files (>1MB). The GET /api/2.1/dbfs/read API is used to download files.
Use GET /api/2.1/dbfs/list to explore directories and manage files programmatically. For large file uploads, use chunked uploads with POST /api/2.1/dbfs/put and the overwrite parameter.
The Secrets API ensures secure storage and retrieval of sensitive information.
Use the POST /api/2.1/secrets/create endpoint to create a new secret for storing sensitive information.
For example, you may create the request body in JSON as follows:
{
"scope": "my-scope",
"key": "my-key",
"string_value": "my-secret-value"
}Then, create the secret using the following command:
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"scope": "my-scope", "key": "my-key", "string_value": "my-secret-value"}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/secrets/createUse the GET /API/2.1/secrets/get endpoint to retrieve secrets for external integrations.
The Databricks platform enables granular control over access to jobs and resources.
Use the POST /api/2.1/permissions/jobs/update endpoint to assign roles like owners or viewers. For example, the following payload is used to update permissions:
{
"access_control_list": [
{
"user_name": "user@example.com",
"permission_level": "CAN_MANAGE"
}
]
}Use Databricks' built-in role-based access control (RBAC) to manage permissions across different roles within your organization.
When working with the Databricks REST API, it’s important to account for rate limits, handle errors gracefully, and address common challenges to ensure reliable performance and smooth operations. In this section, I will cover the strategies for optimizing API usage and troubleshooting effectively.
The Databricks API enforces rate limits to ensure fair usage and maintain service reliability.
The following are the common issues you may experience with Databricks APIs and how to solve them.
If you encounter performance bottlenecks, you should consider the following solutions:
The Databricks REST API is highly versatile, supporting both simple, single-threaded workflows and complex parallel processing. By leveraging advanced workflows, you can optimize efficiency and integrate seamlessly with external systems. Let us look at how to implement these features.
As a note, always configure your environment variables using:
DATABRICKS_HOST: This variable stores the URL of your Databricks instance, which is necessary for constructing API requests.
DATABRICKS_TOKEN: This variable holds your access token, simplifying the process of including it in API calls.
Calling a single API endpoint sequentially is effective for smaller tasks or simple automation. The following is a practical example using the requests library in Python.
import requests
import os
# Set up environment variables
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
# API request to list jobs
url = f"{DATABRICKS_HOST}/api/2.1/jobs/list"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
jobs = response.json().get("jobs", [])
for job in jobs:
print(f"Job ID: {job['job_id']}, Name: {job['settings']['name']}")
else:
print(f"Error: {response.status_code} - {response.text}")Parallel processing can significantly improve efficiency for larger-scale data ingestion or when dealing with multiple endpoints. The example below shows how to use Apache Spark to distribute API calls concurrently.
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
import requests
# Initialize Spark session
spark = SparkSession.builder.appName("ParallelAPI").getOrCreate()
# Sample data for parallel calls
data = [{"job_id": 123}, {"job_id": 456}, {"job_id": 789}]
df = spark.createDataFrame(data)
# Define API call function
def fetch_job_details(job_id):
url = f"{DATABRICKS_HOST}/api/2.1/jobs/get"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers, params={"job_id": job_id})
if response.status_code == 200:
return response.json().get("settings", {}).get("name", "Unknown")
return f"Error: {response.status_code}"
# Register UDF
fetch_job_details_udf = udf(fetch_job_details)
# Apply UDF to DataFrame
results_df = df.withColumn("job_name", fetch_job_details_udf("job_id"))
results_df.show()Consider the following tips for scalability and cost trade-offs.
Integrating Databricks with external orchestrators like Airflow or Dagster allows you to manage complex workflows and automate job execution across different systems. The example below shows how to use Airflow to trigger a Databricks job.
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from datetime import datetime
# Define default arguments for the DAG
default_args = {
"owner": "airflow", # Owner of the DAG
"depends_on_past": False, # Do not depend on past DAG runs
"retries": 1, # Number of retry attempts in case of failure
}
# Define the DAG
with DAG(
dag_id="databricks_job_trigger", # Unique DAG ID
default_args=default_args, # Apply default arguments
schedule_interval=None, # Manually triggered DAG (no schedule)
start_date=datetime(2023, 1, 1), # DAG start date
) as dag:
# Task to trigger a Databricks job
run_job = DatabricksRunNowOperator(
task_id="run_databricks_job", # Unique task ID
databricks_conn_id="databricks_default", # Connection ID for Databricks
job_id=12345, # Replace with the actual Databricks job ID
)
# Set task dependencies (if needed)
run_jobFor CI/CD pipelines, tools like Git integration with Databricks can automate the deployment of code and assets across different environments. This ensures that changes are tested and validated before being deployed to production.
# Example of using Databricks REST API in a CI/CD pipeline
import requests
def deploy_to_production():
# Assuming you have a personal access token
token = "your_token_here"
headers = {"Authorization": f"Bearer {token}"}
# Update job or cluster configurations as needed
url = "https://your-databricks-instance.cloud.databricks.com/api/2.1/jobs/update"
payload = {"job_id": "123456789", "new_settings": {"key": "value"}}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print("Deployment successful.")
else:
print(f"Deployment failed. Status code: {response.status_code}")Now that we have seen the different applications of Databricks API let me walk you through an example of an automated pipeline. This pipeline will ingest data from an external API, transform the data in Databricks, and then write the results to a Databricks table. This scenario is a typical end-to-end workflow for modern data engineering tasks. If you need to refresh your knowledge about the main features of Databricks, including data ingestion, I recommend checking out our tutorial on the 7 Must-know Concepts For Any Data Specialist.
To interact with the Databricks REST API, you need to authenticate using a Personal Access Token (PAT). Follow these steps to generate the PAT.
Databricks Workspace. Image by Author.
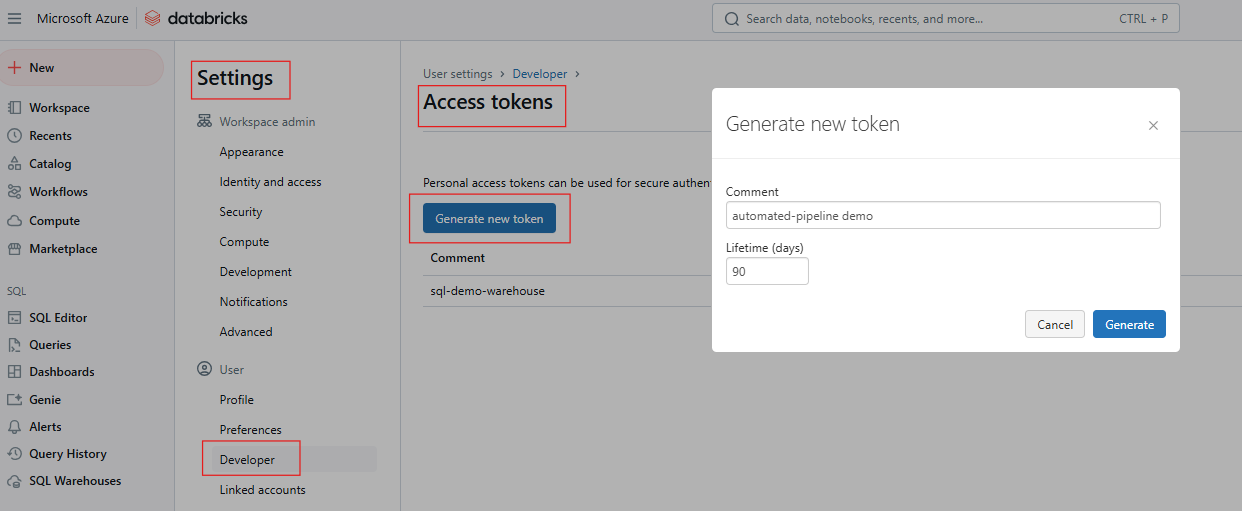
Generating Access Token in Databricks. Image by Author.
If you need to refresh your knowledge about Databricks SQL, I recommend reading our Databricks SQL tutorial to learn how to set up SQL Warehouse from the Databricks web interface.
Set up the environment variables using either of the following:
export DATABRICKS_HOST=https://<your-databricks-instance>
export DATABRICKS_TOKEN=<your-access-token>import os
import requests
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}A Databricks job can consist of multiple tasks, each performing a step in the pipeline. For this example, consider the following:
The following example uses the POST /api/2.1/jobs/create endpoint to create the job.
{
"name": "Multi-Step Pipeline",
"tasks": [
{
"task_key": "fetch_data",
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/fetch_data"
}
},
{
"task_key": "transform_data",
"depends_on": [{"task_key": "fetch_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/transform_data"
}
},
{
"task_key": "write_results",
"depends_on": [{"task_key": "transform_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/write_results"
}
}
]
}Trigger the job using POST /api/2.1/jobs/run-now
curl -n -X POST \
https://$DATABRICKS_HOST/api/2.1/jobs/run-now?job_id=your_job_idMonitor job status using GET /api/2.1/jobs/runs/get with the run_id to track progress.
response = requests.get(f"{DATABRICKS_HOST}/api/2.1/jobs/runs/get", headers=headers, params={"run_id": run_id})
print(response.json())Access the output logs, or results from the tasks using GET /api/2.1/jobs/runs/get-output.
For logging, configure job logs to be written to DBFS or a monitoring tool such as Datadog or Splunk. Also, include detailed logging in each task's notebook for better traceability.
Similarly, implement try-except blocks in notebooks to catch and log exceptions. Use the Databricks Jobs API to retrieve job logs for debugging failed runs. The example below shows error handling in a notebook.
try:
# Code to fetch data from API
response = requests.get(api_url)
# Process data
except Exception as e:
print(f"An error occurred: {e}")
# Log error and exitYou can also integrate with email or Slack notifications using the Databricks Alerts API or third-party tools.
Implementing best practices in Databricks can significantly enhance security, reduce costs, and improve overall system reliability. The following are the key strategies you should consider when using Databricks API and the critical areas.
Avoid storing plain tokens in code or notebooks. Instead, use Databricks Secret to store sensitive information like API keys or credentials securely using the Databricks Secrets API. This ensures that sensitive data is not exposed in plain text within code or notebooks. Always use environment variables to pass tokens or secrets to scripts, but ensure these variables are securely managed and not committed to version control.
Use Role-Based Access Control (RBAC) to define permissions at the workspace, cluster, and job levels and limit access to sensitive APIs to only necessary users or service accounts.
For effective cost management, consider using Single-Node Clusters for continuous, low-load tasks. However, they can be cost-efficient if not fully utilized. Also, ephemeral job clusters are automatically created and terminated for jobs, ensuring resources are not idle.
Due to dynamic pricing for cloud resources, off-peak scheduling can significantly reduce costs. Use the Jobs API to define job schedules during cost-effective time windows.
Lastly, monitor cluster usage by regularly checking cluster utilization to ensure resources are not wasted. Configure clusters to auto-terminate after a specified idle time to prevent unnecessary costs.
For automated tests and job definitions, use unit tests to implement unit tests for job logic to catch errors early. Monitor job runs and log performance metrics to leverage the Jobs API to track job runs programmatically and analyze historical run data:
Using the Databricks REST API allows teams to automate workflows, optimize costs, and seamlessly integrate with external systems, transforming how data pipelines and analytics are managed. I encourage you to start by testing a basic API call, such as creating a job, to build confidence with the platform. You can also explore other advanced topics like Unity Catalog for fine-grained governance or dive into real-time streaming use cases.
Also, I recommend that you refer to the Official Databricks REST API Docs to help answer outstanding questions, and that you explore GitHub repositories on the Databricks CLI and Databricks SDK for Python to learn more about streamlined development.
If you want to explore Databricks' foundational concepts, I highly recommend taking our Introduction to Databricks course. This course teaches you about Databricks as a data warehousing solution for Business Intelligence. I also recommend checking out our Databricks Certifications In 2024 blog post to learn how to obtain Databricks certifications, explore career benefits, and choose the right certification for your career goals.
Learn Cloud with DataCamp
Course
Course
Course
blog
Josep Ferrer
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Jake Roach
Tutorial
Oluseye Jeremiah
Tutorial
Allan Ouko