
Curso
Conceitos de Databricks
4 h
22K
As APIs do Databricks possibilitam a interação programática com o Databricks, permitindo que os usuários automatizem fluxos de trabalho, gerenciem clusters, executem trabalhos e acessem dados. Essas APIs oferecem suporte à autenticação por meio de tokens de acesso pessoal, OAuth ou Azure Active Directory.
Neste artigo, orientarei você em uma jornada prática e detalhada pela API REST da Databricks. Quer você seja novo no Databricks ou esteja procurando otimizar os fluxos de trabalho existentes, este guia o ajudará a dominar as principais operações, incluindo autenticação, gerenciamento de trabalhos e integração com sistemas externos.
Ao final deste artigo, você terá um plano claro para:
Se você for totalmente novo no Databricks e quiser aprendê-lo rapidamente, leia nossa postagem no blog How to Learn Databricks: A Beginner's Guide to the Unified Data Platform, que ajudará você a entender os principais recursos e aplicativos do Databricks e também fornecerá um caminho estruturado para iniciar seu aprendizado.
A API REST da Databricks desbloqueia recursos avançados para desenvolvedores e engenheiros de dados, permitindo que eles gerenciem recursos de forma programática e otimizem fluxos de trabalho. Veja como a API da Databricks pode fazer uma grande diferença:
A API do Databricks permite que os usuários automatizem tarefas como agendamento de tarefas e gerenciamento de clusters. Isso reduz o esforço manual necessário para gerenciar esses processos, liberando tempo para atividades mais estratégicas. Ao automatizar tarefas repetitivas, as organizações podem aumentar a eficiência e reduzir a probabilidade de erro humano, o que pode levar a erros dispendiosos ou tempo de inatividade.
A API da Databricks foi projetada para ser flexível, permitindo a integração com plataformas externas, como ferramentas de orquestração como o Apache Airflow ou o Azure Data Factory.
Você também pode usar a API do Databricks para sistemas de monitoramento e alerta, como o Prometheus ou o Datadog. A API do Databricks também é usada em pipelines de ingestão de dados de ferramentas como Kafka ou serviços de dados RESTful. Essas integrações ajudam a criar fluxos de trabalho de ponta a ponta que unem a engenharia e a análise de dados em vários sistemas.
A API da Databricks oferece suporte à criação e ao gerenciamento de milhares de pipelines automatizados. Ele é facilmente dimensionado para gerenciar milhares de trabalhos executados em paralelo e o dimensionamento dinâmico do cluster com base na demanda da carga de trabalho. Essa escalabilidade garante que sua infraestrutura se adapte perfeitamente às necessidades dos negócios, mesmo em escala empresarial.
A API REST da Databricks oferece uma ampla gama de operações para gerenciar trabalhos, clusters, arquivos e permissões de acesso. A seguir, explorarei as principais operações da API com exemplos práticos para ajudar você a criar e automatizar fluxos de trabalho robustos.
Os trabalhos são a espinha dorsal dos fluxos de trabalho automatizados na Databricks. A API permite que você crie, gerencie e monitore trabalhos sem problemas.
Use o ponto de extremidade POST /API/2.1/jobs/create para definir um novo trabalho. Por exemplo, o payload JSON a seguir cria um novo trabalho do Databricks chamado My Job e executa um notebook localizado em /path/to/notebook. A carga útil usa um cluster existente com o ID cluster-id, evitando a necessidade de criar um novo. Se o trabalho falhar, o payload enviará uma notificação por e-mail para user@example.com.
{
"name": "My Job",
"existing_cluster_id": "cluster-id",
"notebook_task": {
"notebook_path": "/path/to/notebook"
},
"email_notifications": {
"on_failure": ["user@example.com"]
}
}Você pode usar o ponto de extremidade GET /api/2.1/jobs/list para recuperar uma lista de todos os trabalhos em seu espaço de trabalho. Por exemplo, o comando de amostra a seguir listará todos os trabalhos:
curl -n -X GET \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/listUse o ponto de extremidade POST /api/2.1/jobs/run-now para acionar a execução imediata de um trabalho.
curl -n -X POST \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/run-now?job_id=123456789Embora a versão mais recente da API não tenha um ponto de extremidade direto para excluir trabalhos, você pode gerenciar execuções de trabalhos e seu ciclo de vida por meio de outros pontos de extremidade. Use o ponto de extremidade Delete a Job: POST /api/2.1/jobs/delete para excluir um trabalho e POST /api/2.1/jobs/runs/cancel para cancelar uma execução.
Use o site GET /api/2.1/jobs/runs/get para monitorar o status de um trabalho. Recupere os registros ou trate os erros usando o campo run_state.
Os clusters fornecem os recursos de computação para a execução de trabalhos. A API simplifica o gerenciamento do ciclo de vida do cluster.
Crie um cluster com POST /api/2.1/clusters/create. Por exemplo, você pode ter o seguinte no corpo da solicitação.
{
"cluster_name": "Example Cluster",
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 4
}Em seguida, execute o comando de exemplo abaixo para criar esse cluster.
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"cluster_name": "My Cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "i3.xlarge", "num_workers": 2}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/clusters/createUse as seguintes APIs para:
Iniciar o cluster: POST /api/2.1/clusters/start
Reinicie o cluster: POST /api/2.1/clusters/restart
Redimensionar o cluster: PATCH /api/2.1/clusters/edit
Encerrar o cluster: POST /api/2.1/clusters/delete
Considere as seguintes práticas recomendadas para você:
O DBFS permite o armazenamento e a recuperação de arquivos no Databricks.
Você pode usar a API POST /api/2.1/dbfs/upload para fazer upload de arquivos para o DBFS em partes (multipart) ou ao lidar com arquivos grandes (>1 MB). A API GET /api/2.1/dbfs/read é usada para fazer download de arquivos.
Use o site GET /api/2.1/dbfs/list para explorar diretórios e gerenciar arquivos de forma programática. Para uploads de arquivos grandes, use uploads em pedaços com POST /api/2.1/dbfs/put e o parâmetro overwrite.
A API Secrets garante o armazenamento e a recuperação seguros de informações confidenciais.
Use o ponto de extremidade POST /api/2.1/secrets/create para criar um novo segredo para armazenar informações confidenciais.
Por exemplo, você pode criar o corpo da solicitação em JSON da seguinte forma:
{
"scope": "my-scope",
"key": "my-key",
"string_value": "my-secret-value"
}Em seguida, crie o segredo usando o seguinte comando:
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"scope": "my-scope", "key": "my-key", "string_value": "my-secret-value"}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/secrets/createUse o ponto de extremidade GET /API/2.1/secrets/get para recuperar segredos para integrações externas.
A plataforma Databricks permite o controle granular do acesso a trabalhos e recursos.
Use o ponto de extremidade POST /api/2.1/permissions/jobs/update para atribuir funções como proprietários ou visualizadores. Por exemplo, o payload a seguir é usado para atualizar as permissões:
{
"access_control_list": [
{
"user_name": "user@example.com",
"permission_level": "CAN_MANAGE"
}
]
}Use o controle de acesso baseado em função (RBAC) integrado do Databricks para gerenciar as permissões em diferentes funções dentro da organização.
Quando você trabalha com a API REST da Databricks, é importante levar em conta os limites de taxa, lidar com erros de forma elegante e enfrentar desafios comuns para garantir um desempenho confiável e operações tranquilas. Nesta seção, abordarei as estratégias para otimizar o uso da API e solucionar problemas de forma eficaz.
A API da Databricks impõe limites de taxa para garantir o uso justo e manter a confiabilidade do serviço.
Veja a seguir os problemas comuns que você pode enfrentar com as APIs da Databricks e como resolvê-los.
Se encontrar gargalos de desempenho, você deve considerar as seguintes soluções:
A API REST da Databricks é altamente versátil, oferecendo suporte tanto a fluxos de trabalho simples e de thread único quanto a processamento paralelo complexo. Ao aproveitar os fluxos de trabalho avançados, você pode otimizar a eficiência e integrar-se perfeitamente aos sistemas externos. Vamos ver como você pode implementar esses recursos.
Como observação, sempre configure suas variáveis de ambiente usando:
DATABRICKS_HOST: Essa variável armazena a URL da sua instância do Databricks, que é necessária para a construção de solicitações de API.
DATABRICKS_TOKEN: Essa variável contém seu token de acesso, simplificando o processo de incluí-lo nas chamadas de API.
Chamar um único endpoint de API sequencialmente é eficaz para tarefas menores ou automação simples. A seguir, você verá um exemplo prático usando a biblioteca de solicitações em Python.
import requests
import os
# Set up environment variables
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
# API request to list jobs
url = f"{DATABRICKS_HOST}/api/2.1/jobs/list"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
jobs = response.json().get("jobs", [])
for job in jobs:
print(f"Job ID: {job['job_id']}, Name: {job['settings']['name']}")
else:
print(f"Error: {response.status_code} - {response.text}")O processamento paralelo pode aumentar significativamente a eficiência da ingestão de dados em grande escala ou ao lidar com vários pontos de extremidade. O exemplo abaixo mostra como você pode usar o Apache Spark para distribuir chamadas de API simultaneamente.
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
import requests
# Initialize Spark session
spark = SparkSession.builder.appName("ParallelAPI").getOrCreate()
# Sample data for parallel calls
data = [{"job_id": 123}, {"job_id": 456}, {"job_id": 789}]
df = spark.createDataFrame(data)
# Define API call function
def fetch_job_details(job_id):
url = f"{DATABRICKS_HOST}/api/2.1/jobs/get"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers, params={"job_id": job_id})
if response.status_code == 200:
return response.json().get("settings", {}).get("name", "Unknown")
return f"Error: {response.status_code}"
# Register UDF
fetch_job_details_udf = udf(fetch_job_details)
# Apply UDF to DataFrame
results_df = df.withColumn("job_name", fetch_job_details_udf("job_id"))
results_df.show()Considere as seguintes dicas para escalabilidade e compensações de custo.
A integração do Databricks com orquestradores externos, como o Airflow ou o Dagster, permite que você gerencie fluxos de trabalho complexos e automatize a execução de tarefas em diferentes sistemas. O exemplo abaixo mostra como você pode usar o Airflow para acionar um trabalho do Databricks.
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from datetime import datetime
# Define default arguments for the DAG
default_args = {
"owner": "airflow", # Owner of the DAG
"depends_on_past": False, # Do not depend on past DAG runs
"retries": 1, # Number of retry attempts in case of failure
}
# Define the DAG
with DAG(
dag_id="databricks_job_trigger", # Unique DAG ID
default_args=default_args, # Apply default arguments
schedule_interval=None, # Manually triggered DAG (no schedule)
start_date=datetime(2023, 1, 1), # DAG start date
) as dag:
# Task to trigger a Databricks job
run_job = DatabricksRunNowOperator(
task_id="run_databricks_job", # Unique task ID
databricks_conn_id="databricks_default", # Connection ID for Databricks
job_id=12345, # Replace with the actual Databricks job ID
)
# Set task dependencies (if needed)
run_jobPara pipelines de CI/CD, ferramentas como a integração do Git com o Databricks podem automatizar a implantação de código e ativos em diferentes ambientes. Isso garante que as alterações sejam testadas e validadas antes de serem implantadas na produção.
# Example of using Databricks REST API in a CI/CD pipeline
import requests
def deploy_to_production():
# Assuming you have a personal access token
token = "your_token_here"
headers = {"Authorization": f"Bearer {token}"}
# Update job or cluster configurations as needed
url = "https://your-databricks-instance.cloud.databricks.com/api/2.1/jobs/update"
payload = {"job_id": "123456789", "new_settings": {"key": "value"}}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print("Deployment successful.")
else:
print(f"Deployment failed. Status code: {response.status_code}")Agora que já vimos as diferentes aplicações da API do Databricks, deixe-me mostrar a você um exemplo de pipeline automatizado. Com esse pipeline, você receberá dados de uma API externa, transformará os dados no Databricks e, em seguida, gravará os resultados em uma tabela do Databricks. Esse cenário é um fluxo de trabalho típico de ponta a ponta para tarefas modernas de engenharia de dados. Se você precisar atualizar seus conhecimentos sobre os principais recursos do Databricks, incluindo a ingestão de dados, recomendo que consulte nosso tutorial sobre os 7 conceitos obrigatórios para qualquer especialista em dados.
Para interagir com a API REST da Databricks, você precisa se autenticar usando um token de acesso pessoal (PAT). Siga estas etapas para gerar o PAT.
Espaço de trabalho do Databricks. Imagem do autor.
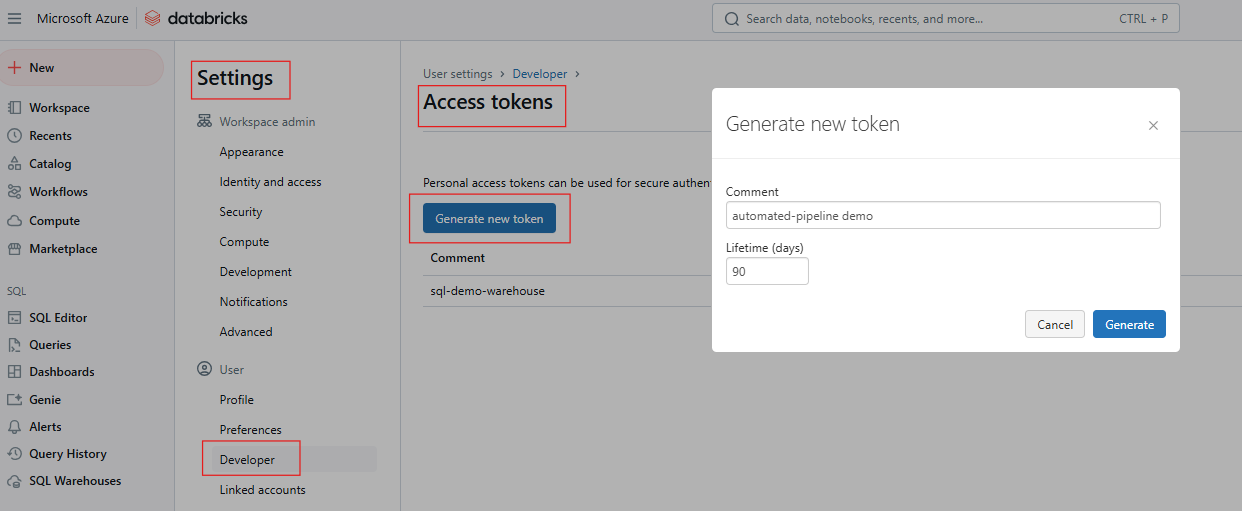
Geração de token de acesso no Databricks. Imagem do autor.
Se você precisar atualizar seus conhecimentos sobre o SQL do Databricks, recomendo a leitura do nosso tutorial do SQL do Databricks para saber como configurar o SQL Warehouse na interface da Web do Databricks.
Configure as variáveis de ambiente usando uma das seguintes opções:
export DATABRICKS_HOST=https://<your-databricks-instance>
export DATABRICKS_TOKEN=<your-access-token>import os
import requests
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}Um trabalho do Databricks pode consistir em várias tarefas, cada uma executando uma etapa do pipeline. Para este exemplo, considere o seguinte:
O exemplo a seguir usa o ponto de extremidade POST /api/2.1/jobs/create para criar o trabalho.
{
"name": "Multi-Step Pipeline",
"tasks": [
{
"task_key": "fetch_data",
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/fetch_data"
}
},
{
"task_key": "transform_data",
"depends_on": [{"task_key": "fetch_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/transform_data"
}
},
{
"task_key": "write_results",
"depends_on": [{"task_key": "transform_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/write_results"
}
}
]
}Acione o trabalho usando POST /api/2.1/jobs/run-now
curl -n -X POST \
https://$DATABRICKS_HOST/api/2.1/jobs/run-now?job_id=your_job_idMonitore o status do trabalho usando GET /api/2.1/jobs/runs/get com o run_id para acompanhar o progresso.
response = requests.get(f"{DATABRICKS_HOST}/api/2.1/jobs/runs/get", headers=headers, params={"run_id": run_id})
print(response.json())Acesse os registros de saída ou os resultados das tarefas usando GET /api/2.1/jobs/runs/get-output.
Para registro, configure os registros de trabalho para serem gravados no DBFS ou em uma ferramenta de monitoramento, como o Datadog ou o Splunk. Além disso, inclua o registro detalhado no caderno de cada tarefa para melhorar a rastreabilidade.
Da mesma forma, implemente blocos try-except em notebooks para capturar e registrar exceções. Use a API Databricks Jobs para recuperar os registros de trabalho para depurar execuções com falha. O exemplo abaixo mostra o tratamento de erros em um notebook.
try:
# Code to fetch data from API
response = requests.get(api_url)
# Process data
except Exception as e:
print(f"An error occurred: {e}")
# Log error and exitVocê também pode integrar notificações por e-mail ou Slack usando a API de alertas da Databricks ou ferramentas de terceiros.
A implementação de práticas recomendadas no Databricks pode aumentar significativamente a segurança, reduzir custos e melhorar a confiabilidade geral do sistema. Veja a seguir as principais estratégias que você deve considerar ao usar a API da Databricks e as áreas críticas.
Evite armazenar tokens simples em códigos ou notebooks. Em vez disso, use o Databricks Secret para armazenar informações confidenciais, como chaves de API ou credenciais, com segurança, usando a API Databricks Secrets. Isso garante que os dados confidenciais não sejam expostos em texto simples no código ou nos notebooks. Sempre use variáveis de ambiente para passar tokens ou segredos para scripts, mas certifique-se de que essas variáveis sejam gerenciadas com segurança e não sejam confirmadas no controle de versão.
Use o RBAC (Role-Based Access Control, controle de acesso baseado em função) para definir permissões nos níveis de espaço de trabalho, cluster e trabalho e limitar o acesso a APIs confidenciais somente aos usuários ou contas de serviço necessários.
Para um gerenciamento de custos eficaz, considere o uso de clusters de nó único para tarefas contínuas e de baixa carga. No entanto, eles podem ser econômicos se não forem totalmente utilizados. Além disso, clusters de trabalhos efêmeros são criados e encerrados automaticamente para os trabalhos, garantindo que os recursos não fiquem ociosos.
Devido ao preço dinâmico dos recursos da nuvem, a programação fora do horário de pico pode reduzir significativamente os custos. Use a API Jobs para definir programações de trabalho durante janelas de tempo econômicas.
Por fim, monitore o uso do cluster verificando regularmente a utilização do cluster para garantir que os recursos não sejam desperdiçados. Configure os clusters para encerrar automaticamente após um tempo ocioso especificado para evitar custos desnecessários.
Para testes automatizados e definições de trabalho, use testes de unidade para implementar testes de unidade para a lógica do trabalho a fim de detectar erros antecipadamente. Monitore as execuções de trabalhos e registre as métricas de desempenho para aproveitar a API de trabalhos para rastrear execuções de trabalhos de forma programática e analisar dados históricos de execução:
O uso da API REST da Databricks permite que as equipes automatizem fluxos de trabalho, otimizem custos e se integrem perfeitamente a sistemas externos, transformando a maneira como os pipelines de dados e a análise são gerenciados. Incentivo você a começar testando uma chamada básica de API, como a criação de um trabalho, para aumentar a confiança na plataforma. Você também pode explorar outros tópicos avançados, como o Unity Catalog para governança refinada, ou mergulhar em casos de uso de streaming em tempo real.
Além disso, recomendo que você consulte os documentos oficiais da API REST da Databricks para ajudar a responder perguntas pendentes e que explore os repositórios do GitHub sobre a CLI da Databricks e o SDK da Databricks para Python para saber mais sobre o desenvolvimento simplificado.
Se você quiser explorar os conceitos básicos da Databricks, recomendo fortemente que faça nosso curso Introduction to Databricks. Este curso ensina a você sobre o Databricks como uma solução de data warehouse para Business Intelligence. Também recomendo que você confira nossa postagem no blog Databricks Certifications In 2024 para saber como obter as certificações da Databricks, explorar os benefícios da carreira e escolher a certificação certa para suas metas profissionais.
Aprenda a usar a nuvem com a DataCamp
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita
Tutorial
Joleen Bothma