Programa
Fundamentos da IA
10 h
A Databricks apresentou recentemente o DBRX, seu modelo de linguagem grande (LLM) aberto e de uso geral, desenvolvido em uma arquitetura de mistura de especialistas (MoE) com uma abordagem de granulação fina. Em vez de usar uma única rede neural para todas as tarefas, o sistema compreende várias redes "especializadas" especializadas, cada uma otimizada para diferentes tipos de tarefas ou dados.
Esse modelo teve um desempenho melhor do que os LLMs tradicionais, como o GPT-3.5 e o Llama 2, porque é mais rápido e econômico. De acordo com os testes, o DBRX obteve uma pontuação de 73,7%, que é maior do que o LLaMa2 (69,8%) em tarefas de compreensão de idiomas.
Neste artigo, discutiremos mais detalhadamente seus recursos e como você pode começar a usar o Databricsk DBRX.
O DBRX usa uma arquitetura de decodificador baseada em transformador treinada usando a previsão do próximo token. Ele emprega uma arquitetura de mistura de especialistas (MoE) de granulação fina. Esses "especialistas" referem-se a agentes especializados baseados em LLMs, aprimorados com conhecimento específico do domínio e habilidades de raciocínio.
O DBRX tem um grande número de especialistas menores (16 especialistas no total) e escolhe um subconjunto deles (4 especialistas) para qualquer entrada.
Simplificando, essa abordagem refinada com 65 vezes mais combinações possíveis de especialistas melhora a qualidade do modelo em comparação com outros modelos abertos de MoE, como Mixtral e Grok-1, que têm menos especialistas e escolhem menos especialistas por entrada.
Aqui estão alguns detalhes importantes sobre a DBRX:
O modelo foi pré-treinado em um conjunto de dados impressionantemente grande, estimado como duas vezes mais eficaz do que os conjuntos de dados anteriores usados pela Databricks. Um conjunto de ferramentas da Databricks, como o Apache Spark e os notebooks da Databricks para processamento de dados e o Unity Catalog para governança de dados, foi usado para treinar o modelo.
Durante o treinamento, o aprendizado curricular foi empregado e a combinação de dados foi alterada para melhorar substancialmente a qualidade do modelo. Essas alterações estratégicas na combinação de dados de treinamento otimizaram a capacidade do modelo de lidar com diversas entradas de forma eficaz.
Algumas das principais tecnologias usadas no pré-treinamento da DBRX incluem:
A Databricks afirma que seu modelo DBRX é superior a vários dos principais modelos de código aberto em termos de eficiência e desempenho de tarefas.
Aqui você encontra uma comparação detalhada de como o DBRX se compara aos seus concorrentes:
Abaixo, reunimos as comparações em uma tabela e mostramos um gráfico com base em alguns dos resultados:
|
Comparação de modelos |
Conhecimento geral |
Raciocínio de senso comum |
Databricks Gauntlet |
Raciocínio de programação |
Raciocínio matemático |
|
DBRX vs LLaMA2-70B |
+9.8% |
+3.1% |
+14% |
+37.9% |
+40.2% |
|
DBRX vs. Mixtral Instruct |
+2.3% |
+1.4% |
+6.1% |
+15.3% |
+5.8% |
|
DBRX vs Grok-1 |
+0.7% |
Não disponível |
Não disponível |
+6.9% |
+4% |
|
DBRX vs Base Mixtral |
+1.8% |
+2.5% |
+10% |
+29.9% |
Não disponível |
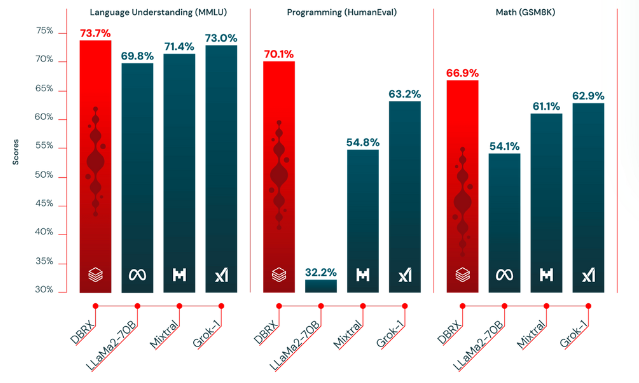
Comparando a qualidade do DBRX com outros LLMs de código aberto - fonte
Antes de acessar o DBRX, certifique-se de que seu sistema tenha pelo menos 320 GB de memória. Em seguida, siga estas etapas para acessar o DBRX:
transformers pip install "transformers>=4.40.0"from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-base", token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-base", device_map="auto", torch_dtype=torch.bfloat16, token="hf_YOUR_TOKEN")
# Directing tensors to "cuda" (GPU) for faster computation as GPUs are better at handling parallel tasks.
input_text = "Databricks was founded in "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
# DBRX accepts a context length of up to 32768 tokens. Here`max_new_tokens` specifies the maximum number of tokens to generate.
outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))Você quer aprender a usar o Transformers e o Hugging Face? Leia nosso tutorial sobre como usar Transformers e Hugging Face.
A DRBX pode ajudar você com a criação de conteúdo básico e tarefas de resposta imediata, como qualquer LLM. Veja o que você pode fazer com o DBRX:
O DBRX também pode executar tarefas avançadas relacionadas à codificação para ajudar os profissionais de dados ou codificadores:

DBRX respondendo a comandos simples - fonte
Você pode ajustar o DBRX com o LLM foundry de código aberto do Github. No entanto, o ajuste fino exige que os exemplos de treinamento sejam formatados como dicionários:
formatted_example = {'prompt': <prompt_text>, 'response': <response_text>}Sugestão: Essa é a pergunta ou instrução inicial que você dá ao modelo.
Resposta: Essa é a resposta que o modelo foi treinado para gerar.
Você pode usar três conjuntos de dados diferentes para fazer o ajuste fino de qualquer LLM:
Se você quiser fazer o ajuste fino usando um conjunto de dados do HuggingFace Hub, e o
O conjunto de dados tem uma função de pré-processamento pré-definida ou já segue o padrão
"prompt"/"response", você pode simplesmente apontar o dataloader para esse conjunto de dados.
train_loader:
name: finetuning
dataset:
hf_name: tatsu-lab/alpaca
split: train
...Se nenhuma função de pré-processamento for definida, use preprocessing_fn para especificar uma função de pré-processamento personalizada para o carregador de dados.
train_loader:
name: finetuning
dataset:
hf_name: mosaicml/doge-facts
preprocessing_fn: my_data.formatting:dogefacts_prep_fn
split: train
...
Se você já tiver um conjunto de dados de ajuste fino em seu dispositivo, defina os arquivos JSONL locais em
A configuração YAML yamls/finetune/1b_local_data_sft.yaml.
train_loader:
name: finetuning
dataset:
hf_name: json # assuming data files are json formatted
hf_kwargs:
data_dir: /path/to/data/dir/
preprocessing_fn: my.import.path:my_preprocessing_fn
split: train
...
Ignore preprocessing_fn se seus dados locais já estiverem no formato "prompt"/"response".
Converta seu conjunto de dados do HuggingFace para o formato MDS usando o
convert_finetuning_dataset.py roteiro.
Depois de converter o conjunto de dados HuggingFace em um formato de streaming, basta ajustar a configuração YAML da seguinte forma.
train_loader:
name: finetuning
dataset:
remote: s3://my-bucket/my-copy-doge-facts
local: /tmp/mds-cache/
split: train
...
Se você quiser ver o ajuste fino completo dos parâmetros, consulte a configuração YAML em
O Databricks DBRX usa várias redes especializadas para aumentar a velocidade do modelo e a relação custo-benefício. Essa abordagem refinada permite que ele supere outros LLMs no tratamento de tarefas complexas.
Você quer saber mais sobre modelos de linguagem grandes e como ajustá-los? Dê uma olhada nestes recursos:
Continue sua jornada de IA hoje mesmo!
Programa
Curso
Curso
blog
Kurtis Pykes
7 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Natassha Selvaraj
Tutorial
Kurtis Pykes


